MySQL八股学习记录6-日志from小林coding
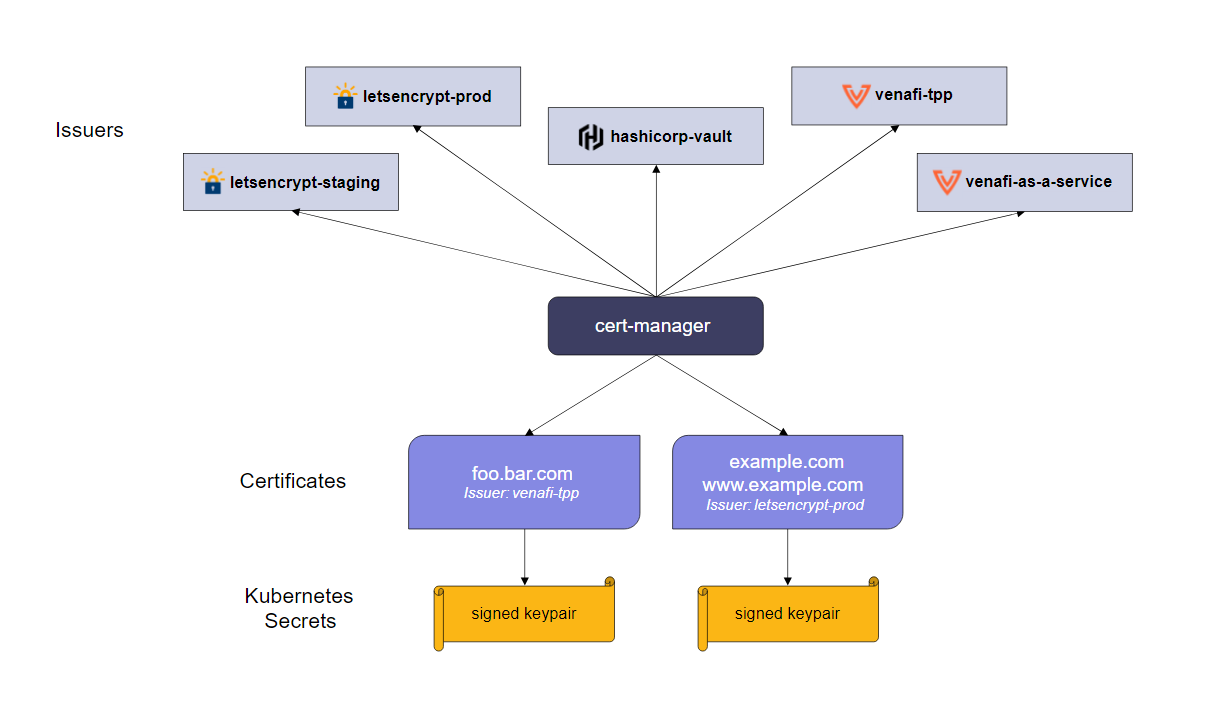
- MySQL日志分类
- undo log
- Buffer Pool
- redo log
- binlog
- redo log 和undo log有什么区别
- 主从复制是如何实现
- update语句执行过程
- 为什么需要两阶段提交
MySQL日志分类
- undo log:InnoDB存储引擎层生成的日志,实现事务中的原子性,主要用于事务回滚和MVCC
- redo log:InnoDB存储层生成的日志,用于事务的持久化,用于掉电等故障恢复
- binlog:server层生成的日志,用于数据备份和主从复制
undo log
执行一条增删改语句的时候,不显式的输入begin和commit开启事务,MySQL也会隐式的开启事务来执行增删改语句
一个事务在执行的过程中,没有提交事务前,MySQL发生崩溃,如何回滚->undo log,保证事务ACID特性中的原子性
- 在插入一条记录时,要把这条记录的主键值记录下来,回滚时删除对应的记录即可
- 删除时,把记录全部记录下来,回滚时,将这些内容插入到表中即可
- 更新一条记录时,旧值记录下来即可
一条记录每一次更新产生的undo log都有一个roll_pointer指针和一个trx_id事务id - 通过trx_id可以知道记录是被哪个事务修改的
- 通过roll_pointer可以将undo log串成一个链表
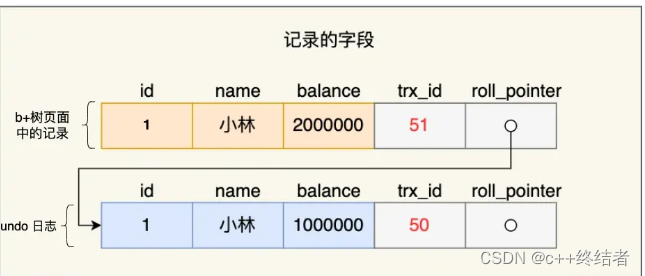
undo log的两大作用: - 实现事务回滚,保障事务的原子性
- 实现MVCC
Buffer Pool
MySQL的数据存放在磁盘中,为了提升数据库的读写性能,InnoDB设计了一个缓冲池
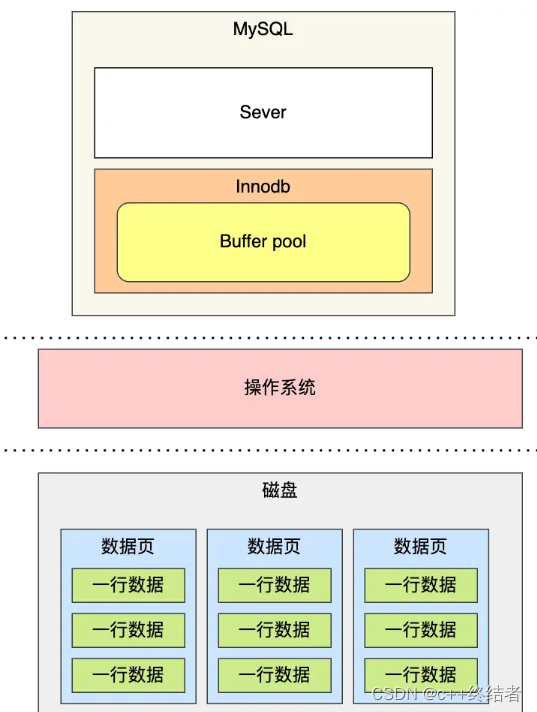
MySQL在启动的时候,InnoDB会为Buffer Pool申请一篇连续的内存空间,按16KB的大小划分出一个个页,Buffer Pool中的页就叫缓存页

redo log
buffer pool提高了读写性能,但是Buffer Pool是基于内存的,内存是不可靠的,为了防止断电导致的数据丢失问题,当有一条记录更新的时候,将对页的修改写道redo log中,这称为WAL技术(Write-Ahead logging)技术.因此,事务提交的时候,只需要将redo log持久化到磁盘即可,redo日志记录的内容是对 XXX 表空间中的 YYY 数据页 ZZZ 偏移量的地方做了AAA 更新
binlog
undo log和redo log两个日志都是InnoDB存储引擎生成的,binlog则是MySQL的server层实现的日志
redo log 和undo log有什么区别
- 适用对象不同:binlog是MySQL的server层实现的日志,所有的存储引擎都可以使用,redo log 是InnoDB存储实现的日志
- 文件格式不同:binlog三种格式STATEMENT,ROW,MIXED
- 写入方式不同:binlog是追加写,写满一个文件,就创建一个新的文件继续写,不会覆盖以前的日志,redo log是循环写
- 用途不同,binlog用于备份,主从复制,redolog用于掉电等故障恢复
主从复制是如何实现
主从复制依赖binlog,记录MySQL上的所有变化并且以二进制形式保存在磁盘上,复制过程就是将binlog中的数据从主库传输到从库上
主从复制三个阶段
- 写入binlog:主库写binlog日志,提交事务,更新本地存储
- 同步binlog:把binlog复制到所有的从库上,每个从库把binlog写到暂存日志中
- 回放binlog:回放binlog,更新存储引擎中的数据
update语句执行过程
- 执行器调用存储引擎的接口,查看是否在buffer pool中,不在的情况下,先读到bufferpool中
- 执行器得到聚簇索引后.看更新前和更新后的数据是否相同,相同不再往下执行
- 开启事务,InnoDB更新前,先更新undo log,并且记录对应的redo log
- InnoDB层开始更新,先更新内存,再将记录写到redo log上,自此一条记录更新完毕
- 更新完之后,记录语句对应的binlog,此时记录的binlog被保存到binlog cache,在事务提交时才将该事务的所有binlog刷新到磁盘
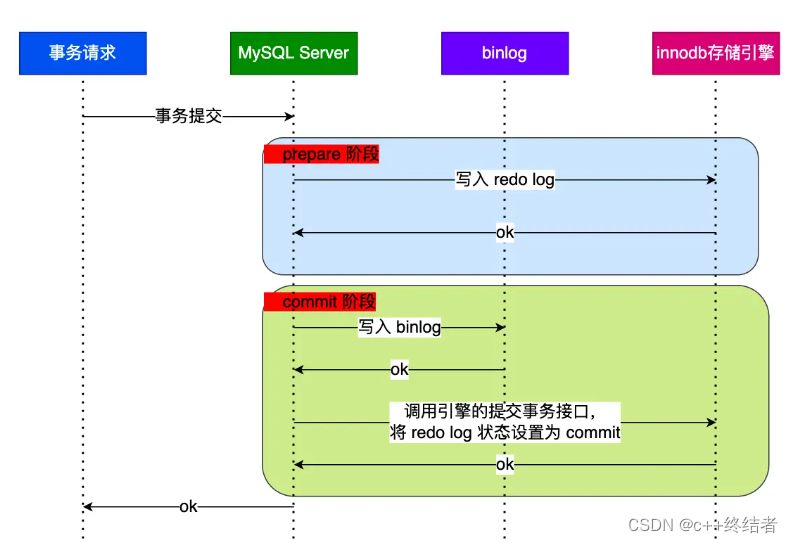
- 事务提交,两阶段更新
为什么需要两阶段提交
为了保证redolog和binlog这两个独立的log日志之间的逻辑日志一致