1. 并发 vs 并行
线程是程序执行的最小单位,一个进程可以由一个或多个线程组成,各个线程之间也是交叉执行。
-
并发,相当于
单核CPU,宏观同时执行,微观高速切换 交替执行。多线程、高并发这些词语更多地出现在服务端程序里。 -
并行,相当于
多核CPU,微观同时执行,更强调提升性能上限。多进程更多地与高性能计算、分布式计算联系在一起。 -
多进程:同时运行多个独立的进程,每个进程有自己独立的内存空间和执行上下文,彼此之间相互独立。
-
多线程:同一进程中同时运行多个线程,线程是进程的一部分,共享同一个进程的内存空间和执行上下文。
多进/线程 与 顺序串行执行的区别:
多进程和多线程都可以实现并行和并发的效果,但也可以减少任务间的等待时间,提高效率,但相较于顺序串行执行,进程/线程的切换也会引起时间损耗。
多进程 与 多线程的区别:
- 切换速度:多个线程共享同一个进程的内存空间和执行上下文,
线程之间的切换比进程切换更快速,开销相对较小。 - 安全性:由于进程之间相互独立,因此
多进程编程更安全,而多线程编程需要更加仔细地管理线程之间的同步和互斥,小心地处理共享数据,防止出现竞态条件等并发问题。
目前电脑主流配置都是四核-八线程的,而实际工作的任务数大都大于四个,所以也是需要交替来并发执行具体任务的。
话不多说,下面举一个例子(同时计算3个不同数字序列的欧拉数),分别用顺序串行执行、多线程调用、多进程调用计算3个task,进行计时测速:
import threading as th
import multiprocessing as mp
import time
from functools import wraps
def timer(func): # 函数的通用计时器,使用时在函数前面声明@timer即可
@wraps(func)
def inner_func():
t = time.time()
rts = func()
print(f"timer: using {time.time() - t :.5f} s")
return rts
return inner_func
def euler_func(n: int) -> int:
res = n
i = 2
while i <= n // i:
if n % i == 0:
res = res // i * (i - 1)
while (n % i == 0): n = n // i
i += 1
if n > 1:
res = res // n * (n - 1)
return res
task1 = list(range(2, 50000, 3)) # 2, 5, ...
task2 = list(range(3, 50000, 3)) # 3, 6, ...
task3 = list(range(4, 50000, 3)) # 4, 7, ...
def job(task: list):
for t in task:
euler_func(t)
@timer
def normal(): # 顺序串行执行
job(task1)
job(task2)
job(task3)
@timer # @timer 是上面写的修饰器
def mutlthread(): # 多线程调用
th1 = th.Thread(target=job, args=(task1, ))
th2 = th.Thread(target=job, args=(task2, ))
th3 = th.Thread(target=job, args=(task3, ))
# start() ,告诉线程/进程:你可以开始干活了,程序主逻辑还得继续往下运行
th1.start()
th2.start()
th3.start()
# 到 join() 这里,咱们是指让线程/进程阻塞住咱的主逻辑,比如p1.join()是指:p1不干完活,我主逻辑不往下进行(属于是「阻塞」)
th1.join()
th2.join()
th3.join()
@timer
def multcore(): # 多进程调用
p1 = mp.Process(target=job, args=(task1, ))
p2 = mp.Process(target=job, args=(task2, ))
p3 = mp.Process(target=job, args=(task3, ))
# start() ,告诉线程/进程:你可以开始干活了,程序主逻辑还得继续往下运行
p1.start()
p2.start()
p3.start()
# 到 join() 这里,咱们是指让线程/进程阻塞住咱的主逻辑,比如p1.join()是指:p1不干完活,我主逻辑不往下进行(属于是「阻塞」)
p1.join()
p2.join()
p3.join()
if __name__ == '__main__':
print("同步串行:"); normal()
print("多线程并发:"); mutlthread()
print("多进程并行:"); multcore()
结果分析:多线程并发的方式具有较好的性能表现。
- 多线程并发可以在同一时间内执行多个子任务,利用了计算机多核心的优势,可以更高效地完成任务。
- 而同步串行的方式需要等待每个子任务完成后才能进行下一个任务,造成了一定的时间延迟。
- 多进程并行的方式虽然也能同时执行多个子任务,但由于进程之间的切换和数据通信开销较大,导致执行时间略长于多线程并发。
需要注意的是,不同的任务和计算环境可能会导致不同的结果。
同步串行:
timer: using 0.44006 s
多线程并发:
timer: using 0.30993 s
多进程并行:
timer: using 0.41000 s
2. 多任务模式
实现多任务的方式主要有以下2种:
1、多进程模式 multiprocessing
2、多线程模式 threading
同时执行多个任务通常各个任务之间并不是没有关联的,而是需要相互通信和协调,有时,任务1必须暂停等待任务2完成后才能继续执行,有时,任务3和任务4又不能同时执行,所以,多进程和多线程的程序的复杂度要远远高于我们前面写的单进程单线程的程序。
比如,算法C/S架构部署时,服务端拉rtmp视频流进行视频帧解析、算法推理、结果推流多个相互依赖的任务时,可以使用多线程、多进程的方式。
2.1 多进程模式 multiprocessing
进程是操作系统中的一个执行实体,每个进程都有自己的内存空间,彼此互不影响。一般进程数默认是电脑CPU核数,当你的电脑是四核的时候,你的电脑进程默认就是4个。
在Python中我们借助多进程包multiprocessing来进行多进程任务处理方式, multiprocessing模块提供了一个Process类来代表一个进程对象:
# Process参数解析
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
#group分组
#target表示调用对象!即此进程调用的函数名
#name表示进程的别名
#args表示调用对象的位置参数元组,即函数的参数
#kwargs表示调用对象的字典
# Process类的常用方法
close() 关闭进程
is_alive() 进程是否在运行
join() 等待join语句之前的所有程序执行完毕以后再继续往下运行,通常用于进程间的同步
start() 进程准备就绪,等待CPU调度
run() strat()调用run方法,如果实例化进程时没有传入target参数,这star执行默认run()方法
# Process类的常用属性
pid 进程ID
name 进程名字
下面的例子演示了启动一个子进程(即单进程),并等待其结束:一个子进程其实就和我们平常调用单一函数是一样的。
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())#用来获取 主进程 的进程ID
p = Process(target=run_proc, args=('test',))#实例化进程p,调用run_proc函数,传入参数对象args
print('Child process will start.')
p.start()#p进程准备就绪
p.join()#调用p进程,主进程等待p进程执行
print('Child process end.')
建立多个子进程(即多进程),其实就是多个函数随机同步运行,建立多进程有两种方法,一种是直接实例化多个进程对象,另一种是进程池(Pool):
- 直接利用
multiprocessing.Process()来实例化多个子进程调用不同的函数即可。但当任务数(需要调用的函数)较多时,就需要实例化多个进程对象,并且写多行p.start()来就绪比较麻烦,如下:
from multiprocessing import Process
import random,time
def do_task(task):
print('我正在做{}'.format(task))
time.sleep(random.randint(1,3))
def write_task(task):
print('我正在写{}'.format(task))
time.sleep(random.randint(1,3))
if __name__ == "__main__":
p1 = Process(target=do_task,args=('PPT',))
p2 = Process(target=write_task,args=('Sql',))
p1.start()
p2.start()
- 使用
multiprocessing.Pool(processing_number)实例化一个包含processing_number个进程的进程池,使用apply_async()方法来异步地提交任务给进程池进行处理。
multiprocessing.Pool = Pool(processes_number: int)#process为进程数
把上面的例子用进程池Pool表示以后的结果如下:
import multiprocessing
import random
import time
from multiprocessing import Process, Queue
def do_task(q, task):
print('我正在做{}'.format(task))
q.put(task) # 将消息入队尾
time.sleep(random.randint(1, 3))
def listen_task(q, xxx):
if (not q.empty()):
print('我收到了,你做完了{}'.format(q.get())) # 从队头取出消息
else:
print('queue empty')
time.sleep(random.randint(1, 3))
if __name__ == "__main__":
q = Queue() # 注意进程通信要用multiprocessing.Queue
p1 = Process(target=do_task,args=(q, ['PPT',]))
p2 = Process(target=listen_task,args=(q, ['Sql',]))
p1.start()
p2.start()
p1.join()
p2.join()
print('All subprocesses done.')
输出结果如下:
Waiting for all subprocesses done...
我正在做PPT
我正在写Sql
All subprocesses done.
进程通信:由于进程不共享内存,因此进程间通信(IPC)需要使用特定的机制,如管道(Pipe)、队列(Queue)等。标准库的Queue只能实现线程间的通信,其get,put方法是阻塞的!!Queue.Queue是进程内非阻塞队列,multiprocess.Queue是跨进程通信队列。多进程前者是各自私有,后者是各子进程共有。
from multiprocessing import Process, Queue
def worker(q):
q.put('Hello from process') # 字符串消息入队q.put()
if __name__ == '__main__':
q = Queue() # 实例化队列q
process = Process(target=worker, args=(q,))
process.start()
process.join()
print(q.get()) # 从队头中取出消息q.get()
特别说明:MultiProcessing.Process创建的进程是有共同父进程的,而MultiProcess.Pool创建的进程则不是。
MultiProcessing.Process创建的进程能够使用MultiProcessing的Queue通信,但是如果使用的是进程池创建的进程,那么就得使用Manager类封装的数据结构了。
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.get([block[, timeout]]) 获取队列,timeout等待时间
Queue.get_nowait() 相当Queue.get(False)
非阻塞 Queue.put(item) 写入队列,timeout等待时间
Queue.put_nowait(item) 相当Queue.put(item, False)
2.2 多线程模式 threading
多线程模式就是一次只启动一个进程,但是在这个进程里启动多个线程,这样多个线程就可以一起执行多个任务,在Python中我们要启动多线程借助于threading模块中的Thread类,构建时使用的参数和方法与Process基本一致。
# Thread参数解析
Thread(group=None, target=None, name=None, args=(), kwargs={})
#方法
isAlive()
get/setName(name) 获取/设置线程名
start()
join()
创建一个线程就是调用一个函数:
import time, threading
def do_chioce(task):
print('我正在{}'.format(task))
time.sleep(random.randint(1,3))
if __name__ == "__main__":
t = threading.Thread(target=do_chioce,args=('选PPT模板',)) # 实例化线程t
t.start() # 调用t线程
创建多个线程就是调用多个函数,do_chioce()和do_content()函数都在各自的线程t1, t2中执行,彼此互不干扰:
import time, threading
def do_chioce(task):
print('我正在{}'.format(task))
time.sleep(random.randint(1,3))
def do_content(task):
print('我正在{}'.format(task))
time.sleep(random.randint(1,3))
if __name__ == "__main__":
t1 = threading.Thread(target=do_chioce,args=('选PPT模板',))
t2 = threading.Thread(target=do_content,args=('列PPT大纲',))
t1.start()
t2.start()
线程通信:由于线程共享内存,因此线程间的数据是可以互相访问的。但是,当多个线程同时修改数据时就会出现问题。为了解决这个问题,我们需要使用线程同步工具,如锁(Lock)和条件(Condition)等。
import threading
class BankAccount:
def __init__(self):
self.balance = 100 # 共享数据
self.lock = threading.Lock()
def deposit(self, amount):
with self.lock: # 使用锁进行线程同步
balance = self.balance
balance += amount
self.balance = balance
def withdraw(self, amount):
with self.lock: # 使用锁进行线程同步
balance = self.balance
balance -= amount
self.balance = balance
def deposit_money(account, amount):
for _ in range(100000):
account.deposit(amount)
def withdraw_money(account, amount):
for _ in range(100000):
account.withdraw(amount)
account = BankAccount()
# 创建两个线程,一个存款,一个取款
deposit_thread = threading.Thread(target=deposit_money, args=(account, 10))
withdraw_thread = threading.Thread(target=withdraw_money, args=(account, 5))
# 启动线程
deposit_thread.start()
withdraw_thread.start()
# 等待线程结束
deposit_thread.join()
withdraw_thread.join()
print(f"最终余额: {account.balance}")
在这个例子中,我们创建了一个银行账户对象account,初始余额为100。然后,我们创建了两个线程,一个用于存款,一个用于取款。每个线程都会对账户进行一定次数的操作(存款或取款)。通过使用线程锁,在进行存款或取款操作时,我们保证了对balance变量的访问是同步的,避免了数据竞争和不一致性。
特别说明:Python的线程虽然受到全局解释器锁(GIL)的限制,但是对于IO密集型任务(如网络IO或者磁盘IO),使用多线程可以显著提高程序的执行效率。
3. OpenCV 视频流的多线程方法
线程是进程中的一个执行单元。多线程是指通过在线程之间快速切换对 CPU 的控制(称为上下文切换)来并发执行多个线程。在我们的示例中,我们将看到多线程通过提高 FPS(每秒帧数)实现更快的实时视频处理。
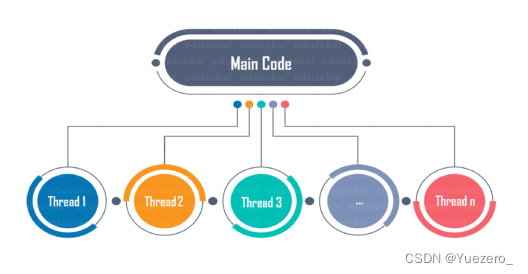
原因多线程有助于更快的处理:
视频处理代码分为两部分:从摄像头读取下一个可用帧并对帧进行视频处理,例如运行深度学习模型进行人脸识别等。
读取下一帧并在没有多线程的程序中按顺序进行处理。程序等待下一帧可用,然后再对其进行必要的处理。读取帧所需的时间主要与请求、等待和将下一个视频帧从相机传输到内存所需的时间有关。对视频帧进行计算所花费的时间,无论是在 CPU 还是 GPU 上,占据了视频处理所花费的大部分时间。
在具有多线程的程序中,读取下一帧并处理它不需要是顺序的。当一个线程执行读取下一帧的任务时,主线程可以使用 CPU 或 GPU 来处理最后读取的帧。这样,通过重叠两个任务,可以减少读取和处理帧的总时间。
没有多线程的代码:
# importing required libraries
import cv2
import time
# opening video capture stream
vcap = cv2.VideoCapture(0)
if vcap.isOpened() is False :
print("[Exiting]: Error accessing webcam stream.")
exit(0)
fps_input_stream = int(vcap.get(5))
print("FPS of webcam hardware/input stream: {}".format(fps_input_stream))
grabbed, frame = vcap.read() # reading single frame for initialization/ hardware warm-up
# processing frames in input stream
num_frames_processed = 0
start = time.time()
while True :
grabbed, frame = vcap.read()
if grabbed is False :
print('[Exiting] No more frames to read')
break
# adding a delay for simulating time taken for processing a frame
delay = 0.03 # delay value in seconds. so, delay=1 is equivalent to 1 second
time.sleep(delay)
num_frames_processed += 1
cv2.imshow('frame' , frame)
key = cv2.waitKey(1)
if key == ord('q'):
break
end = time.time()
# printing time elapsed and fps
elapsed = end-start
fps = num_frames_processed/elapsed
print("FPS: {} , Elapsed Time: {} , Frames Processed: {}".format(fps, elapsed, num_frames_processed))
# releasing input stream , closing all windows
vcap.release()
cv2.destroyAllWindows()
多线程代码:
# importing required libraries
import cv2
import time
from threading import Thread # library for implementing multi-threaded processing
# defining a helper class for implementing multi-threaded processing
class WebcamStream:
def __init__(self, stream_id=0):
self.stream_id = stream_id # default is 0 for primary camera
# opening video capture stream
self.vcap = cv2.VideoCapture(self.stream_id)
if self.vcap.isOpened() is False:
print("[Exiting]: Error accessing webcam stream.")
exit(0)
fps_input_stream = int(self.vcap.get(5))
print("FPS of webcam hardware/input stream: {}".format(fps_input_stream))
# reading a single frame from vcap stream for initializing
self.grabbed, self.frame = self.vcap.read()
if self.grabbed is False:
print('[Exiting] No more frames to read')
exit(0)
# self.stopped is set to False when frames are being read from self.vcap stream
self.stopped = True
# reference to the thread for reading next available frame from input stream
self.t = Thread(target=self.update, args=())
self.t.daemon = True # daemon threads keep running in the background while the program is executing
# method for starting the thread for grabbing next available frame in input stream
def start(self):
self.stopped = False
self.t.start()
# method for reading next frame
def update(self):
while True:
if self.stopped is True:
break
self.grabbed, self.frame = self.vcap.read()
if self.grabbed is False:
print('[Exiting] No more frames to read')
self.stopped = True
break
self.vcap.release()
# method for returning latest read frame
def read(self):
return self.frame
# method called to stop reading frames
def stop(self):
self.stopped = True
# initializing and starting multi-threaded webcam capture input stream
webcam_stream = WebcamStream(stream_id=0) # stream_id = 0 is for primary camera
webcam_stream.start()
frame = []
# processing frames in input stream
num_frames_processed = 0
start = time.time()
while True:
if webcam_stream.stopped is True:
break
else:
frame = webcam_stream.read()
# adding a delay for simulating time taken for processing a frame
delay = 0.03 # delay value in seconds. so, delay=1 is equivalent to 1 second
time.sleep(delay)
num_frames_processed += 1 # count the number of frames
cv2.imshow('frame', frame)
key = cv2.waitKey(1)
if key == ord('q'):
break
end = time.time()
webcam_stream.stop() # stop the webcam stream
# printing time elapsed and fps
elapsed = end - start
fps = num_frames_processed / elapsed
print("FPS: {} , Elapsed Time: {} , Frames Processed: {}".format(fps, elapsed, num_frames_processed))
# closing all windows
cv2.destroyAllWindows()
同理,对于Flask等架构实现rtsp/rtmp推流拉流时也可以使用多线程完成:拉流线程(读取帧)、处理线程(跑算法)、推流线程(发送帧)