学习基于如下书籍,仅供自己学习,用来记录回顾,非教程。
<PyTorch深度学习和图神经网络(卷2)——开发应用>一书配套代码:
https://github.com/aianaconda/pytorch-GNN-2nd-
百度网盘链接:https://pan.baidu.com/s/1dnq5IbFjjdekAR54HLb9Pg
提取码:k7vi
压缩包密码:dszn
图片分类模型
2012年起,在ILSVRC竞赛中获得冠军的模型如下
2012年:AlexNet
2013年:OverFeat
2014年:GoogLeNet、VGG(亚军)
2015年:ResNet
2016年:Trimps-Soushen、ResNeXt(亚军)
2017年:SENet
之后又有很多性能更加出色的如PNASNet、DenseNet、EfficientNet。
Inception系列模型
它主要是解决深层网络中3个问题:
训练数据有限,参数太多,容易过拟合。
网络越大,计算复杂度越大,难以应用。
网络越深,梯度越往后传,越容易消失(梯度弥散),难以优化模型。
多分支结构
原始的Inception模型采用1X1、3X3、5X5卷积和3X3最大池化,增加了网络的宽度,增强了网络对不同尺寸的适应性。
全局均值池化
代替最后的全连接输出层,如1000个分类,最后一层的特征图要1000个,可以直接得出分类。
Inception V1模型
在大卷积核前和池化后加入1X1卷积,起到降低特征图厚度的作用。
Inception V2模型
融入当时的主流技术,加入了BN层和梯度截断技术,借鉴了VGG模型,用两个3X3代替一个5X5,降低了参数量,提高了运算速度。
Inception V3模型
将3X3卷积分解成1XN和NX1,让卷积核分解更小,基于线性代数的原理。
假设256个特征输入,256个特征输出,Inception层只能执行3X3卷积,也就是要完成256X256X3X3(589824)次乘积累加运算。假设现在要减少进行卷积运算的特征数量,将其变为64个(256/4),先进行256到64的1X1的卷积,然后在所有Inception层的分支上进行64次卷积,最后使用一个64到256的特征的1X1卷积。现在有256X64X1X1+64X64X3X3+64X256X1X1=69632次计算量,提高了运算速度。
实际测试中,在前几层效果不好,但对特征图大小为12到20的中间层效果明显
Inception V4模型
结合ResNet模型,加入了残差连接。
Inception-ResNet V2模型
在网络复杂度相近的情况下,该模型略优于V4,残差提高网络准确率,而不会增加计算量的作用。
通过将3个带有残差连接的Inception模型和一个Inception V4模型组合,就可以在ImageNet上得到3.08%的错误率。
ResNet模型
模型层数加深,梯度在多层传播时会越来越小,直到消失,层数越多训练误差会越来越大。ResNet解决深层无法训练的问题,借鉴了高速网络模型的思想,在前馈上加一个直接连接,直连可以保留梯度。作用是将网络串行改成了并行,V4结合残差原理不用残差连接就可以达到ResNet V2等同的效果。
DenseNet模型
2017年被提出,是密集连接的卷积神经网络,每个层都会接受前面所有层的作为输入。主要优势如下:
可以直达最后的误差信号,减轻梯度消失问题
拼接特征图实现短路连接,实现特征重用,每个层独有的特征图比较小
前面的特征图直接传给后面,可以充分利用不同层级的特征
不如就是可能耗费很多GPU显存
稠密块
其中只含有两个卷积层,分别为1X1,3X3。每个稠密块是L个全连接组成,不同稠密块之间没有。
PNASNet模型
使用了残差结构和多分支卷积技术,同时还添加了深度可分离卷积和空洞卷积的处理。
组卷积
了解深度可分离卷积要了解组卷积。组卷积对输入数据先分组,能增强卷积核之间对角相关性,减少训练参数,不容易过拟合,类似于正则效果。
深度可分离卷积
Xception模型是Inception系列模型的统称,主要目的是将通道相关性和平面空间维度相关性进行解耦,使通道关系和平面空间关系上的卷积操作相互独立,达到更好的效果。
空洞卷积
也称为扩张卷积,在不做池化操作而导致损失信息的情况下,加大了卷积的感受野,让每个卷积输出都包含更大的范围。
EfficientNet模型
是谷歌公司通过机器搜索得到的模型,构建步骤如下。
使用强化学习算法实现的MnasNet模型生成基准模型EfficientNet-B0
采用复合缩放,在预先设定的内存和计算量大小的限制条件下,对EfficientNet-B0模型的深度、宽度(特征图通道数)、图片尺寸这3个维度同时进行缩放,这3个维度的缩放比例由网络搜索得到,最终输出了EfficientNet模型。
MBConv
内部由多个MBConv卷积块实现的,也用了类似残差连接的结构,在短连接部分使用了SE模块,并且将常用的ReLU激活函数换成了Swish激活函数,另外使用了Drop Connect层来代替传统的Dropout层(丢弃隐藏层输入而不是输出)。
实例:使用预训练模型识别图片内容
这里用models模块创建模型,然后载入下载好的参数。
model = models.resnet18()
model.load_state_dict(torch.load(r"E:\desktop\Home_Code\pytorch\2-chapter1\some\resnet18-5c106cde.pth")) #true 代表下载
model = model.eval()
记得要进行model.eval()
from PIL import Image #引入基础库
import matplotlib.pyplot as plt
import json
import numpy as np
import torch #引入PyTorch库
import torch.nn.functional as F
from torchvision import models, transforms #引入torchvision库
model = models.resnet18()
model.load_state_dict(torch.load(r"E:\desktop\Home_Code\pytorch\2-chapter1\some\resnet18-5c106cde.pth")) #true 代表下载
model = model.eval()
labels_path = r'pytorch\2-chapter1\some\imagenet_class_index.json' #处理英文标签
with open(labels_path) as json_data:
idx_to_labels = json.load(json_data)
def getone(onestr):
return onestr.replace(',',' ')
with open(r'pytorch\2-chapter1\some\中文标签.csv','r+') as f: #处理中文标签
zh_labels =list( map(getone,list(f)) )
print(len(zh_labels),type(zh_labels),zh_labels[:5]) #显示输出中文标签
transform = transforms.Compose([ #对图片尺寸预处理
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize( #对图片归一化预处理
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
def preimg(img): #定义图片预处理函数
if img.mode=='RGBA': #兼容RGBA图片
ch = 4
print('ch',ch)
a = np.asarray(img)[:,:,:3]
img = Image.fromarray(a)
return img
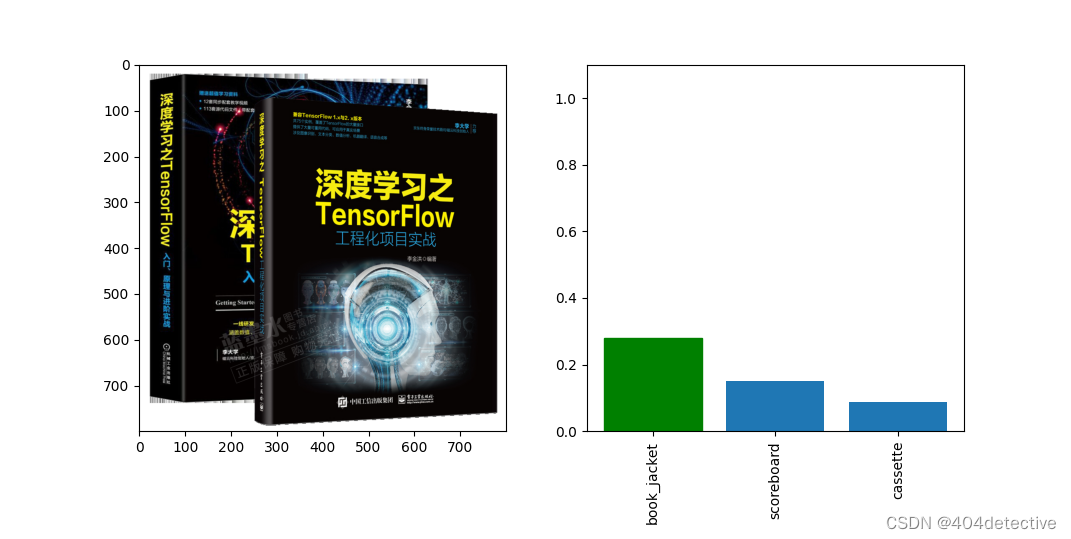
im =preimg( Image.open(r'pytorch\2-chapter1\some\book.png') ) #打开图片
transformed_img = transform(im) #调整图片尺寸
inputimg = transformed_img.unsqueeze(0) #增加批次维度
output = model(inputimg) #输入模型
output = F.softmax(output, dim=1) #获取结果
# 从预测结果中取出前3名
prediction_score, pred_label_idx = torch.topk(output, 3)
prediction_score = prediction_score.detach().numpy()[0] #获取结果概率
pred_label_idx = pred_label_idx.detach().numpy()[0] #获取结果的标签id
predicted_label = idx_to_labels[str(pred_label_idx[0])][1]#取出标签名称
predicted_label_zh = zh_labels[pred_label_idx[0] + 1 ] #取出中文标签名称
print(' 预测结果:', predicted_label,predicted_label_zh,
'预测分数:', prediction_score[0])
#可视化处理,创建一个1行2列的子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 8))
fig.sca(ax1) #设置第一个轴是ax1
ax1.imshow(im) #第一个子图显示原始要预测的图片
#设置第二个子图为预测的结果,按概率取前3名
barlist = ax2.bar(range(3), [i for i in prediction_score])
barlist[0].set_color('g') #颜色设置为绿色
#预测结果前3名的柱状图
plt.sca(ax2)
plt.ylim([0, 1.1])
#竖直显示Top3的标签
plt.xticks(range(3), [idx_to_labels[str(i)][1][:15] for i in pred_label_idx ], rotation='vertical')
fig.subplots_adjust(bottom=0.2) #调整第二个子图的位置
plt.show() #显示图像
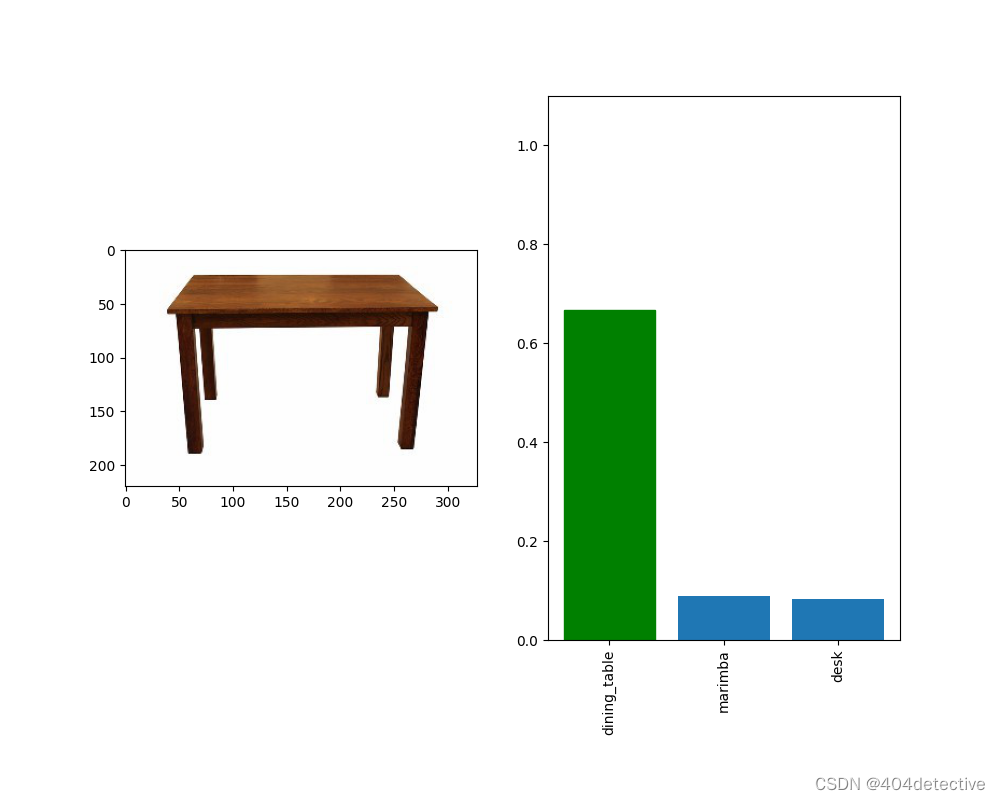
预测结果: book_jacket 防尘罩 书皮
预测分数: 0.27850005
成功识别出书皮,不过可信度不是很高
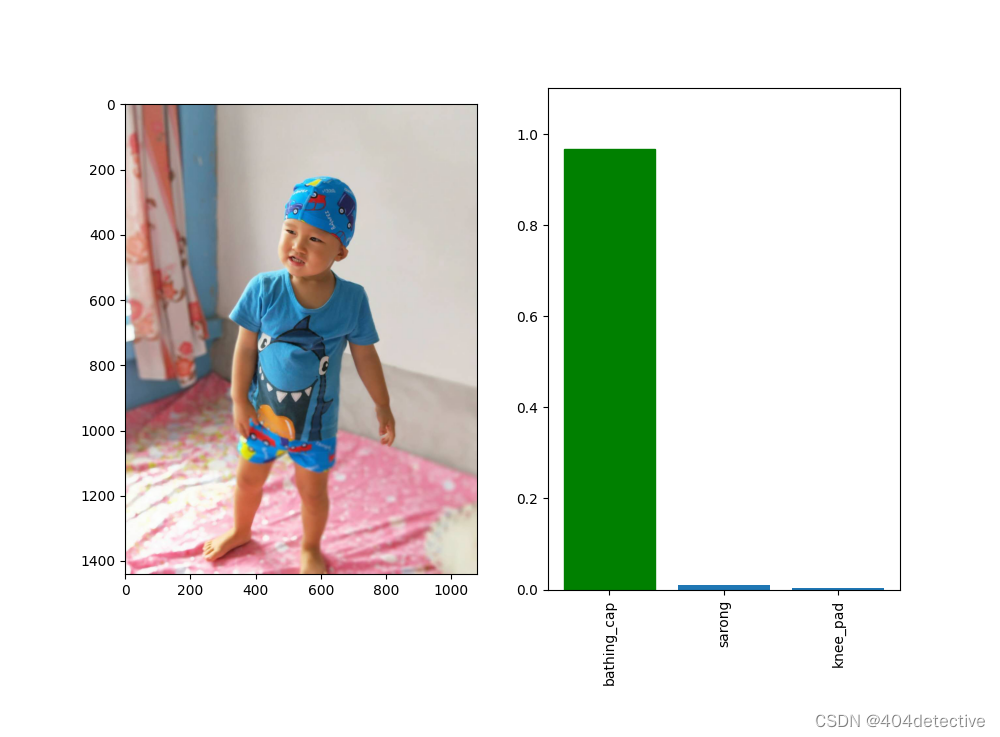
试试别的
迁移学习
把在一个任务上训练完成的模型进行简单的修改,再用另一个任务的数据继续训练,使之能够完成新的任务。
如在ImageNet数据集上训练过的ResNet模型,原任务是用来图片分类的,可以对它进行修改,使之用在目标定位任务上。
迁移学习是机器学习的分支,按照学习方式可以分为基于样本的迁移、基于特征的迁移、基于模型的迁移、基于关系的迁移。
初衷是节省人工标注样本的时间,让模型通过一个已有的标记数据领域向未标记数据领域进行迁移,从而训练出适用于该领域的模型。好处如下:
对于本身数据集很小(几千张图片)的情况,从头开始训练几千万个参数的大型神经网络模型不现实,越大的模型数据量需求越大,过拟合无法避免。如果还想用大型模型的超强特征提取能力,只能靠微调已经训练好的模型。
可以降低训练成本,用导出特征向量的方法,后期训练成本非常低。
前人训练的模型大概率比你自己从零训练要强大,没必要重复造轮子。
与微调的关系没有严格的区分,作者的理解,微调是迁移学习的后期,是它的一部分,一个技巧。
实例:使用迁移学习识别多种鸟类
import glob
import os
import numpy as np#引入基础库
from PIL import Image
import matplotlib.pyplot as plt #plt 用于显示图片
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.utils.data import Dataset,DataLoader
import torchvision
import torchvision.models as models
from torchvision.transforms import ToPILImage
import torchvision.transforms as transforms
def load_dir(directory,labstart=0):#获取所有directory中的所有图片和标签
#返回path指定的文件夹所包含的文件或文件夹的名字列表
strlabels = os.listdir(directory)
#对标签进行排序,以便训练和验证按照相同的顺序进行
strlabels.sort()
#创建文件标签列表
file_labels = []
for i,label in enumerate(strlabels):
# print(label)
jpg_names = glob.glob(os.path.join(directory, label, "*.jpg"))
# print(jpg_names)
#加入列表
file_labels.extend(zip( jpg_names,[i+labstart]*len(jpg_names)) )
return file_labels,strlabels
def load_data(dataset_path): #定义函数加载文件名称和标签
sub_dir= sorted(os.listdir(dataset_path) )#跳过子文件夹
start =1 #none:0
tfile_labels,tstrlabels=[],['none']
for i in sub_dir:
directory = os.path.join(dataset_path, i)
if os.path.isdir(directory )==False: #只处理目录中的数据
print(directory)
continue
file_labels,strlabels = load_dir(directory ,labstart = start )
tfile_labels.extend(file_labels)
tstrlabels.extend(strlabels)
start = len(strlabels)
#理解为解压缩,把数据路径和标签解压缩出来
filenames, labels=zip(*tfile_labels)
return filenames, labels,tstrlabels
def default_loader(path):
return Image.open(path).convert('RGB')
class OwnDataset(Dataset):
def __init__(self,img_dir, labels, indexlist= None, transform=transforms.ToTensor(),
loader=default_loader,cache=True):
self.labels = labels
self.img_dir = img_dir
self.transform = transform
self.loader=loader
self.cache = cache #缓存标志
if indexlist is None:
self.indexlist = list(range(len(self.img_dir)))
else:
self.indexlist = indexlist
self.data = [None] * len(self.indexlist) #存放样本图片
def __getitem__(self, idx):
if self.data[idx] is None: #第一次加载
data = self.loader(self.img_dir[self.indexlist[idx]])
if self.transform:
data = self.transform(data)
else:
data = self.data[idx]
if self.cache: #保存到缓存里
self.data[idx] = data
return data, self.labels[self.indexlist[idx]]
def __len__(self):
return len(self.indexlist)
data_transform = { #定义数据的预处理方法
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
def Reduction_img(tensor,mean,std):#还原图片
dtype = tensor.dtype
mean = torch.as_tensor(mean, dtype=dtype, device=tensor.device)
std = torch.as_tensor(std, dtype=dtype, device=tensor.device)
tensor.mul_(std[:, None, None]).add_(mean[:, None, None])#扩展维度后计算
dataset_path = r'pytorch/2-chapter1/some2/'
filenames, labels,classes = load_data(dataset_path)
#打乱数组顺序
np.random.seed(0)
label_shuffle_index = np.random.permutation( len(labels) )
label_train_num = (len(labels)//10) *8
train_list = label_shuffle_index[0:label_train_num]
test_list = label_shuffle_index[label_train_num: ]
train_dataset=OwnDataset(filenames, labels,train_list,data_transform['train'])
val_dataset=OwnDataset(filenames, labels,test_list,data_transform['val'])
train_loader =DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
val_loader=DataLoader(dataset=val_dataset, batch_size=32, shuffle=False)
#
sample = iter(train_loader)
images, labels = sample.__next__()
print('样本形状:',np.shape(images))
print('标签个数:',len(classes))
mulimgs = torchvision.utils.make_grid(images[:10],nrow=10)
Reduction_img(mulimgs,[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
_img= ToPILImage()( mulimgs )
plt.axis('off')
plt.imshow(_img)
plt.show()
print(','.join('%5s' % classes[labels[j]] for j in range(len(images[:10]))))
############################################
#指定设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
def get_ResNet(classes,pretrained=True,loadfile = None):
ResNet=models.resnet101(pretrained)# 这里自动下载官方的预训练模型
if loadfile!= None:
ResNet.load_state_dict(torch.load( loadfile)) #加载本地模型
# 将所有的参数层进行冻结
for param in ResNet.parameters():
param.requires_grad = False
# 这里打印下全连接层的信息
print(ResNet.fc)
x = ResNet.fc.in_features #获取到fc层的输入
ResNet.fc = nn.Linear(x, len(classes)) # 定义一个新的FC层
print(ResNet.fc) # 最后再打印一下新的模型
return ResNet
ResNet=get_ResNet(classes)
ResNet.to(device)
criterion = nn.CrossEntropyLoss()
#指定新加的fc层的学习率
optimizer = torch.optim.Adam([ {'params':ResNet.fc.parameters()}], lr=0.001)
def train(model,device, train_loader, epoch,optimizer):
model.train()
allloss = []
for batch_idx, data in enumerate(train_loader):
x,y= data
x=x.to(device)
y=y.to(device)
optimizer.zero_grad()
y_hat= model(x)
loss = criterion(y_hat, y)
loss.backward()
allloss.append(loss.item())
optimizer.step()
print ('Train Epoch: {}\t Loss: {:.6f}'.format(epoch,np.mean(allloss) ))
def test(model, device, val_loader):
model.eval()
test_loss = []
correct = []
with torch.no_grad():
for i,data in enumerate(val_loader):
x,y= data
x=x.to(device)
y=y.to(device)
y_hat = model(x)
test_loss.append( criterion(y_hat, y).item()) # sum up batch loss
pred = y_hat.max(1, keepdim=True)[1] # get the index of the max log-probability
correct.append( pred.eq(y.view_as(pred)).sum().item()/pred.shape[0] )
print('\nTest set——{}: Average loss: {:.4f}, Accuracy: ({:.0f}%)\n'.format(
len(correct),np.mean(test_loss), np.mean(correct)*100 ))
if __name__ == '__main__':
firstmodepth = './finetuneRes101_1.pth'
if os.path.exists(firstmodepth) ==False:
print("_____训练最后一层________")
for epoch in range(1, 2):
train(ResNet,device, train_loader,epoch,optimizer )
test(ResNet, device, val_loader )
# 保存模型
torch.save(ResNet.state_dict(), firstmodepth)
secondmodepth = './finetuneRes101_2.pth'
optimizer2=optim.SGD(ResNet.parameters(),lr=0.001,momentum=0.9)
exp_lr_scheduler = lr_scheduler.StepLR(optimizer2, step_size=2, gamma=0.9)
for param in ResNet.parameters():
param.requires_grad = True
if os.path.exists(secondmodepth) :
ResNet.load_state_dict(torch.load( secondmodepth)) #加载本地模型
else:
ResNet.load_state_dict(torch.load(firstmodepth)) #加载本地模型
print("_____全部训练________")
for epoch in range(1, 100):
train(ResNet,device, train_loader,epoch,optimizer2 )
if optimizer2.state_dict()['param_groups'][0]['lr']>0.00001:
exp_lr_scheduler.step()
print("___lr:" ,optimizer2.state_dict()['param_groups'][0]['lr'] )
test(ResNet, device, val_loader )
# 保存模型
torch.save(ResNet.state_dict(), secondmodepth)
训练太慢了,而且输出结果与书籍不符合,标签个数就不一样,应该为201个,我是6个。应该用CUB-200训练,而不是压缩包里的6类数据。这个锐龙显卡不知道怎么加速,就不训练了。
随机数据增强
目前效果最好的Efficient系列模型中,B7版本中就是使用了随机数据增强,RandAugment比自动数据增强(AutoAugment)更简单好用,后者有30多个参数,前者将其简化为2个,图片的N次变换,和每次变换的强度M,取值为0到10。
分类模型中常用的三种损失函数
BCELoss,用于单标签二分类,或者多标签二分类,一个样本可以有多个分类不互斥,输出为(Batch,C),Batch样本数量,C是类别数量。每个C值代表属于一类标签的概率。
BCEWithLogitsLoss,同上,但对网络输出结果进行了一次Sigmoid。
CrossEntropyLoss,用于多类别分类,每个C是互斥的,相互关联的,求每个C的Softmax。
样本均衡
训练样本不均衡时,可以用过采样,欠采样,数据增强等手段来避免过拟合。
采样器类Sample中有一类派生的权重采样类WeightedRandomSampler,能够在加载数据时进行随机顺序采样。
DataLoader类中使用了采样器Sampler类就不能使用shuffle参数
从深度卷积模型中提取视觉特征
前面的实例通过替换预训练模型输出层的方式,实现对其他图片的分类任务,这种迁移学习本质上是借助了预训练模型对图片处理后的视觉特征,这在深度学习任务中起到了很大的作用。如目标检测、语义分割,甚至是图像与文本的混合处理模型等,迁移学习只是其中一种。
有两种方式可以实现视觉特征的提取:钩子函数、重组结构
钩子函数
略
重组结构
ResNet2=nn.Sequential(*list(ResNet.children( ))[:-1])
](https://img-blog.csdnimg.cn/7fd0cb619036418daf38ba678f357a9f.png)