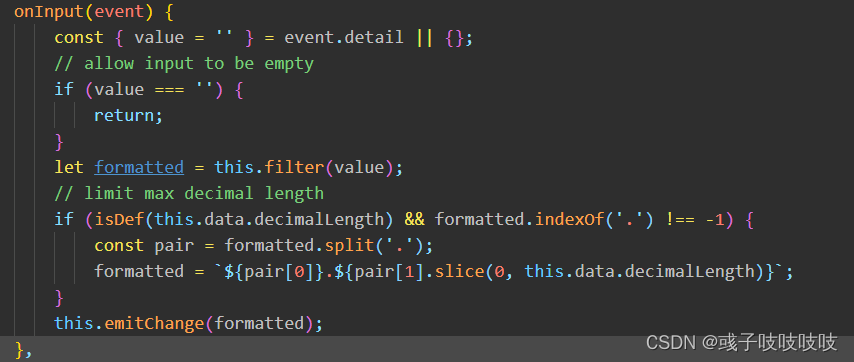
需求
有时候我们并不是需要返回两个字的相似,而是需要返回一个汉字的相似列表。
实现思路
我们可以分别计算所有的汉字之间的相似度,然后保留最大的前100个,放在字典中。
然后实时查询这个字典即可。
实现方式
bihuashu_2w.txt 中我们主要需要的是对应的 2W 常见汉字。
hanzi_similar_list.txt 用来存放汉字和相似字的映射关系。
数据初始化
public static void main(String[] args) {
final String path = "D:\\code\\coin\\nlp-hanzi-similar\\src\\main\\resources\\hanzi_similar_list.txt";
// 读取列表
List<String> lines = FileUtil.readAllLines("D:\\code\\coin\\nlp-hanzi-similar\\src\\main\\resources\\nlp\\bihuashu_2w.txt");
// 所有的单词
Set<String> allWordSet = new HashSet<>();
for(String line : lines) {
String word = line.split(" ")[0];
allWordSet.add(word);
}
// 循环对比
for(String word : allWordSet) {
List<String> list = getSimilarListData(word, allWordSet);
String line = word +" " + StringUtil.join(list, "");
FileUtil.append(path, line);
}
}
- 优先级队列取前 100 个
我们通过优先级队列存储:
private static List<String> getSimilarListData(String word, Set<String> wordSet) {
PriorityQueue<SimilarListDataItem> items = new PriorityQueue<>(new Comparator<SimilarListDataItem>() {
@Override
public int compare(SimilarListDataItem o1, SimilarListDataItem o2) {
// 相似度大的放在前面
return -o1.getRate().compareTo(o2.getRate());
}
});
for(String other : wordSet) {
if(word.equals(other)) {
continue;
}
// 对比
double rate = HanziSimilarHelper.similar(word.charAt(0), other.charAt(0));
SimilarListDataItem item = new SimilarListDataItem(other, rate);
items.add(item);
}
final int limit = 100;
List<String> wordList = new ArrayList<>();
for(SimilarListDataItem item : items) {
wordList.add(item.getWord());
if(wordList.size() >= limit) {
break;
}
}
return wordList;
}
相似字的获取
初始化好数据之后,一切就变得非常简单:
- 接口定义
/**
* 数据接口-相似列表
* @author binbin.hou
* @since 1.3.0
*/
public interface IHanziSimilarListData {
/**
* 返回数据信息
* @param word 单词
* @return 结果
* @since 1.3.0
*/
List<String> similarList(String word);
}
- 数据获取
public class HanziSimilarListData implements IHanziSimilarListData {
private static volatile Map<String, List<String>> map = Guavas.newHashMap();
@Override
public List<String> similarList(String word) {
if(MapUtil.isEmpty(map)) {
initDataMap();
}
return map.get(word);
}
private void initDataMap() {
if(MapUtil.isNotEmpty(map)) {
return;
}
//DLC
synchronized (map) {
if(MapUtil.isEmpty(map)) {
List<String> lines = StreamUtil.readAllLines("/hanzi_similar_list.txt");
for(String line : lines) {
String[] words = line.split(" ");
// 后面的100个相近词
List<String> list = StringUtil.toCharStringList(words[1]);
map.put(words[0], list);
}
}
}
}
}
便利性
为了用户使用方便,我们在 HanziSimilarHelper 中添加 2 个工具类方法:
/**
* 相似的列表
* @param hanziOne 汉字一
* @param limit 大小
* @return 结果
* @since 1.3.0
*/
public static List<String> similarList(char hanziOne, int limit) {
return HanziSimilarBs.newInstance().similarList(hanziOne, limit);
}
/**
* 相似的列表
* @param hanziOne 汉字一
* @return 结果
* @since 1.3.0
*/
public static List<String> similarList(char hanziOne) {
return similarList(hanziOne, 10);
}
测试效果
我们使用看一下效果:
我们来看一下【爱】的形近字。
List<String> list = HanziSimilarHelper.similarList('爱');
Assert.assertEquals("[爰, 爯, 受, 爭, 妥, 憂, 李, 爳, 叐, 雙]", list.toString());
开源地址
为了便于大家使用学习,项目已开源。
GitHub - houbb/nlp-hanzi-similar: The hanzi similar tool.(汉字相似度计算工具,中文形近字算法。可用于手写汉字识别纠正,文本混淆等。)
小结
一个字的形近字可以做很多有趣的事情,这个要看大家的想象力。
实现方式也不难,最核心的还是相似度的计算。