引语:
在Java开发中,我们更希望数据库能直接给我们必要的数据,然后在业务层面直接进行使用,所以写一个简单的sql语句有助于提高Java开发效率,本文由简单到复杂的小白吸收,还请多多指教。
使用MySQL数据库,先创建一个简单的表
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age INT NOT NULL,
email VARCHAR(100) NOT NULL
);
开始玩吧,先看原始数据
-- 初始
SELECT * from `user`
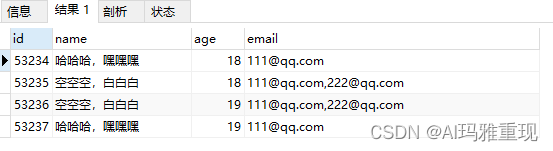
以上原始数据,是我们开始的关键,现在有需求,要拿到所有人的name
-- 添加concat返回的是list<String>
SELECT CONCAT(`name`)
from `user`
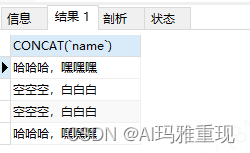
但是我们需要的是一个结果,而不是list的,所以这里要用group_concat
-- 使用group_concat, 一个字符串,形式是:["哈哈哈,嘿嘿嘿","空空空,白白白","哈哈哈,嘿嘿嘿","空空空,白白白"]
SELECT GROUP_CONCAT(`name`) as result
from `user`
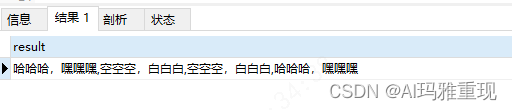
我们可以看到结果已经是一个字符串了,但是有重复,我们这里加上去重
-- 根据业务场景,看似满足需求了,的确去重了,结果形式:["哈哈哈,嘿嘿嘿","空空空,白白白"]
SELECT GROUP_CONCAT( DISTINCT `name`) as result
from `user`
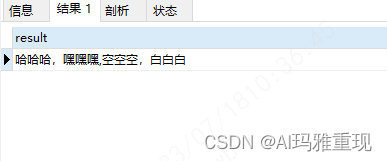
然后拿到目标值啦,发现返回数据没有问题,但是不能直接利用,若想直接想通过正则切分字符串使用,但是切分出来的结果,第一个是:[“哈哈哈,嘿嘿嘿”,最后一个是:“空空空,白白白”],但是我又不想在业务层处理这个 ‘[’ 和 ‘]’,所以sql继续升级,先去掉结果中的 [ ],这里使用replace(字符串结果,要去掉的‘[’,‘成为空字符串’)
SELECT REPLACE(GROUP_CONCAT( DISTINCT `name`),'[','',']','') as result
from `user`

但是报错了 check the manual that corresponds to your MySQL server version for the right syntax to use near ‘,’]‘,’') as result,我数据库版本不支持,所以用下面的sql
-- 使用以下这个版本
SELECT REPLACE(GROUP_CONCAT( DISTINCT `name`),'[','') as result
from `user`
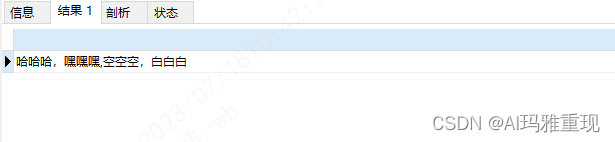
上面的sql只是先去掉了 ‘[’,继续加replace函数,去掉 ‘]’,如下
-- 但是业务层只能拿到 哈哈哈,嘿嘿嘿,因为 "空空空,白白白"] 这里的 ]还没有处理,那就再加一个replace
SELECT REPLACE(REPLACE(GROUP_CONCAT( DISTINCT `name`),'[',''),']','') as result
from `user`
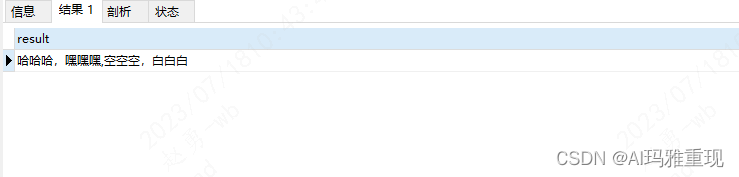
直观看的话,数据库展示的数据已经是我们想要的,但是不对,因为我们的value中的形式:“xxx,xxx”,“xxx,xxx”,并不能直接丢出来使用,还需要对结果进一步处理,使用 SEPARATOR 切分
-- 处理得到的最后结果是 "哈哈哈,嘿嘿嘿","空空空,白白白",因为这里name是字符串,它的value用,分隔,我们还需要对最终的结果进行处理,本是想用sql来处理,SEPARATOR
SELECT REPLACE(REPLACE(GROUP_CONCAT( DISTINCT `name` SEPARATOR ','),'[',''),']','') as result
from `user`
最终我们拿到目标结果值,哈哈哈,嘿嘿嘿,空空空,白白白,可以直接使用
如果你觉得太麻烦的话,可以使用更直观的方式,但是可读性就有一些争议了,这里使用trim函数,相比较replace,trim更加简洁
-- 最终方案本来要采取这个的,但是别忘记了sql中一个重要的函数:trim(),该函数可以直接将目标字符串替换,最最终 不用replace 直接一波`user`
SELECT TRIM(BOTH '[]' FROM IFNULL(GROUP_CONCAT( DISTINCT `name` SEPARATOR ','),'')) as result
from `user`








![C国演义 [第十二章]](https://img-blog.csdnimg.cn/ef799b9f95114cb197c9eb1e1143b2e6.png)