| 🚀 ShardingSphere 🚀 |
🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀
🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨
🌲 作者简介:硕风和炜,CSDN-Java领域优质创作者🏆,保研|国家奖学金|高中学习JAVA|大学完善JAVA开发技术栈|面试刷题|面经八股文|经验分享|好用的网站工具分享💎💎💎
🌲 恭喜你发现一枚宝藏博主,赶快收入囊中吧🌻
🌲 人生如棋,我愿为卒,行动虽慢,可谁曾见我后退一步?🎯🎯
| 🚀 ShardingSphere 🚀 |


🍔 目录
- 🍀 一.ShardingSphere项目实战集群环境准备
- 🍀 二.水平分表之数据库配置
- 🥦 2.1 需求分析说明
- 🥦 2.2 数据库创建
- 🍀 三.SpringBoot项目中水平分表的配置
- 🥦 3.1 配置文件 - 基本配置
- 🥦 3.2 配置文件 - 数据源
- 🥦 3.3 配置文件 - 配置数据节点
- 🥦 3.4 配置文件 - 配置分片策略(包括分片键和分片算法)
- 🍈 3.4.1 分片键配置
- 🍈 3.4.2 分片算法配置
- 🥦 3.5 配置文件 - 分布式序列配置
- 🍈 3.5.1 UUID
- 🍈 3.5.2 SNOWFLAKE
- 🍀 四.SpringBoot项目相关代码准备
- 🥦 4.1 实体类编写
- 🥦 4.2 编写Mapper
- 🍀 五.水平分表测试
- 🥦 5.1 水平分表测试
- 🥦 5.2 结果查询
- 🍀 六.总结
- 💬 七.共勉
🍀 一.ShardingSphere项目实战集群环境准备
关于项目启动需要提前准备并进行配置的环境我在上一篇文章中做了详细的讲解,如果还有问题的同学可以参考上一篇文章进行学习。
ShardingSphere项目实战集群环境准备
🍀 二.水平分表之数据库配置
🥦 2.1 需求分析说明
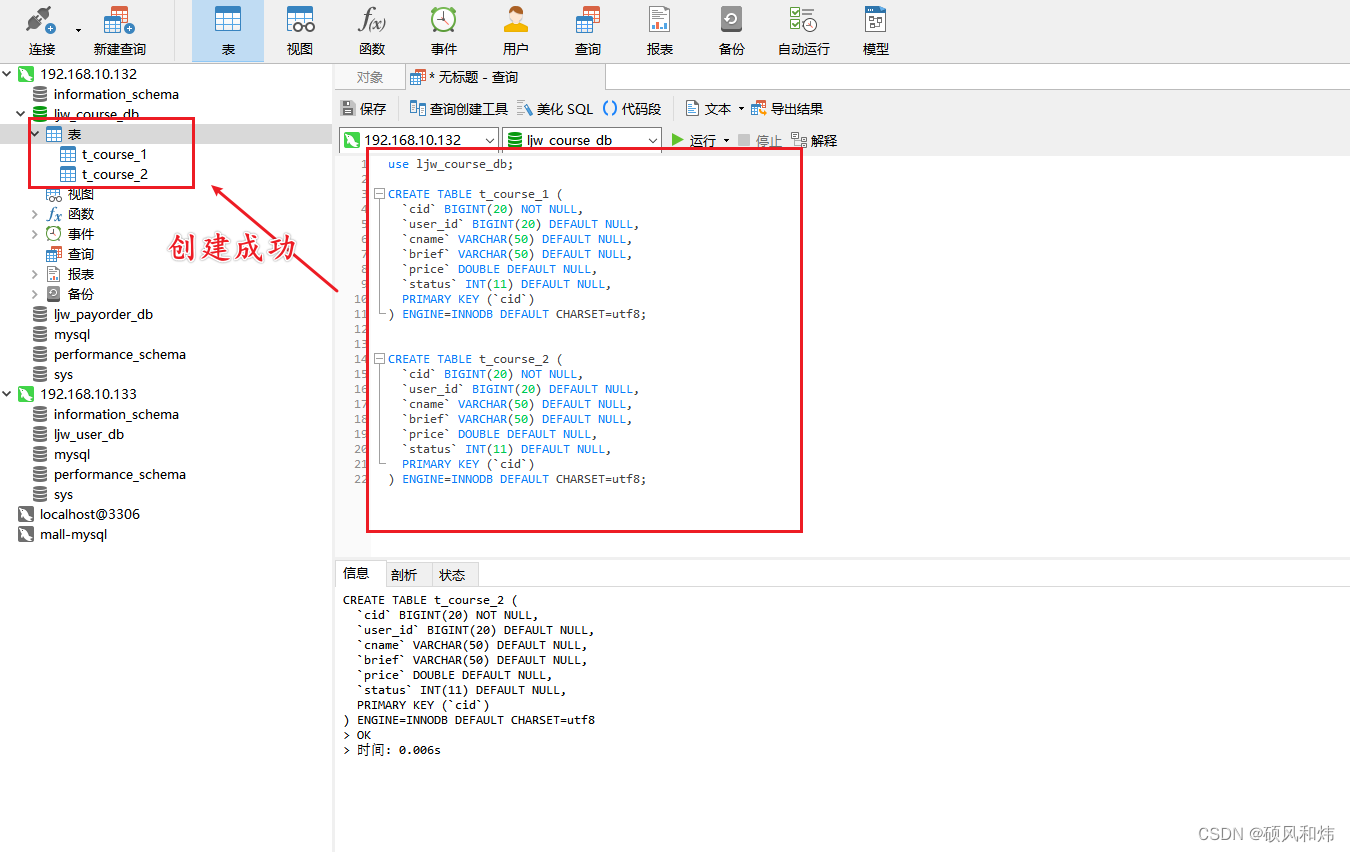
- 在node1-shardingsphere 192.168.10.132服务器上, 创建数据库 ljw_course_db;然后创建表 t_course_1 、 t_course_2;
- 约定规则:如果添加的课程 id 为偶数添加到 t_course_1 中,奇数添加到 t_course_2 中。
🥦 2.2 数据库创建
CREATE TABLE t_course_1 (
`cid` BIGINT(20) NOT NULL,
`user_id` BIGINT(20) DEFAULT NULL,
`cname` VARCHAR(50) DEFAULT NULL,
`brief` VARCHAR(50) DEFAULT NULL,
`price` DOUBLE DEFAULT NULL,
`status` INT(11) DEFAULT NULL,
PRIMARY KEY (`cid`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
CREATE TABLE t_course_2 (
`cid` BIGINT(20) NOT NULL,
`user_id` BIGINT(20) DEFAULT NULL,
`cname` VARCHAR(50) DEFAULT NULL,
`brief` VARCHAR(50) DEFAULT NULL,
`price` DOUBLE DEFAULT NULL,
`status` INT(11) DEFAULT NULL,
PRIMARY KEY (`cid`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
🍀 三.SpringBoot项目中水平分表的配置
sharding-jdbc进行分库分表的配置,主要包括:数据源、分片键、主键生成策略、分片策略等。
注意:项目实战过程中有不熟的概念可以参考对应的官方网站,因为内容较多,本篇文章不做过多详细的说明,包括使用到的很多知识内容,官网开发手册都有更加详细的指导说明。
ShardingSphere开发者手册
🥦 3.1 配置文件 - 基本配置
# 应用名称
spring.application.name=sharding-jdbc-demo
# 打印SQL语句
spring.shardingsphere.props.sql-show=true
# SQL输出日志
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
🥦 3.2 配置文件 - 数据源
# 定义数据源
spring.shardingsphere.datasource.names = db1
# 数据源连接信息配置
spring.shardingsphere.datasource.db1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.db1.driver-class-name = com.mysql.jdbc.Driver
spring.shardingsphere.datasource.db1.url = jdbc:mysql://192.168.10.132:3306/ljw_course_db?characterEncoding=UTF-8&useSSL=false
spring.shardingsphere.datasource.db1.username = root
spring.shardingsphere.datasource.db1.password = root
🥦 3.3 配置文件 - 配置数据节点
表达式 db1.t_course_$->{1..2}
$ 会被大括号中的 {1..2} 所替换, ${begin..end} 表示范围区间
会有两种选择: db1.t_course_1 和 db1.t_course_2

# 标准分片表配置 - 配置数据节点
# 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。
spring.shardingsphere.rules.sharding.tables.t_course.actual-data-nodes=db1.t_course_$->{1..2}
注意:此处使用了行表达式,想深入了解的同学可以参考官网进行学习!
行表达式官方网站学习手册
🥦 3.4 配置文件 - 配置分片策略(包括分片键和分片算法)
分片相关内容官方网站学习手册
🍈 3.4.1 分片键配置
# 分片键名称
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-column=cid
🍈 3.4.2 分片算法配置
在配置分片算法之前,我们做如下的约定:分片规则,约定cid值为偶数时,添加到t_course_1表,如果cid是奇数则添加到t_course_2表。
# 分片算法
# 分片算法名称配置
spring.shardingsphere.rules.sharding.tables.t_course.table-strategy.standard.sharding-algorithm-name=table-inline
# 分片算法类型 --> 行表达式分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.type=INLINE
# 分片算法的属性配置
# 为什么要加1 ? 因为我们约定cid值为偶数时,添加到t_course_1,反之,添加到t_course_2,取余后是0 和 1 ,加 1 就是我们的数据库1 和 数据库2
spring.shardingsphere.rules.sharding.sharding-algorithms.table-inline.props.algorithm-expression=t_course_$->{cid % 2 + 1}
🥦 3.5 配置文件 - 分布式序列配置
分布式主键相关内容官方网站学习手册
🍈 3.5.1 UUID
采用 UUID.randomUUID() 的方式产生分布式主键。
实体类中对应数据库表中的主键ID代码配置
// 省略部分代码
// 核心配置代码
//通过MyBatisPlus生成主键
@TableId(value="cid",type = IdType.ASSIGN_ID)
private Long id;
// 省略部分代码
🍈 3.5.2 SNOWFLAKE
在分片规则配置模块可配置每个表的主键生成策略,默认使用雪花算法(snowflake)生成 64bit 的长整型数据。
雪花算法是由 Twitter 公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
配置文件:
# 分布式序列配置
# 分布式序列的列名
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.column=cid
# 分布式序列-算法名称
spring.shardingsphere.rules.sharding.tables.t_course.key-generate-strategy.key-generator-name=alg-snowflake
# 分布式序列-算法类型
spring.shardingsphere.rules.sharding.key-generators.alg-snowflake.type=SNOWFLAKE
实体类中对应数据库表中的主键ID代码配置
// 省略部分代码
// 核心配置代码
@TableId(type = IdType.AUTO)
private Long id;
// 省略部分代码
🍀 四.SpringBoot项目相关代码准备
🥦 4.1 实体类编写
编写与数据库表对应的实体类
@TableName("t_course")
@Data
@ToString
public class Course {
@TableId(type = IdType.AUTO)
private Long cid;
private Long userId;
private Long corderNo;
private String cname;
private String brief;
private Double price;
private Integer status;
}
🥦 4.2 编写Mapper
@Mapper
public interface CourseMapper extends BaseMapper<Course> {
}
🍀 五.水平分表测试
🥦 5.1 水平分表测试
@Autowired(required = false)
private CourseMapper courseMapper;
@Test
public void testInsertCourse(){
for (int i = 0; i < 30; i++) {
Course course = new Course();
// 注意: cid使用雪花算法配置了(还可以使用MybatisPlus UUID),此处不用配置
course.setUserId(1000L+i);
course.setCname("ShardingSphere");
course.setBrief("ShardingSphere保姆级学习教程!!!");
course.setPrice(99L);
course.setStatus(1);
courseMapper.insert(course);
}
}
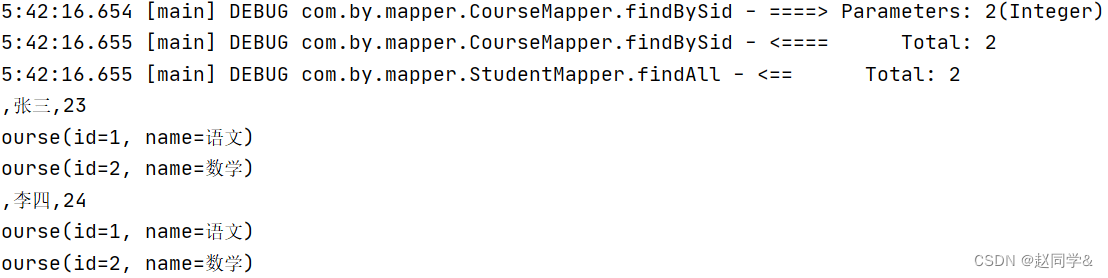
🥦 5.2 结果查询
项目运行成功 !
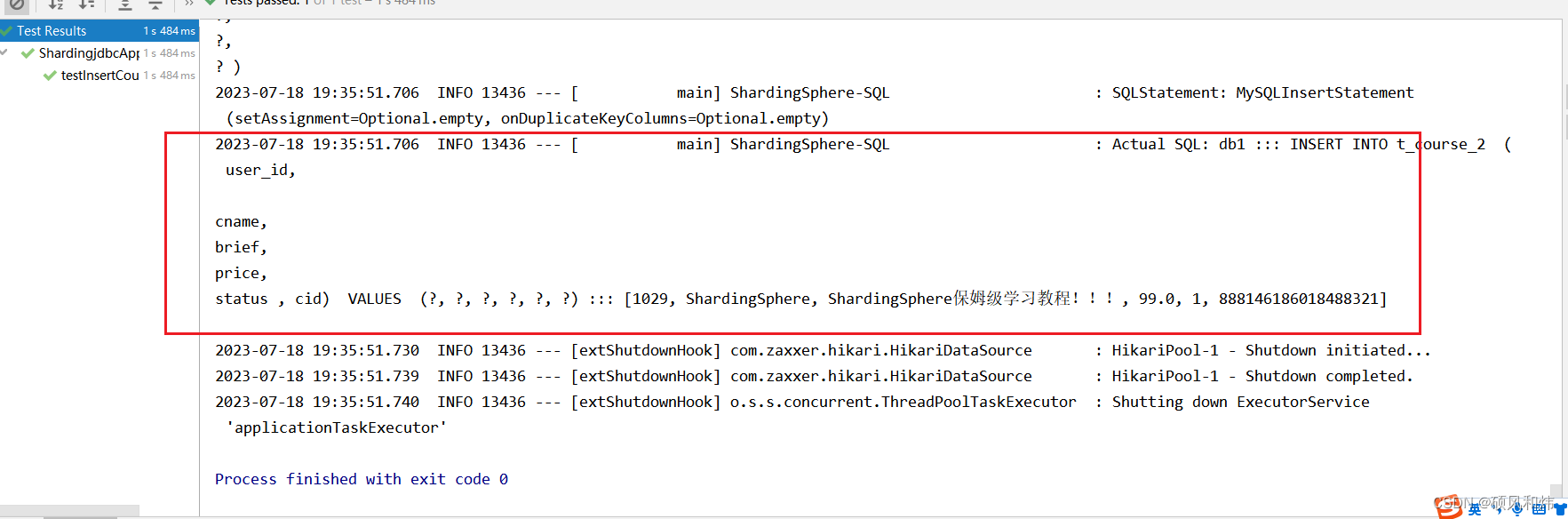
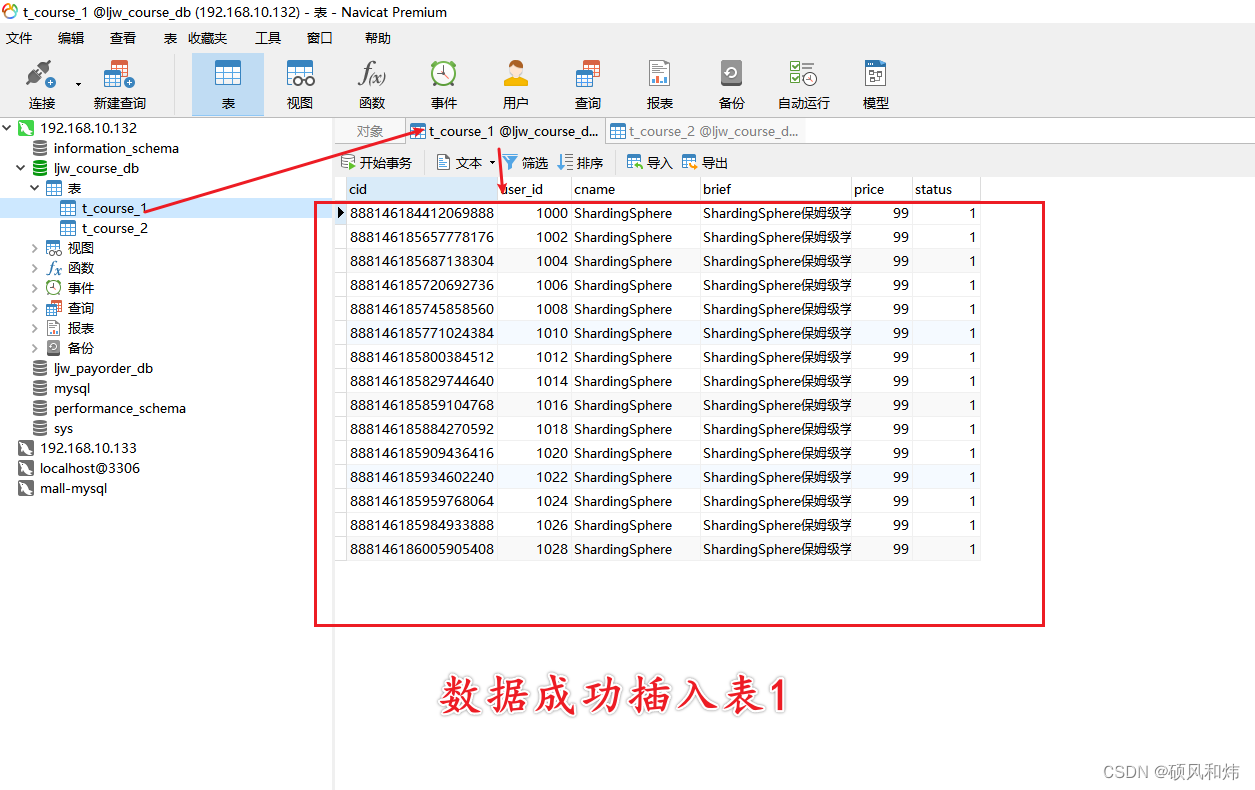
数据成功插到表1 !
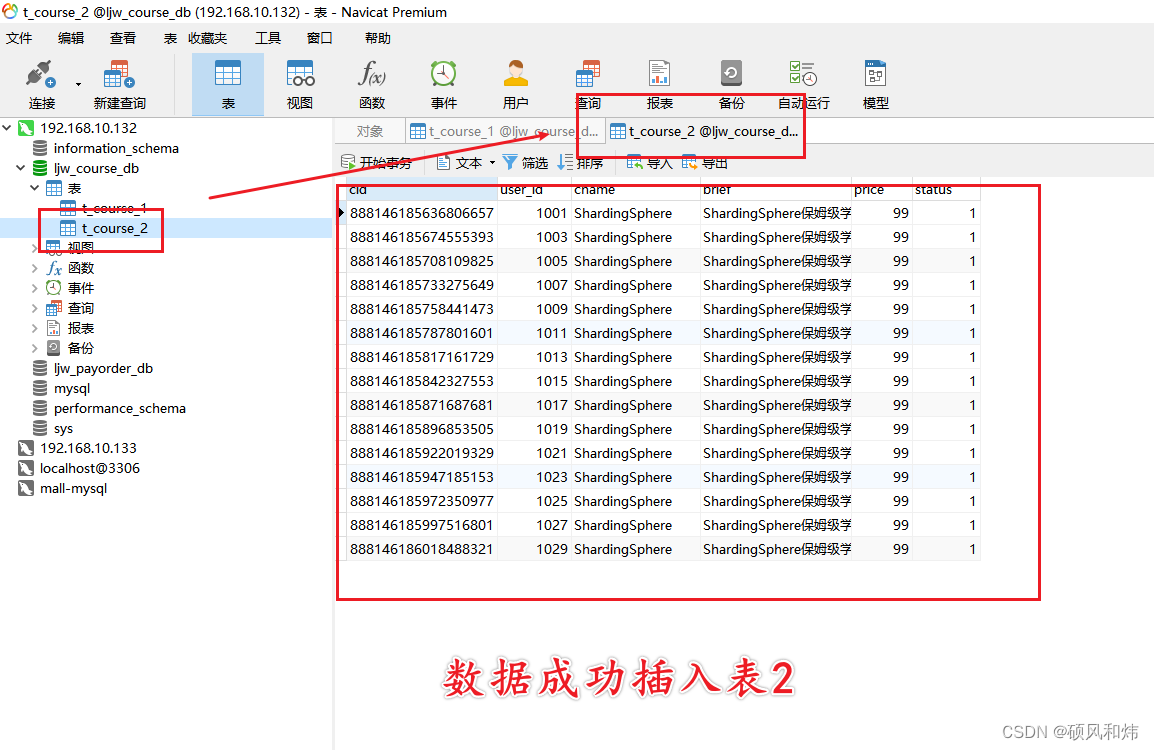
数据成功插入表2 !
🍀 六.总结
本篇文章主要讲解了ShardingSphere分库分表实战之水平分表,下节预告,ShardingSphere分库分表实战之水平分库,敬请期待。
💬 七.共勉
| 最后,我想和大家分享一句一直激励我的座右铭,希望可以与大家共勉! |