文章目录
- 1. 准备工作及知识补充
- 1.1 源文件和Makefile
- 1.2 安装gdb并解决没有调式信息的问题
- debug和release的了解
- 如何解决
- 2. gdb的基本使用
- 2.1 显示代码
- 2.2 设置、删除和查看断点
- 2.3 禁用和启用断点
- 2.4 逐语句和逐过程调式
- 2.5 查看函数调用堆栈
- 2.6 查看指定变量的值
- 2.7 跳至指定行
- 2.8 只执行完当前函数
- 2.9 跳转到下一个断点
- 2.10 修改变量的值
- 2.11 退出gdb
这篇文章我们继续学习Linux中的开发工具。
经过之前的学习,我们已经能够在Linux上编写代码、运行代码和通过git管理代码了。但是如何在Linux上调式代码我们还不知道,所以今天要学的是Linux调试器——gdb 的基本使用。

1. 准备工作及知识补充
那要使用调式器调式,首先我们得有代码,有可执行程序。
1.1 源文件和Makefile
所以,我先来写一个代码,写一下Makefile
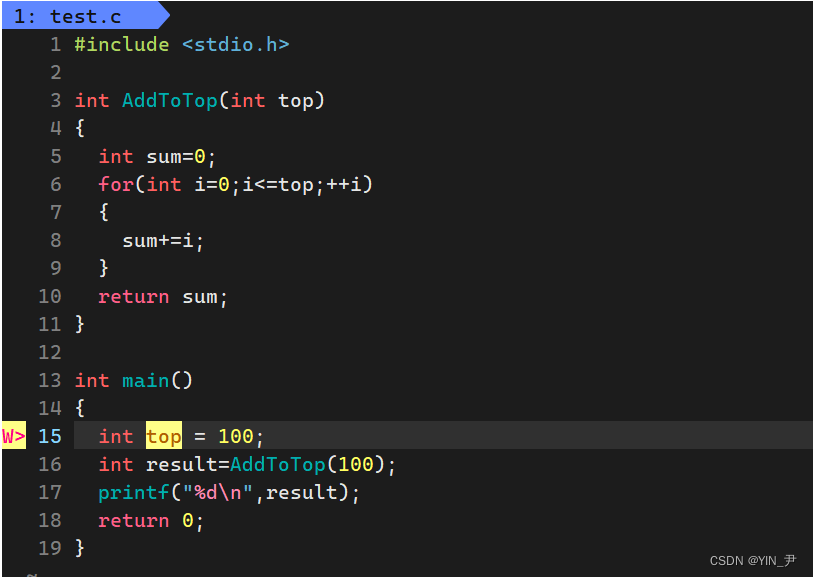
先写一个源文件
test.c
然后写一下Makefile
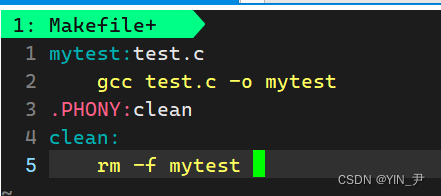
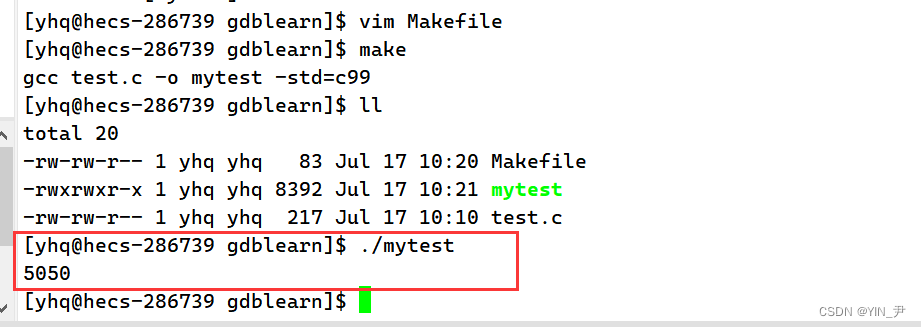
然后我们来编译运行一下:
我们发现报错了
说的是“for”循环初始声明仅在C99模式中允许,即循环变量不能在for循环里面定义
这是因为我们得gcc的版本可能比较低,不支持C99
那怎么让它支持呢?
也很简单,在Makefile里面加一点东西
-std=c99
然后
就可以正常编译运行了


1.2 安装gdb并解决没有调式信息的问题
然后如何调式呢?
我们说了Linux中的调式器是gdb,那如何使用gdb调式
如果你的机器上没有gdb可以先安装一下:sudo yum install -y gdb
然后调式的话,第一步直接gdb+可执行文件名
然后我们输入相应的指令去调式的话,会发现调不成,有一个报错说的是找不到调试符号
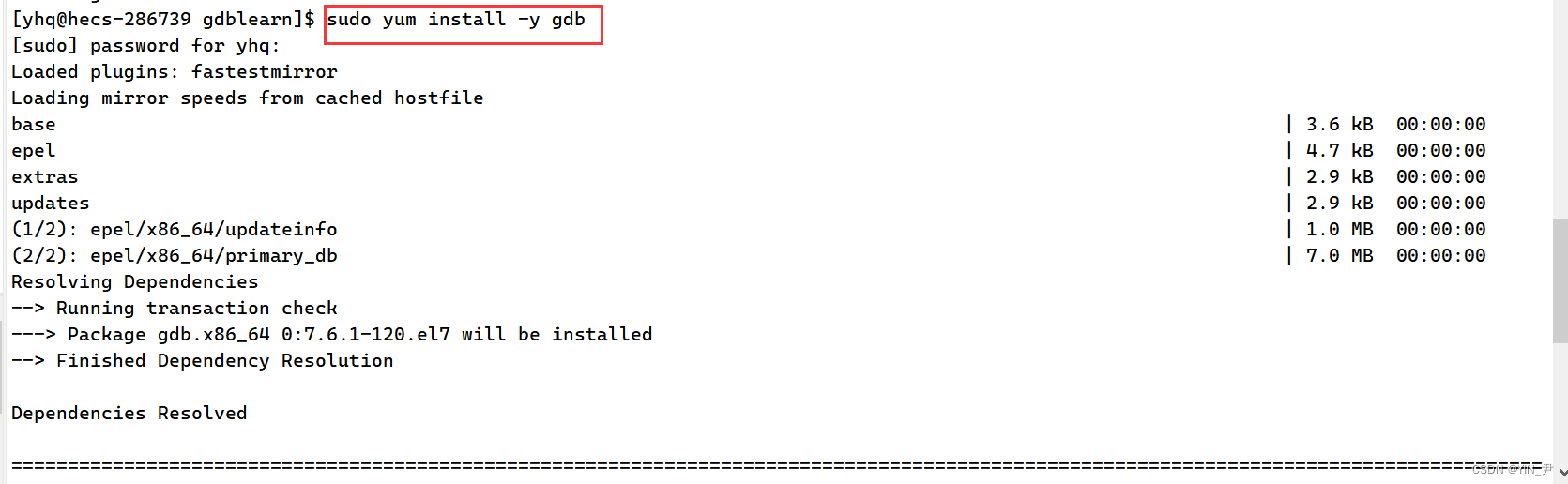
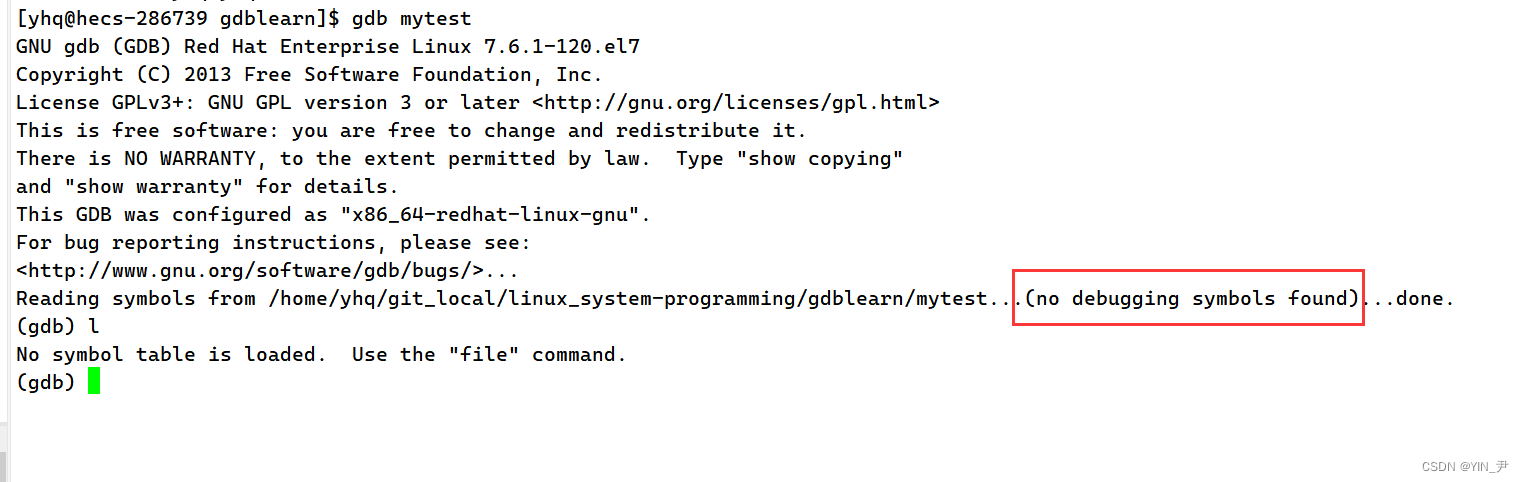
其实就是生成的可执行程序中没有调式信息,怎么回事?又该怎么解决呢?
如果大家平时写C/C++代码用的是vs的话,应该会注意到,在vs上生成程序的时候就有两种模式
debug和release的了解
两者有什么区别呢?
Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序。
Release 称为发布版本,不包含调式信息,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好地使用。
所以我们说调试就是在Debug版本的环境中,找代码中潜伏的问题的一个过程。
"Debug"和"Release"是软件开发过程中常见的两种构建(Build)配置。
Debug(调试)配置:
Debug 配置旨在方便开发人员在代码中进行调试和排查错误。
在 Debug 模式下,编译器会生成带有调试符号信息的可执行文件,这些符号信息包含了变量名、函数名和源代码行号等,以便在调试过程中能够准确地追踪错误。
Debug 配置通常会禁用一些优化,以便在调试过程中能够更好地观察程序的行为。
此配置的构建速度较慢,生成的可执行文件较大。
Release(发布)配置:
Release 配置旨在生成用于最终发布的、优化后的代码。
在 Release 模式下,编译器会对代码进行优化,以提高程序的执行效率和性能。
由于优化的存在,生成的可执行文件可能没有调试符号信息,并且可能会合并和删除一些不必要的代码。
Release 配置通常会启用各种优化策略,例如内联函数、循环展开和减少函数调用开销等,以提高代码的执行速度和资源利用率。
此配置的构建速度较快,生成的可执行文件较小。
在实际开发中,通常会使用 Debug 配置进行代码的开发、调试和测试,以便于快速定位和修复问题。而在准备发布软件时,会切换到 Release 配置,以生成性能更高、体积更小的最终可执行文件。
那在Linux上gcc/g++编译生成的可执行程序其实默认是release版本的,不包含调式信息,所以我们无法调式!
如何解决
那如何让它以debug版本生成呢?
很简单
gcc/g++编译的时候加一个-g就行了
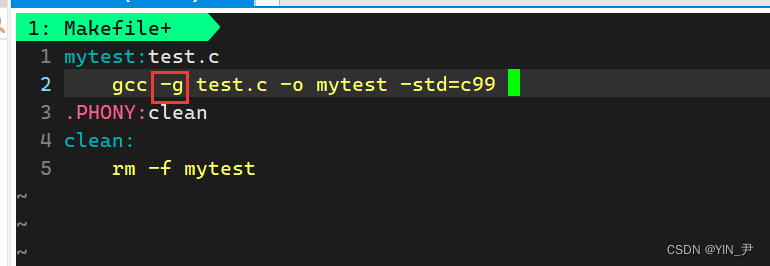
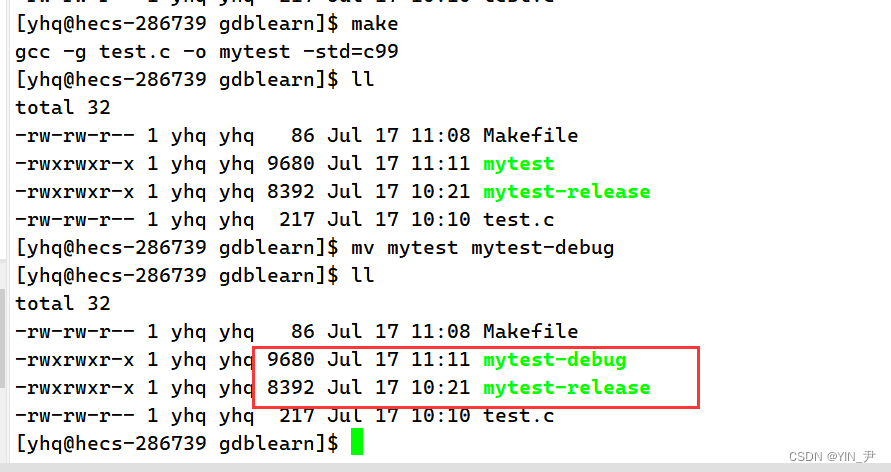
那为了以示区分,我把release版本的重命名一下
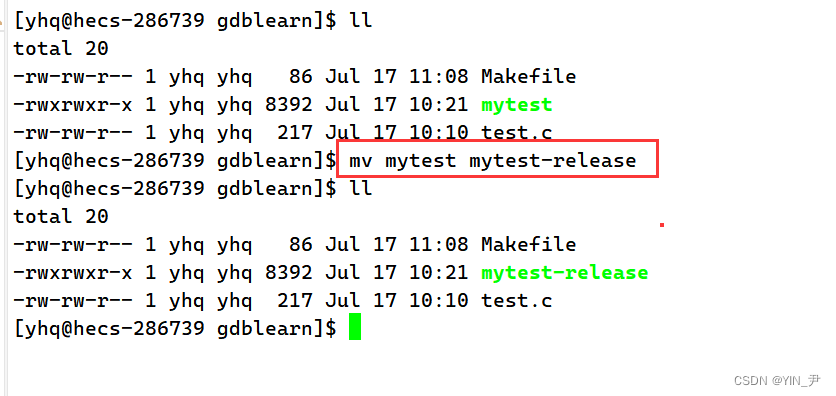
然后我们生成debug版本的,也重命名一下
那这里我们其实就能看到debug和release版本生成的可执行程序大小的差异。
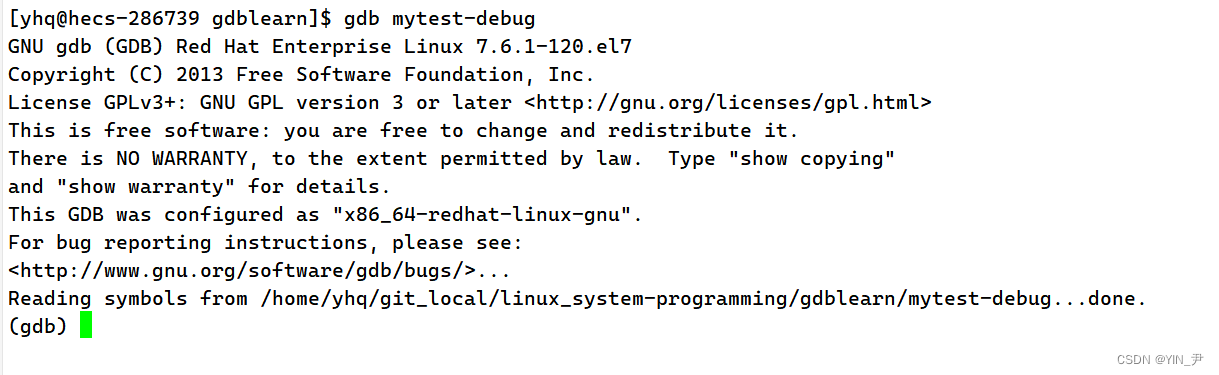
那我们用gdb调式debug版本的话就不会出现刚才的报错信息了:
那具体调式要怎么做呢?
接下来我们就来学习一下,gdb中常用的调式操作所涉及的命令
2. gdb的基本使用
2.1 显示代码
那调式的时候,首先我们得能看到代码啊
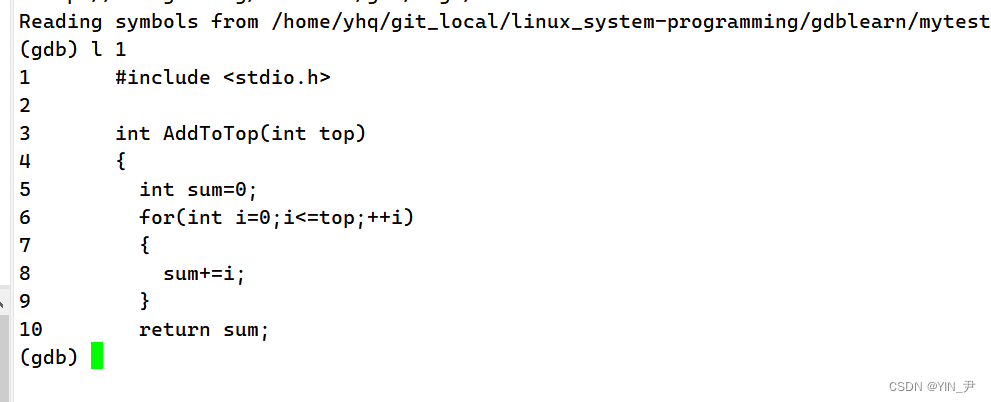
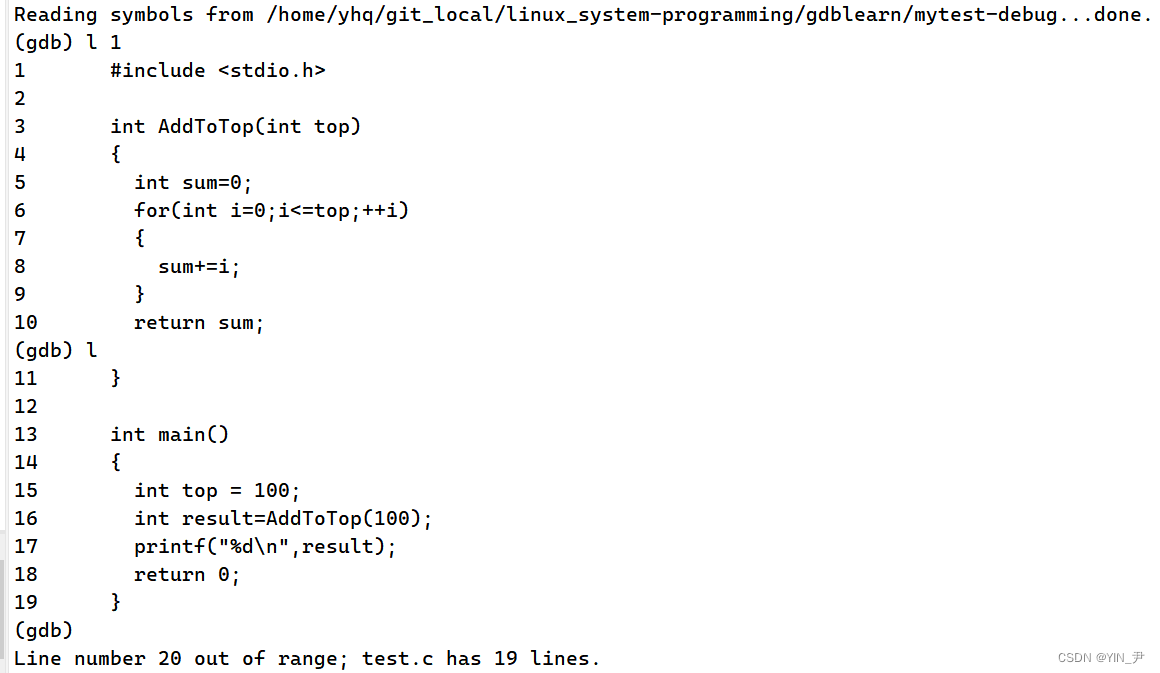
打开调式是这样的,那我们想看看代码怎么做?
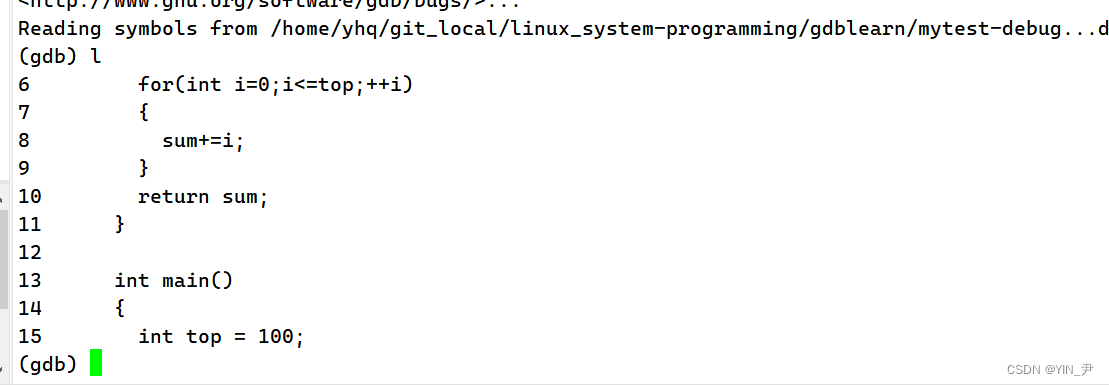
l(list)+行数:就可以从指定行开始显示代码,一次默认显示10行
然后后面我们只输l或者直接按回车键(因为gdb会记录你最近一次敲的命令)就可以继续往下显示
如果第一次只输l的话,随机从某一行开始显示
2.2 设置、删除和查看断点
那我们调式一般要设断点:
如果你不设断点直接就运行结束了
r(run):开始调式
不设断点直接调式的话就直接运行完了

那如何设断点呢?
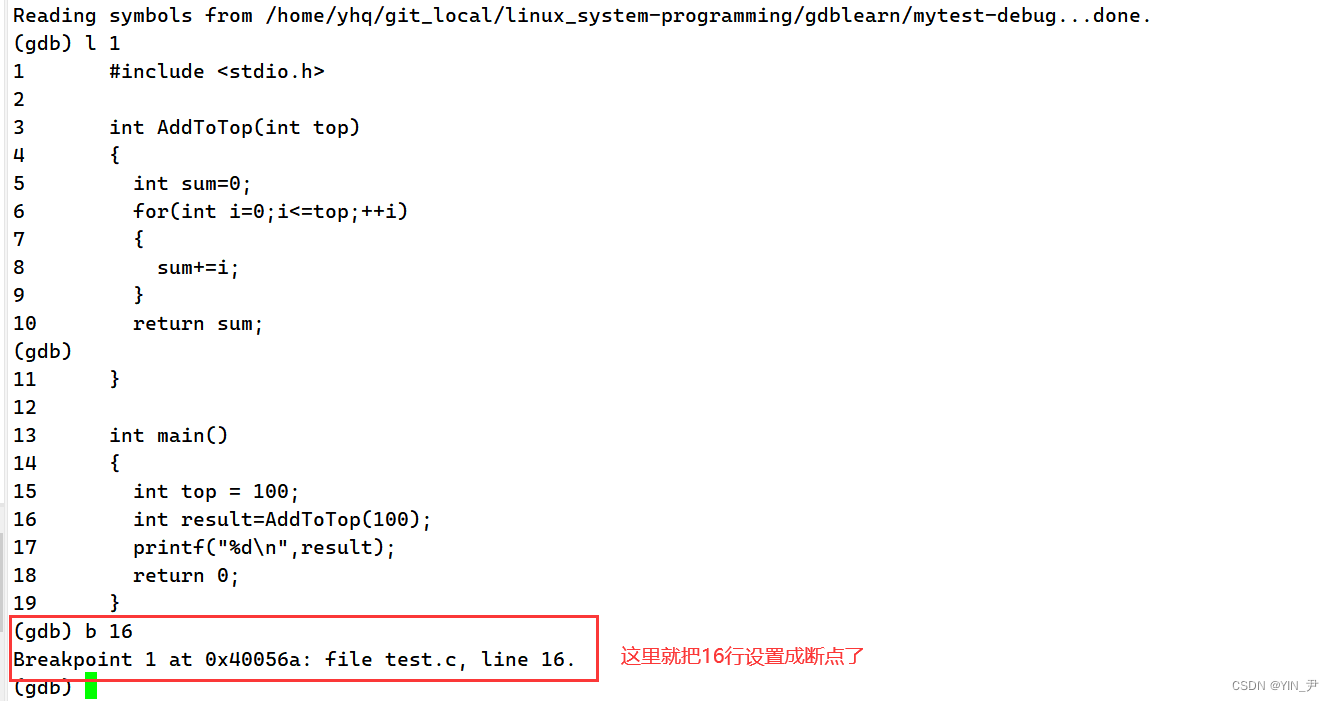
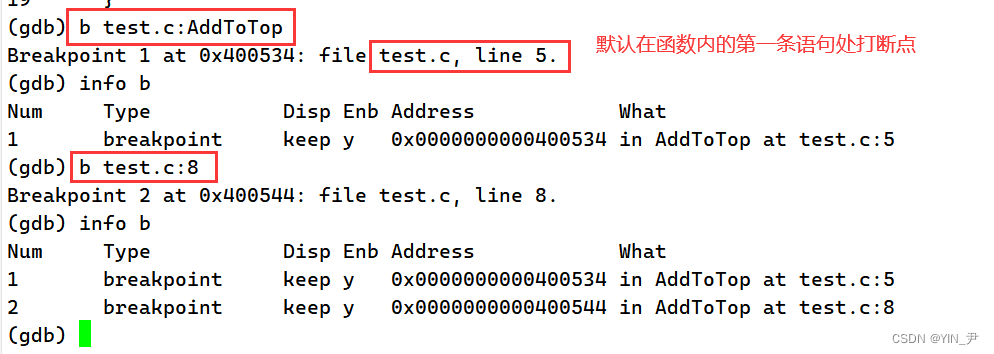
b(break point)+ 行号/函数名:就可以把指定行或指定函数(打在函数内第一条语句处)设置为断点
如果是多文件的话,我们还可以指定文件去给对应的函数或指定行打断点
b 文件名:行号/函数名
(其实查看那里也可以这样来指定)
那设置好我们要查看断点,怎么查看呢?
这可不跟vs上一样,直接有一个红点标记
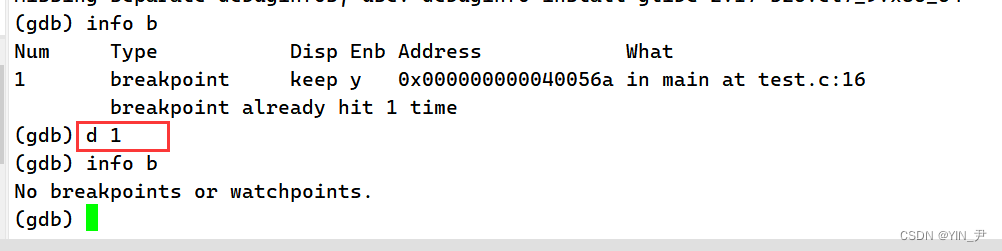
info b:查看断点
这里的num是断点的编号,what就是断点的位置,在哪一个文件哪一行。
那有了断点,我们在开始调式的话,当然就会在断点处停下了


那如何删除一个断点呢?
d(delete)+ 断点编号:删除对应的断点(注意不是行号,而是上面提到的编号)
直接d就是删除所有断点

2.3 禁用和启用断点
对于断点呢还有一个比较冷门的操作,禁用和启用断点:
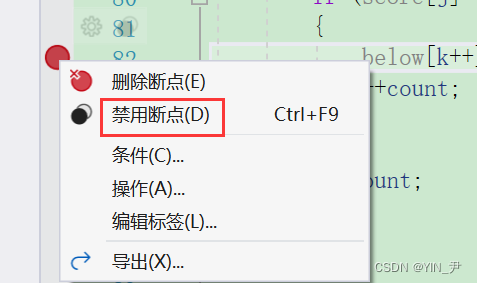
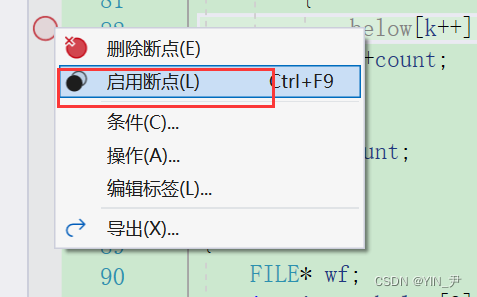
vs上也有对于对应的操作
禁用的话就是不删除这个断点,但让这个断点失效,启用就是让它重新生效。
那在gdb上如何进行对应的操作呢?
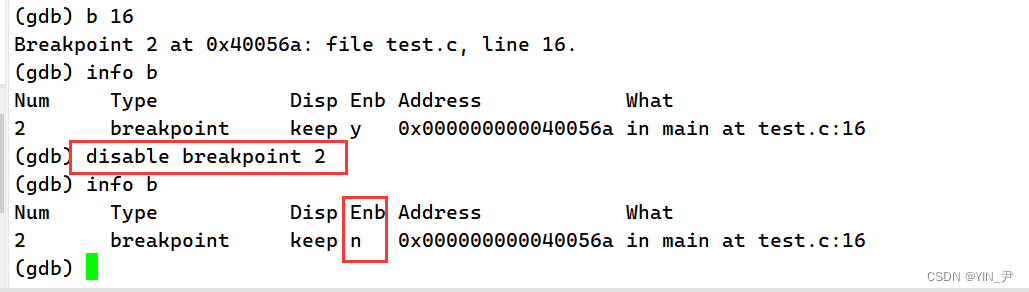
大家看这个:
我们还是把16行设置成断点,然后我们查看的时候,第4列的信息enb(enable breakpoints)如果是y,就表明当前断点是启用状态。
那如果不想删除它,把它设置成禁用,该怎么做呢?
disable breakpoints 断点编号:禁用断点
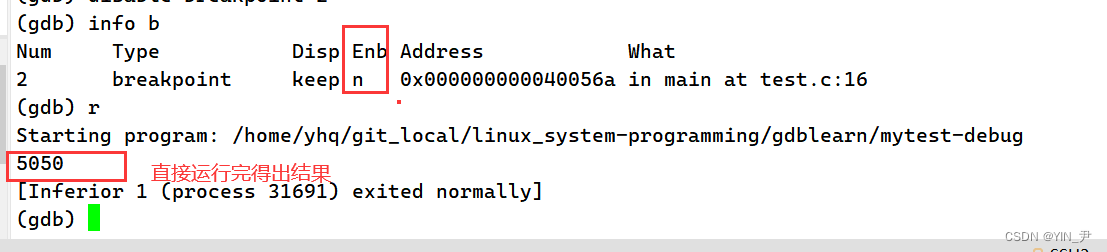
然后enb就变成了n,就说明被禁用了
此时如果我们开始调式,它是不会起作用的:
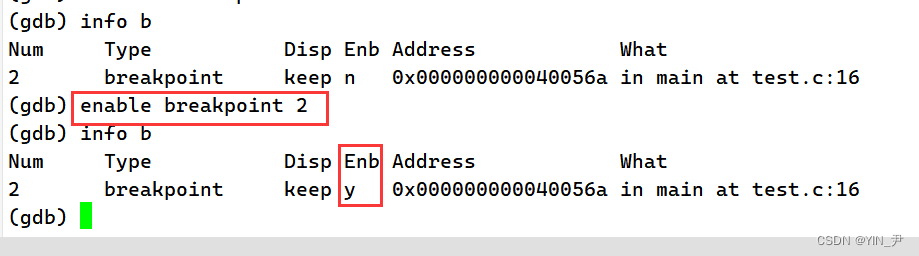
那如果想启用呢?
enable breakpoints 断点编号:启用断点

2.4 逐语句和逐过程调式
我们平时用vs调式的时候,常用的其实就是逐语句和逐过程:
逐过程其实就是一句一句往下执行,遇到函数调用也直接一次就走完了;而逐语句与逐过程的区别就是碰到函数的话会进入到函数体内。
那在gdb中与之对应的操作是什么呢?
首先逐过程:
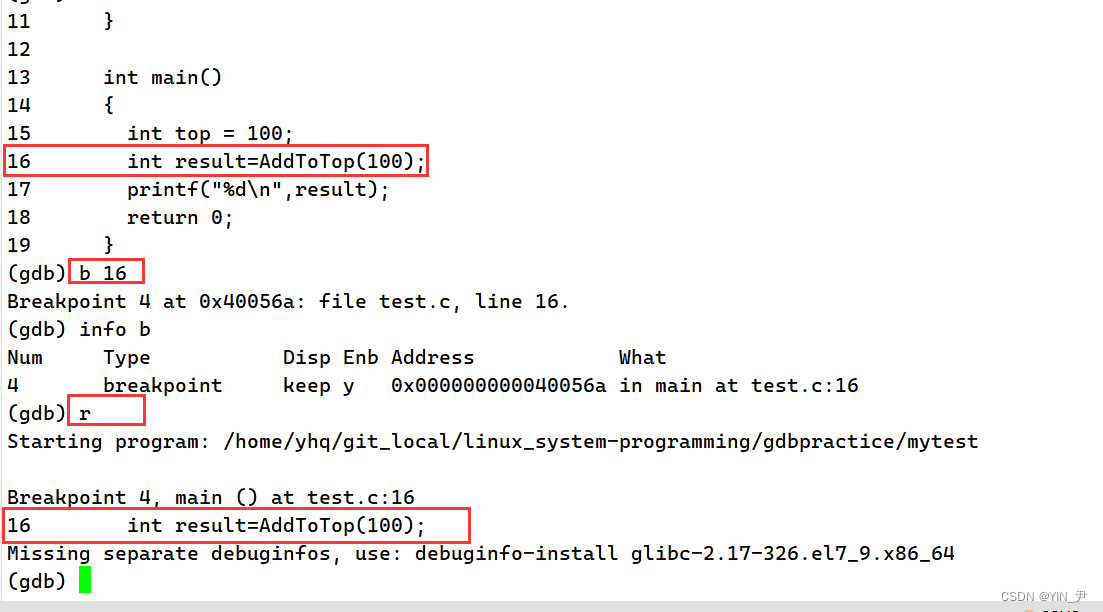
开始调式,到16行的断点就停止了,对应的是一个函数调用。
如果我想逐过程,直接走到下一句代码呢?
n/next:逐过程
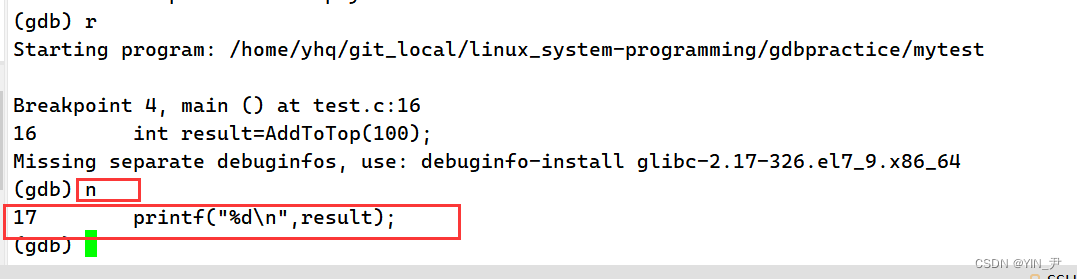
那逐语句呢?
我们重新开始调式
然后又停到了第16行
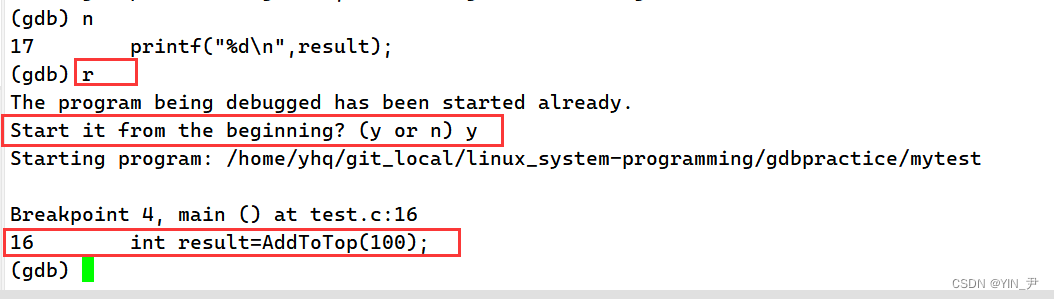
那我现在想进入函数怎么做?
s(step):逐语句(遇到函数会进入)

2.5 查看函数调用堆栈
vs上我们调用一些函数的时候可以通过函数调用堆栈查看它们的调用关系:
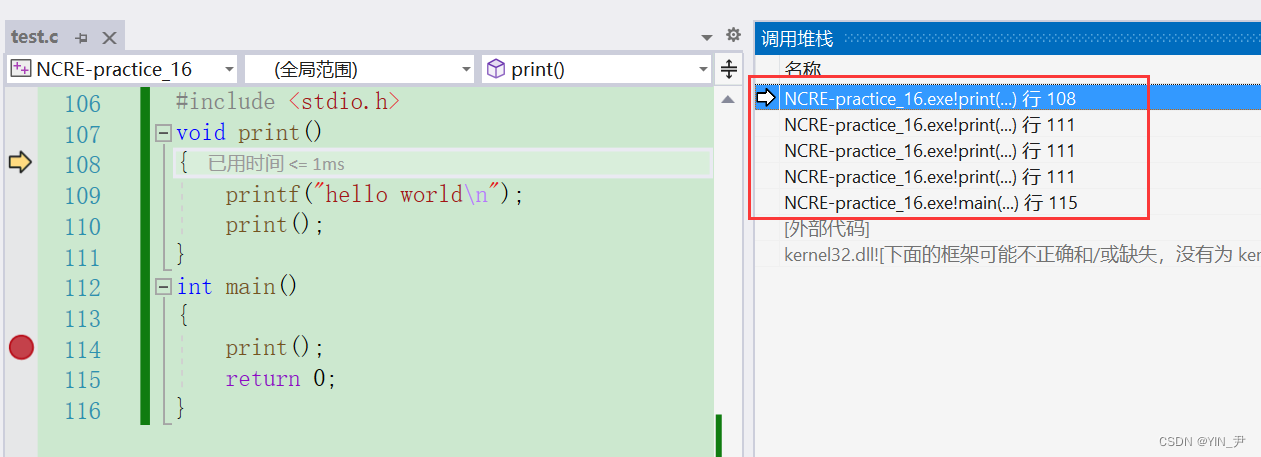
那在gdb上如何查看?
breaktrace/bt:查看函数调用堆栈
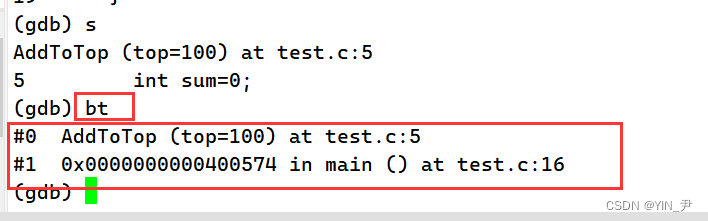
2.6 查看指定变量的值
那我们调式不是光一步步执行,重要的是在调式的过程中观察某些变量的值的变化是否和我们预想的一样,从而找出问题。
vs上可以通过监视窗口查看:
那gdb呢?
p(print)变量名:查看变量的值
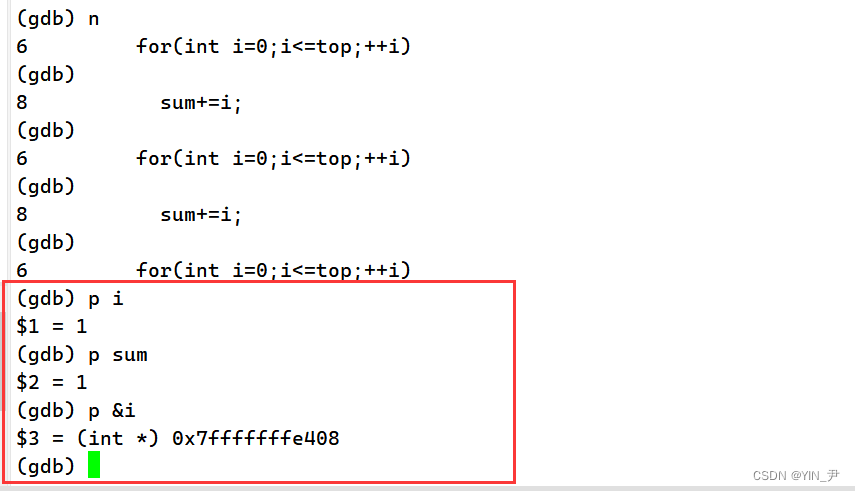
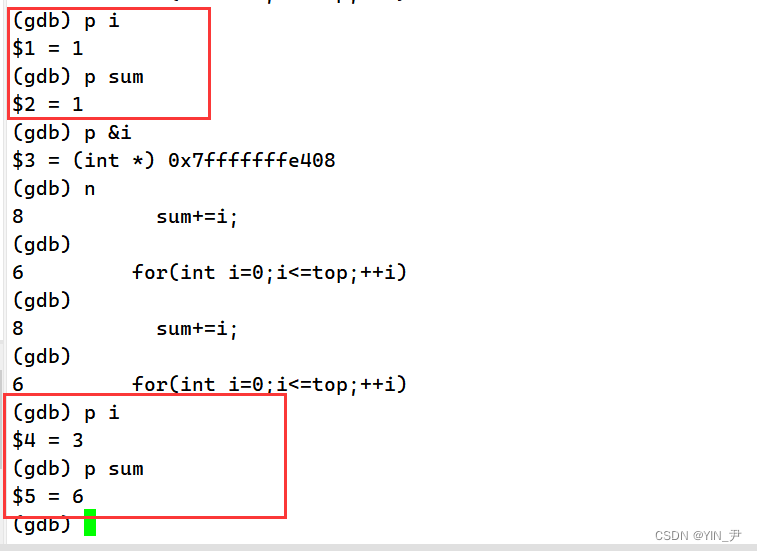
但是,这样好像有点挫啊,我们敲一次,它显示一次,不敲,下一条语句就不显示了。
那怎么让它一直显示,使得在程序执行的过程中我们可以观察变量的变化呢?
display 变量名:常显示对应变量的值(内置类型和自定义类型均可)
这样每走一步,我们都能看到变量值的变化。
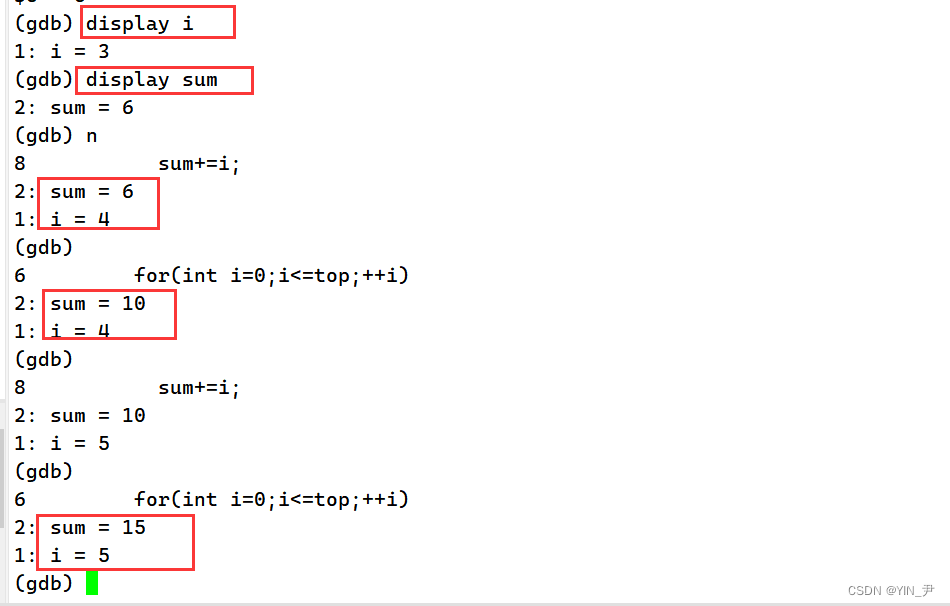
那现在是常显示,如果执行到某一步我不想让它显示了,怎么取消呢?
undisplay 变量编号:取消对应变量的常显示
注意这里不是跟变量名,而还是它们对应的编号

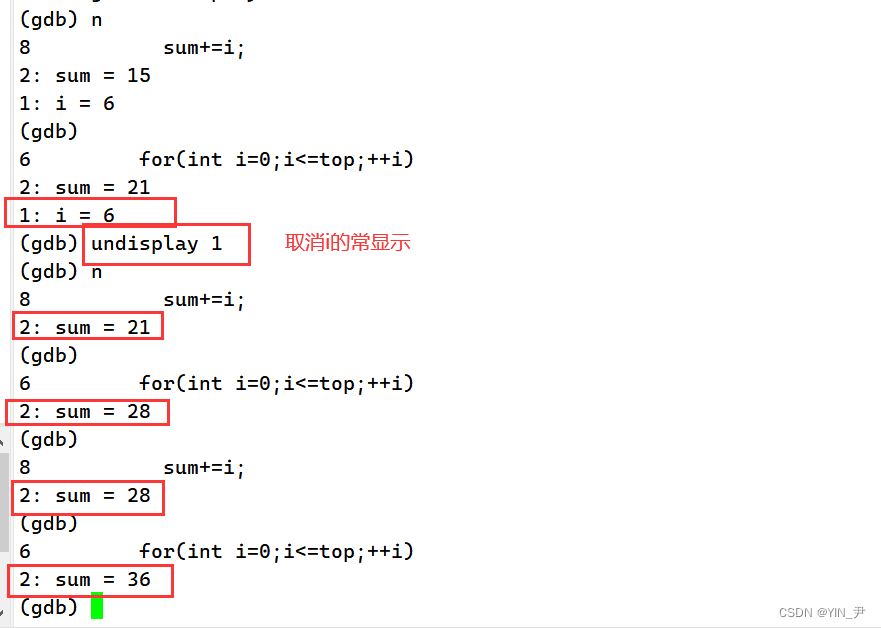
2.7 跳至指定行
现在我们的这个函数的循环还没执行完:

才执行到i等于8,那现在如果我们单步执行的话他肯定还是一直在这循环,那我想直接让它跳转到循环结束,后面的第10行位置,能做到吗?
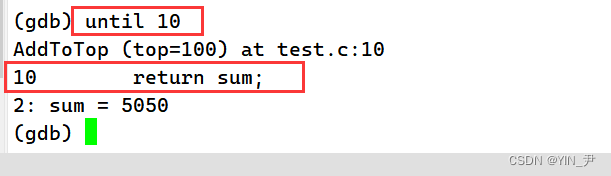
是可以的
until 行号:跳至指定行
此时,程序就直接执行到第10行了。
2.8 只执行完当前函数
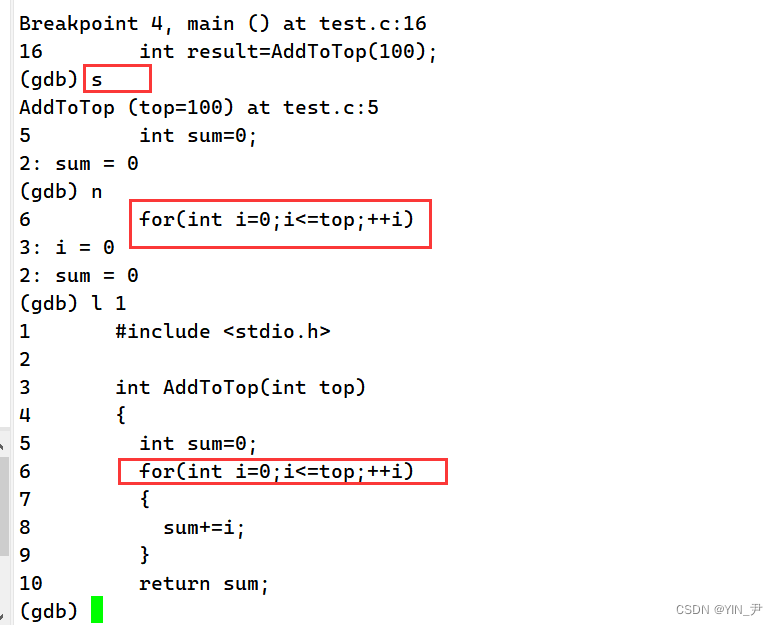
再来看一个:
我现在又进入到了这个函数里面
那我现在想让这个函数直接执行完,然后停下了
那就是finish:执行到当前函数返回,然后停下来等待命令
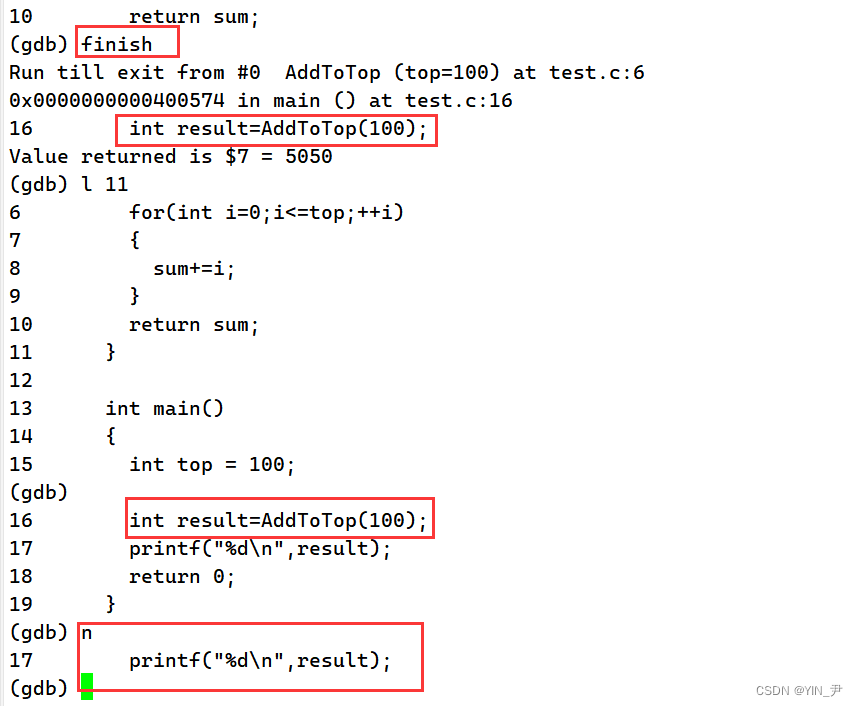
2.9 跳转到下一个断点
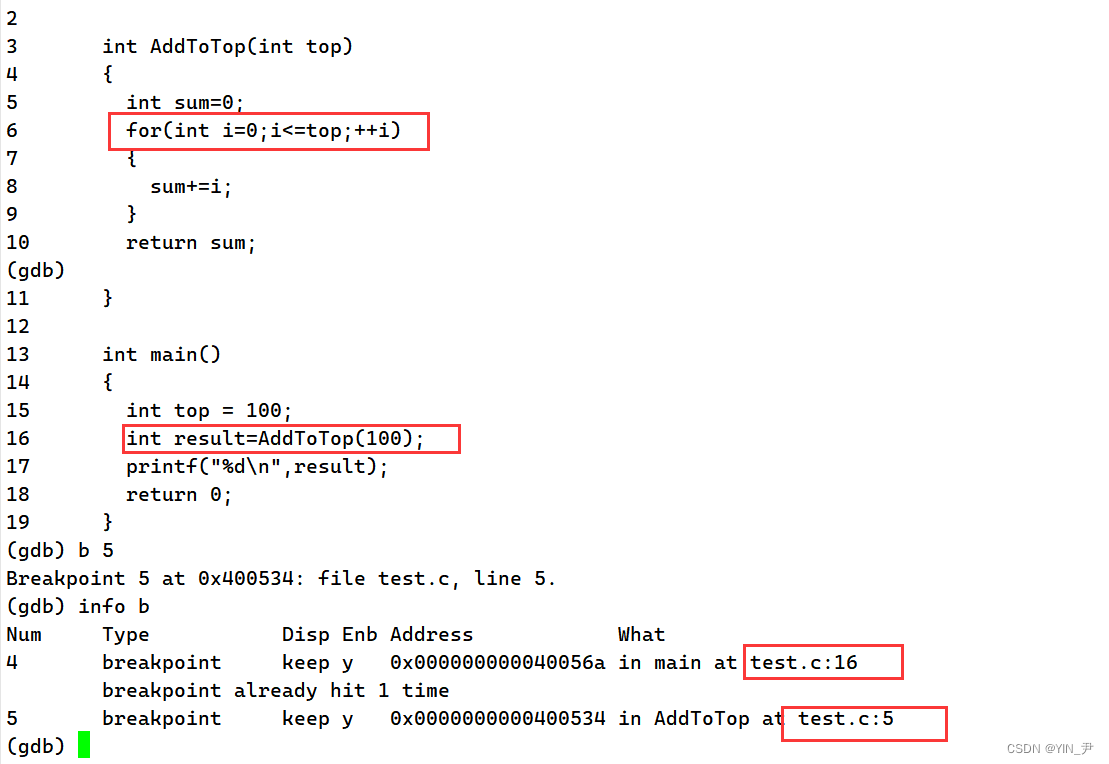
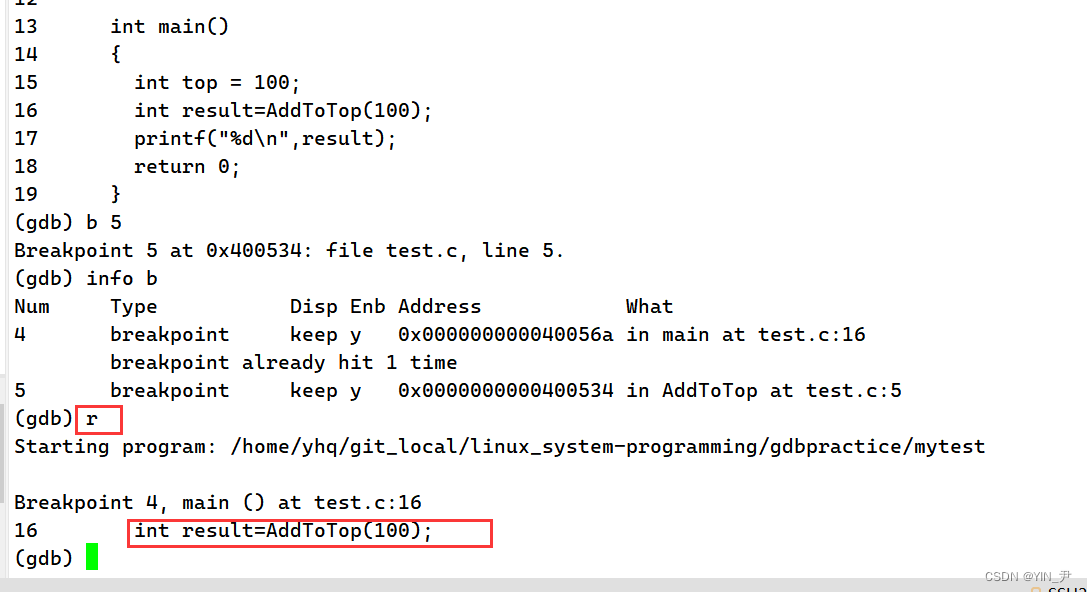
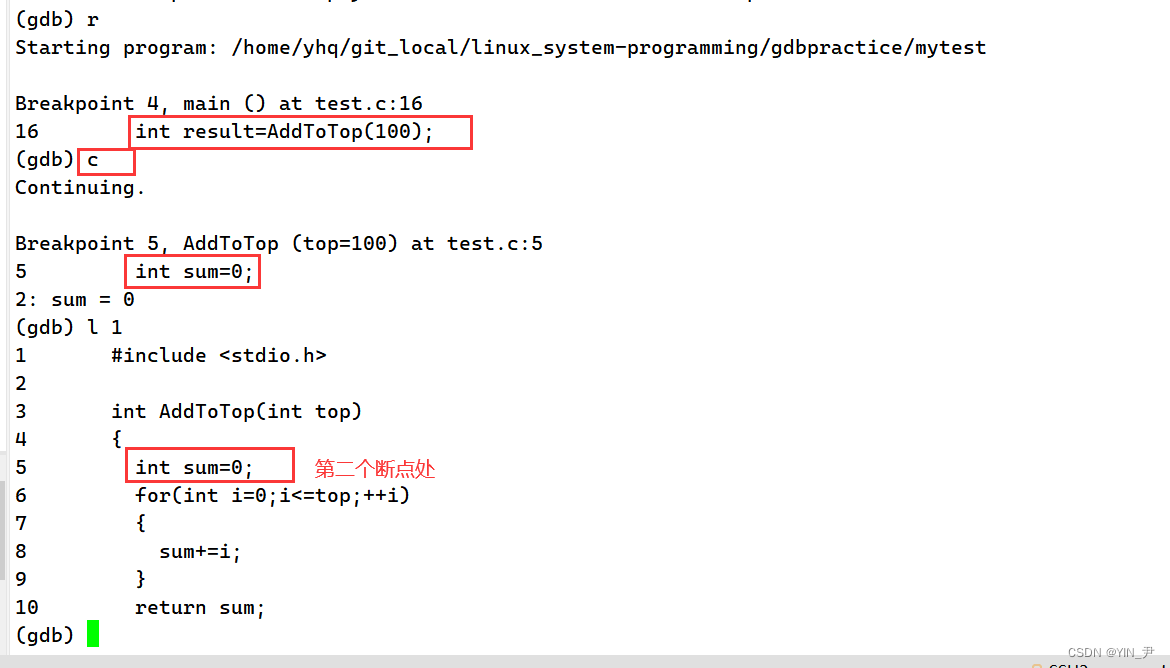
c(continue):从当前位置执行到下一个断点停下来,后面没有断点则直接到程序结束
我现在设了两个断点
现在重新开始调式程序
现在它停在了第一个断点处,我想让它直接跳到下一个断点:
2.10 修改变量的值
set var 变量名=值:修改变量的值
然后循环到10就结束了

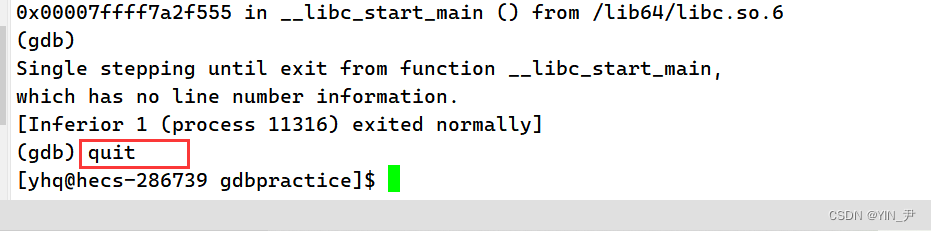
2.11 退出gdb
quit:退出gdb