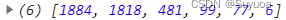C++那些事之彻底搞懂STL HashTable
C++那些事之彻底搞懂STL HashTable
1.常用容器
1.1 接口层
2.HashTable原理
2.1 _Hash_node结构
2.2 hashtable实现
2.3 如何确定桶?
2.4 如何确定在桶中的位置?
3.Rehash
3.1 计算新桶大小
3.2 判断是否需要rehash
3.3 rehash
最近的繁星计划有一个task是阅读hashtable源码,看到一些朋友的提问,这里将总结一些面试常考点,以及看完hashtable你必须要掌握的几点内容。
unordered_xxx容器的h1、h2分别是什么?分别在什么场景下使用,在代码当中是如何使用的?起了什么作用?
unordered_xxx在hashtable中存储的key、value分别是什么?
hashtable的
_Hash_node里面存储的是什么?key?value?还是?hashtable的底层算法逻辑是?桶?怎么设计?
桶的扩容机制是什么?
rehash是干什么用的,什么场景下触发?
对应的视频教程:
注:期待更多内容,欢迎加入知识星球呀~
1.常用容器
unordered_map
unordered_multimap
unordered_set
unordered_multiset
1.1 接口层
// unordered_map
template<typename _Key,
typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = std::equal_to<_Key>,
typename _Alloc = std::allocator<std::pair<const _Key, _Tp> >,
typename _Tr = __umap_traits<__cache_default<_Key, _Hash>::value>>
using __umap_hashtable = _Hashtable<_Key, std::pair<const _Key, _Tp>,
_Alloc, __detail::_Select1st,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
// unordered_multimap.
template<typename _Key,
typename _Tp,
typename _Hash = hash<_Key>,
typename _Pred = std::equal_to<_Key>,
typename _Alloc = std::allocator<std::pair<const _Key, _Tp> >,
typename _Tr = __ummap_traits<__cache_default<_Key, _Hash>::value>>
using __ummap_hashtable = _Hashtable<_Key, std::pair<const _Key, _Tp>,
_Alloc, __detail::_Select1st,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
// unordered_set
template<typename _Value,
typename _Hash = hash<_Value>,
typename _Pred = std::equal_to<_Value>,
typename _Alloc = std::allocator<_Value>,
typename _Tr = __uset_traits<__cache_default<_Value, _Hash>::value>>
using __uset_hashtable = _Hashtable<_Value, _Value, _Alloc,
__detail::_Identity, _Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;
// unordered_multiset
template<typename _Value,
typename _Hash = hash<_Value>,
typename _Pred = std::equal_to<_Value>,
typename _Alloc = std::allocator<_Value>,
typename _Tr = __umset_traits<__cache_default<_Value, _Hash>::value>>
using __umset_hashtable = _Hashtable<_Value, _Value, _Alloc,
__detail::_Identity,
_Pred, _Hash,
__detail::_Mod_range_hashing,
__detail::_Default_ranged_hash,
__detail::_Prime_rehash_policy, _Tr>;对应到_Hashtable类:
template<typename _Key, typename _Value, typename _Alloc,
typename _ExtractKey, typename _Equal,
typename _H1, typename _H2, typename _Hash,
typename _RehashPolicy, typename _Traits>
class _Hashtable我们把上面的模版参数一个个对应上。
| 容器类 | _Key | _Value | _Alloc | _ExtractKey | _Equal | _H1 | _H2 | _Hash | _RehashPolicy | _Traits |
|---|---|---|---|---|---|---|---|---|---|---|
| unordered_map | _Key | std::pair<const _Key, _Tp> | std::allocator<std::pair<const _Key, _Tp>> | __detail::_Select1st | std::equal_to<_Key> | std::hash<_Key> | __detail::_Mod_range_hashing | __detail::_Default_ranged_hash | __detail::_Prime_rehash_policy | __umap_traits |
| unordered_multimap | _Key | std::pair<const _Key, _Tp> | std::allocator<std::pair<const _Key, _Tp>> | __detail::_Select1st | std::equal_to<_Key> | std::hash<_Key> | __detail::_Mod_range_hashing | __detail::_Default_ranged_hash | __detail::_Prime_rehash_policy | __ummap_traits |
| unordered_set | _Value | _Value | std::allocator<_Value> | __detail::_Identity | std::equal_to<_Value> | std::hash<_Value> | __detail::_Mod_range_hashing | __detail::_Default_ranged_hash | __detail::_Prime_rehash_policy | __uset_traits |
| unordered_multiset | _Value | _Value | std::allocator<_Value> | __detail::_Identity | std::equal_to<_Value> | std::hash<_Value> | __detail::_Mod_range_hashing | __detail::_Default_ranged_hash | __detail::_Prime_rehash_policy | __umset_traits |
上表中列出的模板参数包括:
_Key:关联容器中的键类型。_Value:关联容器中的值类型。_Alloc:用于内存分配的分配器类型。_ExtractKey:从键值对中提取键的函数对象类型。_Equal:判断键是否相等的函数对象类型。_H1:第一个哈希函数对象类型。_H2:第二个哈希函数对象类型。_Hash:哈希函数对象类型。_RehashPolicy:重新哈希策略类型。_Traits:特定容器特性的类型。
注意:_Hash是在无缓存hashcode情况下去使用,参考:
struct _Hash_code_base<_Key, _Value, _ExtractKey, _H1, _H2, _Hash, false>2.HashTable原理
2.1 _Hash_node结构
在_Hashtable类中有一个__node_type,这个对应_Hash_node。
using __node_type = __detail::_Hash_node<_Value, __hash_cached::value>;_Hash_node有两个:
存储hashcode
不存储hashcode
+-----------------------------------+
| _Hash_node_base |
+-----------------------------------+
| - next: _Hash_node* |
+-----------------------------------+
^
|
|
+-----------------------------------+
| _Hash_node_value_base |
+-----------------------------------+
| - _M_storage: __aligned_buffer<_Value> |
+-----------------------------------+
| + _M_valptr(): _Value* |
| + _M_valptr() const: const _Value* |
| + _M_v(): _Value& |
| + _M_v() const: const _Value& |
+-----------------------------------+
^
|
|
+--------------------------------+
| _Hash_node |
+--------------------------------+
| - _M_hash_code: std::size_t |
+--------------------------------+2.2 hashtable实现
以find为例:
// 省略template
find(const key_type& __k)
{
// 计算键的哈希码
__hash_code __code = this->_M_hash_code(__k);
// 根据哈希码计算桶的索引
std::size_t __n = _M_bucket_index(__k, __code);
// 在指定桶中查找节点
__node_type* __p = _M_find_node(__n, __k, __code);
// 如果找到节点,返回指向该节点的迭代器;否则返回尾后迭代器
return __p ? iterator(__p) : end();
}首先,通过调用
_M_hash_code方法计算键的哈希码__code。哈希码是根据键的值计算得到的,用于确定键在哈希表中的存储位置。接下来,通过调用
_M_bucket_index方法根据键的哈希码计算桶的索引__n。桶是哈希表中的存储单元,每个桶可以存储一个或多个节点。通过将键的哈希码与桶的数量取模,可以确定键应该存储在哪个桶中。然后,通过调用
_M_find_node方法在指定的桶中查找节点。该方法会遍历桶中的节点,并根据节点的键和哈希码与目标键进行比较,找到匹配的节点。如果找到了匹配的节点,就创建一个迭代器
iterator,指向该节点,并返回该迭代器。否则,返回尾后迭代器end(),表示未找到匹配的节点。
2.3 如何确定桶?
里面有几个比较重要的函数:
// 接口
size_type
_M_bucket_index(__node_type* __n) const noexcept
{ return __hash_code_base::_M_bucket_index(__n, _M_bucket_count); }
size_type
_M_bucket_index(const key_type& __k, __hash_code __c) const
{ return __hash_code_base::_M_bucket_index(__k, __c, _M_bucket_count); }
// 实现
__hash_code
_M_hash_code(const _Key& __k) const
{ return _M_h1()(__k); }
std::size_t
_M_bucket_index(const _Key&, __hash_code __c,
std::size_t __n) const
{ return _M_h2()(__c, __n); }计算hashcode是通过h1计算出来,随后依据hashcode查找桶的index,此时通过h2计算,对于map与set(这里简称,都对应的是unordered_xxx)来说,H1是不一样,分别是Hash(key)、Hash(value),而h2是一样的,都是_Mod_range_hashing:
struct _Mod_range_hashing
{
typedef std::size_t first_argument_type;
typedef std::size_t second_argument_type;
typedef std::size_t result_type;
result_type
operator()(first_argument_type __num,
second_argument_type __den) const noexcept
{ return __num % __den; }
};这里呢使用了operator()重载,所以上面的计算桶的公式就出来了。
buckek_index = (h1(key)) % _M_bucket_count;2.4 如何确定在桶中的位置?
直接贴一下代码吧,_M_find_node会去查找目标节点之前的节点,这样方便单链表的插入、删除操作。
__node_type* _M_find_node(size_type __bkt, const key_type& __key,
__hash_code __c) const
{
// 查找目标节点之前的节点
__node_base* __before_n = _M_find_before_node(__bkt, __key, __c);
// 如果找到了目标节点之前的节点,返回目标节点
if (__before_n)
return static_cast<__node_type*>(__before_n->_M_nxt);
// 否则返回 nullptr,表示未找到目标节点
return nullptr;
}
__node_base* _M_find_before_node(size_type __n, const key_type& __k,
__hash_code __code) const
{
// 获取桶中的首节点
__node_base* __prev_p = _M_buckets[__n];
// 如果桶中没有节点,返回 nullptr
if (!__prev_p)
return nullptr;
// 遍历桶中的节点,查找目标节点之前的节点
for (__node_type* __p = static_cast<__node_type*>(__prev_p->_M_nxt);; __p = __p->_M_next())
{
// 判断当前节点是否与目标节点匹配
if (this->_M_equals(__k, __code, __p))
return __prev_p;
// 如果当前节点没有下一个节点,或者下一个节点所在桶的索引不等于当前桶索引,结束遍历
if (!__p->_M_nxt || _M_bucket_index(__p->_M_next()) != __n)
break;
// 更新目标节点之前的节点为当前节点
__prev_p = __p;
}
// 返回 nullptr,表示未找到目标节点之前的节点
return nullptr;
}到这里是不是非常清楚hashtable的实现呢?是的,首先是确定桶,再次是个链表然后查找到当前key的前一个节点,有了这个接口,你会发现插入、删除、查找都非常简单了。
3.Rehash
紧接着,还有个比较重要的称为rehash,相信大家很清楚rehash,当散列表的冲突到达一定程度,那么就需要重新将key放到合适位置,这里封装成了一个rehash policy:
struct _Prime_rehash_policy
{
//...
};rehash操作中提到:桶的大小(bucket size) 默认通常是最小的素数,从而保证装载因子(load factor 容器当前元素数量与桶数量之比。)足够小。装载因子用来衡量哈希表满的程度,最大加载因子默认值为1.0.
_Prime_rehash_policy(float __z = 1.0)
: _M_max_load_factor(__z), _M_next_resize(0) { }当哈希冲突的时候,怎么rehash呢?
3.1 计算新桶大小
std::size_t
_Prime_rehash_policy::_M_next_bkt(std::size_t __n) const
{
// Optimize lookups involving the first elements of __prime_list.
// (useful to speed-up, eg, constructors)
static const unsigned char __fast_bkt[12]
= { 2, 2, 2, 3, 5, 5, 7, 7, 11, 11, 11, 11 };
if (__n <= 11)
{
_M_next_resize =
__builtin_ceil(__fast_bkt[__n] * (long double)_M_max_load_factor);
return __fast_bkt[__n];
}
const unsigned long* __next_bkt =
std::lower_bound(__prime_list + 5, __prime_list + _S_n_primes, __n);
_M_next_resize =
__builtin_ceil(*__next_bkt * (long double)_M_max_load_factor);
return *__next_bkt;
}函数中的 __fast_bkt 数组存储了一些预定义的较小的素数值,用于优化对前几个元素的查找。
如果 __n 小于等于 11,函数会直接返回 __fast_bkt[__n],并计算 _M_next_resize 的值,这个值表示下一次重新调整大小(resize)的阈值。
如果 __n 大于 11,函数将使用 std::lower_bound 在 __prime_list 数组中查找大于等于 __n 的第一个素数。__prime_list 是另一个数组,它存储了一系列素数值。然后函数会计算 _M_next_resize 的值,并返回找到的素数。
该函数的目的是根据给定的哈希表大小 __n,计算出下一个合适的哈希桶(bucket)的大小,并返回该大小。
写个小函数,测试一下,假设hashtable依次初始化0个元素、1个元素,依次类推,用i表示,下面的结果为bucket的数量,可以看到跟前面的__fast_bkt与__prime_list是对的上的。
➜ practice ./a.out
=====i = 0====
1
=====i = 1====
2
=====i = 2====
2
=====i = 3====
3
=====i = 4====
5
=====i = 5====
5
=====i = 6====
7
=====i = 7====
7
=====i = 8====
11
=====i = 9====
11
=====i = 10====
11
=====i = 11====
11
=====i = 12====
13
=====i = 13====
13
=====i = 14====
17
=====i = 15====
17
=====i = 16====
17
=====i = 17====
17
=====i = 18====3.2 判断是否需要rehash
函数接受三个参数:__n_bkt 表示当前的哈希桶数量,__n_elt 表示当前的元素数量,__n_ins 表示待插入的元素数量。
std::pair<bool, std::size_t>
_Prime_rehash_policy::
_M_need_rehash(std::size_t __n_bkt, std::size_t __n_elt, std::size_t __n_ins) const
{
if (__n_elt + __n_ins >= _M_next_resize)
{
long double __min_bkts = (__n_elt + __n_ins) / (long double)_M_max_load_factor;
if (__min_bkts >= __n_bkt)
{
return std::make_pair(true, _M_next_bkt(std::max<std::size_t>(__builtin_floor(__min_bkts) + 1, __n_bkt * _S_growth_factor)));
}
_M_next_resize = __builtin_floor(__n_bkt * (long double)_M_max_load_factor);
return std::make_pair(false, 0);
}
else
{
return std::make_pair(false, 0);
}
}
static const std::size_t _S_growth_factor = 2;函数首先通过比较 __n_elt + __n_ins 和 _M_next_resize 的大小来判断是否需要重新散列。_M_next_resize 是在之前的操作中计算得到的下一次重新调整大小的阈值。如果 __n_elt + __n_ins 大于等于 _M_next_resize,则表示需要重新散列。
接着,函数计算 __min_bkts,即根据当前元素数量和负载因子 _M_max_load_factor 估计的最小所需桶数量。如果 __min_bkts 大于等于 __n_bkt,则说明当前桶数量已经不足以满足最小所需桶数量,需要重新散列。此时,函数会调用 _M_next_bkt 函数来计算下一个合适的桶数量,并返回 std::make_pair(true, p),其中 p 是下一个合适的桶数量。
如果 __min_bkts 小于 __n_bkt,则说明当前桶数量仍然足够,不需要重新散列。此时,函数会更新 _M_next_resize 为 __n_bkt * _M_max_load_factor,表示下一次重新调整大小的阈值,并返回 std::make_pair(false, 0),表示不需要重新散列。
如果 __n_elt + __n_ins 小于 _M_next_resize,则说明当前元素数量未达到重新散列的阈值,不需要重新散列。函数直接返回 std::make_pair(false, 0),表示不需要重新散列。
所以,我们知道了扩容桶的规则是什么了。
long double __min_bkts = (当前元素数量 + 插入的元素数量) / (long double)_M_max_load_factor;
std::max<std::size_t>(__builtin_floor(__min_bkts) + 1, n * 2)3.3 rehash
rehash最终会通过辅助函数_M_rehash_aux完成rehash操作。
分配新桶
数据迁移
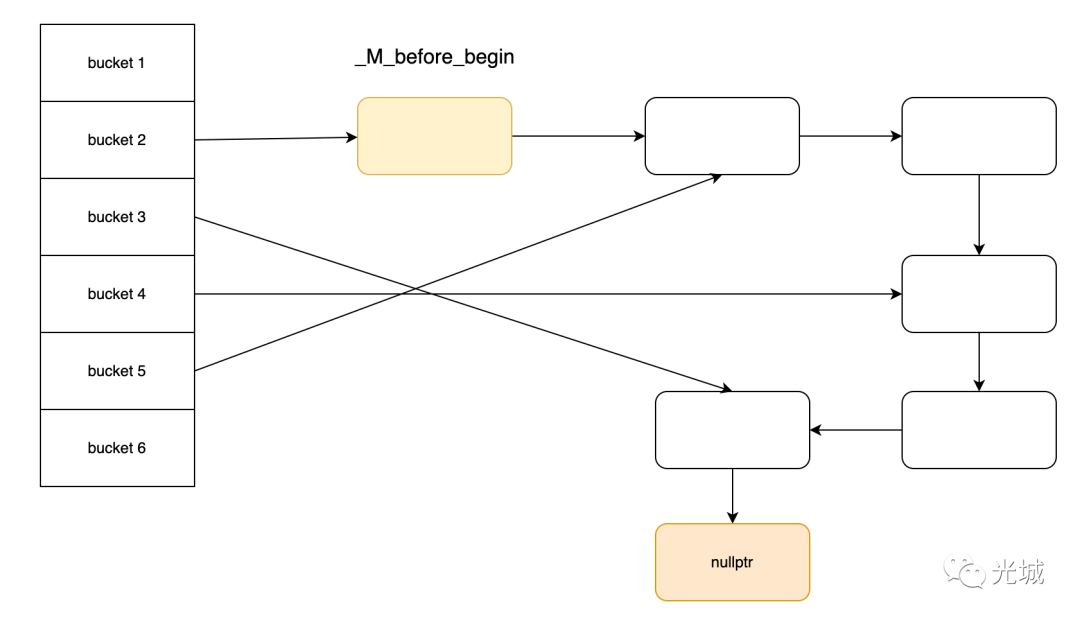
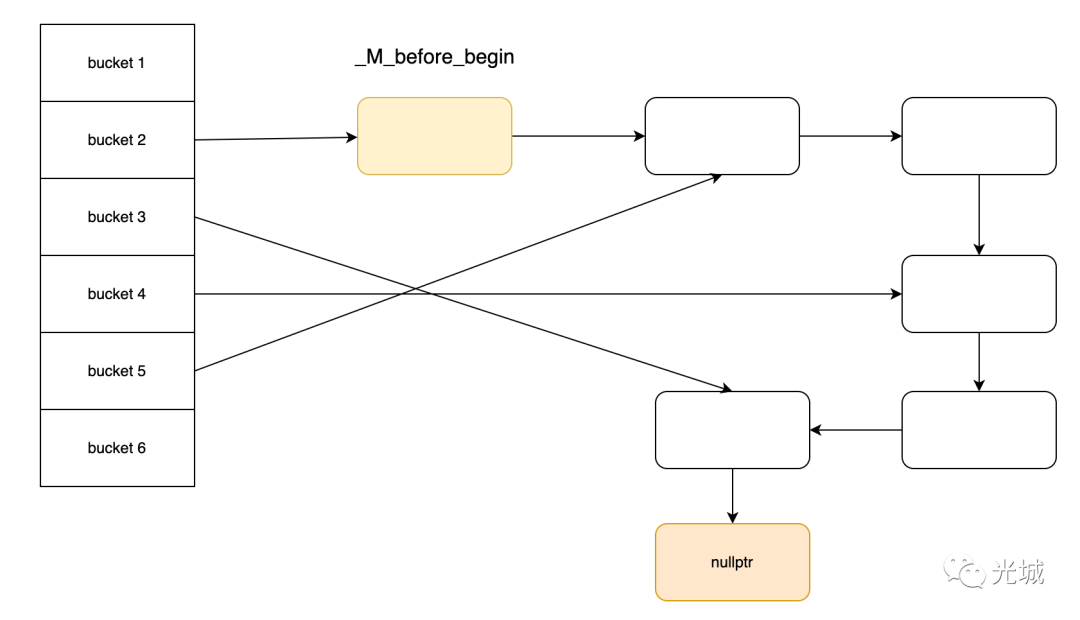
注意哨兵节点或者说dummy节点_M_before_begin,每建立一个新bucket,第一个节点永远是_M_before_begin。对应代码为:__new_buckets[__bkt] = &_M_before_begin;
具体的操作见下面注释:
void
_Hashtable<_Key, _Value, _Alloc, _ExtractKey, _Equal,
_H1, _H2, _Hash, _RehashPolicy, _Traits>::
_M_rehash_aux(size_type __n, std::true_type)
{
__bucket_type *__new_buckets = _M_allocate_buckets(__n);
__node_type *__p = _M_begin();
_M_before_begin._M_nxt = nullptr;
std::size_t __bbegin_bkt = 0; // 前一个桶的index
while (__p)
{
__node_type *__next = __p->_M_next();
std::size_t __bkt = __hash_code_base::_M_bucket_index(__p, __n);
if (!__new_buckets[__bkt]) // 桶不存在
{
__p->_M_nxt = _M_before_begin._M_nxt; // __p链接上旧桶的第一个有效节点
_M_before_begin._M_nxt = __p; // _M_before_begin链接上__p
__new_buckets[__bkt] = &_M_before_begin; // 新桶的第一个节点为_M_before_begin
if (__p->_M_nxt) // 前一个旧桶有节点
__new_buckets[__bbegin_bkt] = __p; // 当前__p为旧桶的第一个有效节点
__bbegin_bkt = __bkt; // 更新桶的index
}
else // 桶存在 头插法 插入当前节点
{
__p->_M_nxt = __new_buckets[__bkt]->_M_nxt;
__new_buckets[__bkt]->_M_nxt = __p;
}
__p = __next;
}
_M_deallocate_buckets();
_M_bucket_count = __n;
_M_buckets = __new_buckets;
}
![[PCIE体系结构导读]PCIE总结(二)](https://img-blog.csdnimg.cn/cd26d82996ba46dc9b6b76ca2ab0b782.png)