前言:人工评估( Manual Evaluation / Human Evaluation)是文本生成工作评估中非常重要的一环。在对模型的文本生成质量进行评估时,除客观的自动评价指标,还需有人工评价指标的主观判断,综合二者的结果完成评估。实际应用中,客观评价指标与人工评估的结合使用,往往能够更加全面地反映生成文本的质量。本篇博客重点介绍常用的人工评价方式,如想了解客观评价指标原理及计算方式请移步本篇博文。
目录
- 评估场景设置
- 1. 评估人数
- 2. 评估维度
- 3. 评估机制
- 3.1 区间式评估(RankME)
- 3.2 量表式评估(Likert Scale)
- 3.3 比较式评估(pair-wise comparison)
- 一致性校验(Inter-Evaluator Agreement / Inter-Annotator Agreement)
- 1. Percentage agreement
- 计算原理
- 计算方式
- 2. Kappa( κ \kappa κ)
- 2.1 Cohen's Kappa (Cohen's κ \kappa κ)
- 维基定义
- 应用场景
- 计算原理
- 计算示例
- 代码实现
- 2.2 Fleiss' Kappa (Fleiss' κ \kappa κ)
- 维基定义
- 应用场景
- 计算示例
- 代码实现
- 3. Krippendorff's Alpha (Krippendorff’s α \alpha α)
- 论文示例
- 参考资料
根据 这篇论文,人工评估广义上可以分为两类:Intrinsic Evaluation 与 Extrinsic Evaluation,前者较为常用,后续内容均为 Intrinsic Evaluation 的介绍。
评估场景设置
在人工评估设置之前,要阐明评估场景,包括评估人数、评估维度、评估机制等设置,并在评估结束后对评估结果进行一致性校验,下面分别对上述设置进行说明。
1. 评估人数
原则上来讲,参与人工评价的评估者越多越好。评估者可以是专家,众包人员,甚至终端用户。在阅读论文过程中,总结下来发现评估者 3 人居多,也有高达 50 人的。
-
3 位评估者,论文示例:
- Read, Attend and Comment: A Deep Architecture for Automatic News Comment Generation (ACL, 2019)
- Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model (ACL, 2019)
-
5 位评估者,论文示例:
- Long and Diverse Text Generation with Planning-based Hierarchical Variational Model (EMNLP, 2019)
-
6 位评估者,论文示例:
- Text is NOT Enough: Integrating Visual Impressions into Open-domain Dialogue Generation (ACM Multimedia, 2021)
-
50 位评估者,论文示例:
- Affective Feedback Synthesis Towards Multimodal Text and Image Data (TOMM, 2023)
2. 评估维度
由于文本生成模型完成的下游任务多样,对生成文本衡量的维度也有所差别。对于机器翻译、摘要生成、图像描述以及 data-to-text (D2T,结构/半结构数据到文本) 等相对封闭式的文本生成任务而言,主流的衡量维度包括:
- 流畅性(语法、拼写、遣词造句、语言风格等方面)(Fluency);
- 覆盖率(Coverage)/丰富性(Adequacy);
- 准确性(Correctness)/ 真实性(Factuality)/Hallucination(幻觉问题)等
而对于对话生成、评论生成等开放式文本生成任务而言,主流的衡量维度包括:
- 流畅性(语法、拼写、遣词造句、语言风格等方面)(Fluency);
- 相关性(与上下文的相关度)(Relevance);
- 真实性(Factuality)等
对于故事续写任务,评估时还需关注生成文本与上下文的一致性、连贯性(Coherence / Consistency);
对于文本风格迁移任务,衡量维度还包括生成文本的语调(tone)等方面。
3. 评估机制
目前主流的评估机制有三种,分别介绍如下:
3.1 区间式评估(RankME)
给定打分区间,让评估者在打分区间内填写打分数字。图片来源:https://github.com/jeknov/RankME

3.2 量表式评估(Likert Scale)
给定打分量表,如 1,2,3,4,5 五等级量表,分别代表 Very Poor, Poor, Okay, Good, and Very Good. 图片来源:https://github.com/jeknov/RankME

3.3 比较式评估(pair-wise comparison)
为更好地比较 proposed model 与 baselihne,评估者从两个模型生成的文本中选出质量更佳的一个文本,间接反映模型的性能。该方法一般分出 Win-Tie-Lose 三个打分等级,分别表示 preferred (wins), not preferred (losses), 以及 equally preferred (ties). 在 baseline 较多的情况下,该方法工作量较大。

以上三种评估方式中,区间式评估和量表是评估是模型间相互独立的绝对评估方式;而比较式评估是一种模型间的相对评估方式,旨在对两个或多个模型进行比较。
一致性校验(Inter-Evaluator Agreement / Inter-Annotator Agreement)
又称评分员间可信度(Inter-rater Reliability)、评分员间吻合性(Inter-rater Agreement),或一致性(Concordance),都是表述评估者评估结果之间的吻合程度。当评估者对同一个样本给出了相同的判断或分数,则体现出他们打分的一致性。一致性校验则用来衡量不同评估人员之间的分歧,评估人员的评价结果一致性越高意味着评价结果越可信。目前,衡量一致性的指标主要有 Percentage Agreement、Cohen’s Kappa、Fleiss‘ Kappa 以及 Krippendorff’s α,也有一些工作使用 Jaccard similarity 或 F1 Score 计算。这些指标的取值范围都在 0~1 之间。
1. Percentage agreement
计算原理
顾名思义,通过计算评估者结果完全一致的百分比来判定所有评估者意见统一的程度,这里简称为" 吻合百分比 "。
计算方式
令
X
i
X_{i}
Xi 表示待评估的文本,
∣
X
∣
|X|
∣X∣ 表示文本的数量,
a
i
a_{i}
ai 表示每所有评估人员对
X
i
X_{i}
Xi 的评估结果,当所有评估人员评估结果一致时,
a
i
=
1
a_{i}=1
ai=1, 否则
a
i
=
0
a_{i}=0
ai=0,则此种校验方式的计算方式为:

上式的分子为评估者打分完全一致的样本数,分母为样本总数,计算结果
P
a
P_{a}
Pa 即为吻合百分比。
2. Kappa( κ \kappa κ)
Kappa 分数代表着在评估者的打分判断中,他们有多少共识,有多一致。Kappa 的计算公式如下:

其中,
P
o
P_{o}
Po 即为吻合百分比,代表评价者之间的相对观察一致性(the relative observed agreement among raters);
P
e
P_{e}
Pe 代表偶然一致性的假设概率(the hypothetical probability of chance agreement)。常用的 Kappa 分数有 Cohen‘s Kappa 和 Fleiss’s Kappa 两种,它们的区别在于
P
o
P_{o}
Po 与
P
e
P_{e}
Pe 的计算方式不同。
Kappa 分数的取值范围为 [-1, 1], 但一般落在 [0-1] 之间(如下表) 图片来源

根据评估者人数划分,如果评估者为2人,常使用 Cohen‘s Kappa 作为一致性校验指标;如果评估者为3人及以上,则使用 Fleiss Kappa 作为一致性校验指标。下面分别对 Cohen‘s Kappa 和 Fleiss’s Kappa 进行介绍。
2.1 Cohen’s Kappa (Cohen’s κ \kappa κ)
该指标能够捕捉评估一致的随机性。
相关论文:J. Cohen. 1960. A coefficient of agreement for nominal scales. Educational and psychological measurement, 20(1):37–46.
维基定义
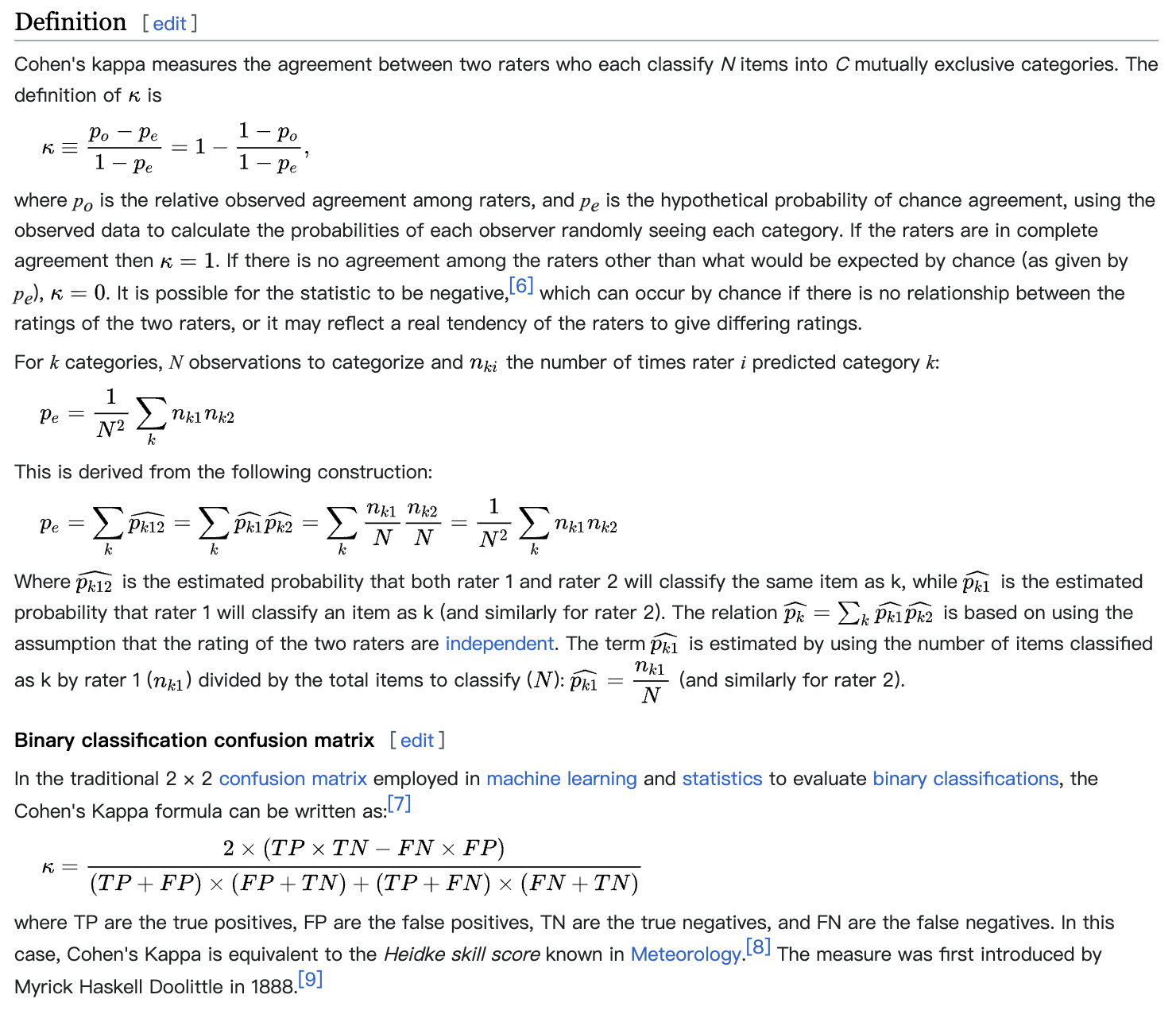
应用场景
Cohen’s Kappa 一般用于两份标注结果之间的比较,例如:
- 两个评估者分别对每个样本进行评分
- 一个评估者对每个样本进行两次评分
计算原理
一般情况下,Cohen’s Kappa 的计算背景是:有两个评分者对每个样本进行二分类.

P
o
P_{o}
Po 的计算方式如下:

P
e
P_{e}
Pe 的计算方式如下:

计算示例
假设 Rater A 和 Rater B 对 50 张图片进行正负二分类,分类结果如下:

Step 1: 计算
P
o
P_{o}
Po:
![]()
Step 2:计算 P e P_{e} Pe:

Step 3:计算 k k k:

k = 0.40 k = 0.40 k=0.40, 查表可知一致性检验结果为 fair agreement.
代码实现
代码来源:https://www.freesion.com/article/86231168789/
# -*- encoding: utf-8 -*-
# 2017-7-27 by xuanyuan14
# 求Cohen's Kappa系数
# 分集0.0~0.20极低的一致性(slight)、0.21~0.40一般的一致性(fair)、0.41~0.60 中等的一致性(moderate)
# 0.61~0.80 高度的一致性(substantial)和0.81~1几乎完全一致(almost perfect)
import numpy as np
def kappa(testData, k): #testData表示要计算的数据,k表示数据矩阵的是k*k的
dataMat = np.mat(testData)
P0 = 0.0
for i in range(k):
P0 += dataMat[i, i]*1.0
xsum = np.sum(dataMat, axis=1)
ysum = np.sum(dataMat, axis=0)
#xsum是个k行1列的向量,ysum是个1行k列的向量
Pe = float(ysum*xsum)/k**2
P0 = float(P0/k*1.0)
cohens_coefficient = float((P0-Pe)/(1-Pe))
return cohens_coefficient
if __name__ == "__main__":
dataArr1 = [[1.1, 1.2], [3.23, 4.78]]
res1 = kappa(dataArr1, 2)
print(res1)
#>>>0.855919552608
2.2 Fleiss’ Kappa (Fleiss’ κ \kappa κ)
Fleiss’s Kappa 是对 Cohen‘s Kappa 的扩展。
相关论文:J. L. Fleiss. 1971. Measuring nominal scale agreement among many raters. Psychological bulletin,76(5):378.
维基定义

应用场景
Fleiss’s Kappa 一般用于三份及以上标注结果之间的比较。
计算示例
假设有 14 个评估者对 10 个样本进行 1 ~ 5 的评分,即 N=10,n=14, k=5(评分等级),评分结果如下:

Step 1:计算
p
j
p_{j}
pj. 以计算
p
1
p_{1}
p1 为例,评估者随机打1分的概率为:
![]()
Step 2:计算 p i p_{i} pi. 以计算 p 2 p_{2} p2 为例,14 个评估者对第 2 个样本达成共识的程度为:

Step 3:计算 P o P_{o} Po 和 P e P_{e} Pe:

Step 4:计算 k k k:

k = 0.21 k=0.21 k=0.21, 查表可知一致性检验结果为 fair agreement.
代码实现
- 版本1:简单版本
代码来源:FLeiss Kappa系数和Kappa系数的Python实现 - 灰信网(软件开发博客聚合) (freesion.com)
# -*- encoding: utf-8 -*-
# 2017-7-27 by xuanyuan14
# 求Fleiss's Kappa系数
# 分集0.0~0.20极低的一致性(slight)、0.21~0.40一般的一致性(fair)、0.41~0.60 中等的一致性(moderate)
# 0.61~0.80 高度的一致性(substantial)和0.81~1几乎完全一致(almost perfect)
import numpy as np
def fleiss_kappa(testData, N, k, n): #testData表示要计算的数据,(N,k)表示矩阵的形状,说明数据是N行j列的,一共有n个标注人员
dataMat = np.mat(testData, float)
oneMat = np.ones((k, 1))
sum = 0.0
P0 = 0.0
for i in range(N):
temp = 0.0
for j in range(k):
sum += dataMat[i, j]
temp += 1.0*dataMat[i, j]**2
temp -= n
temp /= (n-1)*n
P0 += temp
P0 = 1.0*P0/N
ysum = np.sum(dataMat, axis=0)
for i in range(k):
ysum[0, i] = (ysum[0, i]/sum)**2
Pe = ysum*oneMat*1.0
ans = (P0-Pe)/(1-Pe)
return ans[0, 0]
if __name__ == "__main__":
dataArr2 = [[0, 0, 0, 0, 14],
[0, 2, 6, 4, 2],
[0, 0, 3, 5, 6],
[0, 3, 9, 2, 0],
[2, 2, 8, 1, 1],
[7, 7, 0, 0, 0],
[3, 2, 6, 3, 0],
[2, 5, 3, 2, 2],
[6, 5, 2, 1, 0],
[0, 2, 2, 3, 7]]
res2 = fleiss_kappa(dataArr2, 10, 5, 14)
print(res2)
#>>>0.209930704422
- 版本2:复杂版本
代码来源:Python实现Fleiss Kappa一致性分析,并计算Z值和p值等相关统计量_Toblerone_Wind的博客-CSDN博客
该代码同时实现了 Z值和p值等相关统计量的计算
import numpy as np
from scipy.stats import norm
def fleiss_kappa(data: np.array):
"""
Calculates Fleiss' kappa coefficient for inter-rater agreement.
Args:
data: numpy array of shape (subjects, categories), where each element represents
the number of raters who assigned a particular category to a subject.
Returns:
kappa: Fleiss' kappa coefficient.
"""
subjects, categories = data.shape
n_rater = np.sum(data[0])
p_j = np.sum(data, axis=0) / (n_rater * subjects)
P_e_bar = np.sum(p_j ** 2)
P_i = (np.sum(data ** 2, axis=1) - n_rater) / (n_rater * (n_rater - 1))
P_bar = np.mean(P_i)
K = (P_bar - P_e_bar) / (1 - P_e_bar)
tmp = (1 - P_e_bar) ** 2
var = 2 * (tmp - np.sum(p_j * (1 - p_j) * (1 - 2 * p_j))) / (tmp * subjects * n_rater * (n_rater - 1))
# standard error
SE = np.sqrt(var)
Z = K / SE
p_value = 2 * (1 - norm.cdf(np.abs(Z)))
ci_bound = 1.96 * SE / subjects
lower_ci_bound = K - ci_bound
upper_ci_bound = K + ci_bound
print("Fleiss Kappa: {:.3f}".format(K))
print("Standard Error: {:.3f}".format(SE))
print("Z: {:.3f}".format(Z))
print("p-value: {:.3f}".format(p_value))
print("Lower 95% CI Bound: {:.3f}".format(lower_ci_bound))
print("Upper 95% CI Bound: {:.3f}".format(upper_ci_bound))
print()
def transform(*raters):
"""
Transforms the ratings of multiple raters into the required data format for Fleiss' Kappa calculation.
Args:
*raters: Multiple raters' ratings. Each rater's ratings should be a list or array of annotations.
Returns:
data: numpy array of shape (subjects, categories), where each element represents the number of raters
who assigned a particular category to a subject.
"""
assert all(len(rater) == len(raters[0]) for rater in raters), "Lengths of raters are not consistent."
subjects = len(raters[0])
categories = max(max(rater) for rater in raters) + 1
data = np.zeros((subjects, categories))
for i in range(subjects):
for rater in raters:
data[i, rater[i]] += 1
return data
def tranform2(weighted):
"""
Transforms weighted data into the required data format for Fleiss' Kappa calculation.
Args:
weighted: List of weighted ratings. Each row represents [rater_0_category, rater_1_category, ..., rater_n_category, weight].
Returns:
data: numpy array of shape (subjects, categories), where each element represents the number of raters
who assigned a particular category to a subject.
"""
n_rater = len(weighted[0]) - 1
raters = [[] for _ in range(n_rater)]
for i in range(len(weighted)):
for j in range(len(raters)):
raters[j] = raters[j] + [weighted[i][j] for _ in range(weighted[i][n_rater])]
data = transform(*raters)
return data
if __name__ == "__main__":
# Example data provided by wikipedia https://en.wikipedia.org/wiki/Fleiss_kappa
data = np.array([
[0, 0, 0, 0, 14],
[0, 2, 6, 4, 2],
[0, 0, 3, 5, 6],
[0, 3, 9, 2, 0],
[2, 2, 8, 1, 1],
[7, 7, 0, 0, 0],
[3, 2, 6, 3, 0],
[2, 5, 3, 2, 2],
[6, 5, 2, 1, 0],
[0, 2, 2, 3, 7]
])
fleiss_kappa(data)
# need transform
rater1 = [1, 2, 2, 1, 2, 2, 1, 1, 3, 1, 2, 2]
rater2 = [1, 2, 1, 2, 1, 2, 3, 2, 3, 2, 3, 1]
rater3 = [1, 2, 2, 1, 3, 3, 3, 2, 1, 2, 3, 1]
data = transform(rater1, rater2, rater3)
fleiss_kappa(data)
# The first row indicates that both rater 1 and 2 rated as category 0, this case occurs 8 times.
# need transform2
weighted_data = [
[0, 0, 8],
[0, 1, 2],
[0, 2, 0],
[1, 0, 0],
[1, 1, 17],
[1, 2, 3],
[2, 0, 0],
[2, 1, 5],
[2, 2, 15]
]
data = tranform2(weighted_data)
fleiss_kappa(data)
3. Krippendorff’s Alpha (Krippendorff’s α \alpha α)
这一指标反其道而行之,用于判定评测人员之间的不一致性。
相关论文:K. Krippendorff. 1980. Content Analysis: An Introduction to Its Methodology. Sage Publications, BeverlyHills, CA.
Klaus Krippendorff. Estimating the reliability, systematic error and random error of intervaldata. In Educational and Psychological Measurement, volume 30, pp. 61–70, 1970
论文示例
-
Read, Attend and Comment: A Deep Architecture for Automatic News Comment Generation (ACL, 2019) 中,评估者3人,评估样本500个,设定如下打分机制,涵盖 Fluency、Relevance、Richness 以及 Attractiveness 等维度。

使用 Fleiss’ kappa 一致性检验方法衡量打分结果间的相关性,评估者3人,评估样本500个,评估结果如下:


-
Coherent Comment Generation for Chinese Articles with a Graph-to-Sequence Model (ACL, 2019) 设定 Coherence、Informativeness、Fluency 三个打分维度,在 0~10 区间内打一个综合分。使用 Spearman’s Rank Score 一致性检验方法衡量打分结果间的相关性,评估者3人,评估样本100个,评估结果节选如下:

- Text is NOT Enough: Integrating Visual Impressions into Open-domain Dialogue Generation (ACM Multimedia, 2021) 中,设定 Fluency, Coherence, 以及 Informativeness 三个打分维度,评估方式为:在 proposed model 与 baseline 之间进行 pairwise-comparison,有 Win-Tie-Lose 三个等级,评估者6人,评估样本300个,评估结果如下:

- Long and Diverse Text Generation with Planning-based Hierarchical Variational Model (EMNLP, 2019) 中,设定 Grammaticality 与 Coherence 两个打分维度,同样使用上述 pairwise-comparison evaluation 的方法,有 Win-Tie-Lose 三个等级,评估者5人,评估样本200个,评估结果如下:

- Affective Feedback Synthesis Towards Multimodal Text and Image Data (TOMM, 2023) 中,设定语义相关性为唯一的打分维度,分别衡量 ground-truth comment 与 synthesized feedback 及 context 之间的相关性。评估者50人,评估结果如下:(这里论文中没说明表中的数值是什么意思,或许是百分比?)

参考资料
- Evaluation of Text Generation: A Survey (arxiv.org), P5-P13.
- A Survey of Evaluation Metrics Used for NLG Systems (ACM Computing Surveys, 2022)
- (Cohen’s Kappa)A coefficient of agreement for nominal scales (Educational and psychological measurement, 1960)
- (Fleiss’s Kappa)Measuring nominal scale agreement among many raters (Psychological bulletin, 1971)
- Agreement is overrated: A plea for correlation to assess human evaluation reliability
- 文本生成评价方式(一) - 知乎 (zhihu.com)
- 评价者之间的一致性-Kappas Inter-rater agreement Kappas - 简书 (jianshu.com)
- Stats: What is a Kappa coefficient? (Cohen’s Kappa) (pmean.com)
- Cohen’s kappa - Wikipedia
- Fleiss’ kappa - Wikipedia
- 评分员间可信度与Kappa统计量 Inter-rater reliability & Kappa statistics_diemeng1119的博客-CSDN博客
- Python实现Fleiss Kappa一致性分析,并计算Z值和p值等相关统计量_Toblerone_Wind的博客-CSDN博客
- 属性一致性分析 的 kappa 统计量的方法和公式 - Minitab
- Fleiss’ kappa in SPSS Statistics | Laerd Statistics
- https://github.com/dpaleino/tesi/tree/master/docs
- https://github.com/Cucchi01/Fleiss-kappa
- https://github.com/Lucienxhh/Fleiss-Kappa
- https://github.com/bryanfeng/KappaEvaluation
- Kappa(cappa)系数只需要看这一篇就够了,算法到python实现 - 忽逢桃林 - 博客园 (cnblogs.com)
- kappa系数在大数据评测中的应用 - 胖喵~ - 博客园 (cnblogs.com)
![[回馈]ASP.NET Core MVC开发实战之商城系统(开篇)](https://img-blog.csdnimg.cn/img_convert/6532db0e128d37bcea8ad2252fa21ac0.png)