目录
一、什么是kafka
二、kafka接收外部接口数据
三、kafka收到数据后转发
四、kafka总结

一、什么是kafka
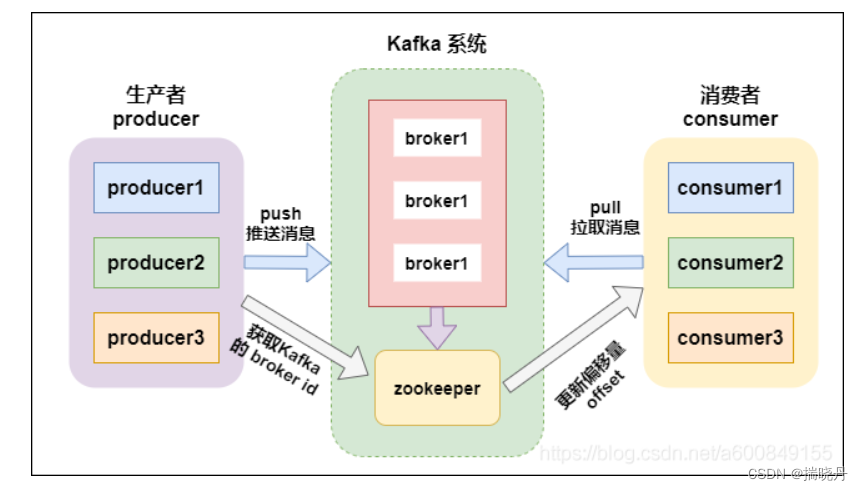
Kafka是一种分布式流式处理平台,最初由LinkedIn开发。它设计用于高吞吐量、低延迟的数据处理,能够处理大规模的实时数据流。Kafka采用发布-订阅模式,将数据发布到一个或多个主题(topics),然后订阅者可以根据自己的需求消费这些主题上的数据。
Kafka是一个分布式系统,它通过分区(partition)将数据进行水平切分,每个分区可以在集群中的不同服务器上进行数据存储和处理。这种设计使得Kafka具有高可伸缩性和高容错性,能够处理海量的数据,并能够在集群中的节点故障时保证数据的可用性。
Kafka广泛应用于日志收集、事件驱动架构、消息队列等场景。它可以用于构建实时数据流处理系统,将数据从源头快速传输到目标系统,并支持数据的持久化存储、数据的复制和数据的回放等功能。

二、kafka接收外部接口数据
Kafka可以通过编写生产者程序将外部接口的数据发送到Kafka集群中,下面是一个使用Java编写的Kafka生产者的简单示例代码:
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import java.util.Properties;
public class KafkaProducerExample {
public static void main(String[] args) {
// Kafka集群的地址
String bootstrapServers = "localhost:9092";
// 创建Producer的配置
Properties props = new Properties();
props.put("bootstrap.servers", bootstrapServers);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建Producer实例
Producer<String, String> producer = new KafkaProducer<>(props);
// 待发送的数据
String topic = "my_topic";
String key = "my_key";
String value = "Hello, Kafka!";
// 创建ProducerRecord并发送数据
ProducerRecord<String, String> record = new ProducerRecord<>(topic, key, value);
producer.send(record);
// 关闭Producer
producer.close();
}
}在上述示例代码中,我们通过创建一个KafkaProducer实例,配置相关参数(如Kafka集群地址、序列化器等),然后创建一个ProducerRecord对象表示要发送的数据,最后通过send方法将数据发送到指定的主题中。
你可以根据自己的需求修改代码中的相关参数,以适应你的具体场景和数据格式。
三、kafka收到数据后转发
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Arrays;
import java.util.Properties;
public class KafkaForwarder {
public static void main(String[] args) {
// Kafka集群的地址
String bootstrapServers = "localhost:9092";
// 消费者配置
Properties consumerProps = new Properties();
consumerProps.put("bootstrap.servers", bootstrapServers);
consumerProps.put("group.id", "my_consumer_group");
consumerProps.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumerProps.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerProps);
// 订阅要消费的主题
consumer.subscribe(Arrays.asList("my_topic"));
// 生产者配置
Properties producerProps = new Properties();
producerProps.put("bootstrap.servers", bootstrapServers);
producerProps.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producerProps.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者实例
Producer<String, String> producer = new KafkaProducer<>(producerProps);
// 循环消费数据并转发
while (true) {
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
// 获取消费的数据
String topic = record.topic();
String key = record.key();
String value = record.value();
// 转发数据给其他终端
// TODO: 编写转发逻辑,将数据发送到目标终端
// 示例:将数据发送到另一个Kafka主题中
String forwardTopic = "forward_topic";
ProducerRecord<String, String> forwardRecord = new ProducerRecord<>(forwardTopic, key, value);
producer.send(forwardRecord);
}
}
}
}在上述示例代码中,我们创建了一个 KafkaConsumer 实例用于从 Kafka 集群中消费数据,并创建了一个 KafkaProducer 实例用于转发数据。首先,我们设置消费者的配置,包括 Kafka 集群地址、消费者组、反序列化器等。然后,我们通过 subscribe 方法订阅要消费的主题。接下来,在一个无限循环中使用 poll 方法从 Kafka 集群中拉取数据,遍历消费数据并进行转发。在示例中,我们将转发的数据发送到另一个 Kafka 主题中,你可以根据自己的需求修改转发逻辑。记得在代码中替换相关配置参数,以适应你的具体场景。
四、kafka总结
Kafka是一个分布式流式处理平台,具有高吞吐量和低延迟的特性。在Kafka中,数据通过主题(topics)进行发布和订阅。生产者(Producer)将数据发送到指定的主题,而消费者(Consumer)从主题中消费数据。
要在Kafka中收发数据,首先需要创建一个生产者实例。生产者可以配置Kafka集群的地址、序列化器等参数。然后,通过创建一个ProducerRecord对象,将要发送的数据封装成记录。通过调用send方法,生产者将记录发送到指定的主题中。
对于消费者,需要创建一个消费者实例。消费者可以配置Kafka集群的地址、消费者组、反序列化器等参数。通过调用subscribe方法,消费者订阅要消费的主题。然后,使用poll方法以一定的时间间隔从Kafka集群中拉取数据。消费者从拉取的数据中遍历消费,可以根据需求处理数据,比如转发、存储等。
总结来说,使用Kafka收发数据的基本步骤如下:
-
创建生产者实例,配置相关参数。
-
创建ProducerRecord对象,封装要发送的数据。
-
调用send方法,将记录发送到指定的主题中。
-
创建消费者实例,配置相关参数。
-
调用subscribe方法,订阅要消费的主题。
-
使用poll方法,从Kafka集群中拉取数据。
-
遍历消费数据,进行相应处理。
需要注意的是,Kafka提供了丰富的配置选项和灵活的功能,可以根据具体的业务需求进行调整和扩展。同时,合理配置Kafka集群的参数、监控Kafka集群的运行状态,也是保障数据收发效率和可靠性的重要方面。
![[PHP]解决exec执行unzip出现中文文件名乱码的问题](https://img-blog.csdnimg.cn/d544d903a4724040838f3f88b7913ad7.png)