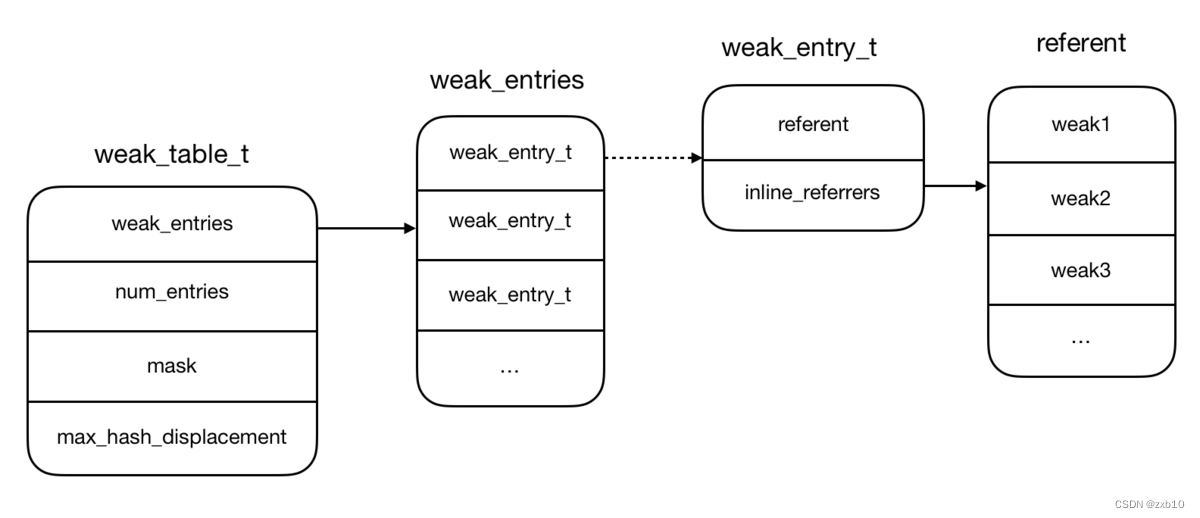
目录
1. 准备HDFS数据
2. 创建Doris表
3. 创建Spark Load导入任务
4. 查看导入任务状态
进入正文之前,欢迎订阅专题、对博文点赞、评论、收藏,关注IT贫道,获取高质量博客内容!
宝子们订阅、点赞、收藏不迷路!抓紧订阅专题!
下面以导入HDFS中数据到Doris表为例,介绍Spark Load的使用,这里使用“spark1”Spark Resource 。
1. 准备HDFS数据
准备spark_load_data.csv数据文件,内容如下。
spark_load_data.csv:
1,zs,18,100
2,ls,19,101
3,ww,20,102
4,ml,21,103
5,tq,22,104将以上数据文件上传到hdfs://mycluster/input/目录下:
[root@node1 ~]# hdfs dfs -put ./spark_load_data.csv /input/2. 创建Doris表
create table spark_load_t1(
id int,
name varchar(255),
age int,
score double
)
ENGINE = olap
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(`id`) BUCKETS 8;注意:Spark load 还不支持 Doris 表字段是String类型的导入,如果你的表字段有String类型的请改成varchar类型,不然会导入失败,提示 type:ETL_QUALITY_UNSATISFIED; msg:quality not good enough to cancel
3. 创建Spark Load导入任务
LOAD LABEL example_db.label1
(
DATA INFILE("hdfs://node1:8020/input/spark_load_data.csv")
INTO TABLE spark_load_t1
COLUMNS TERMINATED BY ","
FORMAT AS "csv"
(id,name,age,score_tmp)
SET
(
score = score_tmp + age
)
)
WITH RESOURCE 'spark1'
(
"spark.driver.memory" = "512M",
"spark.executor.cores" = "1",
"spark.executor.memory" = "512M",
"spark.shuffle.compress" = "true"
)
PROPERTIES
(
"timeout" = "3600"
);注意:
- 加载的HDFS中的文件,不支持HA写法,需要指定Active NameNode节点信息。
- 当 Spark Load 作业状态不为 CANCELLED 或 FINISHED 时,可以被用户手动取消。取消时需要指定待取消导入任务的 Label 。取消导入命令语法可执行 HELP CANCEL LOAD 查看。
- 如果想要清除对应完成的label,可以执行“clean label from example_db;”命令即可。
4. 查看导入任务状态
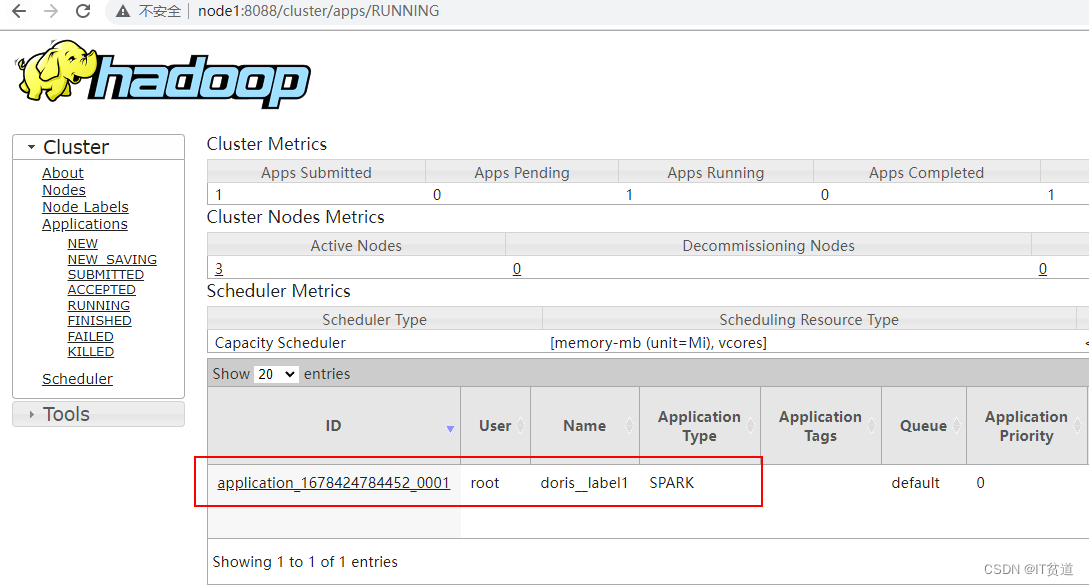
以上任务提交之后,可以在Yarn WebUI中查看提交的任务执行情况:
也可以在FE 节点“/software/doris-1.2.1/apache-doris-fe/log/spark_launcher_log”中查看执行日志,FE节点不一定在node1-node3哪台节点执行Spark ETL任务,执行任务的节点上才有以上日志路径,该日志默认保存3天。
在node1 mysql客户端也可以执行命令查看Spark Load导入情况,命令如下:
mysql> show load order by createtime desc limit 1\G;
*************************** 1. row ***************************
JobId: 37038
Label: label1
State: FINISHED
Progress: ETL:100%; LOAD:100%
Type: SPARK
EtlInfo: unselected.rows=0; dpp.abnorm.ALL=0; dpp.norm.ALL=5
TaskInfo: cluster:spark1; timeout(s):3600; max_filter_ratio:0.0
ErrorMsg: NULL
CreateTime: 2023-03-10 16:11:44
EtlStartTime: 2023-03-10 16:12:16
EtlFinishTime: 2023-03-10 16:12:59
LoadStartTime: 2023-03-10 16:12:59
LoadFinishTime: 2023-03-10 16:13:09
URL: http://node1:8088/proxy/application_1678424784452_0001/
JobDetails: {"Unfinished backends":{"0-0":[]},"ScannedRows":5,"TaskNumber":1,"LoadBytes":0,"All backends":{"0-0":[-1]},"FileNumber":1,"FileSi
ze":60} TransactionId: 24027
ErrorTablets: {}
1 row in set (0.01 sec)当Yarn中任务执行完成之后,通过以上命令查询Spark Load 执行情况还在执行,主要是因为当Spark ETL job完成后,Doris还会加载数据到对应的BE中,完成之后状态会改变成FINISHED。
5. 查看Doris表结果
mysql> select * from spark_load_t1;
+------+------+------+-------+
| id | name | age | score |
+------+------+------+-------+
| 2 | ls | 19 | 120 |
| 3 | ww | 20 | 122 |
| 5 | tq | 22 | 126 |
| 4 | ml | 21 | 124 |
| 1 | zs | 18 | 118 |
+------+------+------+-------+🏡个人主页:https://blog.csdn.net/qq_32020645?type=blog 主页包含各种IT体系技术
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!