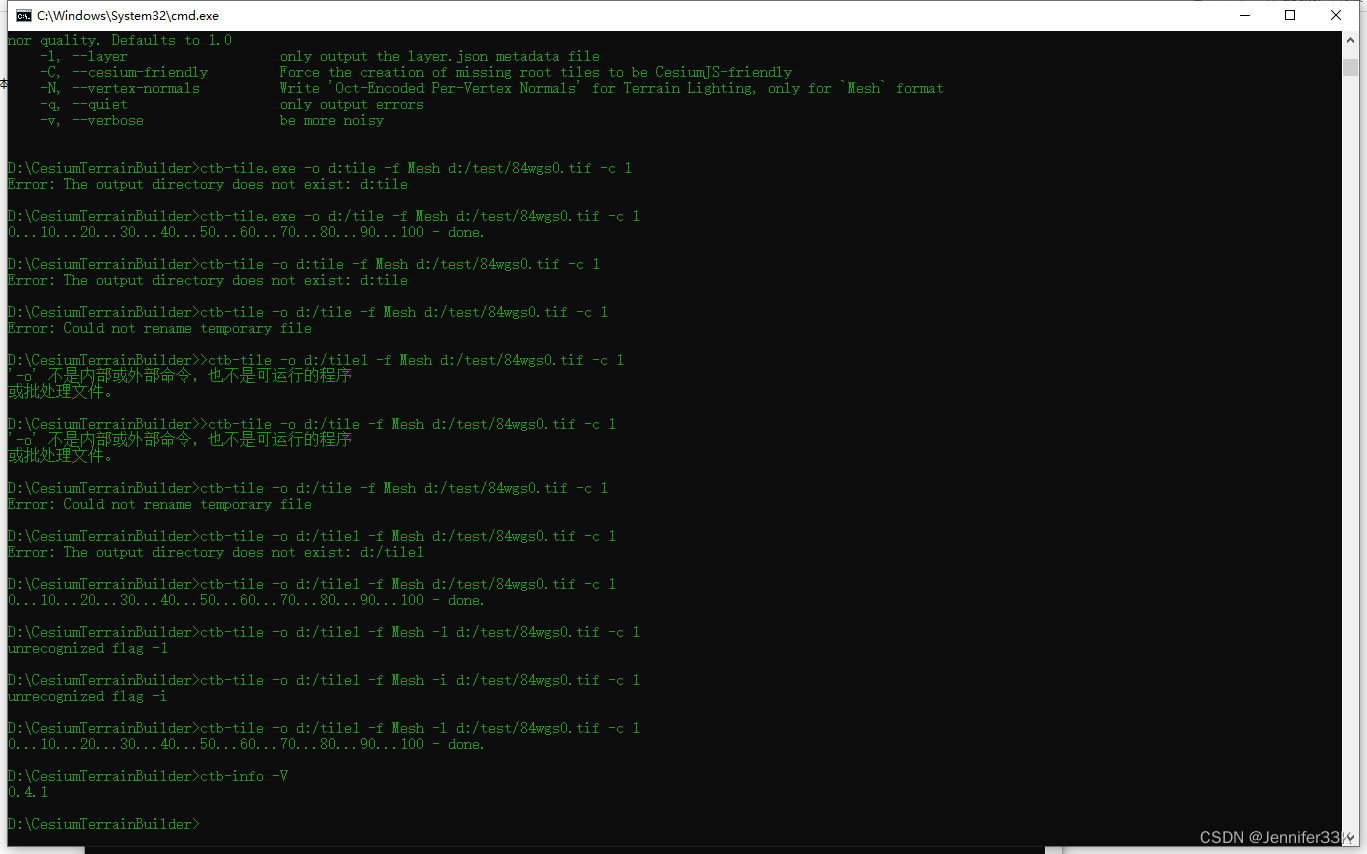
目标检测系列的算法模型可以说是五花八门,不同的系列有不同的理论依据,DETR的亮点在于它是完全端到端的第一个目标检测模型,DETR(Detection Transformer)是一种基于Transformer的目标检测模型,由Facebook AI Research开发。它采用了端到端的方法,在目标检测任务中同时完成目标定位和分类。DETR模型结合了Transformer的自注意力机制和编码器-解码器结构。通过将图像作为输入,并使用Transformer解码器来生成预测框和对应的类别。与传统的目标检测方法不同,DETR不需要使用锚框或候选区域,而是直接从全局观察中生成预测。
DETR模型的训练过程包括两个阶段:首先,使用交叉熵损失函数对预测框和类别进行监督学习;然后,使用匈牙利算法将预测框与真实框进行匹配,计算IoU损失以进一步优化预测结果。DETR模型在目标检测任务上取得了很好的性能,并且具有较高的效率和灵活性。它可以应用于多种场景,如物体检测、实例分割等任务。
DETR官方项目地址在这里,如下所示:

目前已经有超过11.4k的star量,足以见得这是一款很出色的检测模型了。

DETR(DEtection TRansformer)是一种基于Transformer的目标检测模型,提供了PyTorch训练代码和预训练模型。它用Transformer替代了传统的复杂手工设计的目标检测流程,并使用ResNet-50与Faster R-CNN进行比较,在COCO数据集上以相同参数数量和一半计算量(FLOPs)下获得了42 AP的准确率。在只有50行PyTorch代码的情况下,可以进行推断。
DETR的特点是将目标检测作为直接集合预测问题来处理,它包括一个基于集合的全局损失函数,通过二分图匹配强制生成唯一的预测结果,以及一个Transformer编码器-解码器架构。给定一组固定的学习对象查询(object queries),DETR根据对象之间的关系和全局图像上下文直接并行输出最终的预测结果。由于这种并行性质,DETR非常快速高效。
关于代码,我们认为目标检测不应该比分类更困难,也不应该需要复杂的训练和推断库。DETR的实现和实验非常简单,我们提供了一个独立的Colab Notebook,在几行PyTorch代码中展示了如何使用DETR进行推断。训练代码也遵循这个思路,它不是一个库,而只是一个主要的.py文件,导入模型和标准训练循环。此外,我们还提供了Detectron2的封装,位于d2/文件夹中。请参阅那里的自述文件以获取更多信息。
接下来我们来整体看下,如何一步一步基于DETR开发构建自己的个性化目标检测模型。
一、下载准备项目
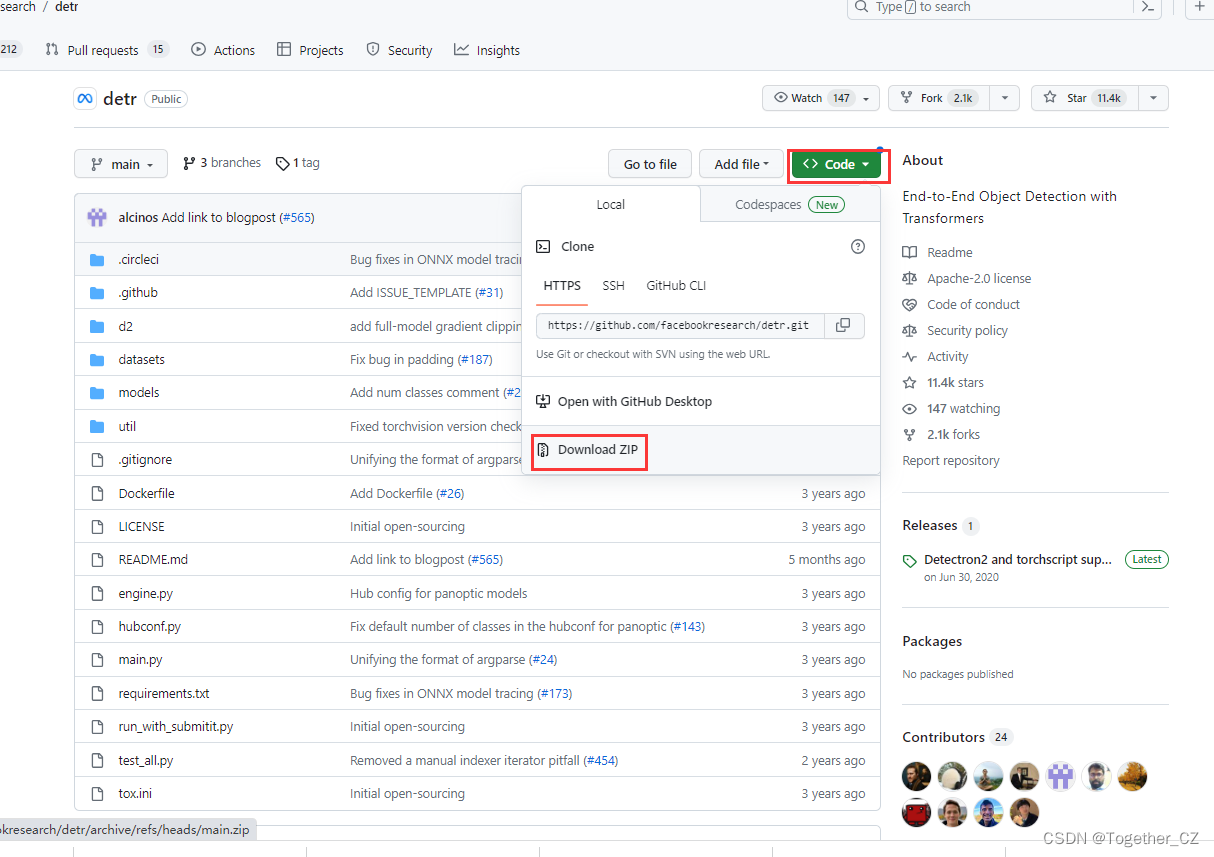
直接页面端安装红框所示点击即可下载源码项目到本地如下所示:
解压缩如下所示:
看起来比较乱,这里删除掉不需要的文件,精简一下,如下所示:

到这里项目下载准备工作已经完成了。
二、项目参数修改
这里主要是根据自己的数据集情况要做一些项目参数的配置修改,首先到这里下载官方提供的预训练模型权重文件。如下所示:

接下来编写下述代码来对预训练模型文件进行修改,修改适配自己的数据集:
import torch
pretrained_weights = torch.load("./detr-r50-e632da11.pth")
num_class = 1 + 1
pretrained_weights["model"]["class_embed.weight"].resize_(num_class+1,256)
pretrained_weights["model"]["class_embed.bias"].resize_(num_class+1)
torch.save(pretrained_weights,'detr_r50_%d.pth'%num_class)这里的核心就是num_class,这里我的类别只有一个所有就是1(目标数量)+1(背景),根据自己的实际情况修改即可,执行上述代码将会生成可用于训练自己数据集的预训练模型文件如下所示:

接下来进入到models目录,如下所示:

来修改detr.py的源码:

修改内容如下所示:

同样也是根据自己的数据集的实际情况进行修改即可。
官方的实例都是以COCO数据集为基础的,这里为了方便直接使用我的数据集,我这里同时修改了datasets目录下的coco.py模块,如下所示:

这里不是必须的,只是因为我前面写yolo系列的超详细教程的时候习惯了以0000目录为基准作为数据集的目录而已,这个根据自己实际情况来就行。
0000/coco/目录下如下所示:
![]()
annotations目录下如下所示:

train和val目录都是图像数据目录。
到这里全部的数据集准备和参数修改配置就完成了。
三、模型训练
完成前面步骤一和步骤二之后就可以开始模型的训练工作了,终端输入下面的命令即可:
python3 main.py --dataset_file "coco" --coco_path "/0000/coco" --epoch 100 --lr=1e-4 --batch_size=2 --num_workers=0 --output_dir="outputs" --resume="weights/detr_r50_2.pth"
终端日志输出如下所示:
感觉这个日志输出的形式和yolo系列的模型风格差异还是很大的,最开始使用的时候多多少少是有点不太适应的。
静静等待,100次epoch训练完成后,结果目录如下所示:
这里我们看一个epoch的结果数据如下所示:
{"train_lr": 0.00010000000000000072, "train_class_error": 8.246314652760823, "train_loss": 11.92804820438226, "train_loss_ce": 0.45436179675161836, "train_loss_bbox": 0.19398587183095514, "train_loss_giou": 1.2654916323721408, "train_loss_ce_0": 0.6175143427525958, "train_loss_bbox_0": 0.21694033461002013, "train_loss_giou_0": 1.3583310965448618, "train_loss_ce_1": 0.5325561841484159, "train_loss_bbox_1": 0.19919901308603585, "train_loss_giou_1": 1.2892874646931887, "train_loss_ce_2": 0.49897560079116376, "train_loss_bbox_2": 0.19595884778536857, "train_loss_giou_2": 1.2676222202057639, "train_loss_ce_3": 0.47517175901836406, "train_loss_bbox_3": 0.19423701039825877, "train_loss_giou_3": 1.2563509756699205, "train_loss_ce_4": 0.457715673193646, "train_loss_bbox_4": 0.19406218592387933, "train_loss_giou_4": 1.2602861863871415, "train_loss_ce_unscaled": 0.45436179675161836, "train_class_error_unscaled": 8.246314652760823, "train_loss_bbox_unscaled": 0.038797174374728155, "train_loss_giou_unscaled": 0.6327458161860704, "train_cardinality_error_unscaled": 25.414583333333333, "train_loss_ce_0_unscaled": 0.6175143427525958, "train_loss_bbox_0_unscaled": 0.04338806696857015, "train_loss_giou_0_unscaled": 0.6791655482724309, "train_cardinality_error_0_unscaled": 29.636458333333334, "train_loss_ce_1_unscaled": 0.5325561841484159, "train_loss_bbox_1_unscaled": 0.03983980262031158, "train_loss_giou_1_unscaled": 0.6446437323465943, "train_cardinality_error_1_unscaled": 27.819791666666667, "train_loss_ce_2_unscaled": 0.49897560079116376, "train_loss_bbox_2_unscaled": 0.03919176950973148, "train_loss_giou_2_unscaled": 0.6338111101028819, "train_cardinality_error_2_unscaled": 27.161458333333332, "train_loss_ce_3_unscaled": 0.47517175901836406, "train_loss_bbox_3_unscaled": 0.03884740209129329, "train_loss_giou_3_unscaled": 0.6281754878349602, "train_cardinality_error_3_unscaled": 26.110416666666666, "train_loss_ce_4_unscaled": 0.457715673193646, "train_loss_bbox_4_unscaled": 0.038812437271311256, "train_loss_giou_4_unscaled": 0.6301430931935708, "train_cardinality_error_4_unscaled": 25.4625, "test_class_error": 3.091428756713867, "test_loss": 10.50865466594696, "test_loss_ce": 0.2767929275830587, "test_loss_bbox": 0.14404282706479232, "test_loss_giou": 1.2663704454898834, "test_loss_ce_0": 0.3979991920292377, "test_loss_bbox_0": 0.16362756925324598, "test_loss_giou_0": 1.36108036339283, "test_loss_ce_1": 0.3436319828033447, "test_loss_bbox_1": 0.1497225967546304, "test_loss_giou_1": 1.3024949004252753, "test_loss_ce_2": 0.30994254574179647, "test_loss_bbox_2": 0.14414388077954451, "test_loss_giou_2": 1.249400516351064, "test_loss_ce_3": 0.2894516279300054, "test_loss_bbox_3": 0.144076735774676, "test_loss_giou_3": 1.270151581366857, "test_loss_ce_4": 0.2760662081340949, "test_loss_bbox_4": 0.1443922327210506, "test_loss_giou_4": 1.2752665122350058, "test_loss_ce_unscaled": 0.2767929275830587, "test_class_error_unscaled": 3.091428756713867, "test_loss_bbox_unscaled": 0.028808565282573303, "test_loss_giou_unscaled": 0.6331852227449417, "test_cardinality_error_unscaled": 31.85, "test_loss_ce_0_unscaled": 0.3979991920292377, "test_loss_bbox_0_unscaled": 0.03272551361781855, "test_loss_giou_0_unscaled": 0.680540181696415, "test_cardinality_error_0_unscaled": 43.225, "test_loss_ce_1_unscaled": 0.3436319828033447, "test_loss_bbox_1_unscaled": 0.02994451941922307, "test_loss_giou_1_unscaled": 0.6512474502126376, "test_cardinality_error_1_unscaled": 39.733333333333334, "test_loss_ce_2_unscaled": 0.30994254574179647, "test_loss_bbox_2_unscaled": 0.02882877611555159, "test_loss_giou_2_unscaled": 0.624700258175532, "test_cardinality_error_2_unscaled": 37.733333333333334, "test_loss_ce_3_unscaled": 0.2894516279300054, "test_loss_bbox_3_unscaled": 0.028815347344304125, "test_loss_giou_3_unscaled": 0.6350757906834285, "test_cardinality_error_3_unscaled": 34.483333333333334, "test_loss_ce_4_unscaled": 0.2760662081340949, "test_loss_bbox_4_unscaled": 0.02887844655973216, "test_loss_giou_4_unscaled": 0.6376332561175029, "test_cardinality_error_4_unscaled": 31.533333333333335, "test_coco_eval_bbox": [0.0784053628963453, 0.27165513666939684, 0.02143312972132683, 0.05011304279117235, 0.10950960486820328, 0.248747506997248, 0.01054397316079559, 0.07481428229091781, 0.18171579199616583, 0.13471350899205353, 0.2401053864168618, 0.3527027027027027], "epoch": 0, "n_parameters": 41279495}可以看到:这是一个标准的字典数据。
完成模型的训练之后就可以对模型进行评估测试了,执行下述的命令:
python3 main.py --batch_size 2 --no_aux_loss --eval --resume outputs/checkpoint.pth --coco_path "/0000/coco"结果输出如下所示:
Accumulating evaluation results...
DONE (t=0.12s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.249
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.614
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.147
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.156
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.356
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.548
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.017
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.142
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.362
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.279
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.468
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.622
初步来看效果还不错,不过跟yolo系列的模型实验结果对比起来还是逊色的。
到这里模型的开发训练和测试评估就结束了
四、训练可视化
想必到这里大家都意识到了DETR项目没有像YOLO那样的可视化功能,所以想要有可视化指标的话还是需要自己去进行可视化绘图的。
这里仅仅是自己的简单绘图,可以根据自己的需要自行实现即可。我将单个epoch训练日志数据进行解析,如下所示:
train_lr 0.00010000000000000072
train_class_error 8.246314652760823
train_loss 11.92804820438226
train_loss_ce 0.45436179675161836
train_loss_bbox 0.19398587183095514
train_loss_giou 1.2654916323721408
train_loss_ce_0 0.6175143427525958
train_loss_bbox_0 0.21694033461002013
train_loss_giou_0 1.3583310965448618
train_loss_ce_1 0.5325561841484159
train_loss_bbox_1 0.19919901308603585
train_loss_giou_1 1.2892874646931887
train_loss_ce_2 0.49897560079116376
train_loss_bbox_2 0.19595884778536857
train_loss_giou_2 1.2676222202057639
train_loss_ce_3 0.47517175901836406
train_loss_bbox_3 0.19423701039825877
train_loss_giou_3 1.2563509756699205
train_loss_ce_4 0.457715673193646
train_loss_bbox_4 0.19406218592387933
train_loss_giou_4 1.2602861863871415
train_loss_ce_unscaled 0.45436179675161836
train_class_error_unscaled 8.246314652760823
train_loss_bbox_unscaled 0.038797174374728155
train_loss_giou_unscaled 0.6327458161860704
train_cardinality_error_unscaled 25.414583333333333
train_loss_ce_0_unscaled 0.6175143427525958
train_loss_bbox_0_unscaled 0.04338806696857015
train_loss_giou_0_unscaled 0.6791655482724309
train_cardinality_error_0_unscaled 29.636458333333334
train_loss_ce_1_unscaled 0.5325561841484159
train_loss_bbox_1_unscaled 0.03983980262031158
train_loss_giou_1_unscaled 0.6446437323465943
train_cardinality_error_1_unscaled 27.819791666666667
train_loss_ce_2_unscaled 0.49897560079116376
train_loss_bbox_2_unscaled 0.03919176950973148
train_loss_giou_2_unscaled 0.6338111101028819
train_cardinality_error_2_unscaled 27.161458333333332
train_loss_ce_3_unscaled 0.47517175901836406
train_loss_bbox_3_unscaled 0.03884740209129329
train_loss_giou_3_unscaled 0.6281754878349602
train_cardinality_error_3_unscaled 26.110416666666666
train_loss_ce_4_unscaled 0.457715673193646
train_loss_bbox_4_unscaled 0.038812437271311256
train_loss_giou_4_unscaled 0.6301430931935708
train_cardinality_error_4_unscaled 25.4625
test_class_error 3.091428756713867
test_loss 10.50865466594696
test_loss_ce 0.2767929275830587
test_loss_bbox 0.14404282706479232
test_loss_giou 1.2663704454898834
test_loss_ce_0 0.3979991920292377
test_loss_bbox_0 0.16362756925324598
test_loss_giou_0 1.36108036339283
test_loss_ce_1 0.3436319828033447
test_loss_bbox_1 0.1497225967546304
test_loss_giou_1 1.3024949004252753
test_loss_ce_2 0.30994254574179647
test_loss_bbox_2 0.14414388077954451
test_loss_giou_2 1.249400516351064
test_loss_ce_3 0.2894516279300054
test_loss_bbox_3 0.144076735774676
test_loss_giou_3 1.270151581366857
test_loss_ce_4 0.2760662081340949
test_loss_bbox_4 0.1443922327210506
test_loss_giou_4 1.2752665122350058
test_loss_ce_unscaled 0.2767929275830587
test_class_error_unscaled 3.091428756713867
test_loss_bbox_unscaled 0.028808565282573303
test_loss_giou_unscaled 0.6331852227449417
test_cardinality_error_unscaled 31.85
test_loss_ce_0_unscaled 0.3979991920292377
test_loss_bbox_0_unscaled 0.03272551361781855
test_loss_giou_0_unscaled 0.680540181696415
test_cardinality_error_0_unscaled 43.225
test_loss_ce_1_unscaled 0.3436319828033447
test_loss_bbox_1_unscaled 0.02994451941922307
test_loss_giou_1_unscaled 0.6512474502126376
test_cardinality_error_1_unscaled 39.733333333333334
test_loss_ce_2_unscaled 0.30994254574179647
test_loss_bbox_2_unscaled 0.02882877611555159
test_loss_giou_2_unscaled 0.624700258175532
test_cardinality_error_2_unscaled 37.733333333333334
test_loss_ce_3_unscaled 0.2894516279300054
test_loss_bbox_3_unscaled 0.028815347344304125
test_loss_giou_3_unscaled 0.6350757906834285
test_cardinality_error_3_unscaled 34.483333333333334
test_loss_ce_4_unscaled 0.2760662081340949
test_loss_bbox_4_unscaled 0.02887844655973216
test_loss_giou_4_unscaled 0.6376332561175029
test_cardinality_error_4_unscaled 31.533333333333335
test_coco_eval_bbox [0.0784053628963453, 0.27165513666939684, 0.02143312972132683, 0.05011304279117235, 0.10950960486820328, 0.248747506997248, 0.01054397316079559, 0.07481428229091781, 0.18171579199616583, 0.13471350899205353, 0.2401053864168618, 0.3527027027027027]
epoch 0
n_parameters 41279495可以看到:不同指标拆分得很细,单个指标核心绘图实现很简单,如下所示:
plt.clf()
plt.figure(figsize=(10,8))
plt.plot(one_value)
plt.title(one_key + "cruve")
plt.savefig("outputs/pictures/"+one_key+".jpg")简单看下可视化结果:
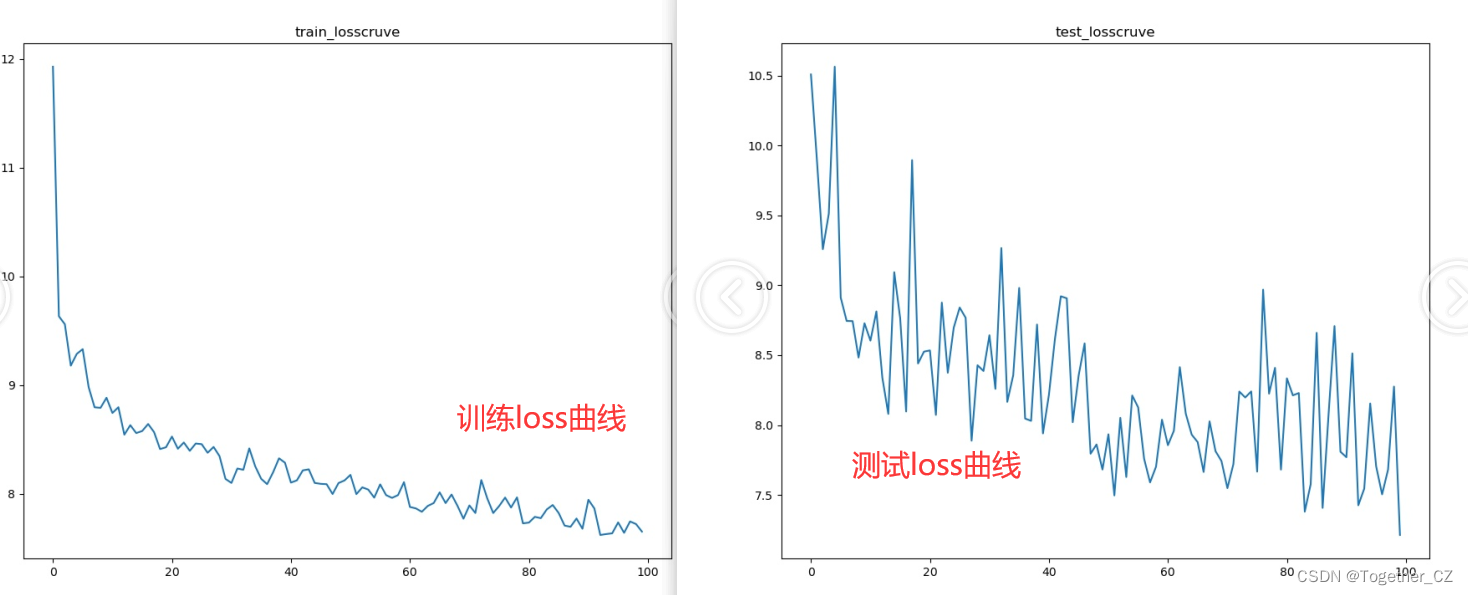
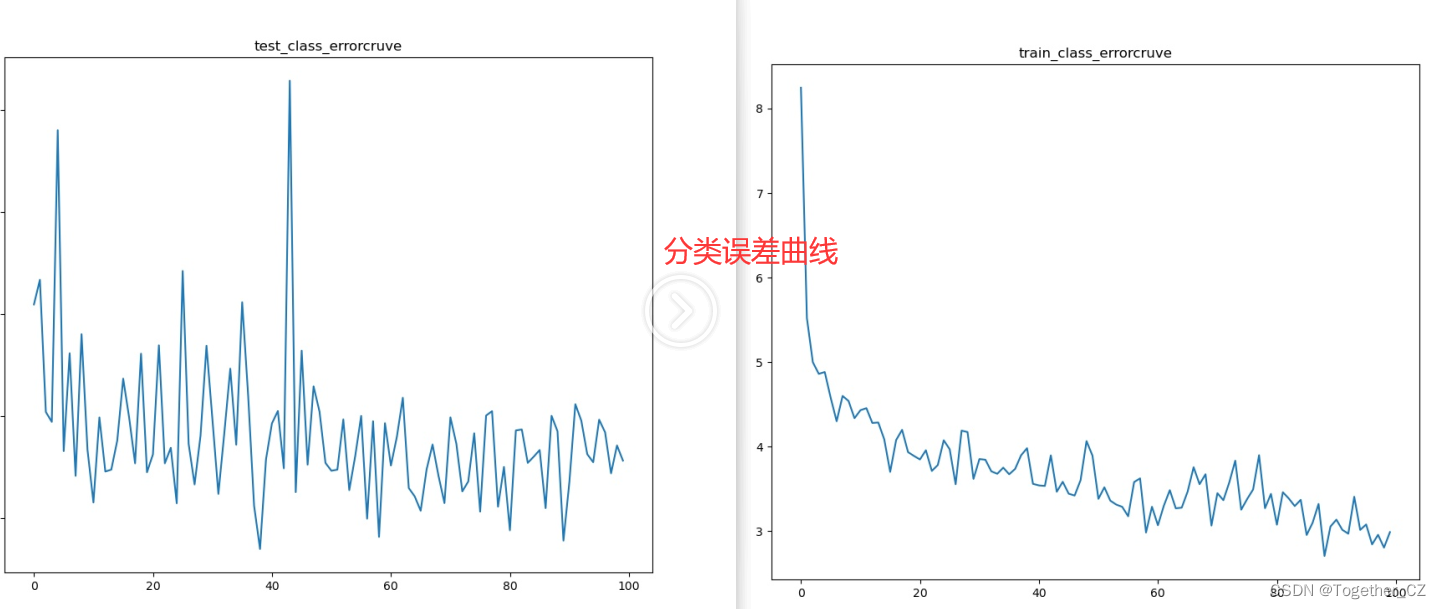
当然了,还有很多很多,这里不再一一展示了,可以自行动手实践下即可:

我这里绘制的很简单,单个指标就是一幅图,可以多个指标叠在一张图上面都是可以的,感兴趣的话可以自己试试。
最后简单看下推理检测实例,如下所示:



到这里本文的实践就结束了,感兴趣的话就自己动手试试吧。