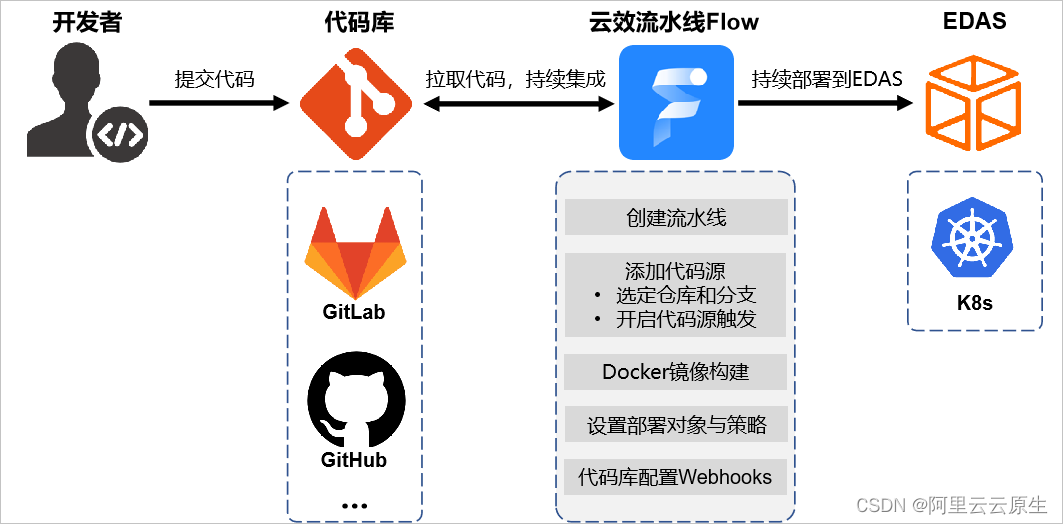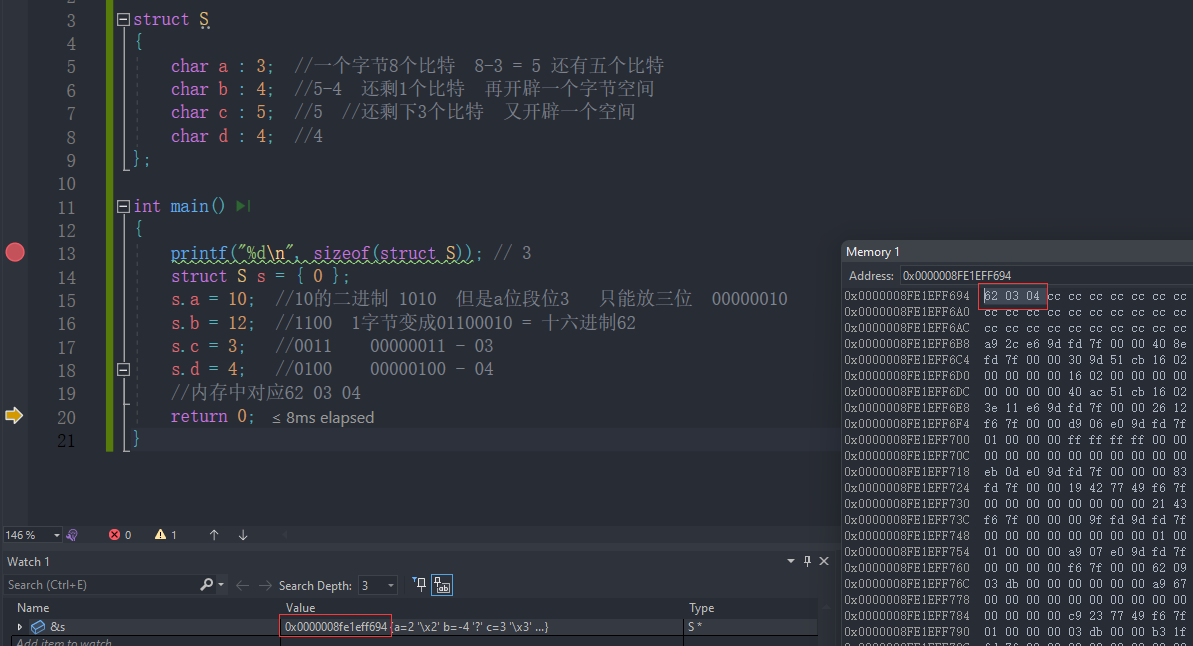
map的结果本身是无序的,但是map输出的结果有序
mapper和reduce是不同的机器,进行了网络传输,所以存在数据拷贝
第二次排序,是将每个reduce对应的task进行排序,然后再进入reduce
maptask运行结束,每个mask块自身排一下序(并行)。先copy到相应的机器,然后再重新进行一次排序。注意,应该是边复制边排序。
map的结果本身是无序的,但是map输出的结果有序
mapper和reduce是不同的机器,进行了网络传输,所以存在数据拷贝
第二次排序,是将每个reduce对应的task进行排序,然后再进入reduce
maptask运行结束,每个mask块自身排一下序(并行)。先copy到相应的机器,然后再重新进行一次排序。注意,应该是边复制边排序。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/770999.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!