作者:David Brimley

索引这个术语在科技界已经被用满了。 如果你问大多数开发人员什么是索引,他们可能会告诉你索引通常指的是关系数据库 (RDBMS) 中与表关联的数据结构,它提高了数据检索操作的速度。
但什么是 Elasticsearch® 索引? Elasticsearch 索引是一个逻辑命名空间,它保存文档集合,其中每个文档都是字段的集合,而字段又是包含数据的键值对。
Elasticsearch 索引与关系数据库有何不同?
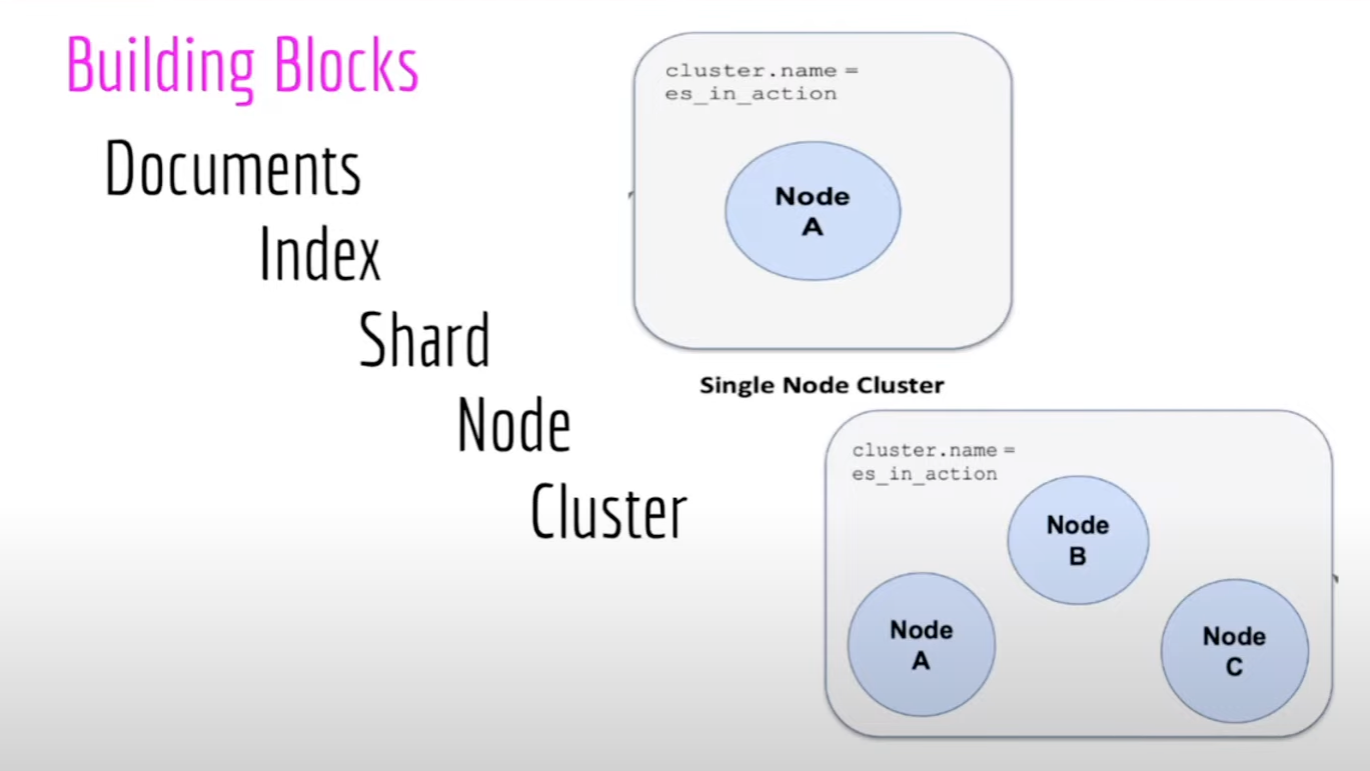
Elasticsearch 索引与你在关系数据库中找到的索引不同。 将 Elasticsearch 集群视为一个数据库,其中可以包含许多索引(你可以将其视为一个表),并且在每个索引中都有许多文档。
- RDBMS => 数据库 => 表 => 列/行
- Elasticsearch => 集群 => 索引 => 分片 => 具有键值对的文档
虽然 Elasticsearch 存储 JSON 文档,但你输入到索引中的内容非常灵活。 使用大量可用的集成(integrations)和 Beats,启动和运行是一个快速的进程。 或者,你可以进一步使用 Ingest Pipelines 或 Logstash® 并借助其众多处理器和插件来定义你自己的 ETL 流程。
与关系数据库的另一个不同之处在于,你可以导入数据而无需任何预先的架构定义。 动态类型是快速入门或解释文档中意外字段的好方法。 然后,一旦设置完毕,切换到固定模式以提高性能。
运行时字段(runtime fields)是另一个有趣的功能,它允许你在读取或写入时执行架构。 可以将它们添加到现有文档并用于派生新字段,或者你可以在查询时创建运行时字段。 将它们视为使用可以读入文档源的脚本计算的值。
准备好看看行动上的差异了吗? 立即使用 Elastic Cloud 上的试用帐户免费试用。
数据如何与 Elasticsearch 用户友好的 API 交互
Elasticsearch 提供基于 RESTful JSON 的 API 用于与文档数据交互。 你可以通过向适当的集群端点发送 HTTP 请求来索引、搜索、更新和删除文档。 这些类似 CRUD 的操作可以发生在单个文档级别或索引级别本身。 如果你愿意,还可以使用特定于语言的客户端库来代替直接 REST。
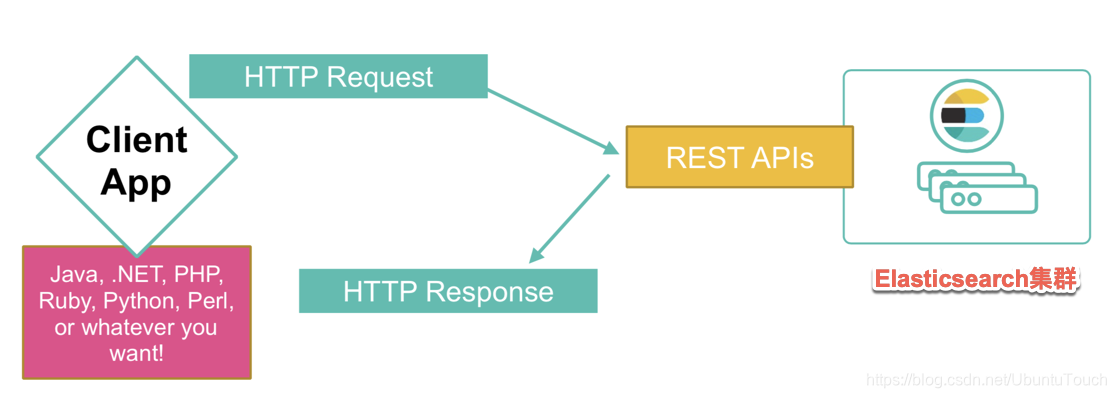
以下示例在名为 playwrights 的索引中创建一个文档,指定的 document_id 为 1。请注意,我们不需要创建任何模式或预先配置;只需创建一个文档即可。 我们只需插入我们的数据。
POST /playwrights/_doc/1
{
"firstname": "William",
"lastname": "Shakespeare"
}我们可以根据需要进一步添加文档和字段,这不是关系数据库可以轻松做到的事情。
POST /playwrights/_doc/2
{
"firstname": "Samuel",
"lastname": "Beckett",
"year_of_birth": 1906
}现在我们可以使用搜索端点查询所有文档:
GET /playwrights/_search
{
"query": {
"match_all": {}
}
}或者我们可以查询特定的出生年份:
GET /playwrights/_search
{
"query": {
“match": {
“year_of_birth": 1906
}
}
}除了基本查询之外,Elasticsearch 还提供高级搜索功能,例如模糊匹配、词干提取、相关性评分、突出显示和标记化(将文本分解为更小的块(称为分词))。 在大多数情况下,这些标记是单独的单词,但有许多不同的分词器可用。你如果想尝试,请详细阅读文章 “开始使用 Elasticsearch (1)”。
为什么非规范化数据对于更快的数据检索至关重要?
在关系数据库中,常常应用规范化来消除数据冗余,保证数据一致性。 例如,你可能有单独的客户、产品和订单表。
在 Elasticsearch 中,非规范化是一种常见的做法。 你无需将数据拆分到多个表中,而是将所有相关信息存储在单个 JSON 文档中。 订单文档将包含客户信息和产品信息,而不是持有引用单独产品和客户索引的外键的订单文档。 这样可以在搜索操作期间更快、更高效地检索 Elasticsearch 中的数据。 根据一般经验,存储可能比连接数据的计算成本更便宜。
更多阅读,请参考 “Elasticsearch:Elasticsearch 中索引映射的非规范化”。
Elasticsearch 如何保证分布式系统的可扩展性?
每个索引都由唯一名称标识,并分为一个或多个分片,这些分片是索引的较小子集,允许跨 Elasticsearch 节点集群进行并行处理和分布式存储。 分片具有主分片和副本分片,副本提供数据的冗余副本,以防止硬件故障并增加服务读取请求(例如搜索或检索文档)的容量。

在集群中添加更多的节点可以为你提供更多的索引和搜索能力,而这对于关系数据库来说是不容易实现的。
回到上面的 playwrights 示例,如果运行以下命令,我们可以看到 Elasticsearch 自动推断的类型映射以及索引分配的分片和副本的数量。
GET /playwrights/Elasticsearch 可以对哪些类型的数据建立索引?
Elasticsearch 可以索引多种类型的数据 - 主要是文本,但也可以索引数字和地理位置数据。 它还可以存储用于相似性搜索的密集向量。 让我们依次看看其中的每一个。
用于文本/词汇搜索的倒排索引
Elasticsearch 还将选择用于特定字段类型的最佳底层数据结构。 例如,文本将被分词化,然后存储在倒排索引中,该索引是一种列出任何文档中出现的每个唯一分词并标识每个单词出现的所有文档的结构。
下表显示了倒排索引的一般构成。 我们可以看到,如果我们要搜索术语 London,我们会发现它出现在索引中的六个不同文档中。 正是这种倒排索引使我们能够非常快速地执行文本查询。
| Token | Document IDs |
| London | 1,3,8,12,23,88 |
| Paris | 1,12,88 |
| Madrid | 3,8,12 |
| Berlin | 12,23 |
用于高效空间分析的数字和地理位置搜索功能
数字和地理位置数据将存储在 BKD 树中,也称为块 KD 树索引,它是工程应用中用于高效空间索引和多维数据查询的数据结构。 它将数据点组织成块,允许在大型数据集中进行快速范围搜索和最近邻查询,使其成为处理空间数据分析和优化的工程师的宝贵工具。
使用 NLP 进行矢量/语义搜索
你可能听说过矢量搜索,但它是什么? 矢量搜索引擎(称为矢量数据库、语义搜索或余弦搜索)查找给定(矢量化)查询的最近邻居。 矢量搜索的强大之处在于它可以发现不完全文本匹配的相似文档,正如上面的倒排索引示例所要求的那样; 相反,它使用描述某种程度相似性的矢量。
自然语言处理 (NLP) 社区开发了一种称为文本嵌入的技术,它将单词和句子编码为数字矢量。 这些矢量表示旨在捕获文本的语言内容,它们可用于评估查询和文档之间的相似性。
矢量搜索的一些常见用例是:
- 回答问题
- 查找先前回答过的问题的答案,其中所提出的问题相似但在文本形式上不完全相同
- 提出推荐 - 例如,音乐应用程序根据你的喜好查找类似的歌曲
所有这些用例都利用数万维的向量,提供数据的全面表示,以实现准确的相似性评估和有针对性的建议。
Elasticsearch 通过密集矢量(dense_vector)文档类型支持矢量搜索,并且能够在文档中的矢量与转换为矢量后的搜索词之间运行相似性搜索(similarity searches)。
对于那些想要更深入地研究生成式人工智能的人,我们还提供 ESRE(Elasticsearch Relevance Engine™),它旨在为基于人工智能的搜索应用程序提供支持。 ESRE 为开发人员提供了一整套复杂的检索算法以及与大型语言模型集成的能力。
试试看!
正如你所看到的,自从 Elastic 联合创始人兼首席技术官 Shay Banon 首次为他的妻子编写菜谱搜索引擎以来,Elasticsearch 索引已经取得了长足的进步。 还有很多东西有待发现,一个很好的起点是在 Elastic Cloud 上创建一个试用帐户 - 你将在几分钟内启动并运行。 此外,请查看 Elasticsearch 入门网络研讨会。