在上一篇文章《IoT 场景下写入性能:TDengine=16.2 x InfluxDB》中,我们基于 IoT 场景下的 TSBS 时序数据库(Time Series Database)性能基准测试报告对三大数据库写入性能进行了相关解读,较为直观地展现出了 TDengine 的众多写入优势。本篇文章将以查询性能作为主题,给 IoT 场景下正在为数据分析痛点而头疼的朋友们带来一些帮助。
在查询性能评估部分,我们使用场景一(只包含4天数据,这个修改与[TimescaleDB vs. InfluxDB]中要求一致)和场景二作为基准数据集,具体基础数据集的特点,请参照《IoT 场景 TSBS 测试报告结果一键检验,测试脚本是______》。
在查询性能评估之前,为确保两大数据库充分发挥查询性能,对于 TimescaleDB,我们采用[TimescaleDB vs. InfluxDB]中的推荐配置,设置为 8 个 Chunk ,以确保其充分发挥查询性能;对于 lInfluxDB,我们开启 InfluxDB 的 TSI (time series index)。在整个查询对比中,TDengine 数据库的虚拟节点数量(vnodes)保持为默认的 6 个(scale=100 时配置 1 个),其他的数据库参数配置为默认值。
TimescaleDB vs. InfluxDB: Purpose Built Differently for Time-Series Data:https://www.timescale.com/blog/TimescaleDB-vs-influxdb-for-time-series-data-timescale-influx-sql-nosql-36489299877/
4,000 devices × 10 metrics 查询性能对比
由于大部分类型单次查询响应时间过长,为了更加准确地测量每个查询场景下较为稳定的响应时间,我们依据卡车数量规模,将单个查询运行次数分别提升到 2,000 次(场景一)和 500 次(场景二),然后使用 TSBS 自动统计并输出结果,最后结果是多次查询的算数平均值,使用并发客户端 Workers 数量为 4。下表是场景二 (4,000 设备)的查询性能对比结果。
| 查询类型 | TDengine | InfluxDB | InfluxDB/TDengine | TimescaleDB | TimescaleDB/TDengine |
| last-loc | 11.52 | 562.86 | 4885.94% | 11.77 | 102.17% |
| low-fuel | 30.72 | 635 | 2067.06% | 416.75 | 1356.61% |
| high-load | 10.74 | 861.13 | 8017.97% | 11.62 | 108.19% |
| stationary-trucks | 23.9 | 3156.65 | 13207.74% | 195.46 | 817.82% |
| long-driving-sessions | 59.44 | 374.98 | 630.85% | 2938.54 | 4943.71% |
| long-daily-sessions | 218.97 | 1439.19 | 657.25% | 19080.95 | 8713.96% |
| avg-vs-projected-fuel-consumption | 3111.18 | 40842.05 | 1312.75% | 37127.24 | 1193.35% |
| avg-daily-driving-duration | 4402.15 | 43588.02 | 990.15% | 73781.97 | 1676.04% |
| avg-daily-driving-session | 4034.09 | 84494.79 | 2094.52% | 80765.04 | 2002.06% |
| avg-load | 1295.97 | 552493.78 | 42631.68% | 30452.26 | 2349.77% |
| daily-activity | 2314.64 | 15248.66 | 658.79% | 79242.14 | 3423.52% |
| breakdown-frequency | 5416.3 | 288804.93 | 5332.14% | 70205.29 | 1296.19% |
下面我们对每个查询结果做一定的分析说明:
注:查询一=daily-activity;查询二=avg-daily-driving-session;查询三=avg-daily-driving-duration;查询四=avg-vs-projected-fuel-consumption

4000 devices 查询响应时间 (数值越小越好)
在分组选择的查询中,TDengine 采用一张表一个设备(卡车)的设计方式,并采用缓存模式的 last_row 函数来查询最新的数据。从结果上看,TDengine 的查询响应时间均优于 InfluxDB 和 TimescaleDB。
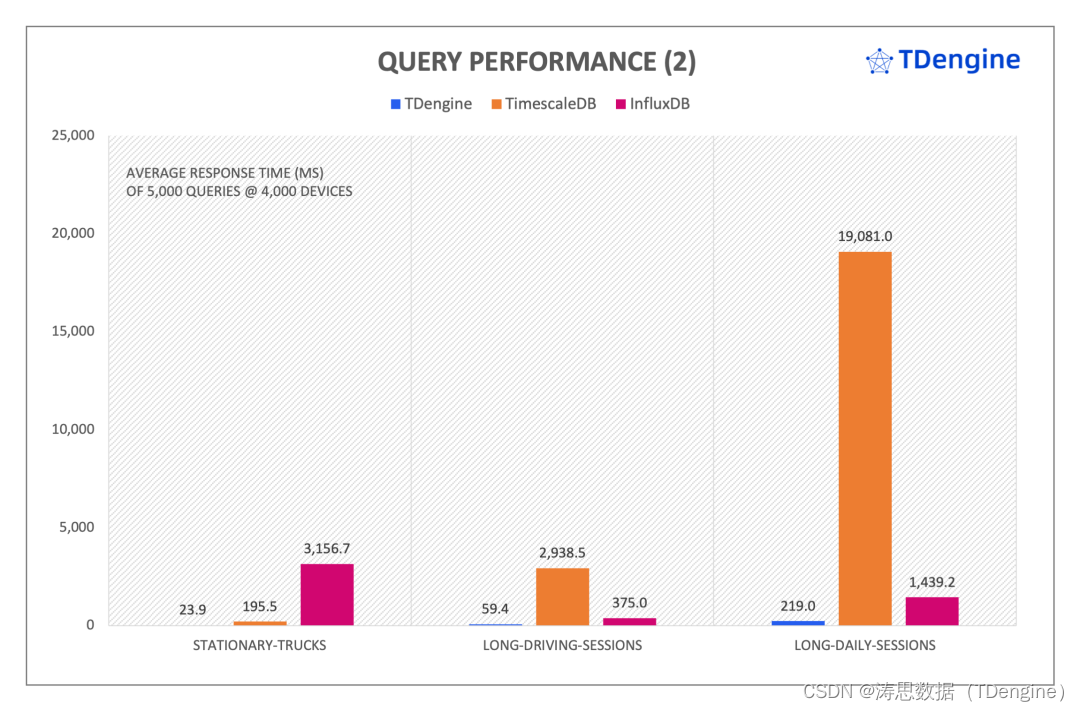
4000 devices Aggregates 查询响应时间 (数值越小越好)
在复杂分组聚合的查询中,我们看到 TDengine 查询性能相比于 TimescaleDB 和 InfluxDB 有非常大的优势;而在时间窗口聚合的查询过程中,针对规模较大的数据集,TimescaleDB 查询性能不佳——long-driving-sessions 和 long-daily-sessions 均表现很差。TDengine 在 stationary-trucks 查询性能是 InfluxDB 的 132 倍,是 TimescaleDB 的 8 倍;在 long-daily-sessions 中是 TimescaleDB 的 87 倍,是 InfluxDB 的 6.5 倍。

4000 devices Double rollups 查询响应时间 (数值越小越好)
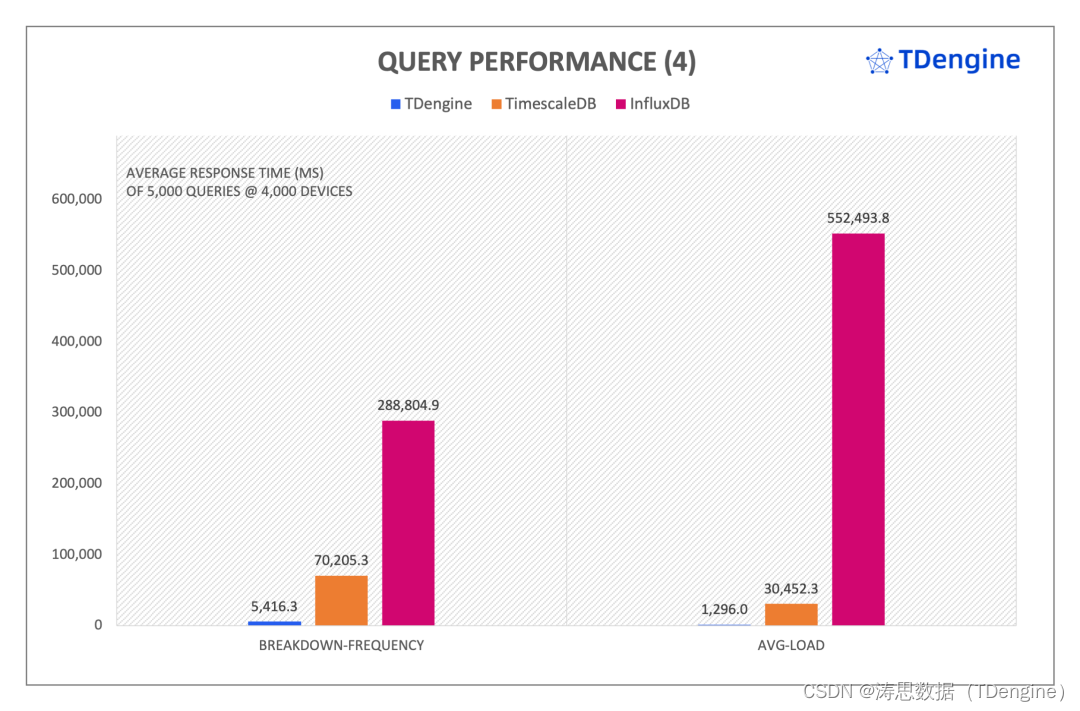 4000 devices 查询响应时间 (数值越小越好)
4000 devices 查询响应时间 (数值越小越好)
在复杂的混合查询中, TDengine 展现出巨大的性能优势,按查询响应时间来度量,在 avg-load 和 breakdown-frequency 的查询中,TDengine 性能是 InfluxDB 的 426 倍和 53 倍 ;对比 TimescaleDB,在 daily-activity 查询中,TDengine 是其 34 倍,在 avg-load 查询中,TDengine 是其 23 倍。
资源开销对比
由于部分查询持续时间特别短,因此并不能完整地看到查询过程中服务器的 IO/CPU/网络情况。为此,我们针对场景二,以 daily-activity 查询为例,执行 50 次查询,记录三个软件系统在查询执行的整个过程中服务器 CPU、内存、网络的开销并进行对比。
服务器 CPU 开销
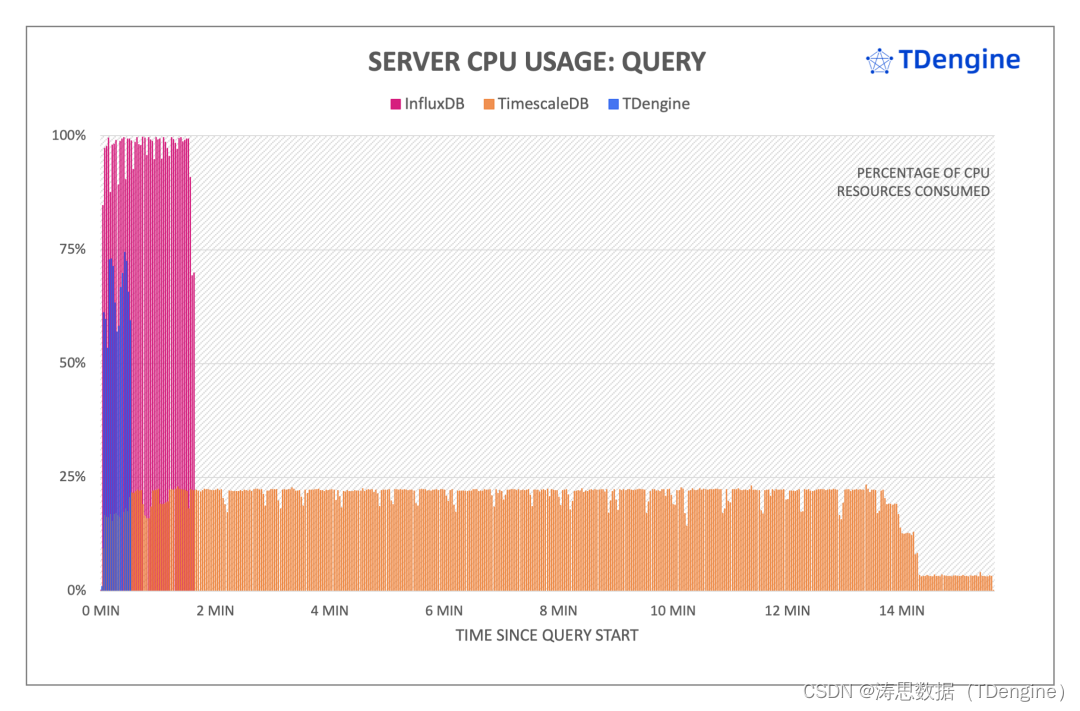 查询过程中服务器 CPU 开销
查询过程中服务器 CPU 开销
从上图可以看到,三个系统在整个查询过程中 CPU 的使用均较为平稳。TDengine 在查询过程中整体 CPU 占用约 为 70%,TimescaleDB 在查询过程中瞬时 CPU 最低,约为 22%,InfluxDB 的稳定阶段 CPU 占用最大,约 98 %(有较多的瞬时100%)。从整体 CPU 开销上来看,虽然 TimescaleDB 瞬时 CPU 开销最低,但是其完成查询持续时间最长,所以整体 CPU 资源消耗最多;InfluxDB 基本顶格 100% 使用全部 CPU,持续时间是 TDengine 的三倍,开销次之。TDengine 完成全部查询的时间仅是 TimescaleDB 的 1/30,整体 CPU 开销最低。
服务器内存状况
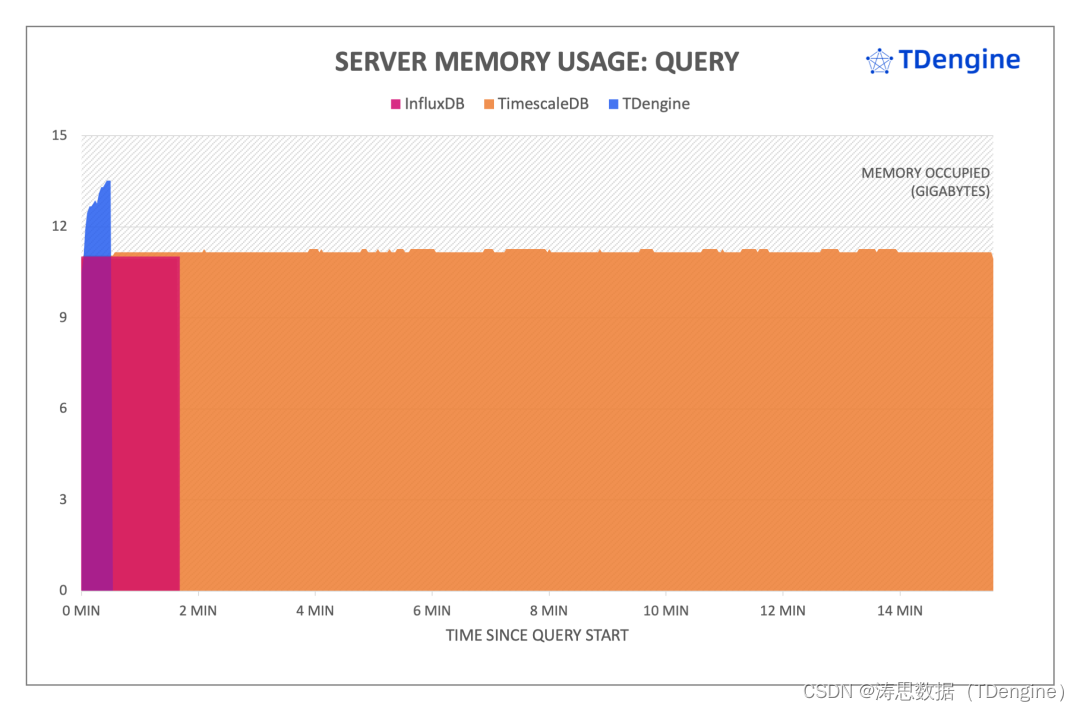 查询过程中服务器内存情况
查询过程中服务器内存情况
如上图所示,在整个查询过程中,TDengine 内存维持了一个相对平稳的状态,平均使用约为 12GB;TimescaleDB 和 InfluxDB 内存占用在整个查询过程中均保持平稳,平均约为 10GB;其中 TimescaleDB 对 buffer 和 cache 使用比较多。
服务器网络带宽
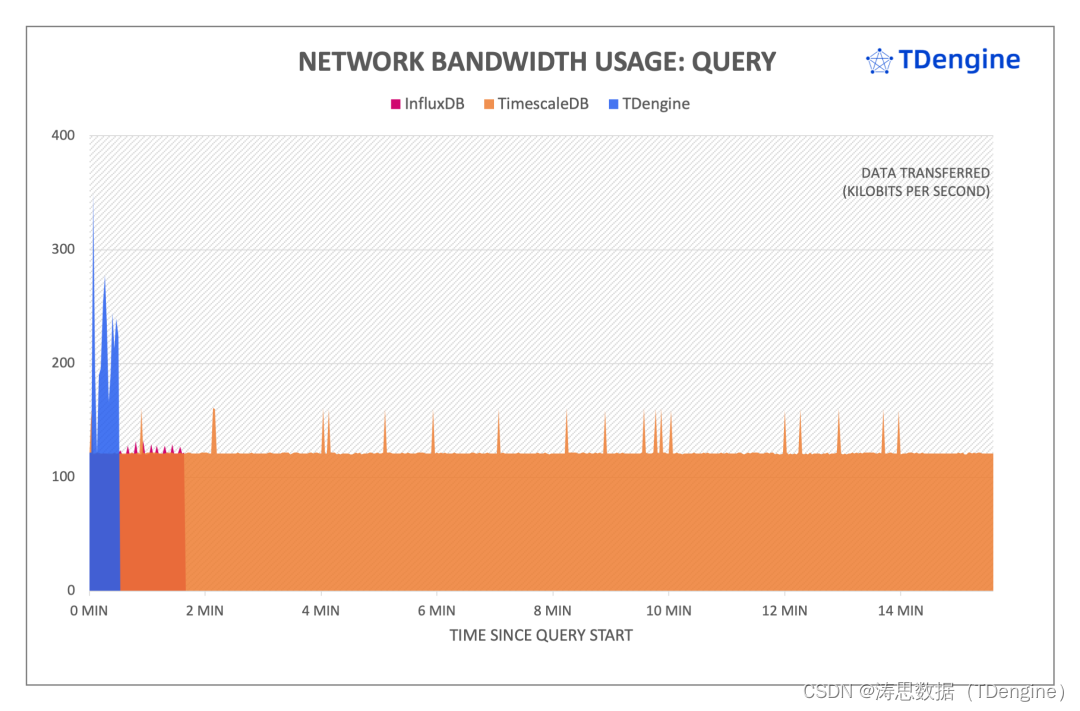 查询过程中网络占用情况
查询过程中网络占用情况
上图展示了查询过程中三大系统服务器端上行和下行的网络带宽情况,负载状况基本上和 CPU 状况相似——TDengine 网络带宽开销最高,因为在最短的时间内就完成了全部查询,需要将查询结果返回给客户端;InfluxDB 和 TimescaleDB 网络带宽大致相同。
100 devices × 10 metrics 查询性能对比
对于场景一(100 devices x 10 metrics),TSBS 的 15 个查询对比结果如下:
| 查询类型 | TDengine | InfluxDB | InfluxDB/TDengine | TimescaleDB | TimescaleDB/TDengine |
| last-loc | 1.03 | 14.94 | 1450.49% | 1.35 | 131.07% |
| low-fuel | 4.61 | 17.45 | 378.52% | 6.74 | 146.20% |
| high-load | 1.03 | 18.33 | 1779.61% | 1.31 | 127.18% |
| stationary-trucks | 3.59 | 69.1 | 1924.79% | 4.02 | 111.98% |
| long-driving-sessions | 5.4 | 13 | 240.74% | 61.87 | 1145.74% |
| long-daily-sessions | 13.88 | 42.91 | 309.15% | 228.38 | 1645.39% |
| avg-vs-projected-fuel-consumption | 267.03 | 1033.72 | 387.12% | 830.79 | 311.12% |
| avg-daily-driving-duration | 278.62 | 942.47 | 338.26% | 1049.07 | 376.52% |
| avg-daily-driving-session | 166.49 | 1707.27 | 1025.45% | 1066.69 | 640.69% |
| avg-load | 102.31 | 15956.73 | 15596.45% | 487.39 | 476.39% |
| daily-activity | 146.5 | 510.3 | 348.33% | 1245.05 | 849.86% |
| breakdown-frequency | 413.82 | 6953.83 | 1680.40% | 955.2 | 230.82% |
如上表所示,从更小规模的数据集(场景一)上的查询对比可以看到,整体上 TDengine 同样展现出极好的性能,在全部的查询语句中全面优于 TimescaleDB 和 InfluxDB,部分查询性能超过 TimescaleDB 16 倍,超过 InfluxDB 155 倍。
写在最后
基于上文可以做出总结,查询方面整体来讲,在场景一(只包含 4 天的数据)与场景二的 15 个不同类型的查询中,TDengine 的查询平均响应时间全面优于 InfluxDB 和 TimescaleDB,在复杂查询上优势更为明显,同时具有最小的计算资源开销。相对于 InfluxDB,场景一中 TDengine 查询性能是其 2.4 ~ 155.9 倍,场景二中 TDengine 查询性能是其 6.3 ~ 426.3 倍;相对于 TimescaleDB,场景一中 TDengine 查询性能是其 1.1 ~ 16.4 倍,场景二中 TDengine 查询性能是其 1.02 ~ 87 倍。
同样地,TDengine 3.0 高效的查询性能也在企业实践中得到了验证,在《老朋友,新版本:中移物联的 TDengine 3.0 全新体验》一文中可以看到,从 2.0 到 3.0,TDengine 读取数据性能依旧很突出,面对中移物联网场景最常用的单设备单日查询,3.0 可以在 0.1s 内返回结果。如果你也面临着数据处理难题或想要进行数据架构升级,欢迎添加小T vx:tdengine1,加入 TDengine 用户交流群,和更多志同道合的开发者一起攻克难关。