1. 环境准备(Yarn 集群)
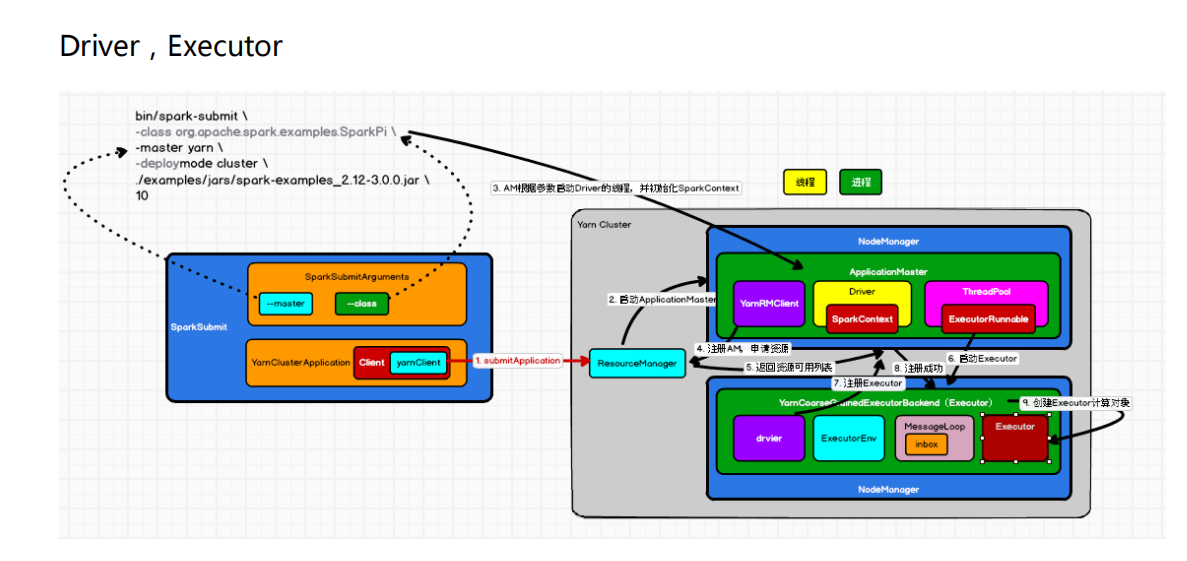

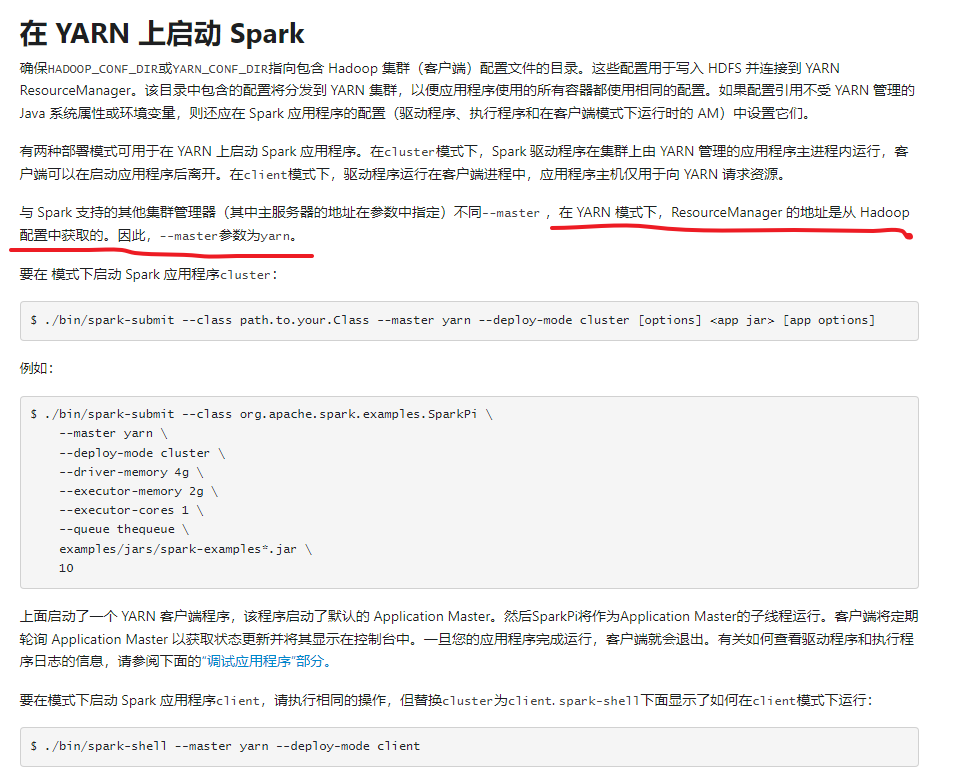
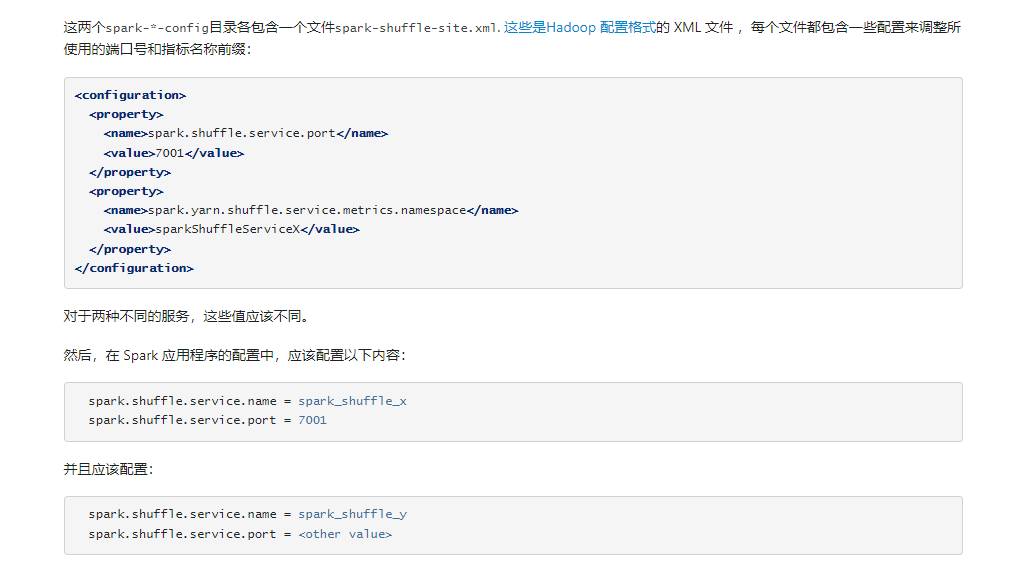
搭建Spark on Yarn集群
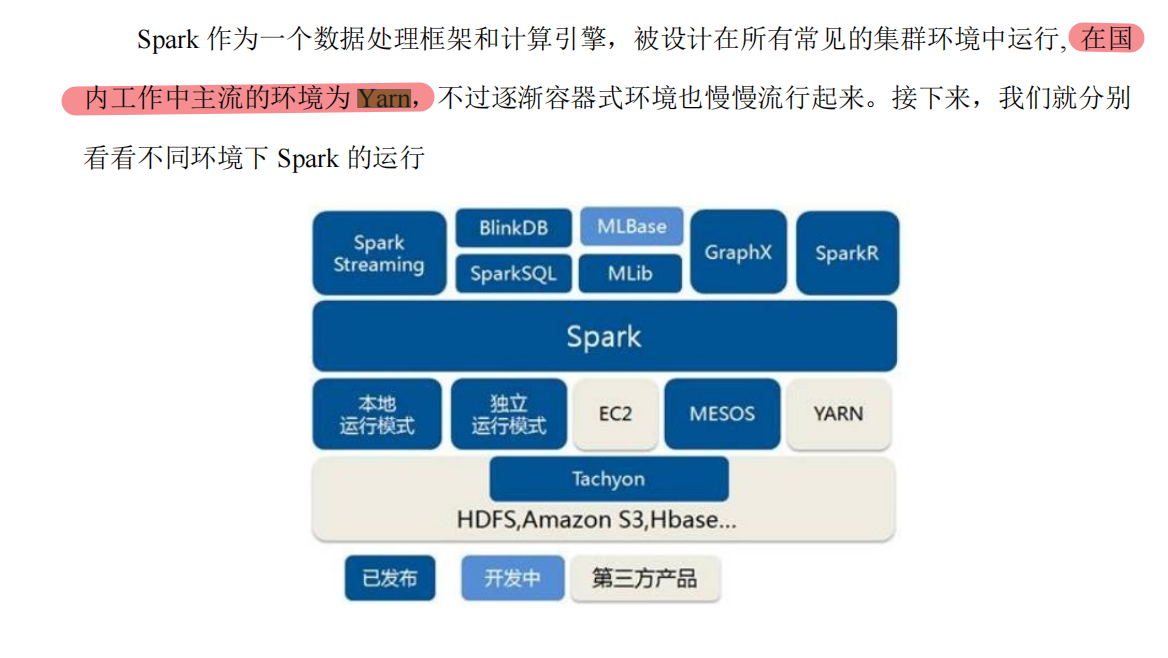
3.3 Yarn 模式
- 独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的 Yarn 环境下 Spark 是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)。
spark on yarn
Xshell 7 (Build 0113)
Copyright (c) 2020 NetSarang Computer, Inc. All rights reserved.
Type `help' to learn how to use Xshell prompt.
[C:\~]$
Host 'hadoop102' resolved to 10.16.51.223.
Connecting to 10.16.51.223:22...
Connection established.
To escape to local shell, press Ctrl+Alt+].
Last login: Tue Jul 18 17:00:00 2023 from 10.16.51.1
[atguigu@hadoop102 ~]$ cat /etc/pro
profile profile.d/ protocols
[atguigu@hadoop102 ~]$ cat /etc/pro
profile profile.d/ protocols
[atguigu@hadoop102 ~]$ cat /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#HIVE_HOME
export HIVE_HOME=/opt/module/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
#MAHOUT_HOME
export MAHOUT_HOME=/opt/module/mahout-distribution-0.13.0
export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf
export PATH=$MAHOUT_HOME/conf:$MAHOUT_HOME/bin:$PATH
#MAVEN_HOME
export MAVEN_HOME=/opt/module/maven-3.8.8
export PATH=$PATH:$MAVEN_HOME/bin
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase-2.4.11
export PATH=$PATH:$HBASE_HOME/bin
#PHOENIX_HOME
export PHOENIX_HOME=/opt/module/phoenix-hbase-2.4-5.1.2
export PHOENIX_CLASSPATH=$PHOENIX_HOME
export PATH=$PATH:$PHOENIX_HOME/bin
#REDIS_HOME
export REDIS_HOME=/usr/local/redis
export PATH=$PATH:$REDIS_HOME/bin
#SCALA_VERSION
export SCALA_HOME=/opt/module/scala-2.12.11
export PATH=$PATH:$SCALA_HOME/bin
#SPARK_HOME
export SPARK_HOME=/opt/module/spark-3.0.0-bin-hadoop3.2
export PATH=$PATH:$SPARK_HOME/bin
export SPARK_LOCAL_DIRS=$PATH:$SPARK_HOME
[atguigu@hadoop102 ~]$ sbin/start-history-server.sh
-bash: sbin/start-history-server.sh: 没有那个文件或目录
[atguigu@hadoop102 ~]$ locate /start-history-server.sh
/opt/module/spark-3.0.0-bin-hadoop3.2/sbin/start-history-server.sh
[atguigu@hadoop102 ~]$ cd /opt/module/spark-3.0.0-bin-hadoop3.2/sbin
[atguigu@hadoop102 sbin]$ start-history-server.sh
bash: start-history-server.sh: 未找到命令...
[atguigu@hadoop102 sbin]$ sbin/start-history-server.sh
-bash: sbin/start-history-server.sh: 没有那个文件或目录
[atguigu@hadoop102 sbin]$ sbin/start-history-server.sh
-bash: sbin/start-history-server.sh: 没有那个文件或目录
[atguigu@hadoop102 sbin]$ pwd
/opt/module/spark-3.0.0-bin-hadoop3.2/sbin
[atguigu@hadoop102 sbin]$ ll
总用量 84
-rwxr-xr-x. 1 atguigu atguigu 2803 6月 6 2020 slaves.sh
-rwxr-xr-x. 1 atguigu atguigu 1429 6月 6 2020 spark-config.sh
-rwxr-xr-x. 1 atguigu atguigu 5689 6月 6 2020 spark-daemon.sh
-rwxr-xr-x. 1 atguigu atguigu 1262 6月 6 2020 spark-daemons.sh
-rwxr-xr-x. 1 atguigu atguigu 1190 6月 6 2020 start-all.sh
-rwxr-xr-x. 1 atguigu atguigu 1764 6月 6 2020 start-history-server.sh
-rwxr-xr-x. 1 atguigu atguigu 2097 6月 6 2020 start-master.sh
-rwxr-xr-x. 1 atguigu atguigu 1877 6月 6 2020 start-mesos-dispatcher.sh
-rwxr-xr-x. 1 atguigu atguigu 1425 6月 6 2020 start-mesos-shuffle-service.sh
-rwxr-xr-x. 1 atguigu atguigu 3242 6月 6 2020 start-slave.sh
-rwxr-xr-x. 1 atguigu atguigu 1527 6月 6 2020 start-slaves.sh
-rwxr-xr-x. 1 atguigu atguigu 2025 6月 6 2020 start-thriftserver.sh
-rwxr-xr-x. 1 atguigu atguigu 1478 6月 6 2020 stop-all.sh
-rwxr-xr-x. 1 atguigu atguigu 1056 6月 6 2020 stop-history-server.sh
-rwxr-xr-x. 1 atguigu atguigu 1080 6月 6 2020 stop-master.sh
-rwxr-xr-x. 1 atguigu atguigu 1227 6月 6 2020 stop-mesos-dispatcher.sh
-rwxr-xr-x. 1 atguigu atguigu 1084 6月 6 2020 stop-mesos-shuffle-service.sh
-rwxr-xr-x. 1 atguigu atguigu 1557 6月 6 2020 stop-slave.sh
-rwxr-xr-x. 1 atguigu atguigu 1064 6月 6 2020 stop-slaves.sh
-rwxr-xr-x. 1 atguigu atguigu 1066 6月 6 2020 stop-thriftserver.sh
[atguigu@hadoop102 sbin]$ s
Display all 347 possibilities? (y or n)
[atguigu@hadoop102 sbin]$ start
start-all.cmd start-dfs.cmd start-pulseaudio-x11 startx
start-all.sh start-dfs.sh start-secure-dns.sh start-yarn.cmd
start-balancer.sh start-hbase.sh start-statd start-yarn.sh
[atguigu@hadoop102 sbin]$ start-
start-all.cmd start-dfs.cmd start-pulseaudio-x11 start-yarn.cmd
start-all.sh start-dfs.sh start-secure-dns.sh start-yarn.sh
start-balancer.sh start-hbase.sh start-statd
[atguigu@hadoop102 sbin]$ pwd
/opt/module/spark-3.0.0-bin-hadoop3.2/sbin
[atguigu@hadoop102 sbin]$ start-history-server.sh
bash: start-history-server.sh: 未找到命令...
[atguigu@hadoop102 sbin]$ cd ..
[atguigu@hadoop102 spark-3.0.0-bin-hadoop3.2]$ sbin/s
slaves.sh start-mesos-dispatcher.sh stop-master.sh
spark-config.sh start-mesos-shuffle-service.sh stop-mesos-dispatcher.sh
spark-daemon.sh start-slave.sh stop-mesos-shuffle-service.sh
spark-daemons.sh start-slaves.sh stop-slave.sh
start-all.sh start-thriftserver.sh stop-slaves.sh
start-history-server.sh stop-all.sh stop-thriftserver.sh
start-master.sh stop-history-server.sh
[atguigu@hadoop102 spark-3.0.0-bin-hadoop3.2]$ sbin/s
slaves.sh start-mesos-dispatcher.sh stop-master.sh
spark-config.sh start-mesos-shuffle-service.sh stop-mesos-dispatcher.sh
spark-daemon.sh start-slave.sh stop-mesos-shuffle-service.sh
spark-daemons.sh start-slaves.sh stop-slave.sh
start-all.sh start-thriftserver.sh stop-slaves.sh
start-history-server.sh stop-all.sh stop-thriftserver.sh
start-master.sh stop-history-server.sh
[atguigu@hadoop102 spark-3.0.0-bin-hadoop3.2]$ sbin/start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /opt/module/spark-3.0.0-bin-hadoop3.2/logs/spark-atguigu-org.apache.spark.deploy.history.HistoryServer-1-hadoop102.out
[atguigu@hadoop102 spark-3.0.0-bin-hadoop3.2]$ bin/spark-submit
Usage: spark-submit [options] <app jar | python file | R file> [app arguments]
Usage: spark-submit --kill [submission ID] --master [spark://...]
Usage: spark-submit --status [submission ID] --master [spark://...]
Usage: spark-submit run-example [options] example-class [example args]
Options:
--master MASTER_URL spark://host:port, mesos://host:port, yarn,
k8s://https://host:port, or local (Default: local[*]).
--deploy-mode DEPLOY_MODE Whether to launch the driver program locally ("client") or
on one of the worker machines inside the cluster ("cluster")
(Default: client).
--class CLASS_NAME Your application's main class (for Java / Scala apps).
--name NAME A name of your application.
--jars JARS Comma-separated list of jars to include on the driver
and executor classpaths.
--packages Comma-separated list of maven coordinates of jars to include
on the driver and executor classpaths. Will search the local
maven repo, then maven central and any additional remote
repositories given by --repositories. The format for the
coordinates should be groupId:artifactId:version.
--exclude-packages Comma-separated list of groupId:artifactId, to exclude while
resolving the dependencies provided in --packages to avoid
dependency conflicts.
--repositories Comma-separated list of additional remote repositories to
search for the maven coordinates given with --packages.
--py-files PY_FILES Comma-separated list of .zip, .egg, or .py files to place
on the PYTHONPATH for Python apps.
--files FILES Comma-separated list of files to be placed in the working
directory of each executor. File paths of these files
in executors can be accessed via SparkFiles.get(fileName).
--conf, -c PROP=VALUE Arbitrary Spark configuration property.
--properties-file FILE Path to a file from which to load extra properties. If not
specified, this will look for conf/spark-defaults.conf.
--driver-memory MEM Memory for driver (e.g. 1000M, 2G) (Default: 1024M).
--driver-java-options Extra Java options to pass to the driver.
--driver-library-path Extra library path entries to pass to the driver.
--driver-class-path Extra class path entries to pass to the driver. Note that
jars added with --jars are automatically included in the
classpath.
--executor-memory MEM Memory per executor (e.g. 1000M, 2G) (Default: 1G).
--proxy-user NAME User to impersonate when submitting the application.
This argument does not work with --principal / --keytab.
--help, -h Show this help message and exit.
--verbose, -v Print additional debug output.
--version, Print the version of current Spark.
Cluster deploy mode only:
--driver-cores NUM Number of cores used by the driver, only in cluster mode
(Default: 1).
Spark standalone or Mesos with cluster deploy mode only:
--supervise If given, restarts the driver on failure.
Spark standalone, Mesos or K8s with cluster deploy mode only:
--kill SUBMISSION_ID If given, kills the driver specified.
--status SUBMISSION_ID If given, requests the status of the driver specified.
Spark standalone, Mesos and Kubernetes only:
--total-executor-cores NUM Total cores for all executors.
Spark standalone, YARN and Kubernetes only:
--executor-cores NUM Number of cores used by each executor. (Default: 1 in
YARN and K8S modes, or all available cores on the worker
in standalone mode).
Spark on YARN and Kubernetes only:
--num-executors NUM Number of executors to launch (Default: 2).
If dynamic allocation is enabled, the initial number of
executors will be at least NUM.
--principal PRINCIPAL Principal to be used to login to KDC.
--keytab KEYTAB The full path to the file that contains the keytab for the
principal specified above.
Spark on YARN only:
--queue QUEUE_NAME The YARN queue to submit to (Default: "default").
--archives ARCHIVES Comma separated list of archives to be extracted into the
working directory of each executor.
[atguigu@hadoop102 spark-3.0.0-bin-hadoop3.2]$ bin/spark-submit \
> --class org.apache.spark.examples.SparkPi \
> --master yarn \
> --deploy-mode client \
> ./examples/jars/spark-examples_2.12-3.0.0.jar \
> 10
2023-07-18 17:47:53,922 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-07-18 17:47:54,184 INFO spark.SparkContext: Running Spark version 3.0.0
2023-07-18 17:47:54,224 INFO resource.ResourceUtils: ==============================================================
2023-07-18 17:47:54,225 INFO resource.ResourceUtils: Resources for spark.driver:
2023-07-18 17:47:54,226 INFO resource.ResourceUtils: ==============================================================
2023-07-18 17:47:54,226 INFO spark.SparkContext: Submitted application: Spark Pi
2023-07-18 17:47:54,342 INFO spark.SecurityManager: Changing view acls to: atguigu
2023-07-18 17:47:54,390 INFO spark.SecurityManager: Changing modify acls to: atguigu
2023-07-18 17:47:54,390 INFO spark.SecurityManager: Changing view acls groups to:
2023-07-18 17:47:54,390 INFO spark.SecurityManager: Changing modify acls groups to:
2023-07-18 17:47:54,390 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(atguigu); groups with view permissions: Set(); users with modify permissions: Set(atguigu); groups with modify permissions: Set()
2023-07-18 17:47:56,205 INFO util.Utils: Successfully started service 'sparkDriver' on port 34360.
2023-07-18 17:47:56,274 INFO spark.SparkEnv: Registering MapOutputTracker
2023-07-18 17:47:56,393 INFO spark.SparkEnv: Registering BlockManagerMaster
2023-07-18 17:47:56,417 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
2023-07-18 17:47:56,417 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
2023-07-18 17:47:56,514 INFO spark.SparkEnv: Registering BlockManagerMasterHeartbeat
2023-07-18 17:47:56,540 INFO storage.DiskBlockManager: Created local directory at /opt/module/mahout-distribution-0.13.0/conf:/opt/module/mahout-distribution-0.13.0/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/hive-3.1.2/bin:/opt/module/maven-3.8.8/bin:/opt/module/hbase-2.4.11/bin:/opt/module/phoenix-hbase-2.4-5.1.2/bin:/usr/local/redis/bin:/opt/module/scala-2.12.11/bin:/opt/module/spark-3.0.0-bin-hadoop3.2/bin:/opt/module/spark-3.0.0-bin-hadoop3.2/blockmgr-86112ae9-a017-45c6-b650-9882145753e6
2023-07-18 17:47:56,564 INFO memory.MemoryStore: MemoryStore started with capacity 366.3 MiB
2023-07-18 17:47:56,602 INFO spark.SparkEnv: Registering OutputCommitCoordinator
2023-07-18 17:47:56,685 INFO util.log: Logging initialized @3908ms to org.sparkproject.jetty.util.log.Slf4jLog
2023-07-18 17:47:56,779 INFO server.Server: jetty-9.4.z-SNAPSHOT; built: 2019-04-29T20:42:08.989Z; git: e1bc35120a6617ee3df052294e433f3a25ce7097; jvm 1.8.0_212-b10
2023-07-18 17:47:56,809 INFO server.Server: Started @4033ms
2023-07-18 17:47:56,951 INFO server.AbstractConnector: Started ServerConnector@4362d7df{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2023-07-18 17:47:56,951 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
2023-07-18 17:47:57,284 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1a6f5124{/jobs,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,302 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2d35442b{/jobs/json,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,303 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4593ff34{/jobs/job,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,322 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@22db8f4{/jobs/job/json,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,323 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1d572e62{/stages,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,324 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@46cf05f7{/stages/json,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,324 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7cd1ac19{/stages/stage,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,394 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1804f60d{/stages/stage/json,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,397 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@547e29a4{/stages/pool,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,404 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@238b521e{/stages/pool/json,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,406 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3e2fc448{/storage,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,409 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@588ab592{/storage/json,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,411 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4cc61eb1{/storage/rdd,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,412 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@2024293c{/storage/rdd/json,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,414 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@c074c0c{/environment,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,415 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5949eba8{/environment/json,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,417 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@58dea0a5{/executors,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,418 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3c291aad{/executors/json,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,419 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@733037{/executors/threadDump,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,456 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@320e400{/executors/threadDump/json,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,596 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1cfd1875{/static,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,600 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@751e664e{/,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,603 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@182b435b{/api,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,604 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3153ddfc{/jobs/job/kill,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,605 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@28a2a3e7{/stages/stage/kill,null,AVAILABLE,@Spark}
2023-07-18 17:47:57,609 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://hadoop102:4040
2023-07-18 17:47:57,628 INFO spark.SparkContext: Added JAR file:/opt/module/spark-3.0.0-bin-hadoop3.2/./examples/jars/spark-examples_2.12-3.0.0.jar at spark://hadoop102:34360/jars/spark-examples_2.12-3.0.0.jar with timestamp 1689673677628
2023-07-18 17:47:59,004 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/10.16.51.224:8032
2023-07-18 17:48:00,470 INFO yarn.Client: Requesting a new application from cluster with 3 NodeManagers
2023-07-18 17:48:05,839 INFO conf.Configuration: resource-types.xml not found
2023-07-18 17:48:05,839 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-07-18 17:48:05,933 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
2023-07-18 17:48:05,944 INFO yarn.Client: Will allocate AM container, with 896 MB memory including 384 MB overhead
2023-07-18 17:48:05,944 INFO yarn.Client: Setting up container launch context for our AM
2023-07-18 17:48:05,945 INFO yarn.Client: Setting up the launch environment for our AM container
2023-07-18 17:48:06,056 INFO yarn.Client: Preparing resources for our AM container
2023-07-18 17:48:06,356 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
2023-07-18 17:48:27,982 INFO yarn.Client: Uploading resource file:/opt/module/mahout-distribution-0.13.0/conf:/opt/module/mahout-distribution-0.13.0/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/hive-3.1.2/bin:/opt/module/maven-3.8.8/bin:/opt/module/hbase-2.4.11/bin:/opt/module/phoenix-hbase-2.4-5.1.2/bin:/usr/local/redis/bin:/opt/module/scala-2.12.11/bin:/opt/module/spark-3.0.0-bin-hadoop3.2/bin:/opt/module/spark-3.0.0-bin-hadoop3.2/spark-1f765dd5-975a-4756-aa9c-c0122330465b/__spark_libs__1986064070290985513.zip -> hdfs://hadoop102:8020/user/atguigu/.sparkStaging/application_1689076989054_0001/__spark_libs__1986064070290985513.zip
2023-07-18 17:48:59,245 INFO yarn.Client: Uploading resource file:/opt/module/mahout-distribution-0.13.0/conf:/opt/module/mahout-distribution-0.13.0/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/hive-3.1.2/bin:/opt/module/maven-3.8.8/bin:/opt/module/hbase-2.4.11/bin:/opt/module/phoenix-hbase-2.4-5.1.2/bin:/usr/local/redis/bin:/opt/module/scala-2.12.11/bin:/opt/module/spark-3.0.0-bin-hadoop3.2/bin:/opt/module/spark-3.0.0-bin-hadoop3.2/spark-1f765dd5-975a-4756-aa9c-c0122330465b/__spark_conf__6902573288688043647.zip -> hdfs://hadoop102:8020/user/atguigu/.sparkStaging/application_1689076989054_0001/__spark_conf__.zip
2023-07-18 17:48:59,326 INFO spark.SecurityManager: Changing view acls to: atguigu
2023-07-18 17:48:59,326 INFO spark.SecurityManager: Changing modify acls to: atguigu
2023-07-18 17:48:59,326 INFO spark.SecurityManager: Changing view acls groups to:
2023-07-18 17:48:59,326 INFO spark.SecurityManager: Changing modify acls groups to:
2023-07-18 17:48:59,326 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(atguigu); groups with view permissions: Set(); users with modify permissions: Set(atguigu); groups with modify permissions: Set()
2023-07-18 17:48:59,350 INFO yarn.Client: Submitting application application_1689076989054_0001 to ResourceManager
2023-07-18 17:49:06,092 INFO impl.YarnClientImpl: Submitted application application_1689076989054_0001
2023-07-18 17:49:07,271 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:07,275 INFO yarn.Client:
client token: N/A
diagnostics: [星期二 七月 18 17:49:06 +0800 2023] Scheduler has assigned a container for AM, waiting for AM container to be launched
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1689673742617
final status: UNDEFINED
tracking URL: http://hadoop103:8088/proxy/application_1689076989054_0001/
user: atguigu
2023-07-18 17:49:08,491 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:09,514 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:10,540 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:11,543 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:12,610 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:13,751 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:14,846 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:15,927 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:16,968 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:17,989 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:19,035 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:20,079 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:21,388 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:22,638 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:23,647 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:25,027 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:26,766 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:29,265 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:30,301 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:31,446 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:32,648 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:33,787 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:34,844 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:36,160 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:37,850 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:38,885 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:39,977 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:41,248 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:42,274 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:43,446 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:44,471 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:45,537 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:46,669 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:47,672 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:48,687 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:50,498 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:51,612 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:52,771 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:53,780 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:55,188 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:56,677 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:49:57,920 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:00,770 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:03,314 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:04,790 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:05,852 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:06,901 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:08,000 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:09,071 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:12,072 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:19,044 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:20,130 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:21,176 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:22,523 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:23,675 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:24,794 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:27,556 INFO yarn.Client: Application report for application_1689076989054_0001 (state: ACCEPTED)
2023-07-18 17:50:28,780 INFO yarn.Client: Application report for application_1689076989054_0001 (state: RUNNING)
2023-07-18 17:50:28,780 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 10.16.51.223
ApplicationMaster RPC port: -1
queue: default
start time: 1689673742617
final status: UNDEFINED
tracking URL: http://hadoop103:8088/proxy/application_1689076989054_0001/
user: atguigu
2023-07-18 17:50:28,783 INFO cluster.YarnClientSchedulerBackend: Application application_1689076989054_0001 has started running.
2023-07-18 17:50:28,981 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 44812.
2023-07-18 17:50:28,981 INFO netty.NettyBlockTransferService: Server created on hadoop102:44812
2023-07-18 17:50:28,984 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
2023-07-18 17:50:29,008 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, hadoop102, 44812, None)
2023-07-18 17:50:29,329 INFO storage.BlockManagerMasterEndpoint: Registering block manager hadoop102:44812 with 366.3 MiB RAM, BlockManagerId(driver, hadoop102, 44812, None)
2023-07-18 17:50:29,346 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, hadoop102, 44812, None)
2023-07-18 17:50:29,357 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, hadoop102, 44812, None)
2023-07-18 17:50:30,120 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6415f61e{/metrics/json,null,AVAILABLE,@Spark}
2023-07-18 17:50:30,121 INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> hadoop103, PROXY_URI_BASES -> http://hadoop103:8088/proxy/application_1689076989054_0001), /proxy/application_1689076989054_0001
2023-07-18 17:50:30,715 WARN net.NetUtils: Unable to wrap exception of type class org.apache.hadoop.ipc.RpcException: it has no (String) constructor
java.lang.NoSuchMethodException: org.apache.hadoop.ipc.RpcException.<init>(java.lang.String)
at java.lang.Class.getConstructor0(Class.java:3082)
at java.lang.Class.getConstructor(Class.java:1825)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:830)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:806)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1515)
at org.apache.hadoop.ipc.Client.call(Client.java:1457)
at org.apache.hadoop.ipc.Client.call(Client.java:1367)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy17.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:903)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy18.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1665)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1582)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1579)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1594)
at org.apache.spark.deploy.history.EventLogFileWriter.requireLogBaseDirAsDirectory(EventLogFileWriters.scala:77)
at org.apache.spark.deploy.history.SingleEventLogFileWriter.start(EventLogFileWriters.scala:221)
at org.apache.spark.scheduler.EventLoggingListener.start(EventLoggingListener.scala:81)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:572)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2555)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$1(SparkSession.scala:930)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:921)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:30)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:928)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1007)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1016)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
2023-07-18 17:50:30,729 ERROR spark.SparkContext: Error initializing SparkContext.
java.io.IOException: Failed on local exception: org.apache.hadoop.ipc.RpcException: RPC response exceeds maximum data length; Host Details : local host is: "hadoop102/10.16.51.223"; destination host is: "hadoop102":9870;
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:816)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1515)
at org.apache.hadoop.ipc.Client.call(Client.java:1457)
at org.apache.hadoop.ipc.Client.call(Client.java:1367)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy17.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:903)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy18.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1665)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1582)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1579)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1594)
at org.apache.spark.deploy.history.EventLogFileWriter.requireLogBaseDirAsDirectory(EventLogFileWriters.scala:77)
at org.apache.spark.deploy.history.SingleEventLogFileWriter.start(EventLogFileWriters.scala:221)
at org.apache.spark.scheduler.EventLoggingListener.start(EventLoggingListener.scala:81)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:572)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2555)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$1(SparkSession.scala:930)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:921)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:30)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:928)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1007)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1016)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: org.apache.hadoop.ipc.RpcException: RPC response exceeds maximum data length
at org.apache.hadoop.ipc.Client$IpcStreams.readResponse(Client.java:1830)
at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1173)
at org.apache.hadoop.ipc.Client$Connection.run(Client.java:1069)
2023-07-18 17:50:30,753 INFO server.AbstractConnector: Stopped Spark@4362d7df{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2023-07-18 17:50:30,756 INFO ui.SparkUI: Stopped Spark web UI at http://hadoop102:4040
2023-07-18 17:50:30,861 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread
2023-07-18 17:50:31,071 WARN cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Attempted to request executors before the AM has registered!
2023-07-18 17:50:31,094 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
2023-07-18 17:50:31,456 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
2023-07-18 17:50:31,516 INFO cluster.YarnClientSchedulerBackend: YARN client scheduler backend Stopped
2023-07-18 17:50:32,076 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
2023-07-18 17:50:32,210 INFO memory.MemoryStore: MemoryStore cleared
2023-07-18 17:50:32,210 INFO storage.BlockManager: BlockManager stopped
2023-07-18 17:50:32,241 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
2023-07-18 17:50:32,249 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
2023-07-18 17:50:32,279 INFO spark.SparkContext: Successfully stopped SparkContext
Exception in thread "main" java.io.IOException: Failed on local exception: org.apache.hadoop.ipc.RpcException: RPC response exceeds maximum data length; Host Details : local host is: "hadoop102/10.16.51.223"; destination host is: "hadoop102":9870;
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:816)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1515)
at org.apache.hadoop.ipc.Client.call(Client.java:1457)
at org.apache.hadoop.ipc.Client.call(Client.java:1367)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy17.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:903)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy18.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1665)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1582)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1579)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1594)
at org.apache.spark.deploy.history.EventLogFileWriter.requireLogBaseDirAsDirectory(EventLogFileWriters.scala:77)
at org.apache.spark.deploy.history.SingleEventLogFileWriter.start(EventLogFileWriters.scala:221)
at org.apache.spark.scheduler.EventLoggingListener.start(EventLoggingListener.scala:81)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:572)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2555)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$1(SparkSession.scala:930)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:921)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:30)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:928)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:180)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:203)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:90)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:1007)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:1016)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: org.apache.hadoop.ipc.RpcException: RPC response exceeds maximum data length
at org.apache.hadoop.ipc.Client$IpcStreams.readResponse(Client.java:1830)
at org.apache.hadoop.ipc.Client$Connection.receiveRpcResponse(Client.java:1173)
at org.apache.hadoop.ipc.Client$Connection.run(Client.java:1069)
2023-07-18 17:50:32,293 INFO util.ShutdownHookManager: Shutdown hook called
2023-07-18 17:50:32,294 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-784b431d-eaf1-4413-909d-d512a6f10f03
2023-07-18 17:50:32,305 INFO util.ShutdownHookManager: Deleting directory /opt/module/mahout-distribution-0.13.0/conf:/opt/module/mahout-distribution-0.13.0/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/module/jdk1.8.0_212/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin:/opt/module/hive-3.1.2/bin:/opt/module/maven-3.8.8/bin:/opt/module/hbase-2.4.11/bin:/opt/module/phoenix-hbase-2.4-5.1.2/bin:/usr/local/redis/bin:/opt/module/scala-2.12.11/bin:/opt/module/spark-3.0.0-bin-hadoop3.2/bin:/opt/module/spark-3.0.0-bin-hadoop3.2/spark-1f765dd5-975a-4756-aa9c-c0122330465b
[atguigu@hadoop102 spark-3.0.0-bin-hadoop3.2]$
2.组建通信
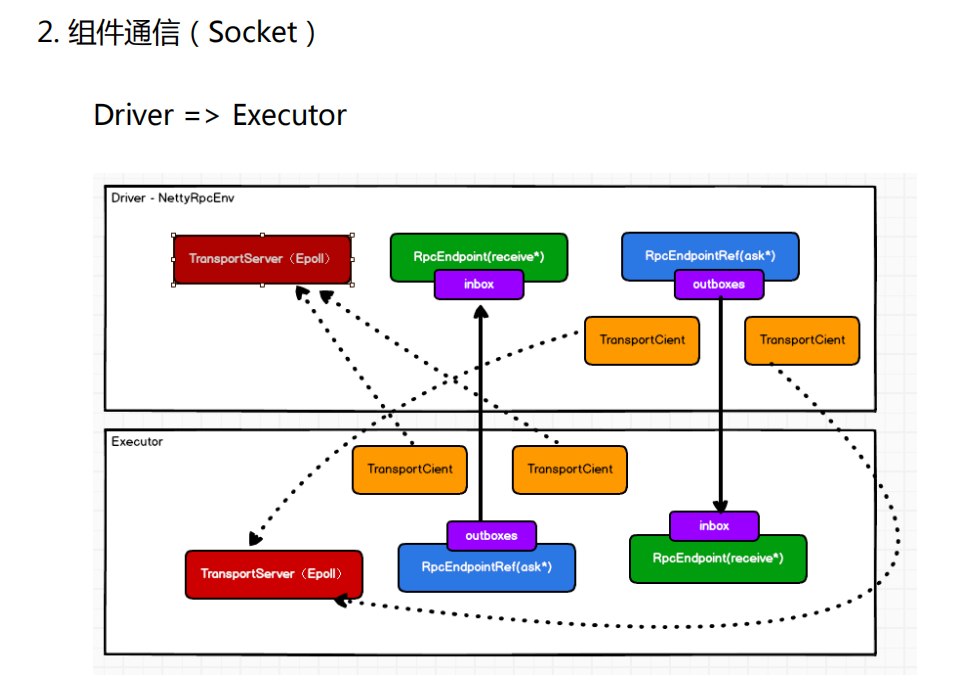
在Spark中,组件之间的通信主要通过Spark的分布式计算框架来实现。Spark采用分布式数据集(Resilient Distributed Dataset,简称RDD)作为其核心抽象数据结构,它是分布式内存中的数据集合,可以在集群中进行并行计算和操作。
组件通信的主要方式如下:
-
RDD转换操作:Spark提供了一系列的转换操作(如map、filter、reduce、join等),通过这些转换操作,不同的组件可以对RDD进行处理和转换。例如,一个组件可以将一个RDD进行map操作,生成另一个RDD,并将其传递给另一个组件进行进一步的处理。
-
Shuffle操作:Shuffle是Spark中一种特殊的数据重分布操作,用于将数据重新分布到不同的节点上。Shuffle通常发生在具有宽依赖关系的转换操作中,例如groupByKey、reduceByKey等。Shuffle操作可以在不同的组件之间传递数据,并在节点之间进行数据交换和合并。
-
广播变量(Broadcast Variables):广播变量是一种在集群中广播只读变量的机制。它允许将一个大的只读变量发送到所有的节点,以便在节点上使用,而不必将该变量复制到每个任务中。这样可以减少数据传输和复制,提高性能和效率。
-
共享变量(Accumulators):共享变量是一种用于在分布式任务中聚合信息的机制。它允许将一个可累加的变量发送到所有的节点,每个节点可以对该变量进行更新,最后将所有节点上的更新结果进行合并。
通过以上方式,Spark中的不同组件可以在集群中进行通信和协作,共同完成任务。Spark的分布式计算框架和数据处理能力使得组件之间可以高效地传递和处理数据,从而实现了大规模数据的分布式计算和并行处理。
RDD转换操作:
在Spark中,RDD转换操作是指通过对一个RDD应用某种操作,生成一个新的RDD。RDD转换操作是惰性的,意味着它们不会立即执行,而是在遇到一个行动操作(例如收集数据、保存数据)时触发计算。以下是一些常见的RDD转换操作:
-
map(func):对RDD中的每个元素应用给定的函数func,生成一个新的RDD,其中包含应用函数后的结果。
-
filter(func):对RDD中的每个元素应用给定的函数func,根据返回值为true或false来过滤出符合条件的元素,生成一个新的RDD。
-
flatMap(func):类似于map操作,但是每个输入元素可以映射到多个输出元素,生成一个扁平化的新RDD。
-
union(otherRDD):将当前RDD与另一个RDD合并,生成一个包含两个RDD元素的新RDD。
-
distinct():去除RDD中的重复元素,生成一个新的不包含重复元素的RDD。
-
groupByKey():对包含键值对的RDD按照键进行分组,生成一个包含(key, Iterable)的新RDD。
-
reduceByKey(func):对包含键值对的RDD按照键进行合并,使用给定的函数func进行reduce操作,生成一个新的(key, reducedValue)的RDD。
-
sortByKey():对包含键值对的RDD按照键进行排序,生成一个新的按键排序的RDD。
-
join(otherRDD):将当前RDD与另一个RDD按照键进行连接,生成一个新的包含(key, (value1, value2))的RDD。
-
cogroup(otherRDD):将当前RDD与另一个RDD按照键进行联结组合,生成一个新的包含(key, (Iterable, Iterable))的RDD。
以上仅是一些常见的RDD转换操作示例,Spark还提供了许多其他的转换操作和函数,以满足不同的数据处理需求。这些转换操作可以组合使用,以构建复杂的数据处理流程和数据转换链。值得注意的是,RDD转换操作都是惰性的,只有在遇到行动操作时才会触发实际的计算。
Shuffle操作:
Shuffle操作是Spark中一种特殊的数据重分布操作,用于将数据重新分布到不同的节点上。Shuffle通常发生在具有宽依赖关系的转换操作中,即一个父RDD的一个分区的数据可能会被多个子RDD的分区所使用。Shuffle操作是在数据进行转换或聚合时发生的,涉及大规模数据的洗牌和重排,因此在性能上是比较昂贵的。
Shuffle操作的主要步骤包括:
-
Map阶段:在Map阶段,数据根据自定义的key进行映射,将相同key的数据发送到同一个节点的同一个分区。
-
洗牌和排序:在洗牌阶段,数据根据key进行洗牌,即将相同key的数据聚合到同一个节点上,并按照key进行排序,以便后续的合并操作。
-
Reduce阶段:在Reduce阶段,将相同key的数据合并起来,进行聚合操作,生成新的RDD。
Shuffle操作是Spark中的一个重要组件,特别是在涉及到数据合并和聚合的场景中。一些触发Shuffle操作的常见转换操作包括groupByKey、reduceByKey、join、cogroup等。由于Shuffle操作涉及到数据的重新分布和传输,因此在性能上会引入一定的开销。在设计Spark应用程序时,需要合理地控制Shuffle操作的频率和数据量,以尽可能减少Shuffle的影响,提高整体性能。
为了优化Shuffle操作,Spark提供了一些参数和配置选项,例如合理设置分区数、使用广播变量和共享变量等,以及使用持久化存储(如Tachyon、HDFS)来减少Shuffle数据的磁盘写入和读取。另外,Spark还提供了一些高级API和优化技术,如Spark SQL的Shuffle Hash算法和Tungsten项目等,以进一步提高Shuffle操作的性能和效率。
广播变量(Broadcast Variables):
广播变量(Broadcast Variables)是Spark中的一种分布式只读变量,用于将一个大的只读数据结构广播到集群中的所有节点上,以便在执行任务时,所有节点都可以共享这个变量而不必重复传输。
在Spark中,通常情况下,每个任务都会获取一份执行代码所需的数据副本。当数据量较大时,这可能会导致网络传输和存储开销的增加。而广播变量的引入解决了这个问题。广播变量只会在集群中的驱动器程序中保存一份副本,并将其广播到所有节点。然后,在执行任务时,每个节点只需要获取这个共享的广播变量即可,不需要重复传输和存储。
广播变量的主要特点包括:
-
分布式共享:广播变量是在集群中的驱动器程序上创建的,然后广播到所有节点上,所有节点共享同一个变量。
-
只读性质:广播变量是只读的,即在任务执行过程中,不能修改广播变量的值。
-
高效性:广播变量可以有效地减少网络传输和存储开销,尤其适用于较大的只读数据结构。
广播变量的创建和使用方法如下:
# 在驱动程序中创建广播变量
broadcast_var = sc.broadcast(data)
# 在任务中获取广播变量
data = broadcast_var.value
其中,sc是SparkContext对象,data是要广播的数据结构。在驱动程序中使用broadcast()方法创建广播变量,并在任务中使用value属性获取广播变量的值。
广播变量通常在一些需要用到大规模只读数据的场景中使用,如使用全局配置、字典数据或机器学习模型参数等。通过使用广播变量,可以显著提高Spark应用程序的性能和效率。
共享变量(Accumulators):
共享变量(Accumulators)是Spark中一种用于在分布式任务中进行聚合操作的特殊变量。与广播变量不同,共享变量是可写的,允许在各个任务中对其进行累加操作。然而,共享变量的累加操作只能在驱动器程序中进行,任务中只能对其进行读取操作,不允许进行写操作。
共享变量的主要特点包括:
-
分布式累加:共享变量可以在不同节点上进行分布式累加操作,将各个节点上的计算结果进行聚合。
-
只写一次:共享变量只能在驱动器程序中进行写操作,即在任务中不能对其进行写操作,只能进行读操作。
-
并行计算:共享变量的累加操作可以并行执行,从而提高聚合性能。
共享变量通常用于在分布式任务中进行计数、求和等聚合操作。Spark提供了两种类型的共享变量:累加器(Accumulator)和集合累加器(Collection Accumulator)。
累加器(Accumulator)是一种支持数值型的共享变量,可以通过add方法对其进行累加操作。
# 在驱动程序中创建累加器
accum = sc.accumulator(0)
# 在任务中对累加器进行累加操作
rdd.foreach(lambda x: accum.add(x))
集合累加器(Collection Accumulator)是一种支持集合类型的共享变量,可以通过add方法将元素添加到集合中。
# 在驱动程序中创建集合累加器
accum = sc.accumulator([])
# 在任务中将元素添加到集合累加器中
rdd.foreach(lambda x: accum.add([x]))
需要注意的是,共享变量的累加操作只有在执行行动操作时才会真正触发。在转换操作中,共享变量的累加是不会执行的,因为转换操作是惰性执行的。
共享变量在Spark中被广泛应用于需要在分布式任务中进行聚合操作的场景,如计数、求和、最大值、最小值等。通过使用共享变量,可以有效地在分布式环境下完成复杂的聚合任务,从而提高Spark应用程序的性能和效率。
3. 应用程序的执行
详情可以参考下面的跳转:
应用程序的执行 && 第 4 章 Spark 任务调度机制
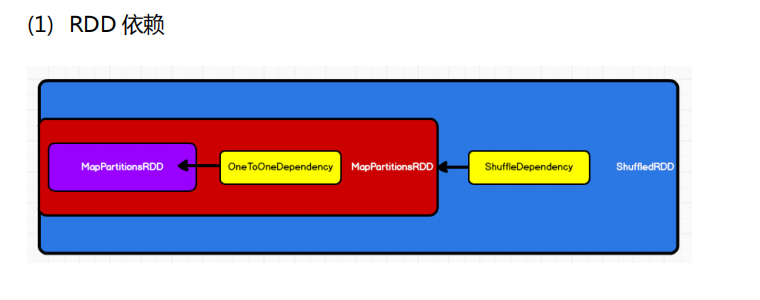
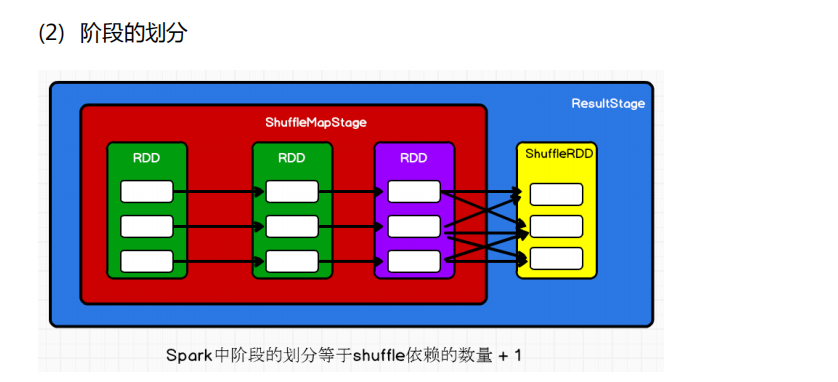
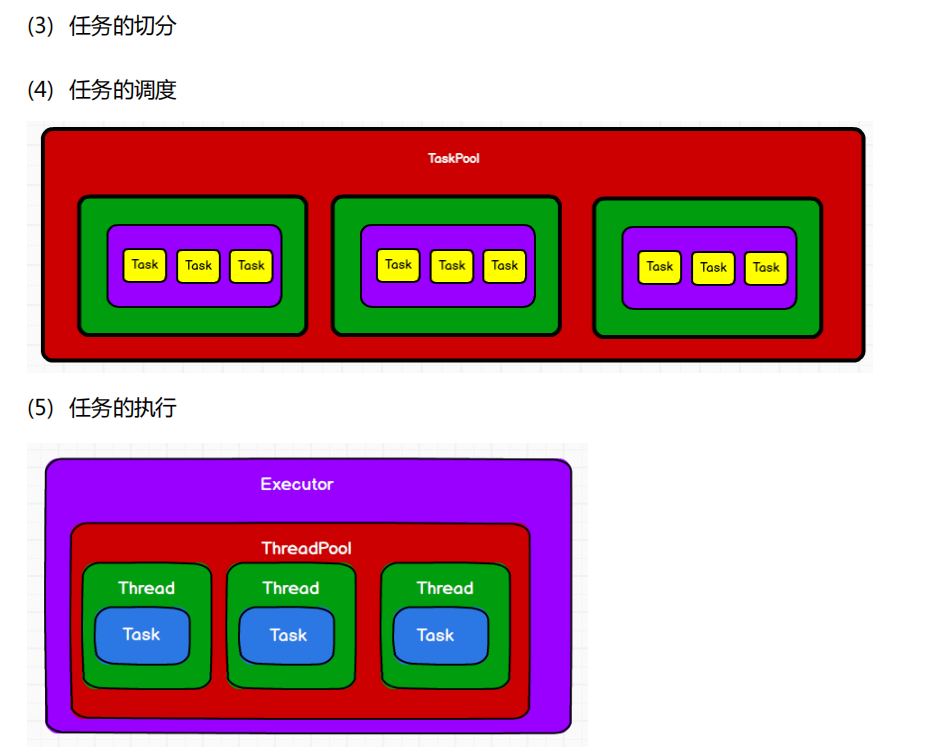
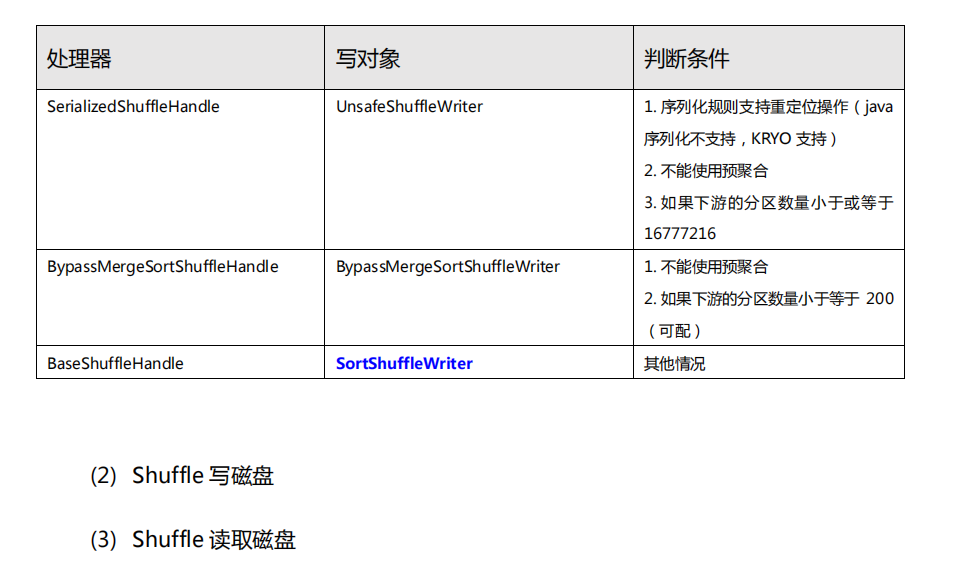
4. Shuffle
详情可以参考下面的跳转:
4. Shuffle && 5. 内存的管理

5. 内存的管理
详情可以参考下面的跳转:
4. Shuffle && 5. 内存的管理