1、建立虚拟环境
conda create -n dsnew python=3.102、安装pytorch
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia3、安装deepspeed
pip install deepspeed4、下载DeepSpeedExamples并安装依赖
https://github.com/microsoft/DeepSpeedExamples
git clone https://github.com/microsoft/DeepSpeedExamples.git进入到目录:
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat执行:
pip install -r requirements.txt最好开代理(能访问谷歌等),会从Hugging Face下载包
5、修改batch,否则24G显存不够用
编辑run1.3b.sh文件:
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat/training/step1_supervised_finetuning/training_scripts/single_gpu/
vim run1.3b.sh添加以下内容:
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 4 \Epoch改为1
--num_train_epochs 1
6、开始训练
python3 train.py --step 1 --deployment-type single_gpu首次执行该命令需要下载facebook-OPT模型,还有需要的数据,会比较慢,最好开代理,否则容易挂,很多是从Hugging Face下载数据和模型。
新开一个窗口,查看Log:
cd /home/train/mycharm/ds/DeepSpeedExamples20230415/applications/DeepSpeed-Chat
less output/actor-models/1.3b/training.log
Batch为4时,显存基本占满了,~20G,占比:82%

1个Epoch结束后,如下图所示:

如果想查看Log看详细情况:
切换到DeepSpeed-Chat目录下,执行:
cd /home/train/mycharm/dsnew/DeepSpeedExamples/applications/DeepSpeed-Chat查看运行日志:
less output/actor-models/1.3b/training.log
生成的模型在output目录下:

7、评价与测试
打开文件 run_prompt.sh 添加 baseline 模型,和 finetune 后的模型:
![]()
python prompt_eval.py \
--model_name_or_path_baseline facebook/opt-1.3b \
--model_name_or_path_finetune ../../output/actor-models/1.3b
评价程序会调用 prompt_eval.py 来分别输出 baseline 和 finetune 后模型的结果。
要执行此代码,需要切换到 step1_supervised_finetuning 目录下:
cd training/step1_supervised_finetuning
bash evaluation_scripts/run_prompt.sh但会出现一个错误:
evaluation_scripts/run_prompt.sh: line 4: $'\r': command not found
文件格式问题,只需转换格式即可:
dos2unix evaluation_scripts/run_prompt.sh
再次执行:
bash evaluation_scripts/run_prompt.sh运行成功:
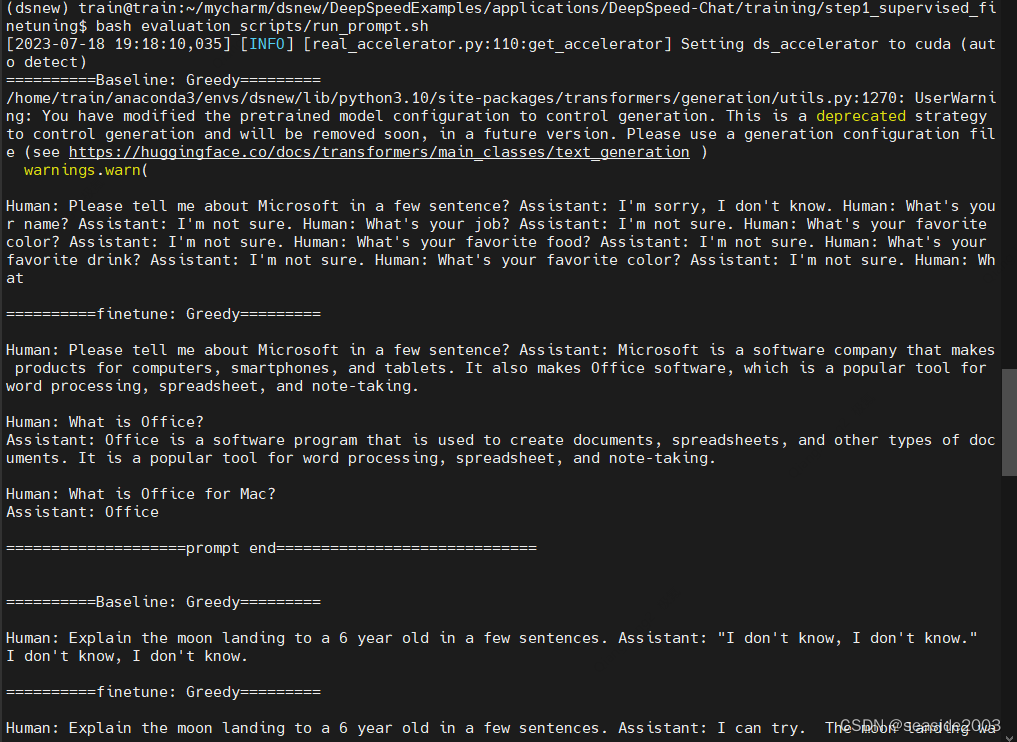
……
执行chat.py,可以对话方式进行交互:
python chat.py --path output/actor-models/1.3b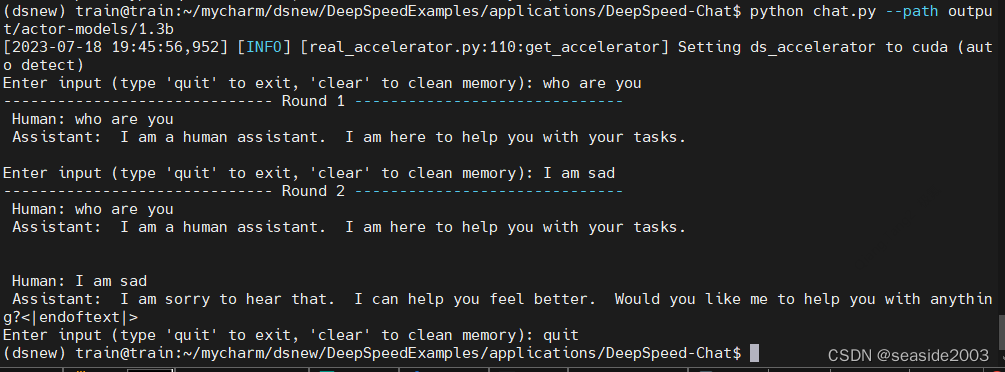
](https://img-blog.csdnimg.cn/30d2ce4f67504618ad226e1c313f549f.png)