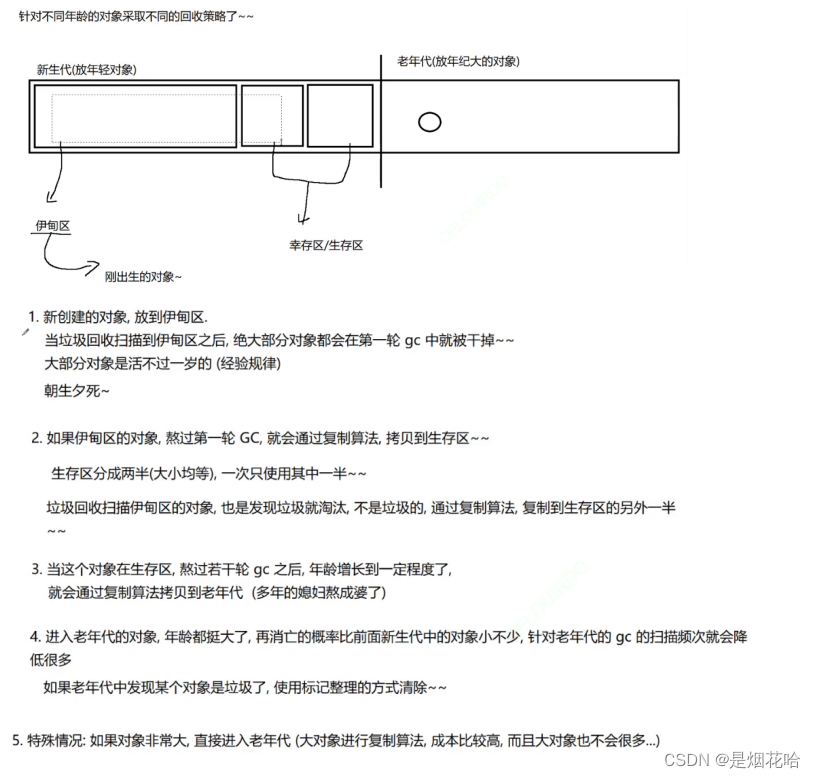
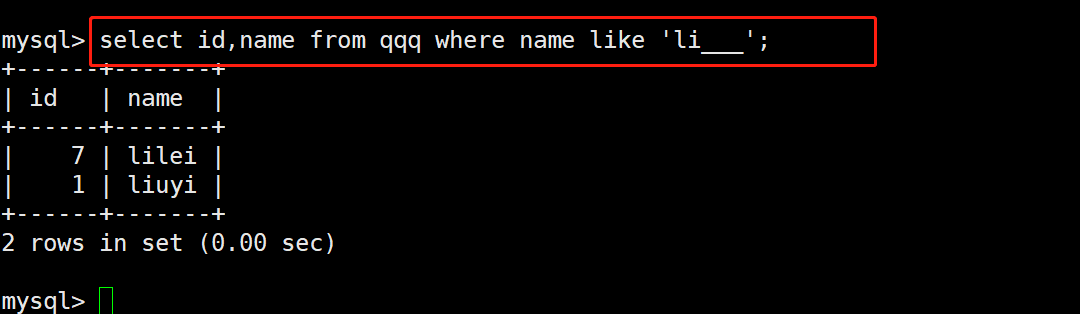
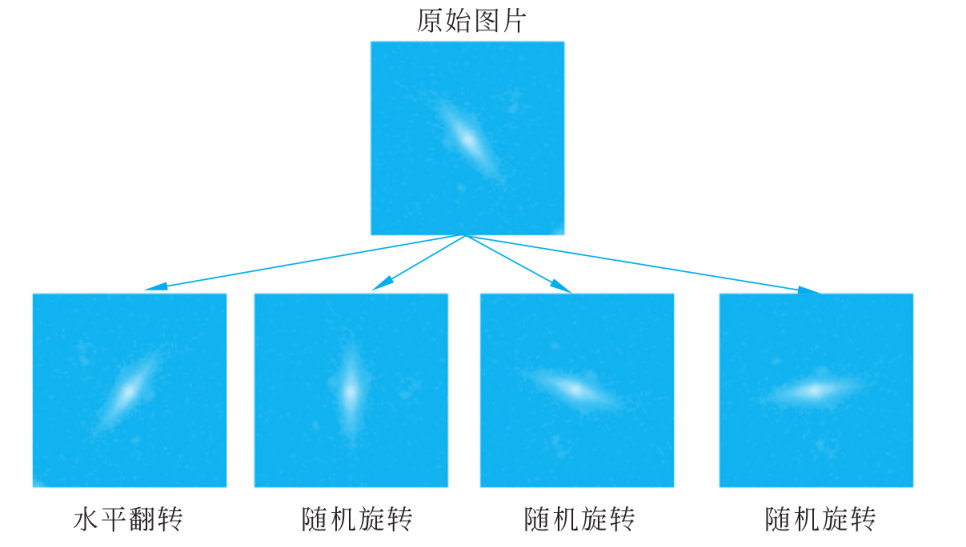
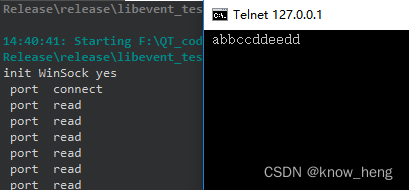
本专栏是网易云课堂人工智能课程《神经网络与深度学习》的学习笔记,视频由网易云课堂与 deeplearning.ai 联合出品,主讲人是吴恩达 Andrew Ng 教授。感兴趣的网友可以观看网易云课堂的视频进行深入学习,视频的链接如下:
神经网络和深度学习 - 网易云课堂
也欢迎对神经网络与深度学习感兴趣的网友一起交流 ~
目录
1 梯度消失与梯度爆炸
2 初始化权重
1 梯度消失与梯度爆炸
训练神经网络,尤其是深度神经网络所面临的一个问题是,梯度消失(Vanish gradient)与梯度爆炸(Explode gradient)。也就是说,当你训练深度网络时,导数或梯度有时会变得非常大,或非常小,甚至以指数方式变小,这加大了训练的难度。

假设你正在训练这样一个极深的神经网络,为了简单起见,假设使用激活函数 g(z) = z,那么输出 y 等于各层权重的矩阵乘积作用在输入 x 上。

假设前 L-1 层的权重都取如下矩阵
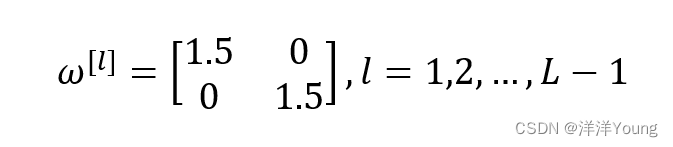
那么最后的输出 为

对于深度神经网络来说,L 的值很大,那么激活函数的输出也很大,并且以指数级增长;相反地,如果对角线上的权重是 0.5,激活函数的输出将以指数级递减。对应地梯度下降法的步长会变得非常大,或非常小,不利于梯度下降算法的计算过程。
2 初始化权重
针对深度神经网络的梯度消失与梯度爆炸问题,有一种不完整的解决方案,虽然不能解决问题,但是能帮助我们谨慎地选择初始化权值。

对于单个神经元的模型,假如有 n 个输入特征。为了防止 z 的值过大,在 n 值越大时,我们希望各层的权重 wi 越小,最合理的权重初始化方法是,使 wi 的方差 Var(wi) = 1/n,实现代码为
W = np.random.randn(X.shape) * np.sqrt(1/n)
如果激活函数使用 ReLU,那么设置 Var(wi) = 2/n,效果会更好。