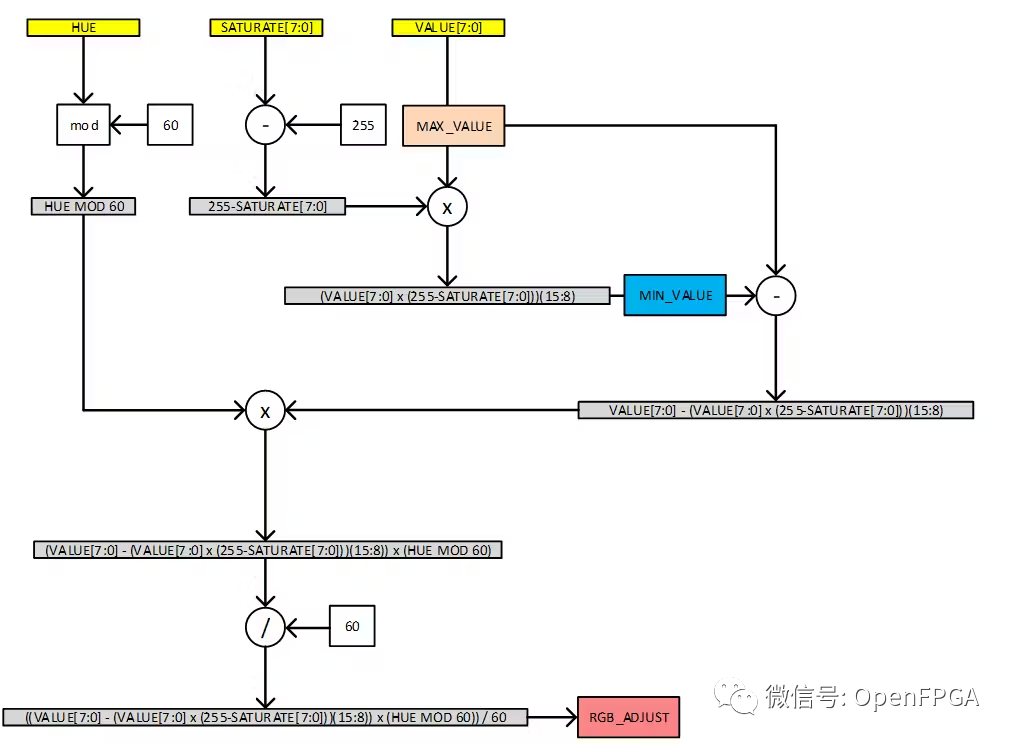
一、说明
想要开始您的下一个数据可视化项目吗?首先与数据清理友好。数据清理是任何数据管道中的重要步骤,可将原始的“脏”数据输入转换为更可靠、相关和简洁的数据输入。诸如Tableau Prep或Alteryx之类的数据准备工具就是为此目的而创建的,但是当您可以使用Python等开源编程语言完成任务时,为什么要在这些服务上花钱呢?本文将指导您完成使用 Python 脚本为可视化准备数据的过程,为数据准备工具提供更具成本效益的替代方案。

摄影:Robert Katzki on Unsplash
二、数据清洗概说
注意:在本文中,我们将重点介绍如何让 Tableau 为数据可视化做好准备,但主要概念同样适用于其他商业智能工具。
我明白了。数据清理似乎是将可视化或仪表板变为现实的漫长过程中的又一步。但这是至关重要的,而且可以令人愉快。这是您通过深入了解您拥有和没有的数据以及为实现最终分析目标而必须采取的相应决策来适应数据集的方式。
虽然 Tableau 是一种多功能的数据可视化工具,但有时获得答案的途径并不明确。在这里,在将数据集加载到 Tableau 之前对其进行处理可能是您最大的秘密帮手。让我们探讨一下为什么在将数据清理与 Tableau 集成之前,数据清理是有益的一些关键原因:
- 消除不相关的信息: 原始数据通常包含不必要或重复的信息,这些信息可能会使您的分析混乱。通过清理数据,您可以消除浪费,并将可视化集中在最相关的数据功能上。
- 简化数据转换:如果您对要生成的可视化有清晰的认识,那么在将数据加载到 Tableau 之前执行这些预转换可以简化流程。
- 团队内部更易于转移:定期更新数据源时,新增数据源可能会带来不一致,并可能破坏 Tableau。借助 Python 脚本和代码描述(更正式地称为 markdown 文档),您可以有效地共享和授权其他人理解您的代码并解决可能出现的任何编程问题。
- 节省数据刷新时间: 需要定期刷新的数据可以从利用 Hyper API 中受益,Hyper API 是一个生成特定于 Tableau 的 Hyper 文件格式的应用程序,允许自动上传数据提取,同时提高数据刷新过程的效率。
现在我们已经介绍了准备数据的一些优点,让我们通过创建一个简单的数据管道来将其付诸实践。我们将探讨如何将数据清理和处理集成到工作流中,并帮助简化可视化效果的管理。
三、使用 Python 脚本创建数据管道
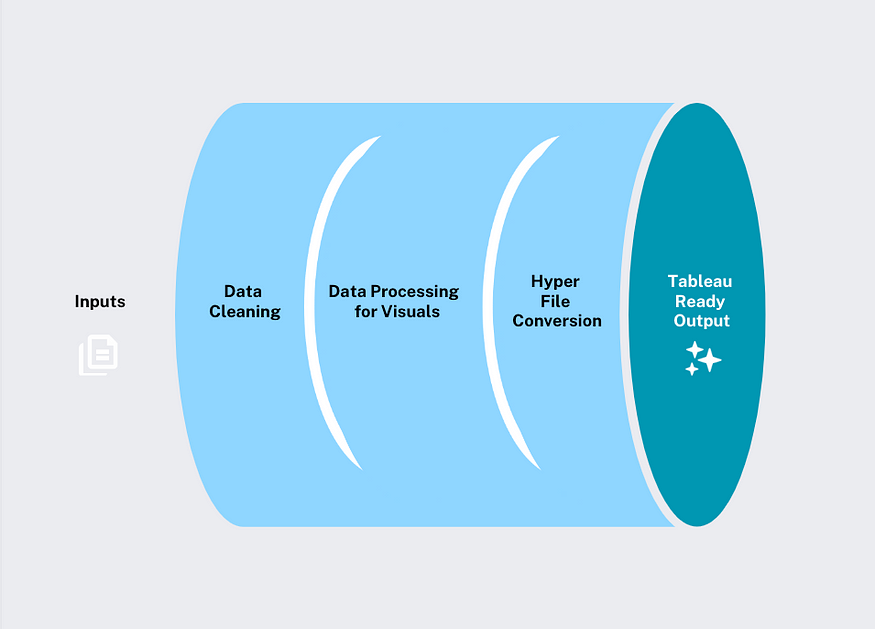
图片来源:作者
我们的数据过程非常简单:数据清理、视觉对象数据处理,并将其转换为 Tableau 就绪的超级文件以实现无缝集成。
在深入研究我们的工作示例之前,最后一点是,对于 Hyper 文件转换,您需要下载库。此库简化了将 Pandas 数据帧转换为 Tableau .hyper 数据提取的过程。您可以通过在所选环境的终端中使用以下代码轻松完成此操作(对于那些不太熟悉环境的人来说,这是一篇关于它们是什么以及如何安装某些库的很棒的入门文章):pantab
#run the following line of code to install the pantab library in your environment
pip install pantab四、教程:使用 Python 进行数据准备(探索加拿大的电动汽车牌照)
我们将根据加拿大统计局的政府可用数据,专注于不同电动汽车制造商和车型的受欢迎程度。
重要的是要注意,这建立在我之前的文章中使用的数据集之上:使用R进行电动汽车分析。如果您有兴趣了解数据集的初步探索以及所做决策背后的基本原理,请参阅它以获取更多详细信息。本教程重点介绍如何构建 Python 脚本,在初始输入之后的每一步中,我们将每个 Python 脚本的输出保存到各自的文件夹中,如下所述:

图片来源:作者
文件夹过程可确保管道井井有条,并且我们能够记录项目中每个输出。让我们开始构建我们的第一个 Python 脚本!
4.1 数据清理
管道中的初始脚本遵循数据清理的基本步骤,对于此数据集,这些步骤包括:保留/重命名相关列、删除 null 和/或重复项,以及使数据值保持一致。
我们可以从指定输入文件位置和输出文件的目的地开始。此步骤很重要,因为它允许我们在同一位置组织文件的不同版本,在这种情况下,我们每月修改文件输出,因此每个文件输出按月分隔,如文件名末尾所示:2023_04
#import necessary packages
import pandas as pd
import os.path as path
inputfile = "Data/prep_tableau/input/izev-april-2023.csv"
outputfile = 'clean_data/clean_data_2023-04.csv'以下代码读取原始.csv输入,并定义我们要保留的列。在这种情况下,我们有兴趣保留与所购买车型类型相关的信息,而忽略与汽车经销商或任何其他不相关的列。
# read in the data
df = pd.read_csv(inputfile)
# removing certain columns
clean_df = df[df.columns[~df.columns.isin(['Incentive Request Date',
'Government of Canada Fiscal Year (FY)',
'Dealership Province / Territory '
'Dealership Postal Code','BEV/PHEV/FCEV - Battery equal to or greater than 15 kWh or \nElectric range equal to or greater than 50 km',
'BEV, PHEV ? 15 kWh or PHEV < 15 kWh (until April 24, 2022) \nand\nPHEV ? 50 km or PHEV < 50 km and FCEVs ? 50 km or FCEVs < 50 km\n(April 25, 2022 onward)',
'Individual or Organization \n(Recipient)',
'Country'])]]现在我们可以缩短列名,删除前导或尾随空格,并添加下划线以便于理解。
# shortening longer column names
clean_df = clean_df.rename({"Battery-Electric Vehicle (BEV), Plug-in Hybrid Electric Vehicle (PHEV) or Fuel Cell Electric Vehicle (FCEV)" : "EV_Type",
"Recipient Province / Territory":"Province.Recipient"},axis="columns")
# adding and removing white spaces underscores between column names
clean_df.columns = clean_df.columns.str.strip()
clean_df.columns = clean_df.columns.str.replace(' ', '_') 接下来,在检查数据集中只有几个空条目后,我们将使用该函数删除空数据。此时,您还希望删除重复项,但对于此特定数据集,我们不会删除。这是因为存在大量重复信息,并且在没有行标识符的情况下,删除重复项将导致数据丢失。.dropna
# removing nulls
clean_df = clean_df.dropna(how="all") 最后一步是将数据作为.csv文件保存到适当的文件夹位置,该位置将放置在我们共享目录的文件夹中。clean_data
# save to csv
clean_path = path.abspath(path.join(__file__ ,'../', outputfile ))
clean_df.to_csv(clean_path,index=False) 请注意我们如何使用 引用文件,并使用 bash 命令指定文件目录,其中指示以前的文件夹。我们的数据清理脚本到此结束。现在让我们进入数据处理阶段!__file__../
访问完整的工作代码和组装脚本可以在我的Github存储库中找到。
4.2 可视化的数据处理
让我们重新审视一下我们试图实现的可视化目标,这些目标旨在突出注册电动汽车普及率的变化。为了有效地展示这一点,我们希望最终的 Tableau 就绪数据集包含以下功能,我们将对这些功能进行编码:
- 按年份划分的车辆绝对数量
- 按年份划分的车辆比例
- 登记车辆增减幅度最大
- 登记车辆排名
- 以前注册比较的车辆排名
根据您打算生成的视觉效果,创建理想列可能是一个迭代过程。就我而言,我在构建可视化后包括了最后一列,因为我知道我想为查看者提供排名差异的视觉比较,因此相应地调整了 Python 脚本。
对于以下代码,我们将重点关注模型聚合数据集,因为品牌的其他数据集非常相似。让我们首先定义我们的和:inputfileoutputfile
inputfile = "/Data/prep_tableau/clean_data/clean_data_2023-04.csv"
outputfile = "clean_model/ev_vehicle_models_2023-04.csv" #edit date as needed 请注意我们如何引用 from 文件夹,这是我们的数据清理脚本的输出。inputfileclean_data
下面的代码读取数据,并创建聚合计数的数据框:Vehicle_Make_and_ModelCalendar_Year
# Read in the data
auto_df = pd.read_csv(inputfile)
# Defining the Dataframe and renaming columns
processed_auto = pd.DataFrame(auto_df.groupby(["Vehicle_Make_and_Model", "Calendar_Year"])["Calendar_Year"].count())
processed_auto = processed_auto.rename(columns={"Calendar_Year": "count"}).reset_index() 该函数的执行类似于 Excel 中的数据透视表函数,其中它将每个值作为列输入。pivotCalendar_Year
# Pivoting the data based on Vehicle Make and Year with their respective counts
processed_auto_pivot = processed_auto.pivot(index='Vehicle_Make_and_Model', columns='Calendar_Year', values='count').reset_index()
然后,脚本使用 For 循环来创建输入。这将计算每个模型的比例,以便能够在同一比例上比较每个模型,并为每年创建一个列:per_1K
# Defining column list required for the For Loop
col_list = range(2019, 2024)
# Looking at magnitude every 1000 cars - For loop
for year in col_list:
column_name = f"per_1K_{year}"
total_column = year
processed_auto_pivot[column_name] = round(processed_auto_pivot[total_column] / processed_auto_pivot[total_column].sum(), 4) * 1000
通过按年计算比例,我们可以计算出从 2019 年数据集开始到 2022 年最后一个全年数据的最大增减。
#Calculating prop_num_change
processed_auto_pivot["prop_num_change"] = processed_auto_pivot["per_1K_2022"] - processed_auto_pivot["per_1K_2019"]
在这里,该函数用于将按年份分隔的列重新透视回行,因此我们只有一列及其关联值。meltper_1Kper_1K
# Pivoting for totals
cars_per1K = pd.melt(
processed_auto_pivot,
id_vars=["Vehicle_Make_and_Model", "prop_num_change"],
value_vars=["per_1K_2019", "per_1K_2020", "per_1K_2021", "per_1K_2022", "per_1K_2023"],
var_name="year",
value_name="per_1K"
).loc[:, ["Vehicle_Make_and_Model", "year", "per_1K", "prop_num_change"]下面的代码允许我们联接绝对计数和我们刚刚创建的其他计算。
# Making year names consistent with processed_auto
cars_per1K["year"]= cars_per1K["year"].str.replace("per_1K_", "")
#joining the total counts with 1K totals
ev_totals = processed_auto.merge(cars_per1K, left_on=["Vehicle_Make_and_Model", "Calendar_Year"], right_on=["Vehicle_Make_and_Model", "year"], how="left")
#dropping irrevelant column
ev_totals = ev_totals.drop("year", axis=1)现在,我们可以使用许可证计数创建列,并按 和 对这些值进行排序。rankVehicle_Make_and_ModelCalendar_Year
#ranking model by counts
ev_totals['rank'] = ev_totals.groupby('Calendar_Year')['count'].rank(ascending=False, method="min")
ev_totals = ev_totals.sort_values(['Vehicle_Make_and_Model', 'Calendar_Year'])要创建的最后一列是使用该函数创建的列。previous_rankshift
#creating previous rank, lag by rank
ev_totals['previous_rank'] = ev_totals.groupby('Vehicle_Make_and_Model')['rank'].shift()最后,我们能够将输出保存到管道中的文件夹路径,为我们提供一个可视化就绪数据集。clean_model
# save to csv
model_path = path.abspath(path.join(__file__ ,'../', outputfile ))
ev_totals.to_csv(model_path,index=False)作为友情提醒,完整的 python 脚本代码,包括已处理数据集的代码,可以在我的 GitHub 存储库中找到。
clean_brand
4.3 将最终数据文件转换为 .hyper 文件格式
管道的最后一步相对简单,因为我们剩下要做的就是将我们创建.csv处理的文件转换为 .hyper 文件格式。只要您下载了前面提到的库,这应该相对容易。pantab
值得一提的是,在 Tableau 中,连接的数据既可以实时连接,也可以提取。实时连接可确保数据流持续,来自源的更新几乎立即反映在 Tableau 中。提取的数据涉及 Tableau 创建一个文件扩展名为 .hyper 的本地文件,其中包含数据的副本(可在此处找到数据源的详细说明)。它的主要优点是其快速加载功能,Tableau 可以更有效地访问和呈现信息,这对于大型数据集特别有用。
超级文件转换脚本的代码从加载和包开始,然后读取 Tableau 所需的数据集。pandaspantabcleaned_model
import pandas as pd
import pantab
#read in files
model_df = pd.read_csv('Data/prep_tableau/clean_model/ev_vehicle_models_2023-04.csv') 最后一行代码使用生成 .hyper 文件并将其保存到文件夹中的函数。frame_to_hyper hyper
#save to hyper file
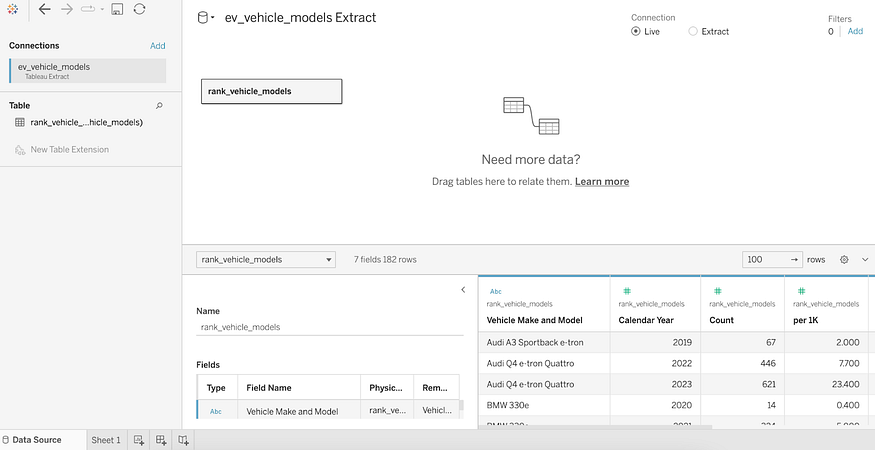
pantab.frame_to_hyper(model_df, "hyper/ev_vehicle_models.hyper", table="rank_vehicle_models") 最后一步,我们可以通过打开新工作簿轻松地将 .hyper 文件格式加载到 Tableau 中,在该部分中,您可以通过选择 .当我们加载文件时,它应该显示为 Tableau 数据提取,如下面的屏幕截图所示,您的数据已准备好在其上构建视觉对象!select a filemoreev_vehicle_models.hyper
五、结语
通过将深思熟虑的规划纳入可视化效果,您可以通过创建简单的数据管道来简化仪表板的维护。如果您缺乏资源,请不要担心;像Python这样的开源编码程序提供了强大的功能。最后,作为友好的提醒,要访问Python脚本,请在此处查看我的GitHub存储库。