在《机器学习28:推荐系统-概述》一文中,笔者概述了推荐系统的基本术语和一般架构,通过【推荐系统 I~IV】系列课程的学习,相信读者对推荐系统已经有了一定的理解。本节,我们再来回顾一下推荐系统的核心环节——召回、打分、重排。
目录
1.召回-Retrieval
1.1 大规模检索
1.2 近似最邻近-ANN 算法
2.打分-Scoring
2.1 为什么不让候选 Item 生成器评分?
2.2 选择评分目标函数
2.3 得分中的位置偏差
3.重排-Re-ranking
3.1 新鲜度
3.2 多样性
3.3 公平性
4.参考文献
1.召回-Retrieval
假设已有一个嵌入模型。给定一个用户,你将如何决定推荐哪些项目?
在服务时,给定一个查询,首先执行以下操作之一:
- 对于矩阵分解模型,查询(或用户)嵌入是静态已知的,系统可以简单地从用户嵌入矩阵中查找它。
- 对于 DNN 模型,在服务时,基于特征向量
运行网络,系统即可计算出查询嵌入
。
如图 1 所示,一旦有了查询嵌入 ,我们就可以在嵌入空间(embedding space)中找到那些 “靠近” 查询嵌入
的 Item 的嵌入
。这本质上是一个最近邻问题(nearest neighbor problem)问题。例如,可以根据相似度得分
返回 Top k 个 Item 。
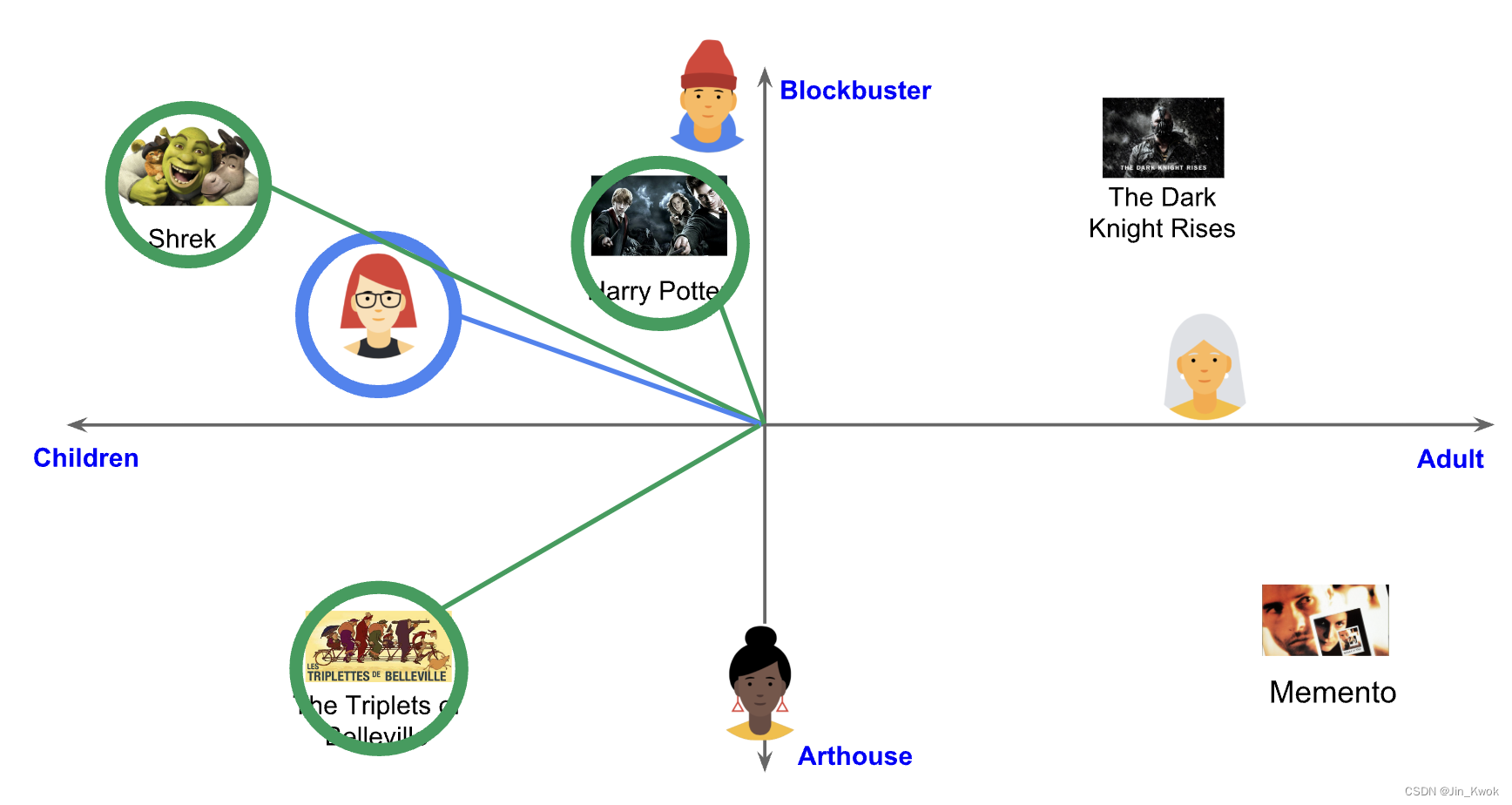
图 1 嵌入空间中与查询 靠近的 Item 示意图
在 “相关Item” 推荐场景中,我们可以使用类似的方法。例如,当用户正在观看 YouTube 视频时,系统可以首先查找该 Item(视频)的嵌入,然后,在嵌入空间中查找那些距离该 Item 接近的其他 Item 的嵌入 。
1.1 大规模检索
为了计算嵌入空间中的最近邻居,系统可以对每个潜在候选者进行全面的评分。不过,对于非常大的物料库来说,全面的评分可能会很昂贵,因此,我们需要采取一些措施来降低成本:
- 1-如果查询嵌入是静态已知的,系统可以离线执行评分,预先计算并存储每个查询的最佳候选列表,在服务时,直接查询并返回即可。在 “相关 Item ” 推荐场景中,为了降低成本,离线打分是最常用的策略之一。
- 使用近似最近邻(approximate nearest neighbors,ANN)
1.2 近似最邻近-ANN 算法
对于一个现有的数据候选集(Dataset),返回在数据候选集中与某一查询 最相似的 Top K 数据。最朴素的想法就是,每次来了一个新的查询
,都遍历一遍数据候选集(Dataset)里面的所有数据,计算出 query 与 dataset 中所有元素的相似度或者距离,然后精准地返回 Top K 相似的数据即可。
但是,当数据候选集特别大的时候,遍历一遍数据候选集里面的所有元素就会耗费过多的时间,其时间复杂度是 O(n), 因此,计算机科学家们开发了各种各样的近似最近邻搜索方法(approximate nearest neighbors,ANN)来加快其搜索速度,在精确率和召回率上面就会做出一定的牺牲,但是其搜索速度相对暴力搜索有很大地提高。
在推荐/搜索场景下,通常都是欧式空间里面的数据,形如 x=(x1,⋯,xn)∈, 其中 n 是欧氏空间的维度。常用的距离公式包括:
- Manhattan 距离:L1 范数;
- Euclidean 距离:L2 范数;
- Cosine 距离:1 – Cosine 相似度;
- 角距离:用两个向量之间的夹角来衡量两者之间的距离;
- Hamming 距离:一种针对 64 维的二进制数的 Manhattan 距离,相当于
中的 L1 范数;
- Dot Product 距离:
在近似最近邻搜索(ANN)领域,有很多开源的算法可以使用,包括但不限于:
- Annoy(Approximate Nearest Neighbors Oh Yeah);
- ScaNN(Scalable Nearest Neighbors);
- Faiss(Billion-scale similarity search with GPUs);
- Hnswlib(fast approximate nearest neighbor search);
关于 ANN 算法,读者可以查看文章《近似最近邻搜索算法 ANNOY》
2.打分-Scoring
通过召回,可以生成一个候选 Item 池。之后,我们还需要另一个模型对候选Item进行评分和排名,以便选择出要返回的 Item 集——在推荐领域,这一环节通常被称为【排序】。一个推荐系统可能有多个不同来源的候选 Item 生成器,例如:
- 矩阵分解模型中的相关 Item。
- 考虑用户个性化特征的 Item。
- “本地”与“远程” Item;即考虑地理信息的 Item。
- 流行的 Item。
- 社交图谱;即朋友喜欢或推荐的 Item。
打分系统将上述不同来源的 Item 组合成一个公共候选池——(本质上是【多路召回】),然后通过单个模型对其进行评分并根据该分数进行排名。例如,系统可以训练一个模型来预测用户在 YouTube 上观看视频的概率,具体如下:
- 查询特征(例如用户观看记录、语言、国家、时间)
- 视频特征(例如标题、标签、视频嵌入)
然后,系统可以根据模型的预测对候选池中的视频进行排名。
2.1 为什么不让候选 Item 生成器评分?
由于候选生成器会计算分数(例如嵌入空间中的相似性度量),因此,理论上可以使用它们来进行排名。但是,由于以下原因,我们应该避免这种做法:
- 一些系统依赖于多个候选生成器。这些不同生成器的分数可能无法比较——打分的体系不一样,无法客观比较。以高考为例,直接对比不同省份的高考分数是不客观的,因为打分标准、试卷都不尽相同。
- 经过召回,得到的候选 Item 数量一般较少,打分算力成本可控,因此,打分应采用更多的特征和更复杂的模型,从而更好地捕获上下文,提高推荐效果。
2.2 选择评分目标函数
评分函数的选择可以极大地影响 Item 的排名,并最终影响推荐的质量。常见的目标如下:
-
最大化点击率
如果评分针对点击进行优化,系统可能会推荐点击诱饵视频。这种评分策略会产生点击,但不会带来良好的用户体验。用户的兴趣可能很快就会消失。
-
最大化观看时间
如果评分针对观看时间进行优化,系统可能会推荐很长的视频,这可能会导致较差的用户体验。
-
增加多样性并最大化会话观看时间
推荐较短的视频,保持用户的参与度。
2.3 得分中的位置偏差
如图 2 所示,与屏幕上显示靠前的 Item 相比,屏幕上显示靠后的 Item 不太可能被点击。然而,在对视频进行评分时,系统通常不知道该视频的链接最终会出现在屏幕上的哪个位置。查询具有所有可能位置的模型的成本太高。即使查询多个位置是可行的,系统仍然可能无法在多个排名分数中找到一致的排名。常用解决方案:
- 创建与位置无关的排名。
- 对所有候选 Item 进行排名。
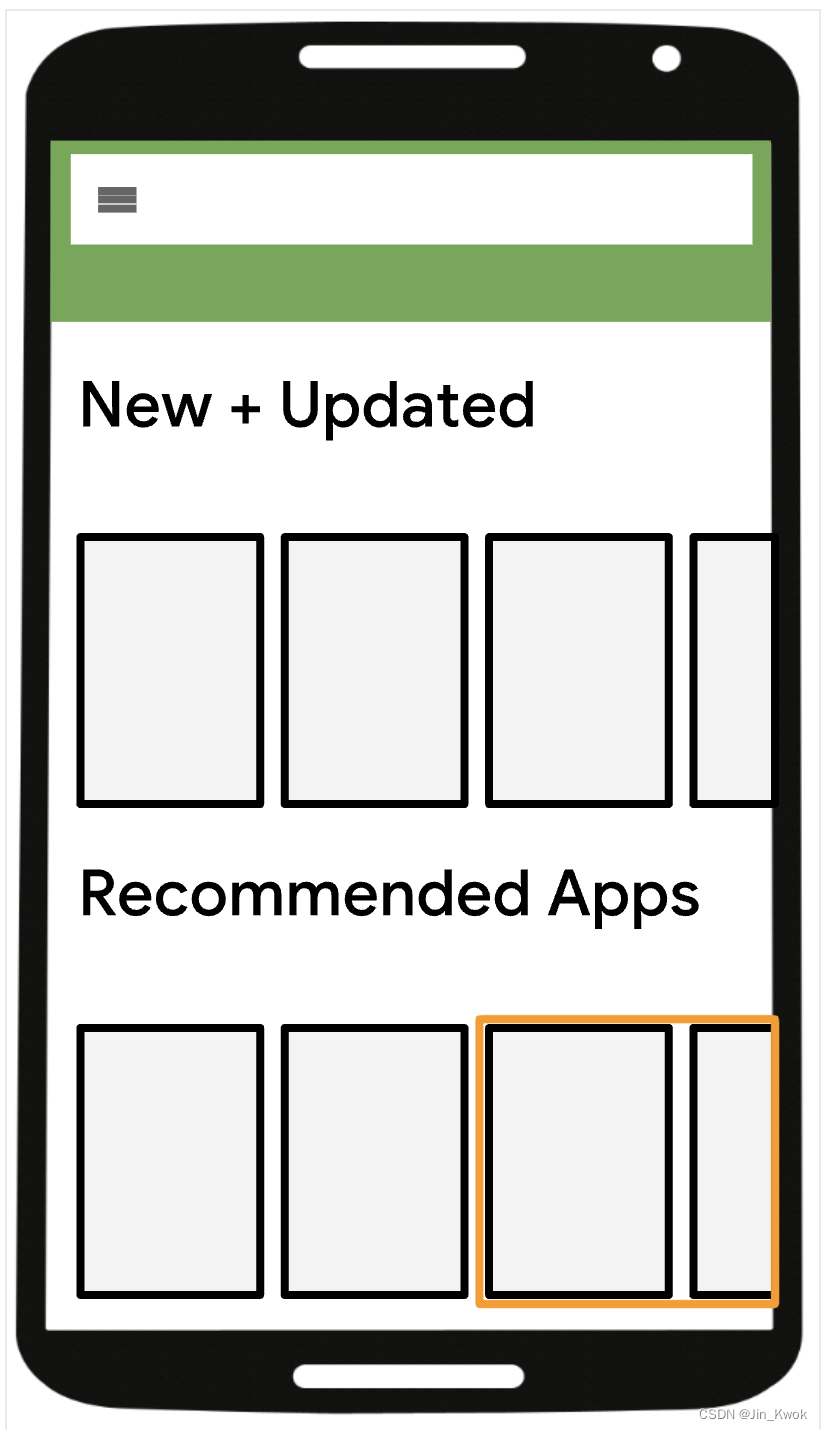
图 2 Item C端展示示意图
3.重排-Re-ranking
在推荐系统的最后阶段,系统可以对候选 Item 进行重新排名——这一环节通常被称为【重排】,以考虑其他标准或约束。一种常用重排的方法是使用过滤器来删除一些候选 Item。
示例: 可以通过执行以下操作对视频推荐器实施重新排名:
- 训练一个单独的模型来检测视频是否为“诱饵”。
- 在候选列表上运行该模型。
- 删除模型归类为点击诱饵的视频。
另一种重排方法是手动转换排名器返回的分数。
示例: 系统通过将分数修改为以下函数来重新排名视频:
- 视频时效(例如,为了推广更新鲜的内容,可以将最新上架的视频放在更靠前的位置)
- 视频长度
本节简要讨论新鲜度、多样性和公平性。这些因素是有助于改进推荐系统的众多因素之一。其中一些因素通常需要修改流程的不同阶段。每个部分都提供了可以单独或组合应用的解决方案。
3.1 新鲜度
大多数推荐系统旨在合并最新的使用信息,例如当前的用户历史记录和最新的项目。保持模型的新鲜度有助于模型提出好的建议。常用解决方案如下:
- 尽可能频繁地重新运行训练以了解最新的训练数据。建议热启动训练,以便模型不必从头开始重新学习。热启动可以显着减少训练时间。例如,在矩阵分解中,热启动模型先前实例中存在的项的嵌入。
- 创建一个 “平均” 用户来代表矩阵分解模型中的新用户。不需要为每个用户使用相同的嵌入 ——可以根据用户特征创建用户集群。
- 使用 DNN,例如 softmax 模型或双塔模型。由于该模型采用特征向量作为输入,因此它可以在训练期间未见过的查询或 Item上运行。
- 创建时间作为一项特征。例如,YouTube 可以增加视频的创建时间或上次观看的时间作为一项特征。
3.2 多样性
如果系统总是推荐与查询嵌入“最接近”的 Item,则候选 Item 往往彼此非常相似。这种缺乏多样性可能会导致糟糕或无聊的用户体验。例如,如果 YouTube 只推荐与用户当前正在观看的视频非常相似的视频,例如除了猫头鹰视频之外什么都没有,用户可能会很快失去兴趣。常用解决方案如下:
- 使用不同的源训练多个候选 Item 生成器。
- 使用不同的目标函数训练多个排名器。
- 根据流派或其他元数据对 Item 重新排名,以确保多样性。
3.3 公平性
模型应该公平对待所有用户。因此,请确保模型不会从训练数据中学习无意识的偏差。常用的解决方案如下:
- 在设计和开发中纳入不同的观点。
- 在综合数据集上训练 ML 模型。当数据过于稀疏时(例如,当某些类别代表性不足时),请添加辅助数据。
- 跟踪统计指标(例如准确性和绝对误差)以观察偏差。
- 为特殊的群体建立单独的模型。
4.参考文献
1-https://developers.google.cn/machine-learning/recommendation/dnn/re-ranking
2-近似最近邻搜索算法 ANNOY(APPROXIMATE NEAREST NEIGHBORS OH YEAH) - 知乎