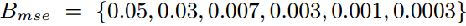如果有疑问的话可以在我的谈论群:706128290 来找我
目录
前言
二、编写代码
1.引入库
2.编写主类
4.获取命令行参数
运行效果
前言
browser_cookie3 第三方模块
browser_cookie3是browser_cookie模块的分支,它可以获取到电脑上的浏览器cookies,本次程序会使用到此模块。
一、HTML藏玄机
在小破站的任意一个视频html中,head标签下都有一个script。里面有window.__playinfo__的json数据
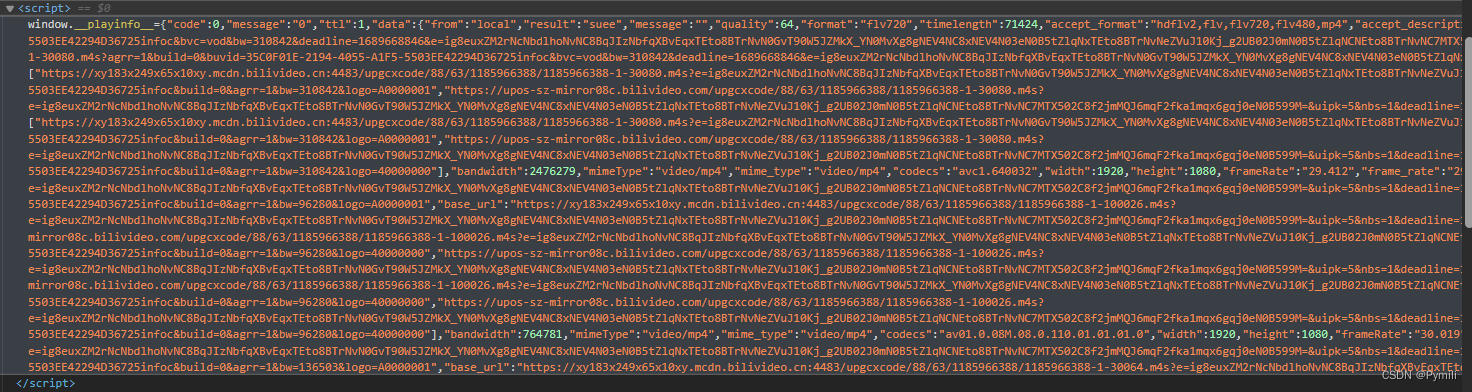
通过JSON在线解析及格式化验证 - JSON.cn 进行解析,我看到了以下内容



天助我也!我想要的视频链接不就是在这里吗?
二、编写代码
1.引入库
代码如下:
# 处理windows.__playinfo__中的json
import json
# 后面使用命令行获取链接
import sys
import os
import getopt
# 用于请求和解析链接
import requests
from fileid.fileid import Newid # 生成随机文件名
from tqdm import tqdm
from bs4 import BeautifulSoup
# 自定义的功能文件
import getHeaders
import bvid_aid
2.编写主类
代码如下:
PATH: str = os.path.split(__file__)[0]
COOKIE: bool = False
OUTPUTPATH: str = PATH
PAGE: list = [
None
]
class GBV:
def __init__(self, _url: str, _browser: int, _params) -> None:
self.url = _url
self.params = _params
self.headers = getHeaders.get(_browser)
self.title = None
self.audio = None
self.video = None
self.tqdm = tqdm(range(100))
self.tqdm.set_description(f"Url is: {self.url}")
def move(self, file: str, toPath: str) -> str:
if os.path.isfile(file):
rfp = open(file, "rb")
else:
return None
if os.path.isfile(toPath) == False:
if os.path.isdir(toPath):
toPath = os.path.join(toPath, self.title+".mp4")
else:
return None
try:
with open(toPath, "wb") as wfp:
wfp.write(rfp.read())
except OSError:
toPath = os.path.join(OUTPUTPATH, Newid(10).newfileid()+".mp4")
with open(toPath, "wb") as wfp:
wfp.write(rfp.read())
rfp.close()
os.remove(file)
return toPath
def GetPlayinfoData(self) -> tuple:
with requests.get(self.url, headers=self.headers, params=self.params) as get:
self.title = BeautifulSoup(get.text, "lxml").find_all("h1")[0].attrs['title']
data = BeautifulSoup(get.text, "lxml").find_all("script")[2].text.split("__playinfo__=")[-1]
data = json.loads(data)
self.audio = data['data']['dash']['audio'][0]['baseUrl']
self.video = data['data']['dash']['video'][0]['baseUrl']
return (self.title, self.audio, self.video)
def save(self) -> None:
randomStr = os.path.join(os.getcwd(), Newid(5).newfileid()+".mp4")
outputJoin = os.path.join(os.getcwd(), "output.mp4")
tempMp4Join = os.path.join(os.getcwd(), "temp.mp4")
tempMp3Join = os.path.join(os.getcwd(), "temp.mp3")
ffempgJoin = os.path.join(PATH, "ffmpeg.exe")
with requests.get(self.audio, headers=self.headers) as AudioGet:
with open(tempMp3Join, "wb") as faudio:
self.tqdm.set_description("保存音频文件....")
faudio.write(AudioGet.content)
faudio.close()
self.tqdm.update(50)
with requests.get(self.video, headers=self.headers) as VideoGet:
with open(tempMp4Join, "wb") as fvideo:
self.tqdm.set_description("保存视频文件...")
fvideo.write(VideoGet.content)
fvideo.close()
os.popen(
fr"{ffempgJoin} -y -i {tempMp4Join} {outputJoin}"
).read()
os.popen(
fr"{ffempgJoin} -y -i {outputJoin} -i {tempMp3Join} -c:v copy -c:a copy -bsf:a aac_adtstoasc {randomStr}",
).read()
moveRturn = self.move(f"{randomStr}", OUTPUTPATH)
self.tqdm.update(50)
self.tqdm.close()
if COOKIE:
with open(f"{PATH}/.cookie", "w+", encoding="utf-8") as wfp:
wfp.write(COOKIE)
print("\n删除缓存...")
os.remove(tempMp4Join)
os.remove(tempMp3Join)
os.remove(outputJoin)
print(f"\nOk!视频保存文件为:{moveRturn}")
def run(self, bvid: str) -> None:
global OUTPUTPATH
url = "https://api.bilibili.com/x/web-interface/wbi/view/detail"
params = {
"bvid": bvid,
"aid": bvid_aid.getAID(bvid),
}
videos = {}
with requests.get(url, params=params, headers=self.headers) as get:
page_all = 1
for i in get.json()['data']['View']['pages']:
videos[i['page']] = i['part']
page_all += 1
if OUTPUTPATH == os.path.split(__file__)[0]:
try:
OUTPUTPATH = os.path.join(
os.getcwd(),
get.json()['data']['View']['title']
)
if os.path.isdir(OUTPUTPATH) == False:
os.mkdir(OUTPUTPATH)
except OSError as oserror:
print(f"{oserror}\n程序将随机生成文件夹名。")
OUTPUTPATH = os.path.join(
os.getcwd(),
Newid(10).newfileid()
)
if os.path.isdir(OUTPUTPATH) == False:
os.mkdir(OUTPUTPATH)
if PAGE[0] == "ALL":
for key, value in videos.items():
self.params = {
"p": i
}
self.GetPlayinfoData()
self.title = value
self.save()
elif (type(PAGE) == list) and (PAGE[0] != None):
for i in PAGE:
if i <= int(page_all):
self.params = {
"p": i
}
self.GetPlayinfoData()
self.title = f"{i}."+videos[i]
self.save()
elif PAGE[0] == None:
self.GetPlayinfoData()
self.save()
1.run函数用于读取用户输入的数据并处理,再启动相应函数
2.GetPlayinfoData就是用于处理window__playinfo__对象中的数据的
2.save函数用于下载音频与视频,再使用ffmpeg合并后保存文件。
3. 自动获取cookies值和生成headers
GetBilibiliCookies.py
import browser_cookie3
class GetBrowser_cookies:
def __init__(self, browser: int = 0) -> None:
self.Bkeys = [
"buvid4",
"b_nut",
"b_lsid",
"buvid3",
"i-wanna-go-back",
"_uuid",
"FEED_LIVE_VERSION",
"home_feed_column",
"browser_resolution",
"buvid_fp",
"header_theme_version",
"PVID",
"SESSDATA",
"bili_jct",
"DedeUserID",
"DedeUserID__ckMd5",
"b_ut",
"CURRENT_FNVAL",
"sid",
"rpdid"
]
try:
if browser == 0:
self.browserCookes = browser_cookie3.edge()
if browser == 1:
self.browserCookes = browser_cookie3.chrome()
if browser == 2:
self.browserCookes = browser_cookie3.firefox()
except browser_cookie3.BrowserCookieError:
self.browserCookes = None
except PermissionError as PE:
self.browserCookes = None
raise PermissionError(f"{PE}\n可能是浏览器引起的问题,可以尝试重装浏览器")
def get(self) -> str:
cookies = ""
for i in self.browserCookes:
if i.name in self.Bkeys:
cookies += f"{i.name}={i.value}; "
return cookies
def getValue(self, key: str) -> str:
for i in self.browserCookes:
if key == i.name:
return i.value
return ""为什么要获取cookies值?当然没有cookie值也行,但是下载下来的文件一般都是低画质的。但是你登录了账户在浏览器,就可以通过浏览器记录的cookies来提交服务器。 前提是你在浏览器登录了bilibili账户。
getHeaders.py
此处为生成headers的程序
import GetBilibiliCookies
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
REFERER = "https://www.bilibili.com/"
def get(browser: int = 0) -> dict:
return {
"User-Agent":USER_AGENT,
"cookie": GetBilibiliCookies.GetBrowser_cookies(browser).get(),
"Referer": REFERER
}bvid_aid.py
import requests
import getHeaders
def getAID(bvid: str) -> int:
aid = None
url = f'https://api.bilibili.com/x/web-interface/view?bvid={bvid}'
with requests.get(url, headers=getHeaders.get()) as get:
if get.status_code == 200:
aid = get.json()['data']['aid']
return aid4.获取命令行参数
代码如下:
def main(_url: str, _browser: int, bvid: str, params: dict) -> None:
gbv = GBV(_url, _browser, params)
gbv.run(bvid)
def help() -> None:
print("""
########################################################################
# Get Bilibili Video (gbv)
# Author: PYmili
# Email: mc2005wj@163.com
########################################################################
Command:
--cookie or -c [Url Cookies]
--input_url or -i [Video URL]
--browser or -b [edge(default), chrome, firefox]
--output or -o [Output file or path]
--page or -p [start-end / all] Select an array of videos to download
""")
if __name__ == '__main__':
URL = None
BROWSER = 0
BVID = None
PARAMS = {}
options, argv = getopt.getopt(
sys.argv[1:], "i:c:b:o:p:",
["--input_url=", "--cookie=", "--browser=", "--output=", "--page="]
)
for key, value in options:
if key in ["-i", "--input_url"]:
splitValue = value.split("video")[-1]
splitValue = splitValue.split("/", 1)[-1].split("/", 1)
URL = value
BVID = splitValue[0]
if splitValue[-1]:
for i in splitValue[-1][1:].split("&"):
try:
PARAMS[i.split("=")[0]] = eval(i.split('=')[-1])
except SyntaxError:
PARAMS[i.split("=")[0]] = str(i.split('=')[-1])
if key in ["-c", "--copkie"]:
COOKIE = value
if key in ["-b", "--browser"]:
if value == "chrome":
BROWSER = 1
elif value == "firefox":
BROWSER = 2
if key in ["-o", "--output"]:
if os.path.isdir(value):
OUTPUTPATH = value
else:
print(f"没有:{value} 这个路径。")
if key in ["-p", "--page"]:
if "-" in value:
start, end = value.split("-")
PAGE = [i for i in range(int(start), int(end)+1)]
elif value in ["all", "ALL", "All"]:
PAGE[0] = "ALL"
else:
PAGE.append(int(value))
if (URL != None) and (BVID != None):
main(URL, BROWSER, BVID, PARAMS)
else:
help()这就是获取终端输入的传输来运行程序 。
运行效果
当没有输入参数时:
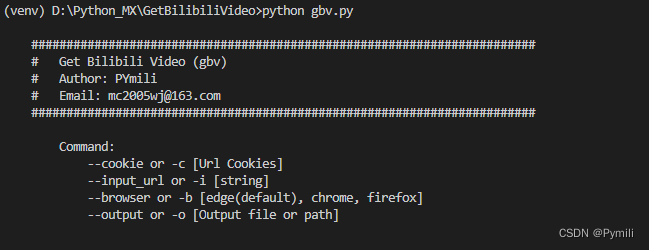
基础输入格式:

完整参数:
--cookie 或者 -c [此处填写cookies]
--input_url 或者 -i [填入B站视频链接]
--browser 或者 -b [edge(default), chrome, firefox 有这三个浏览器供选择默认edge]
--output 或者 -o [文件输出路径,默认当前位置]
--page 或者 -p [start-end / all] 选择要下载的视频阵列如:0-100或者 all 全部下载
以上就是本篇内容,如果有疑问的话可以在我的谈论群:706128290 来找我,下次再见拜拜!