在数学建模赛题中,官方给所有选手的数据可能受到主观或客观条件的影响有一定的问题,如果不进行数据的处理而直接使用的话可能对最终的结果造成一定的影响,因此为了保证数据的真实性和建模结果的可靠性,需要在建模之前对数据进行相关的预处理工作。
数据预处理一般包括:数据清洗,数据集成,数据变换和数据规约
数据清洗(数据中存在错误或异常数据,我们将这些数据找出并进行相关处理,使其变成常规的,近似正常的数据)
数据集成(将不同格式,不同获取规范,不同获取逻辑的数据集合在一块进行集中化处理)
数据变换(将数据按照一定的规范使它变成一个统一的数据集)
数据规约/数据降维(数据存在很多冗余或者数据的维度过高,计算起来十分复杂繁琐,因而使用关键的指标代替原先高维的数据)
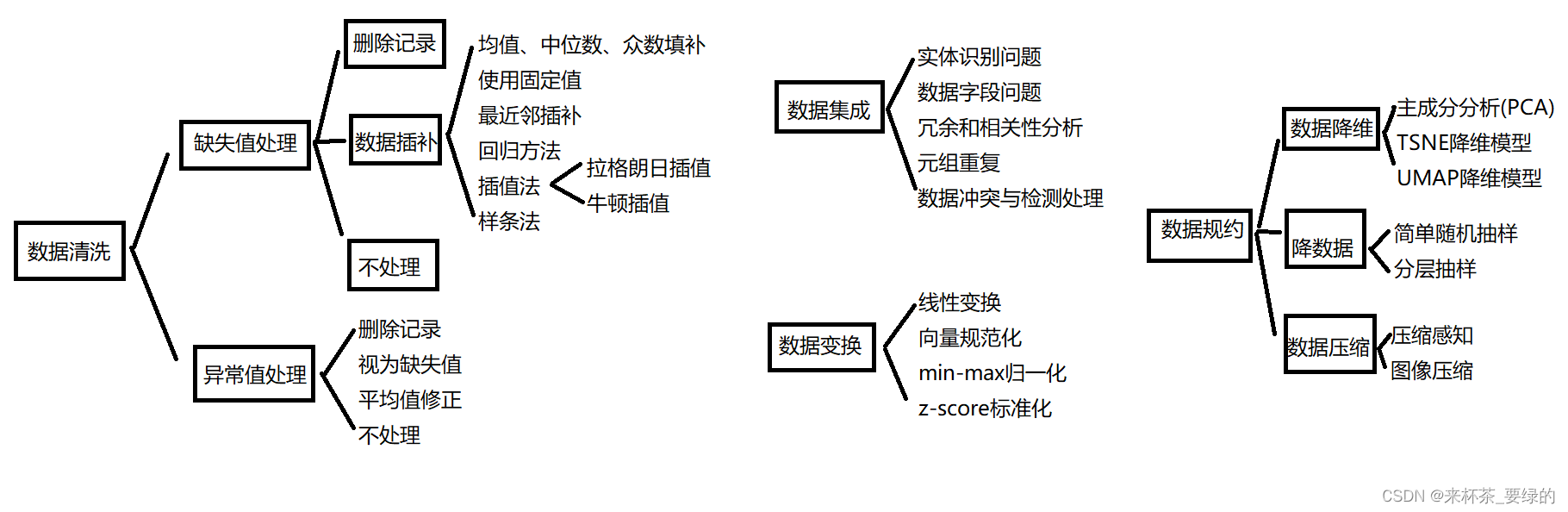
数据清洗
缺失值处理
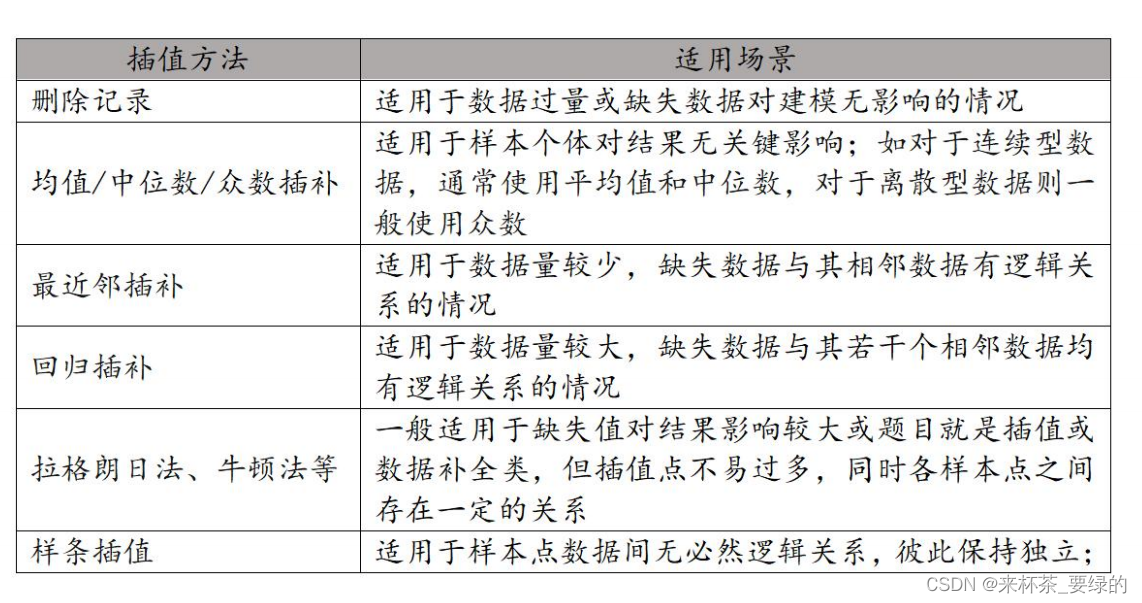
缺失值处理方法主要有三种:删除记录、数据插补、不处理
删除记录:指当该组数据某一个案的数据缺省时,删除组个案的数据,这种方法的优点是处理方便,但在数据较少时要慎重使用。
数据插补:使用不同的插补方法将缺省数据补齐。
最近邻插补:在记录中找到与缺失样本最接近的样本的该属性插补,可以通过计算对象间的欧氏距离衡量。
回归方法插补:根据已有数据和与其相关的其他变量的数据建立拟合模型来预测缺失值。
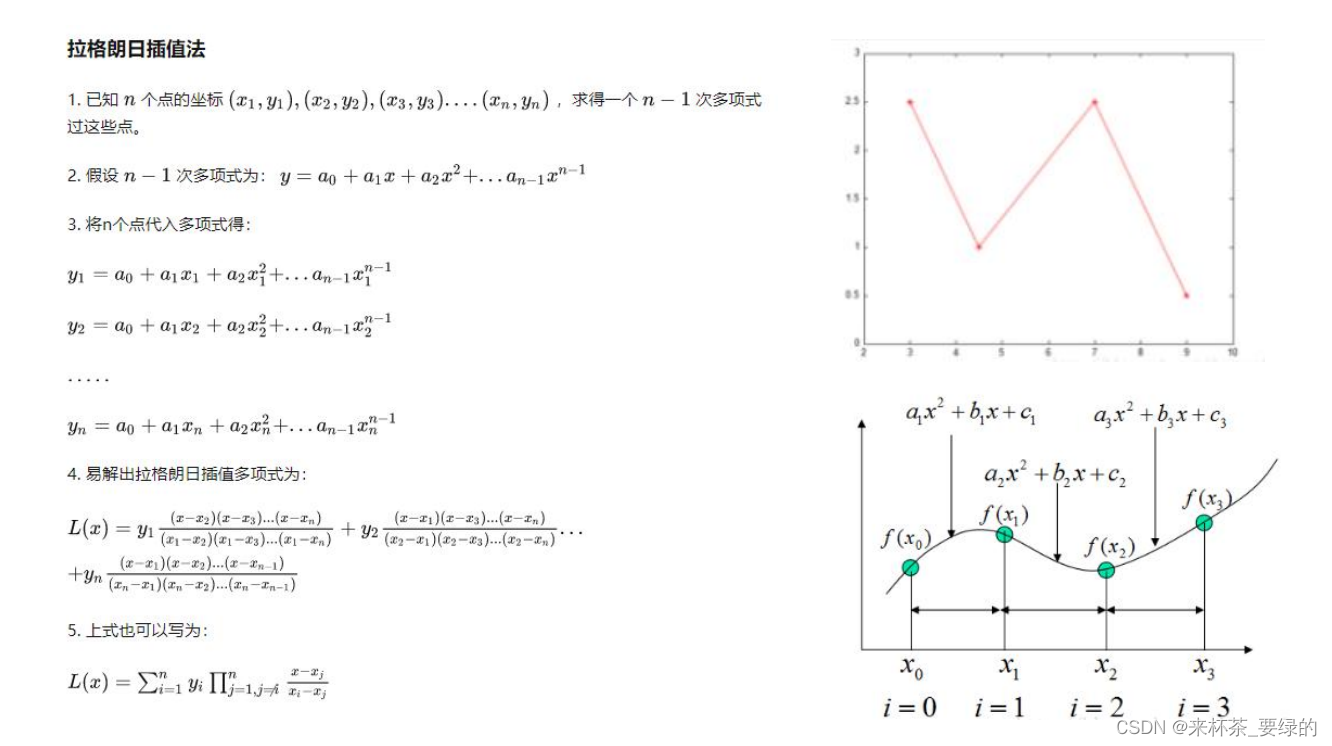
插值法:常用的插值法有很多,主要有拉格朗日插值法、牛顿插值法。
 异常值处理
异常值处理
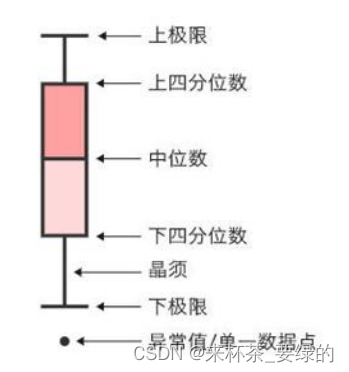
处理方法有两种:正态分布原则和画箱型图

数据变换
数据类型的一致化处理方法
一般问题的数据指标可能有“极大型”,“极小型”,“中间型”,“区间型”指标。
极大型:期望取值越大越好
极小型:期望取值越小越好
中间型:期望取值既不要太大,也不要太小,取适当区间为最好
区间型:期望取值最好是落在某个确定的区间内为最好
极小型:对某个极小型数据指标x,则令x'=1/x(x>0),或x'=M-x,即可将x极大化。
中间型:对某个中间型数据指标x,则令:
即可将中间型数据指标x极大化。
区间型:对某个区间型数据指标x,则令:
其中[a,b]为x的最佳稳定区间,c=max{a-m,M-b},M和m分别为x可能取值的最大值和最小值,即可将x极大化。
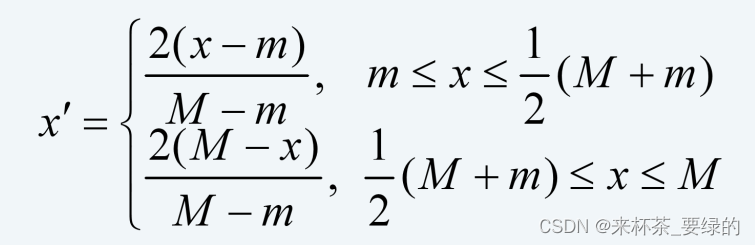
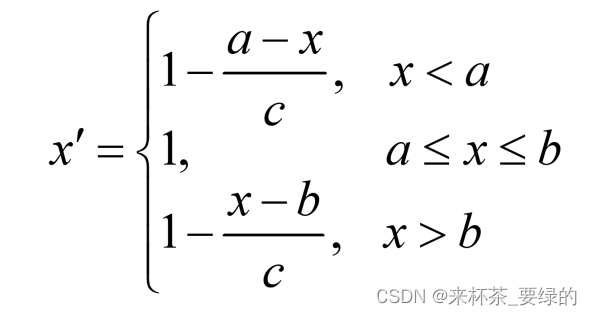
数据指标的无量纲化处理
在实际数据指标之间,往往存在着不可公度性(没有共同的基础、尺度和标准),直接应用是困难的,会出现“大数吃小数”(数据指标之间的量纲不同导致)的错误,从而导致结果的不合理。
常用方法:标准差法(数据比较均匀)、极值差法(数据分布不是很均匀,保留数据的原有特性)、功效系数法(极值差法基础改进)等。
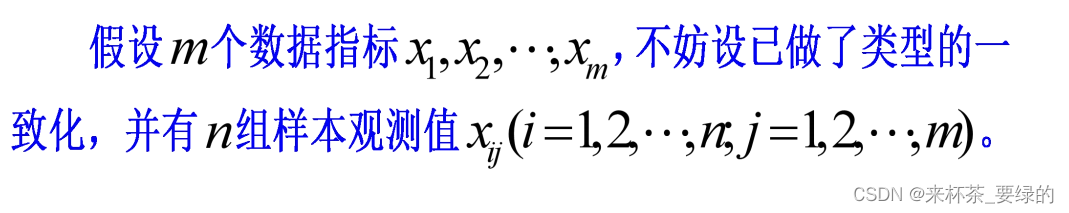



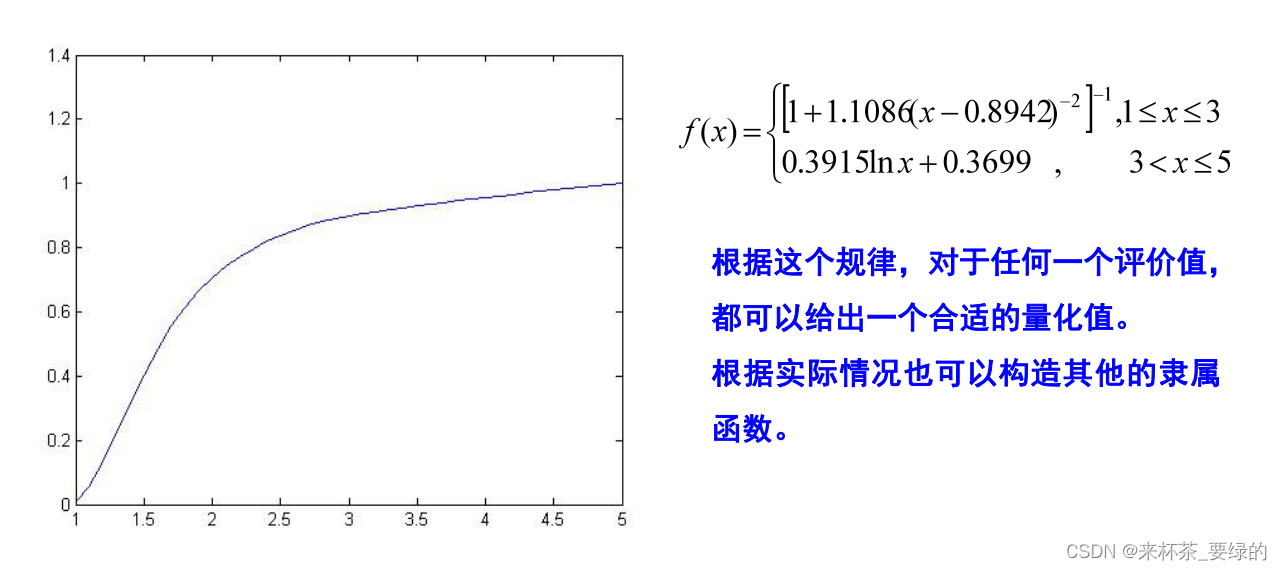
定性指标(文字指标)的量化处理方法
在社会实践中,很多问题都涉及到定性因素(指标)的定量化处理问题。诸如:教学质量、科研水平、工作政绩、人员素质、各种满意度、信誉、态度、意识、观念、能力等因素有关的政治、社会、人文等领域的问题。如何对这些相关问题给出定量分析呢?