一.前言
我们内部排序已经学了插入排序(直接插入排序、折半插入排序、希尔排序),交换排序(冒泡排序、快速排序),选择排序(简单选择排序、堆排序),这些都属于内部排序,接下来我们学习内部排序里面剩下的归并排序和基数排序。
二.归并排序
1.算法思路
归并排序与上述基于交换、选择等排序的思想不一样,“归并”的含义是将两个或两个以上的有序表合并成一个新的有序表。假定待排序表含有n个记录,则可将其视为n个有序的子表,每个子表的长度为1,然后两两归并,得到[n/2]个长度为2或1的有序表;继续两两归并…如此重复,直到合并成-一个长度为n的有序表为止,这种排序方法称为2路归并排序。
分解:将含有n个元素的待排序表分成各含n/2个元素的子表,采用2路归并排序算法对两
个子表递归地进行排序。
合并:合并两个已排序的子表得到排序结果。
2.举例
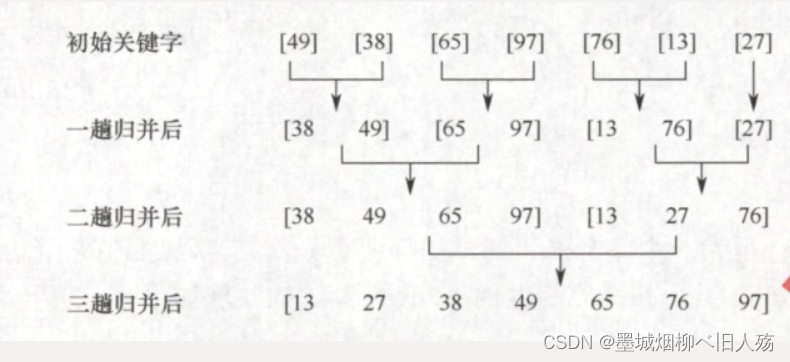
3.性能分析
- 空间效率: Merge ()操作中,辅助空间刚好为n个早兀,所以算法的空间复朵度为O(n)。
- 时间效率:每趟归并的时间复杂度为O(n),共需进行[log2 n]趟归并,所以算法的时间复杂度为O(nlog2 n)。
- 稳定性:由于Merge ()操作不会改变相同关键字记录的相对次序,所以2路归并排序算法是一种稳定的排序方法。
三.基数排序
1.算法思路
为实现多关键字排序,通常有两种方法:第-一种是最高位优先(MSD)法,按关键字位权重
递减依次逐层划分成若干更小的子序列,最后将所有子序列依次连接成-一个有序序列。第二种是最低位优先(LSD) 法,按关键字位权重递增依次进行排序,最后形成一个有序序列。
对i=0,d-1,依次做一-次“分配”和“收集”(其实是一次稳定的排序过程)。
- 分配:开始时,把Qo, .,., Q-1各个队列置成空队列,然后依次考察线性表中的每个结点a; (j=0,1,.,n-1), 若a;的关键字k;=k,就把a;放进Qk队列中。
- 收集:把Qo, 0.,-, Qr1各个队列中的结点依次首尾相接,得到新的结点序列,从而组成新的线性表。
2.举例
通常采用链式基数排序,假设对如下10个记录进行排序:

依次取个位、十位、百位进行分配和收集:

每个关键字是1000 以下的正整数,基数r= 10,在排序过程中需要借助10个链队列,每个关键字由3位子关键字构成K’K2K’,分别代表百位、十位和个位,一共需要进行三趟“分配”和“收集”操作。第一趟分配用最低位子关键字K3进行,将所有最低位子关键字(个位)相等的记录分配到同一个队列,如图(a)所示,然后进行收集操作,第一趟收集后 的结果如图(b)所示。
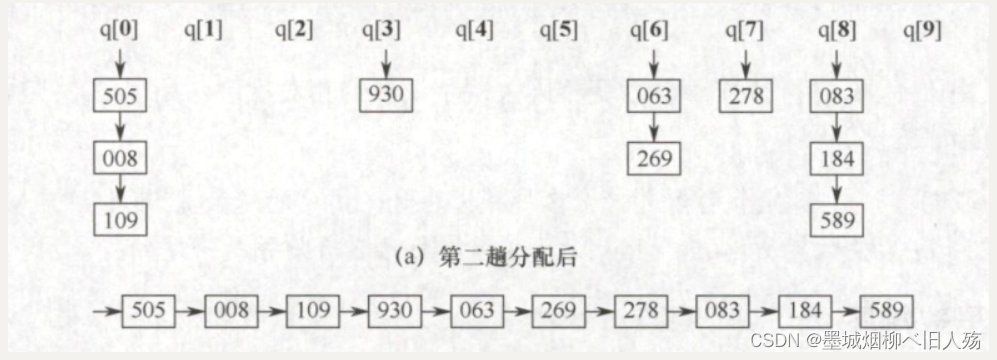
第二趟分配用次低位子关键字K2 进行,将所有次低位子关键字(十位)相等的记录分配到
同一个队列,如图(a)所示,第二趟收集后的结果如图(b)所示。
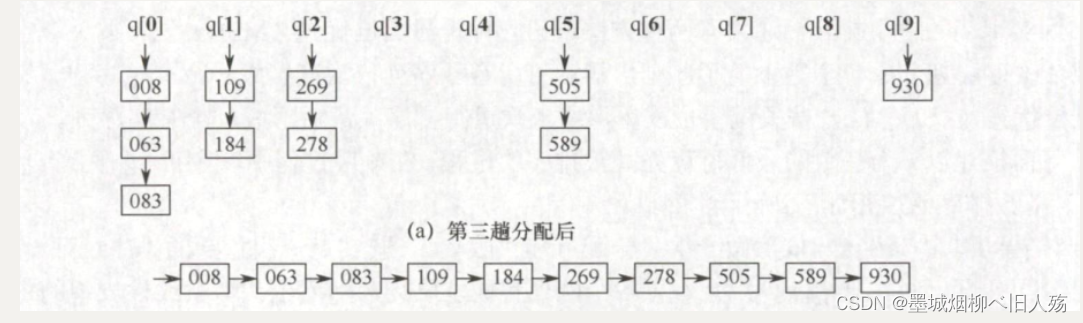
第三趟分配用最高位子关键字K’ 进行,将所有最高位子关键字(百位)相等的记录分配到
同一个队列,如图(a)所示,第三趟收集后的结果如图(b)所示,至此整个排序结束。
3.性能分析
- 空间效率:一趟排序需要的辅助存储空间为r (r个队列: r个队头指针和r个队尾指针),但以后的排序中会重复使用这些队列,所以基数排序的空间复杂度为0®。
- 时间效率:基数排序需要进行d趟分配和收集,一趟分配需要O(n),一趟收集需要0®,所以基数排序的时间复杂度为O(d(n + r)),它与序列的初始状态无关。
- 稳定性:对于基数排序算法而言,很重要一点就是按位排序时必须是稳定的。因此,这也保证了基数排序的稳定性。
四.排序算法代码
1.归并排序
Merge()的功能是将前后相邻的两个有序表归并为一个有序表。设两段有序表A[low.mid]、A[mid1…high]存放在同-顺序表中的相邻位置,先将它们复制到辅助数组B
中。每次从对应B中的两个段取出一一个 记录进行关键字的比较,将较小者放入A中,当数组B中有一段的下标超出其对应的表长(即该段的所有元素都已复制到A中)时,将另一段中的剩余部分直接复制到A中。算法如下:
//归并函数
Elemtype *A=(Elemtype *)malloc(MaxSize * sizeof(Elemtype)); //辅助数组
void Merge(SqList &L,int low,int mid,int high){ //这里三个指针不是为了快排,而是为了方便指示序列长度
int i,j,k;
for(k=low;k<=high;k++)
A[k]=L.data[k]; //将L.data[]的所有元素复制到A中
for(i=low,j=mid+1,k=i;i<=mid && j<=high;k++){
if(A[i].grade<=A[j].grade)
L.data[k]=A[i++]; //比较左右两端元素的大小
else
L.data[k]=A[j++];
}
while(i<=mid) L.data[k++]=A[i++]; //没检测完的直接复制
while(j<=high) L.data[k++]=A[j++];
}
//归并排序函数
void Mergesort(SqList &L,int low,int high){
if(low<high){
int mid=(low+high)/2; //从中间划分两个子序列
Mergesort(L,low,mid); //对左侧子树进行递归排序
Mergesort(L,mid+1,high); //对右侧子树进行递归排序
Merge(L,low,mid,high); //归并
}
}
2.基数排序
//基数排序
void Basesort(LinkNode &L, Saquene queue[]) {
for (int radix = 1; radix <= 100; radix *= 10) { // 对每个位数进行排序
// 入队列
LinkNode p = L->next;
while (p != NULL) {
int i = (p->data.grade / radix) % 10;
enQueue(queue[i], &(p->data));
p = p->next;
}
// 出队列
LinkNode tail = L;
for (int i = 0; i < 10; i++) {
while (!QueueEmpty(queue[i])) {
Elemtype e;
deQueue(queue[i], &e);
LinkNode newNode = (LinkNode)malloc(sizeof(LNode));
newNode->data = e; //不断的“收集”
newNode->next = NULL;
tail->next = newNode; //tail相当于一个头结点
tail = newNode;
}
}
}
}
五.完整C语言测试代码
1.测试归并排序
/*我们今天的主角是归并排序,所以我们还是利用线性表来进行模拟*/
/*为了便于我们后面演示希尔排序,所以我们采用顺序存储结构*/
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define MaxSize 50 //这里只是演示,我们假设这里最多存五十个学生信息
//定义学生结构
typedef struct {
char name[200]; //姓名
int grade; //分数,这个是排序关键字
} Elemtype;
//声明使用顺序表
typedef struct {
/*这里给数据分配内存,可以有静态和动态两种方式,这里采用动态分配*/
Elemtype *data; //存放线性表中的元素是Elemtype所指代的学生结构体
int length; //存放线性表的长度
} SqList; //给这个顺序表起个名字,接下来给这个结构体定义方法
//初始化线性表
void InitList(SqList &L){
/*动态分配内存的初始化*/
L.data = (Elemtype*)malloc(MaxSize * sizeof(Elemtype)); //为顺序表分配空间
L.length = 0; //初始化长度为0
}
//求表长函数
int Length(SqList &L){
return L.length;
}
//求某个数据元素值
bool GetElem(SqList &L, int i, Elemtype &e) {
if (i < 1 || i > L.length)
return false; //参数i错误时,返回false
e = L.data[i - 1]; //取元素值
return true;
}
//输出线性表
void DispList(SqList &L) {
if (L.length == 0)
printf("线性表为空");
//扫描顺序表,输出各元素
for (int i = 0; i < L.length; i++) {
printf("%s %d", L.data[i].name, L.data[i].grade);
printf("\n");
}
printf("\n");
}
//插入数据元素
bool ListInsert(SqList &L, int i, Elemtype e) {
/*在顺序表L的第i个位置上插入新元素e*/
int j;
//参数i不正确时,返回false
if (i < 1 || i > L.length + 1 || L.length == MaxSize)
return false;
i--; //将顺序表逻辑序号转化为物理序号
//参数i正确时,将data[i]及后面的元素后移一个位置
for (j = L.length; j > i; j--) {
L.data[j] = L.data[j - 1];
}
L.data[i] = e; //插入元素e
L.length++; //顺序表长度加1
return true;
/*平均时间复杂度为O(n)*/
}
//归并函数
Elemtype *A=(Elemtype *)malloc(MaxSize * sizeof(Elemtype)); //辅助数组
void Merge(SqList &L,int low,int mid,int high){ //这里三个指针不是为了快排,而是为了方便指示序列长度
int i,j,k;
for(k=low;k<=high;k++)
A[k]=L.data[k]; //将L.data[]的所有元素复制到A中
for(i=low,j=mid+1,k=i;i<=mid && j<=high;k++){
if(A[i].grade<=A[j].grade)
L.data[k]=A[i++]; //比较左右两端元素的大小
else
L.data[k]=A[j++];
}
while(i<=mid) L.data[k++]=A[i++]; //没检测完的直接复制
while(j<=high) L.data[k++]=A[j++];
}
//归并排序函数
void Mergesort(SqList &L,int low,int high){
if(low<high){
int mid=(low+high)/2; //从中间划分两个子序列
Mergesort(L,low,mid); //对左侧子树进行递归排序
Mergesort(L,mid+1,high); //对右侧子树进行递归排序
Merge(L,low,mid,high); //归并
}
}
int main(){
SqList L;
Elemtype stuents[10]={{"张三",649},{"李四",638},{"王五",665},{"赵六",697},{"冯七",676},
{"读者",713},{"阿强",627},{"杨曦",649},{"老六",655},{"阿黄",604}};
//这一部分忘了的请回顾我的相关博客
printf("初始化顺序表并插入开始元素:\n");
InitList(L); //这时是一个空表,接下来通过插入元素函数完成初始化
for (int i = 0; i < 10; i++)
ListInsert(L, i + 1, stuents[i]);
DispList(L);
printf("根据分数进行归并排序后结果为:\n");
int low=0,high=L.length-1;
Mergesort(L,low,high);
DispList(L);
}
2.测试基数排序
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define MaxSize 50 //定义队列元素的最大个数
//定义学生结构
typedef struct {
char name[20]; //姓名
int grade; //分数
} Elemtype;
//声明链表
typedef struct LNode
{
Elemtype data;
struct LNode *next;
}LNode,*LinkNode;
//和上次实验的不同,上次实验初始化是建立一个头结点把next置为空
//这里用LinkNode L表示一个链表,用LNode *表示一个结点(该思路来源于王道考研)
//不带头结点链表的初始化
bool InitList1(LinkNode &L)
{
L=NULL;
return true;
}
//带头结点链表的初始化
bool InitList2(LinkNode &L){
L=(LNode *)malloc(sizeof(LNode));
if(L==NULL)
return false;
L->next=NULL;
return true;
}
//尾插法建立单链表
void CreateListR(LinkNode &L,Elemtype a[],int n)
{
LNode *s,*r; //r位始终指向尾结点的指针,而s为指向要插入结点的过度指针
//头节点已存在,不再在这里建立了
r=L; //r始终指向尾节点,但初始时指向头节点(初始时头节点即为尾节点)
for(int i=0;i<n;i++)
{
s=(LNode * )malloc(sizeof(LNode)); //创建数据新节点
s->data=a[i]; //将数组元素赋值给新节点s的数据域
r->next=s; //将s放在原来尾指针r的后面
r=s;
}
r->next=NULL; //插入完成后,尾节点的next域为空
}
//头插法建立单链表
void CreateListF(LinkNode &L,Elemtype a[],int n)
{
LNode *s;
//头节点已存在,不再在这里建立了
for(int i=0;i<n;i++)
{
s=(LNode * )malloc(sizeof(LNode)); //创建数据新节点
s->data=a[i]; //将数组元素赋值给s的数据域
s->next=L->next; //将s放在原来L节点之后
L->next=s;
}
}
/*头插法和尾插法一定要画图弄清思路*/
//按序号查找结点
LNode *GetElem(LinkNode &L,int i){
if(i<1)
return NULL;
int j=1;
LNode *p=L->next;
while(p!=NULL && j<i){
p=p->next;
j++;
}
return p;
}
//插入数据元素
bool ListInsert(LinkNode &L,int i,Elemtype e)
{
/*在链表L的第i个位置上插入新元素e*/
int j=0;
LNode *p=L,*s; //p开始指向头节点,s为存放数据新节点
if(i<=0) //位置不对就报错
return false;
while(j<i-1 && p!=NULL) //定位,使p指向第i-1个节点
{
j++;
p=p->next;
}
if(p==NULL) //如果没找到第i-1个节点就报错
return false;
else //成功定位后,执行下面操作
{
s=(LNode * )malloc(sizeof(LNode)); //创建新节点s,其数据域置为e
s->data=e;
s->next=p->next; //创建的新节点s放在节点p之后
p->next=s;
return true;
}
}
//输出线性表
void DispList(LinkNode &L)
{
LinkNode p=L->next; //p指向首节点
while(p!=NULL) //p不为空就输出p节点的data域
{
printf("%s %d\n",p->data.name,p->data.grade);
p=p->next; //p移向下一位节点
}
printf("-------------------------------\n");
}
//定义循环顺序队列结构体
typedef struct {
Elemtype data[MaxSize]; //存放队中元素
int front, rear; //队头和队尾的伪指针
} SqQueue, *Saquene; //顺序队类型
//初始化队列
void InitQueue(Saquene *q) {
*q = (SqQueue *) malloc(sizeof(SqQueue)); //申请一个顺序队大小的空队列空间
(*q)->front = (*q)->rear = 0; //队头和队尾的伪指针均设置伪-1
}
//销毁队列
void DestroyQueue(Saquene q) {
free(q); //释放q所占的空间即可
}
//判断空队列
int QueueEmpty(Saquene q) {
return (q->front == q->rear);
}
//进队列
int enQueue(Saquene q, Elemtype *e) {
if ((q->rear + 1) % MaxSize == q->front) //队满上溢出报错
return 0;
q->rear = (q->rear + 1) % MaxSize; //队尾增1
q->data[q->rear] = *e; //rear位置插入元素e
return 1;
}
//出队列
int deQueue(Saquene q, Elemtype *e) {
if (q->rear == q->front) //队空下溢出报错
return 0;
q->front = (q->front + 1) % MaxSize; //队头增1
*e = q->data[q->front];
return 1;
}
//基数排序
void Basesort(LinkNode &L, Saquene queue[]) {
for (int radix = 1; radix <= 100; radix *= 10) { // 对每个位数进行排序
// 入队列
LinkNode p = L->next;
while (p != NULL) {
int i = (p->data.grade / radix) % 10;
enQueue(queue[i], &(p->data));
p = p->next;
}
// 出队列
LinkNode tail = L;
for (int i = 0; i < 10; i++) {
while (!QueueEmpty(queue[i])) {
Elemtype e;
deQueue(queue[i], &e);
LinkNode newNode = (LinkNode)malloc(sizeof(LNode));
newNode->data = e; //不断的“收集”
newNode->next = NULL;
tail->next = newNode; //tail相当于一个头结点
tail = newNode;
}
}
}
}
/*这里容易产生一个思维误区,由于我们这里是链表,它是一个一个结点构成的,在我们进队操作时,原来的链表相当于被我们打散了
分成一个个结点插入不同的队列中,在后面收集的出队过程中,我们又把每个结点拿出来重新链接,所以最后结果就相当于在原来的线性表L上修改*/
int main(){
LinkNode L;
Elemtype stuents[10]={{"张三",649},{"李四",638},{"王五",665},{"赵六",697},{"冯七",676},
{"读者",713},{"阿强",627},{"杨曦",649},{"老六",655},{"阿黄",604}};
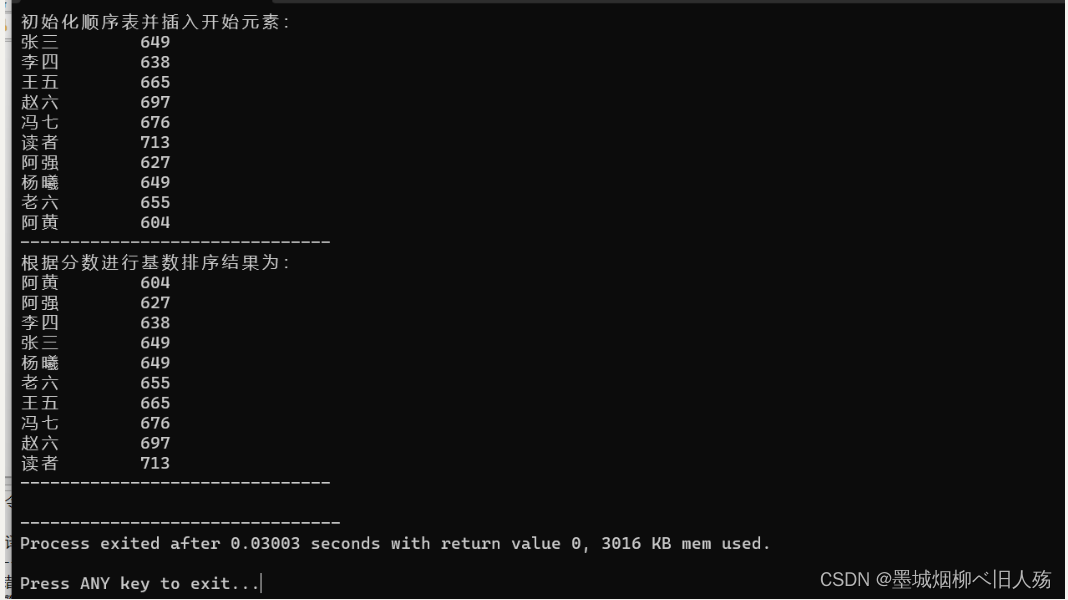
printf("初始化顺序表并插入开始元素:\n");
InitList2(L); //这时是一个空表,接下来通过插入元素函数完成初始化
for (int i = 0; i < 10; i++)
ListInsert(L, i + 1, stuents[i]);
DispList(L);
//这一步是验证了插入函数是正确的,我们通过for循环插入
//同时,我还写了头插法和尾插法建立单链表,可以直接使用这两个算法建立单链表,把students[]作为参数传入即可
Saquene queue[10]; //定义十个队列
for(int i=0;i<10;i++){
Saquene a;
InitQueue(&a);
queue[i]=a;
}
Basesort(L, queue); // 基数排序
DispList(L); // 输出排序后的链表
return 0;
}
六.测试结果
1.归并排序测试结果
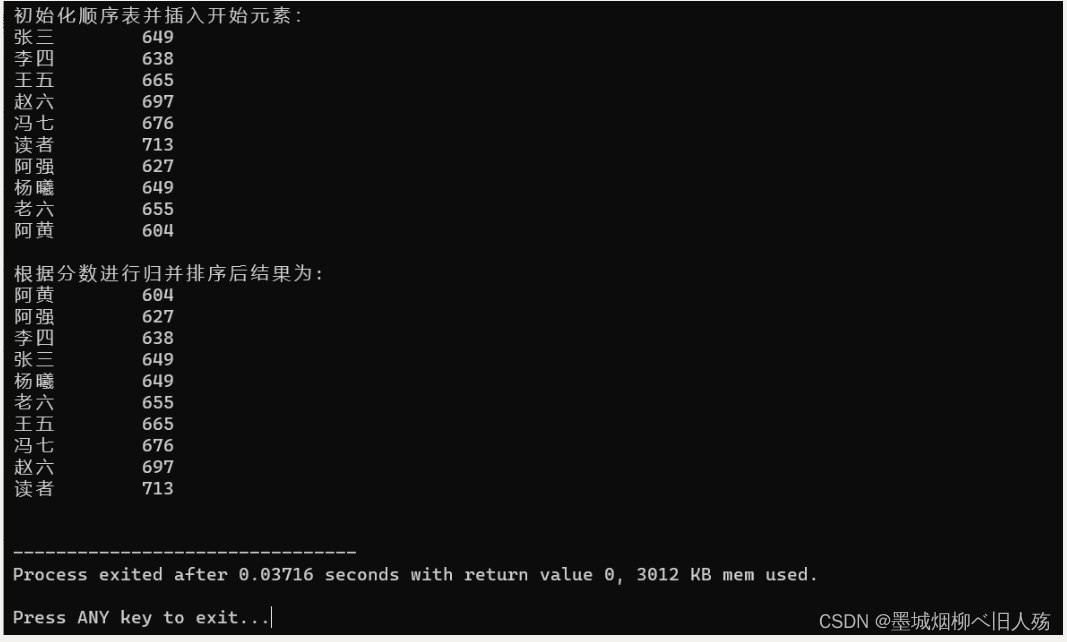
2.基数排序测试结果