得益于语音识别技术的发展,人工智能可以帮助人们记录会议,自动检测与会后行动项关联的会议内容,并进行总结。
行动项识别对于管理会后待办任务至关重要。
针对对于行动项识别任务,相关数据集稀缺且规模小。因此,达摩院构建并开源了AMC-A语料库,这或是首个带有行动项标注的中文会议语料库。
基于行动项数据集,达摩院提出了 Context-Drop 方法,通过对比学习利用局部和全局上下文,在行动项识别任务中取得了更好的表现和鲁棒性。此外,我们探索了轻量级模型集成方式来利用不同的预训练模型的方法。
开源数据链接👇:
https://www.modelscope.cn/datasets/modelscope/Alimeeting4MUG/summary
开源方法链接👇:
https://github.com/alibaba-damo-academy/SpokenNLP/tree/main/action-item-detection
数据集构建
AMI 数据集
AMI 会议语料库在各种会议相关研究中发挥了重要作用。它包含 171 份会议记录和各种类型的第三方标注。其中,场景式会议有 145 篇,自然发生会议有 26 篇。
AMI 会议语料库是用于评估行动项识别表现的常用数据集。虽然这个语料库没有行动项的直接标注,但是可以根据摘要的标注生成间接标注。
参照之前工作的范式,我们将与行动项相关的摘要所对应的对话行为视为正样本,否则为负样本。通过这种方式,我们获得了 101 篇带有 381 个行动项正例的有标注会议。此外,我们应用了官方推荐的仅限场景的数据集划分方式。
AMC-A 数据集
我们构建并提供了一个中文会议语料库,即 AliMeeting-Action Corpus 语料库 (AMC-A),其中包含行动项标注。我们扩展了之前在 M2MET 中发布的 224 次会议,增加了 200 次会议。每场会议由 2 到 4 名参与者进行 15 分钟到 30 分钟的讨论。讨论的话题比较多样,偏向于各个行业的工作会议。所有 424 份会议记录均为手动转录,并插入了标点符号。以手动标记的句号、问号和感叹号结尾的语义单元被视为用于行动项标注和建模的句子。
我们将行动项识别看作二分类任务,并进行句子级别的行动项标注,即包含行动项信息(任务描述、时间期限、负责人)的句子为正样本(标记为 1),否则为负样本 (标记为 0)。根据之前的研究和我们的经验,行动项的标注具有高主观性和低一致性,比如在 ICSI 语料库上的 Kappa 系数仅为 0.36。
为了简化任务,我们提供了详细的标注规范和充足的示例。为了降低标注成本,我们首先选择包含时间表达(例如“明天”)和与动作相关的动词(例如“完成”)的候选句子,并以不同的颜色进行高亮显示。然后由三位标注员独立地标注候选句子。标注时,候选句子会随上下文一起显示,以便标注员可以更好地利用上下文信息进行理解。
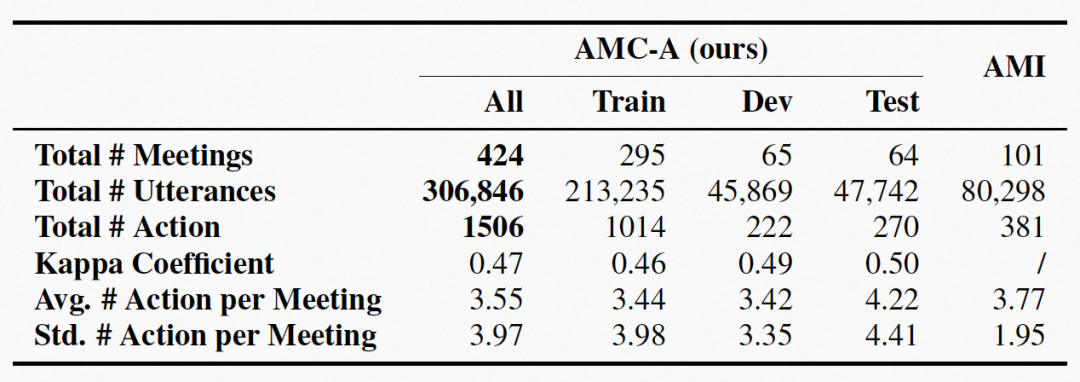
(图示:中文 AMC-A 数据集及英文 AMI 数据集统计结果)
通过这些标注方法,标注员之间的平均 Kappa 系数为 0.47。对于来自三位标注员的不一致标注,由一位专家决定最终标注。上表显示 AMC-A 和 AMI 会议语料库的统计结果。AMC-A 或是第一个中文带有行动项标注的会议语料库。
方法介绍
此前的研究方法几乎都用到了局部上下文,但是对于全局上下文的关注不足。通过下面这个例子可以看出,局部上下文可以提供很多相关信息。但是有一些不邻近的句子,也可以提供一些相关信息,我们称之为全局上下文。

(图示:行动项示例,提供了句子编号、说话人信息,标注了行动项、局部上下文和全局上下文)
一方面,上下文对于行动项识别任务非常重要。另一方面,局部上下文和全局上下文中都有一些无关信息,这可能反而会对分类器的表现造成负面影响。
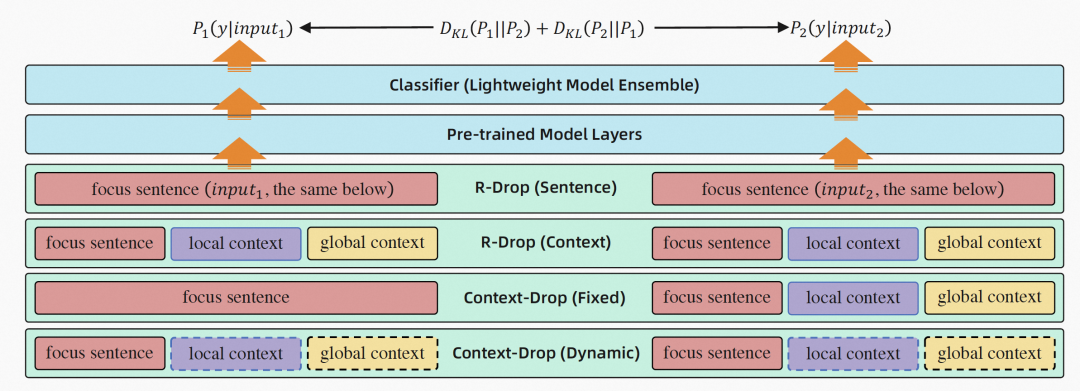
(图示:上下文建模方法)
我们希望模型可以更专注于当前句子,可以更好地利用上下文中的有关信息提高模型表现,避免受到无关信息的负面影响。因此,我们提出了 Context-Drop 的方法,使得当前句子作为输入得到的预测概率分布,和当前句子与上下文作为输入得到的预测概率分布,两者之间的距离尽可能接近,通过 KL 散度来度量两者之间的距离。
我们提出了两种 Context-Drop 方法,一种是 Context-Drop (fixed) 方法,输入 1 是当前句子,输入 2 是当前句子和上下文信息。另一种是 Context-Drop (dynamic) 方法,对于输入 1 和输入 2,上下文中的所有句子,均有一定概率被保留,也有一定概率被舍弃。因此,Context-Drop (dynamic) 方法比较灵活。
此外,我们观察到,尽管标注过程中不同标注员之间的一致性很低,但是投票结果往往是靠谱的。因此,我们考虑 Model Ensemble 的方法。为了保持模型的推理速率,我们提出了 Lightweight Model Ensemble 方法,使用预训练模型 A 的对应参数初始化编码器参数,使用另一个预训练模型 B 的对应参数初始化 pooler 层参数,轻量级地整合不同预训练模型的知识。
实验分析
在英文 AMI 和中文 AMC-A 数据集上,我们进行了多个实验,验证 Context-Drop 和 Lightweight Model Ensemble 方法的表现。
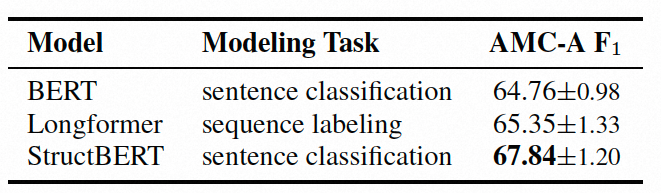
(图示:不同预训练模型及建模方式实验结果)
我们对比了多个预训练模型,以及不同的建模方式。发现 StructBERT 在口语任务上表现较好,这或许因为其 WSO 预训练任务,通过把打乱的 tri-gram 重构为正确顺序,StructBERT 模型对乱序表达的理解力得到改善,而这种乱序表达在口语里是比较常见的。
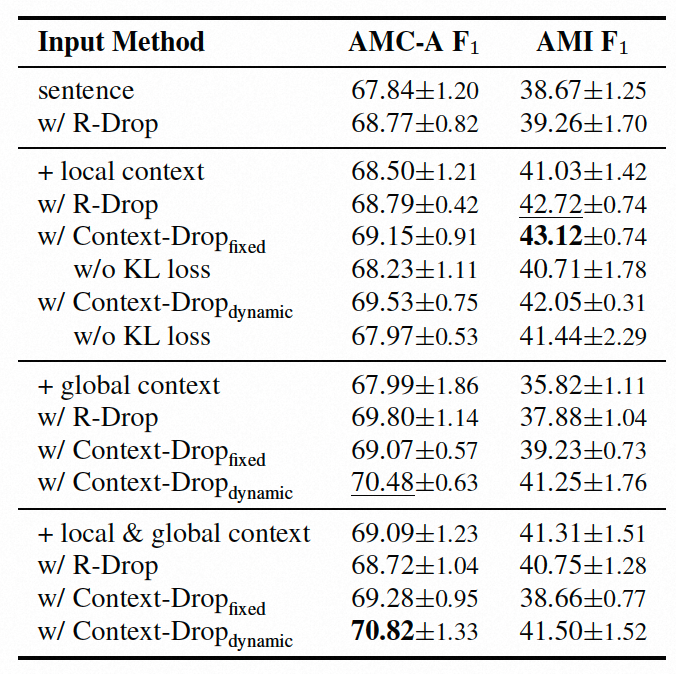
(图示:不同上下文建模方式对比实验结果)
我们发现 sentence + local & global context 的设置,在中英文数据集上都比 sentence + local context 的表现要好。而且,sentence + local context 的设置,均比 sentence 的表现要好。这说明,上下文对于行动项识别任务确实很重要,而且全局上下文可以提供一些局部上下文所不具备的补充信息。
而且,我们可以看到 Context-Drop 比 baseline 的表现更好,而且鲁棒性也有所改善。这验证了我们的假设,Context-Drop 方法可以使得模型更关注于当前句子,利用上下文中的相关信息提升模型表现,并避免受到上下文中的无关信息的干扰。此外,我们发现 Context-Drop (dynamic) 方式通常是表现尚佳的,说明这种更加灵活的对比学习方式可以取得更好的效果。
通过消融实验,我们去掉了 KL 散度正则化的 loss,相当于仅做了数据增强,可以观察到表现的下降,反映了对比学习对于表现提升的重要性。
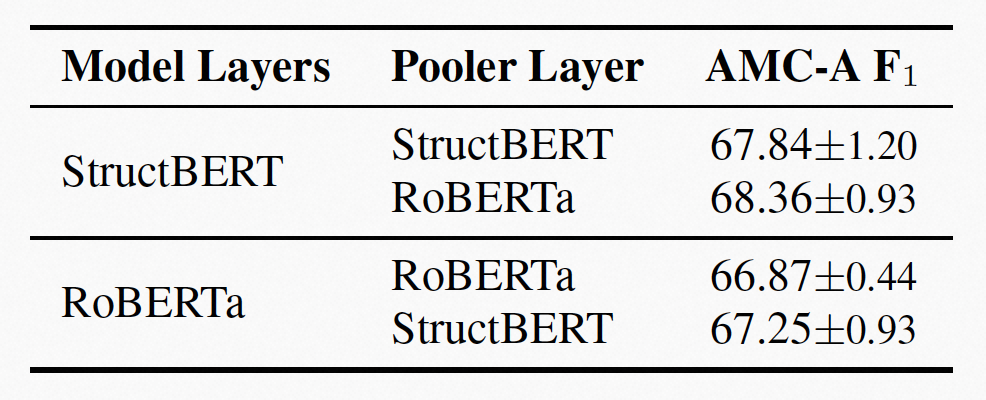
(图示:Lightweight Model Ensemble 实验结果)
通过实验,可以看到,当模型从两个不同的预训练模型进行初始化时,这种 Lightweight Model Ensemble 的方式比传统方式取得了更好的表现。在不增加参数量和计算量的情况下,Lightweight Model Ensemble 方法可以轻量级地整合不同预训练模型的知识。
References:
[1]William Morgan, Pi-Chuan Chang, Surabhi Gupta, and Jason Brenier, “Automatically detecting action items in audio meeting recordings,” in Proceedings of the 7th SIGdial Workshop on Discourse and Dialogue, 2006, pp. 96–103.
[2]Matthew Purver, Patrick Ehlen, and John Niekrasz, “Detecting action items in multi-party meetings: Annotation and initial experiments,” in Machine Learning for Multimodal Interaction, Third International Workshop, MLMI 2006, Bethesda, MD, USA, May 1-4, 2006, Revised Selected Papers, Steve Renals, Samy Bengio, and Jonathan G. Fiscus, Eds. 2006, vol. 4299 of Lecture Notes in Computer Science, pp. 200–211, Springer.
[3]Matthew Purver, John Dowding, John Niekrasz, Patrick Ehlen, Sharareh Noorbaloochi, and Stanley Peters, “Detecting and summarizing action items in multi-party dialogue,” in Proceedings of the 8th SIGdial Workshop on Discourse and Dialogue, 2007, pp. 18–25.
[4]Kishan Sachdeva, Joshua Maynez, and Olivier Siohan, “Action item detection in meetings using pretrained transformers,” in 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021, pp. 861–868.
[5]James Mullenbach, Yada Pruksachatkun, Sean Adler, Jennifer Seale, Jordan Swartz, Greg McKelvey, Hui Dai, Yi Yang, and David Sontag, “Clip: A dataset for extracting action items for physicians from hospital discharge notes,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 1365–1378.
[6]Fan Yu, Shiliang Zhang, Yihui Fu, Lei Xie, Siqi Zheng, Zhihao Du, Weilong Huang, Pengcheng Guo, Zhijie Yan, Bin Ma, et al., “M2met: The icassp 2022 multi-channel multi-party meeting transcription challenge,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6167–6171.
本期撰稿:刘嘉庆,邓憧,张庆林,陈谦,王雯