目录
一、介绍
二、使用方法
1.推理
2.训练
三、MPRNet结构
1.整体结构
2.CAB(Channel Attention Block)
3.Stage1 Encoder
4.Stage2 Encoder
5.Decoder
6.SAM(Supervised Attention Module)
7.ORSNet(Original Resolution Subnetwork)
四、损失函数
1.CharbonnierLoss
2.EdgeLoss
一、介绍
论文地址:https://arxiv.org/pdf/2102.02808.pdf
代码地址:http://github.com/swz30/MPRNet
恢复图像任务,需要在空间细节和高级上下文特征之间取得复杂的平衡。于是作者设计了一个多阶段的模型,模型首先使用编解码器架构来学习上下文的特征,然后将它们与保留局部信息的高分辨率分支结合起来。
打个比方,我要修复一张蛇的图片,编解码器负责提取高级上下文特征,告诉模型要在蛇身上“画”鳞片,而不是羽毛或其他东西;然后高分辨率分支负责细化鳞片的图案。
MPRNet细节很多,但最主要的创新还是“多阶段”,模型共有三个阶段,前两个阶段是编解码器子网络,用来学习较大感受野的上下文特征,最后一个阶段是高分辨率分支,用于在最终的输出图像中构建所需的纹理。作者给出了Deblurring、Denoising、Deraining三个任务的项目,三个项目的backbone是一样的,只是参数规模有所不同(Deblurring>Denoising>Deraining),下面我们以最大的Deblurring为例进行介绍。
二、使用方法
MPRNet项目分为Deblurring、Denoising和Deraining 三个子项目。作者没有用稀奇古怪的库,也没用高级的编程技巧,非常适合拿来研究学习,使用方法也很简单,几句话技能说完。
1.推理
(1)下载预训练模型:预训练模型分别存在三个子项目的pretrained_models文件夹,下载地址在每个pretrained_models文件夹的 README.md中,需要科学上网,我放在了网盘里:
链接:https://pan.baidu.com/s/1sxfidMvlU_pIeO5zD1tKZg 提取码:faye
(2)准备测试图片:将退化图片放在目录samples/input/中
(3)执行demo.py
# 执行Deblurring
python demo.py --task Deblurring
# 执行Denoising
python demo.py --task Denoising
# 执行Deraining
python demo.py --task Deraining(4)结果放在目录samples/output/中。
2.训练
(1)根据Dataset文件夹内的README.md文件中的地址下载数据集。
(2)查看training.yml是否需要修改,主要是最后的数据集地址。
(3)执行训练
python train.py三、MPRNet结构
我将按照官方代码实现来介绍模型结构,一些重要模块的划分可能跟论文有区别,但是整体结构是一样的。
1.整体结构
MPRNet官方给出的结构图如下:
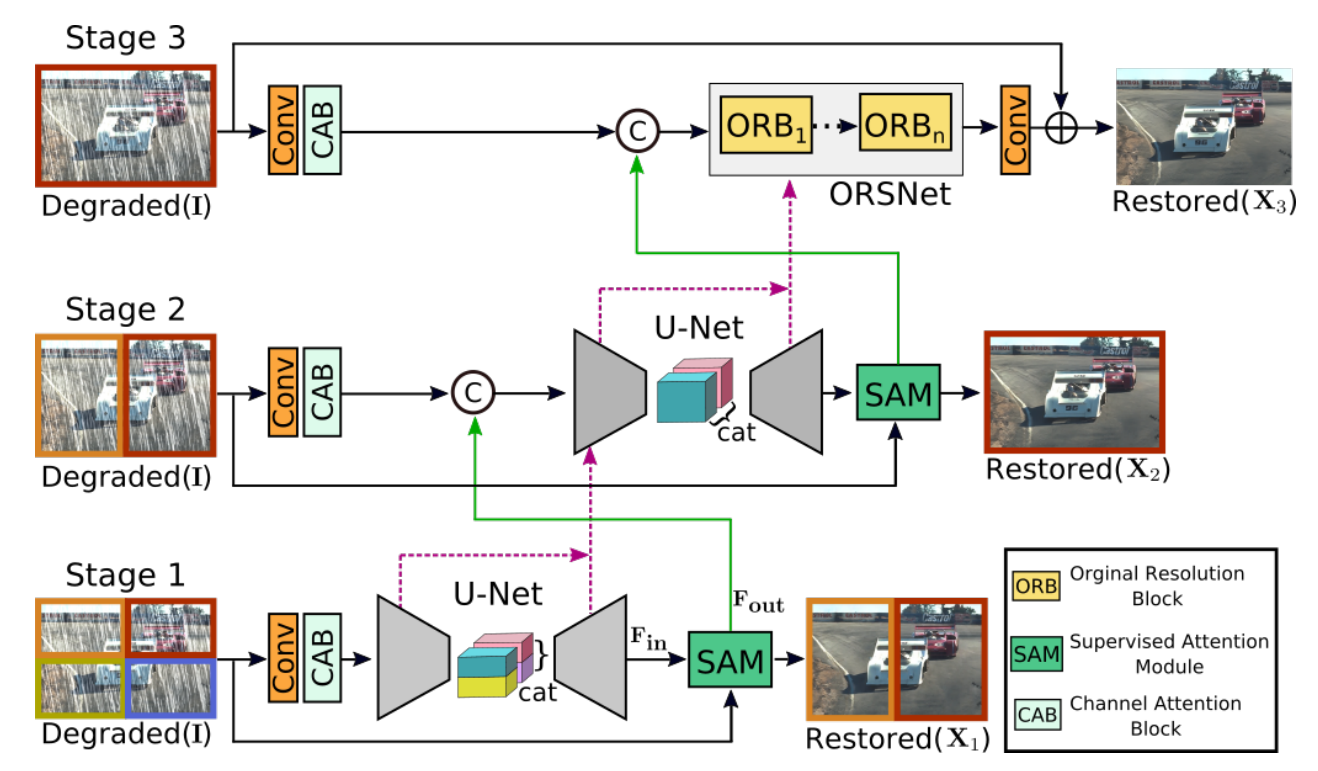
图1
这个图总体概括了MPRNet的结构,但是很多细节没有表现出来,通过阅读代码我给出更加详细的模型结构介绍。下面的图中输入统一512x512,我们以Deblurring为例,并且batch_size=1。
整体结构图如下:
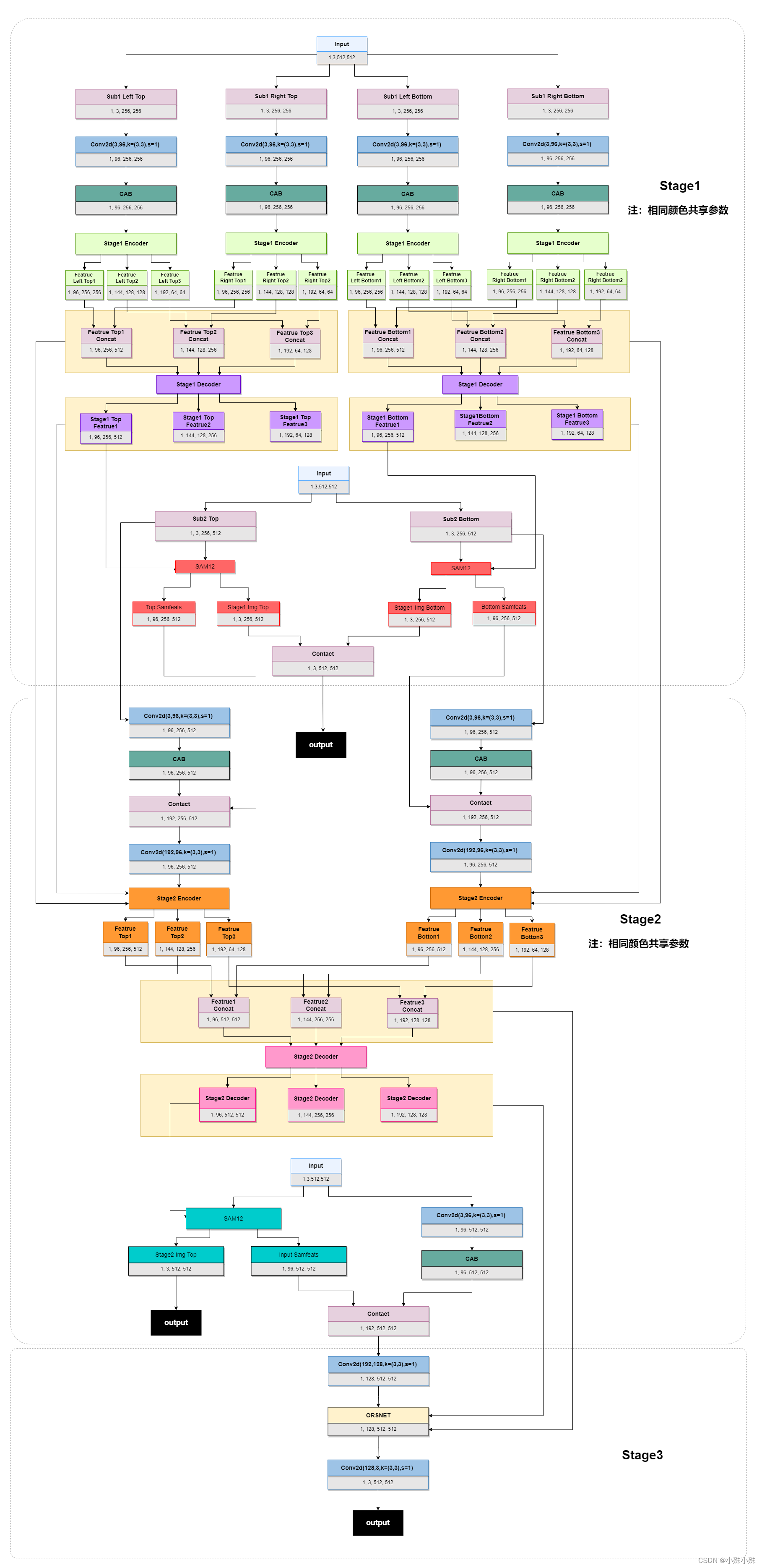
图2
图中的三个Input都是原图,整个模型三个阶段,整体流程如下:
1.1 输入图片采用multi-patch方式分成四份,分成左上、右上、左下、右下;
1.2 每个patch经过一个3x3的卷积扩充维度,为的是后面能提取更丰富的特征信息;
1.3 经过CAB(Channel Attention Block),利用注意力机制提取每个维度上的特征;
1.4 Encoder,编码三种尺度的图像特征,提取多尺度上下文特征,同时也是提取更深层的语义特征;
1.5 合并深特征,将四个batch的同尺度特征合并成左右两个尺度,送入Decoder;
1.6 Decoder,提取合并后的每个尺度的特征;
1.7 输入图片采用multi-patch方式分成两份,分成左、右;
1.8 将左右两个batch分别与Stage1 Decoder输出的大尺度特征图送入SAM(Supervised Attention Module),SAM在训练的时候可以利用GT为当前阶段的恢复过程提供有用的控制信号;
1.9 SAM的输出分成两部分,一部分是第二次输入的原图特征,它将继续下面的流程;一部分用于训练时的Stage1输出,可以利用GT更快更好的让模型收敛。
2.0 经过Stage2的卷积扩充通道和CAB操作,将Stage1中的Decoder前后的特征送入Stage2的Encoder。
2.2 经过和Stage1相似的Decoder,也产生两个部分的输出,一部分继续Stage3,一部分输出与GT算损失;
3.1 Stage3的原图输入不在切分,目的是利用完整的上下文信息恢复图片细节。
3.2 将原图经过卷积做升维处理;
3.3 将Stage2中的Decoder前后的特征送入Stage3的ORSNet(Original Resolution Subnetwork),ORSNet不使用任何降采样操作,并生成空间丰富的高分辨率特征。
3.4 最后经过一个卷积将维度降为3,输出。
图中还有一些模块细节没有表现出来,下面我将详细介绍。
2.CAB(Channel Attention Block)
顾名思义,CAB就是利用注意力机制提取每个通道的特征,输出输入特征图形状不变,结构图如下:
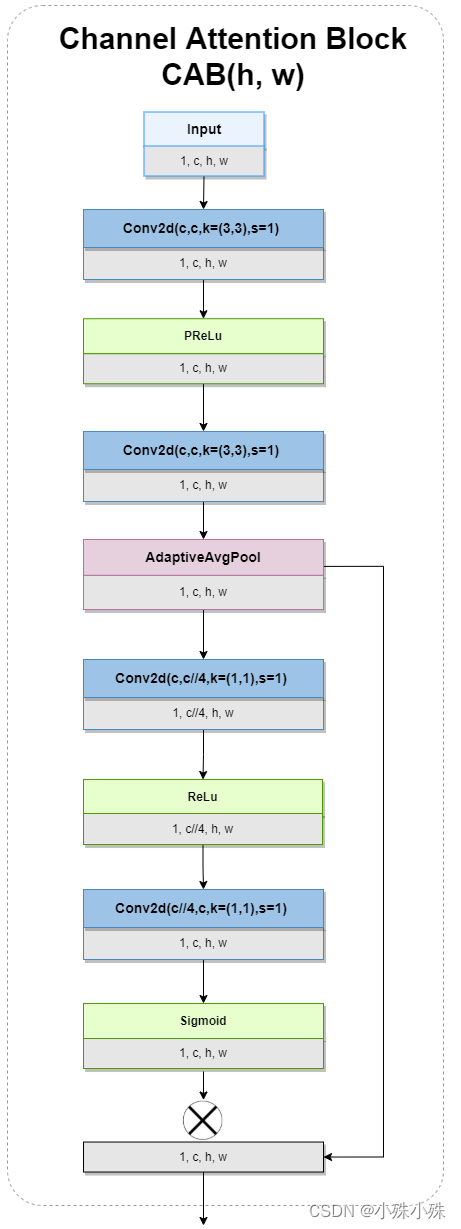
图3
可以看到,经过了两个卷积和GAP之后得到了一个概率图(就是那个残差边),在经过两个卷积和Sigmoid之后与概率图相乘,就实现了一个通道注意力机制。
3.Stage1 Encoder
Stage1和Stage1的Encoder有一些区别,所以分开介绍。Stage1 Encoder有一个输入和三个不同尺度的输出,为的是提取三个尺度的特征并为下面的尺度融合流程做准备;其中有多个CAB结构,可以更好的提取通道特征;下采样通过粗暴的Downsample实现,结构如下:
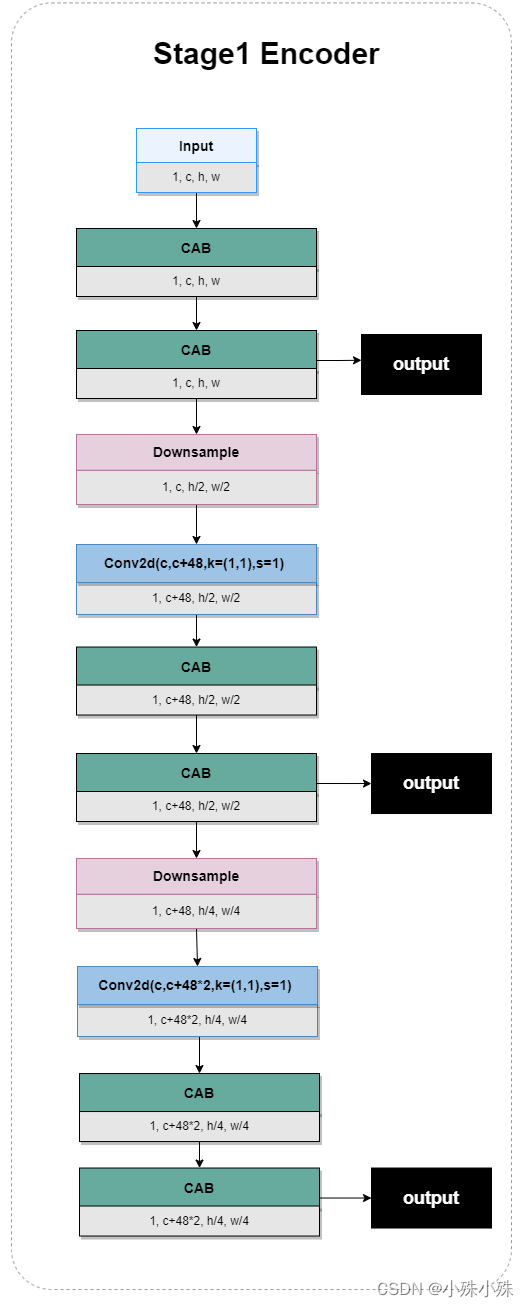
图4
4.Stage2 Encoder
Stage2 Encoder输入为三个,分别为上一层的输出和Stage1中的Decoder前后的特征。主流程(也就是左面竖着的那一列)和Stage1 Encoder是一样的。增加的两个输入,每个输入又分为三个尺度,每个尺度经过一个卷积层,然后相同尺度的特征图做特征融合,输出,结构如下:
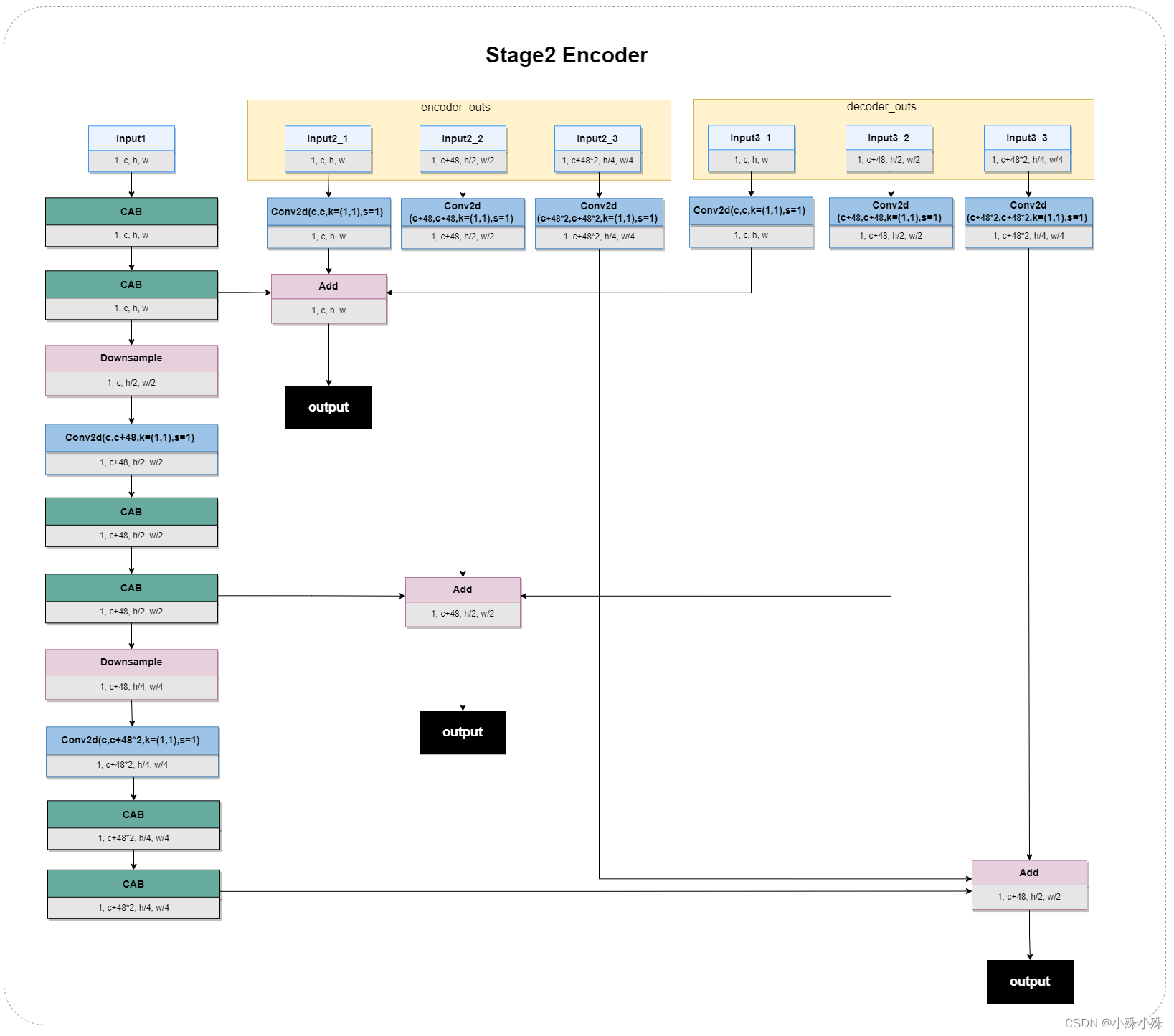
图5
5.Decoder
两个阶段的Decoder结构是一样的,所以放在一起说,有三个不用尺度的输入;通过CAB提取特征;小尺度特征通过上采样变大,通过卷积使通道变小;小尺度的特征图shape最终变成跟大尺度一样,通过残差边实现特征融合,结构如下:
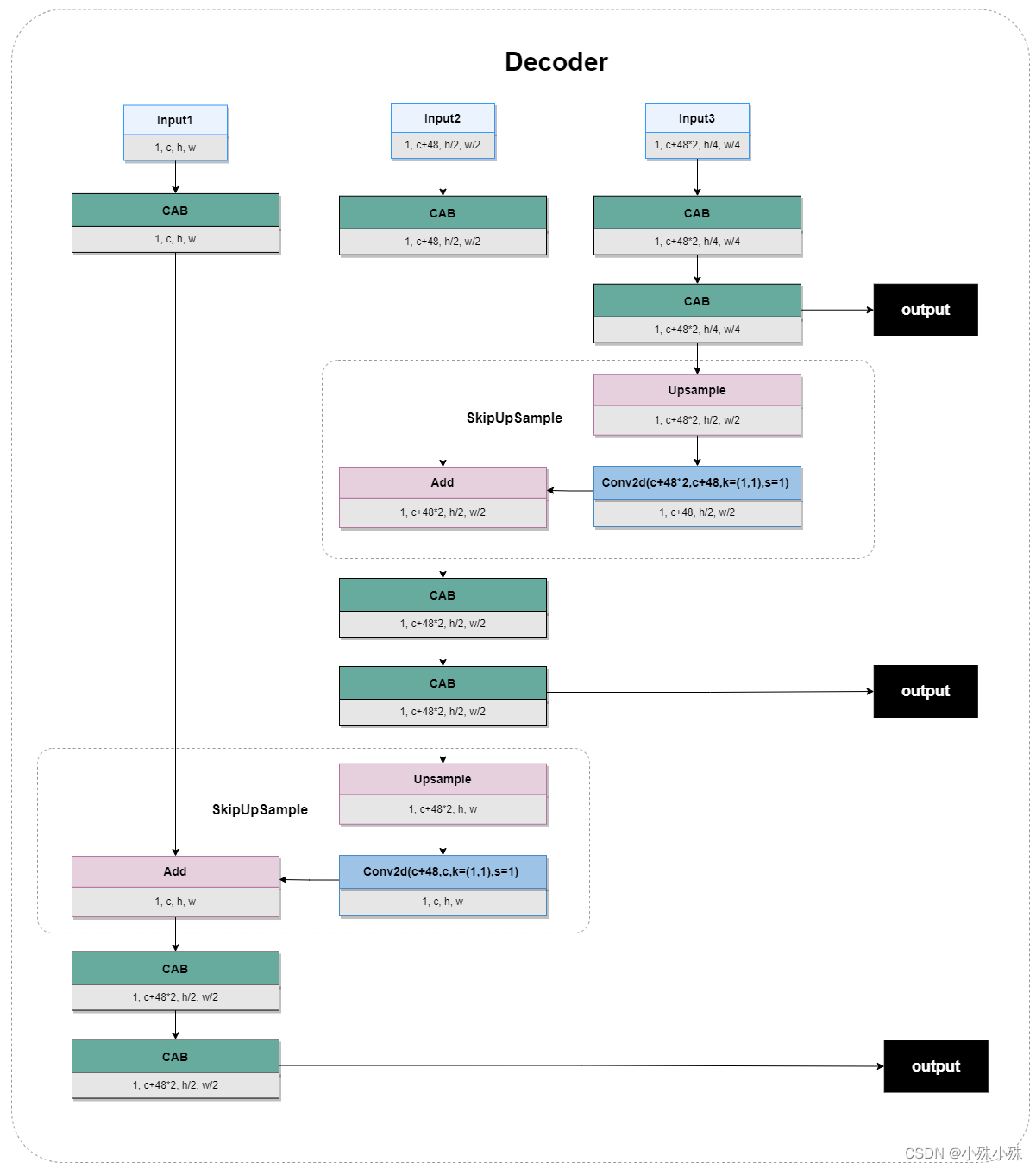
图6
6.SAM(Supervised Attention Module)
SAM出现在两个阶段间,有两个输入,将上一层特征和原图作为输入,提升了特征提取的性能,,SAM作为有监督的注意模块,使用注意力图强力筛选了跨阶段间的有用特征。有两个输出,一个是经过了注意力机制的特征图,为下面的流程提供特征;一个是3通道的图片特征,为了训练阶段输出,结构如下:
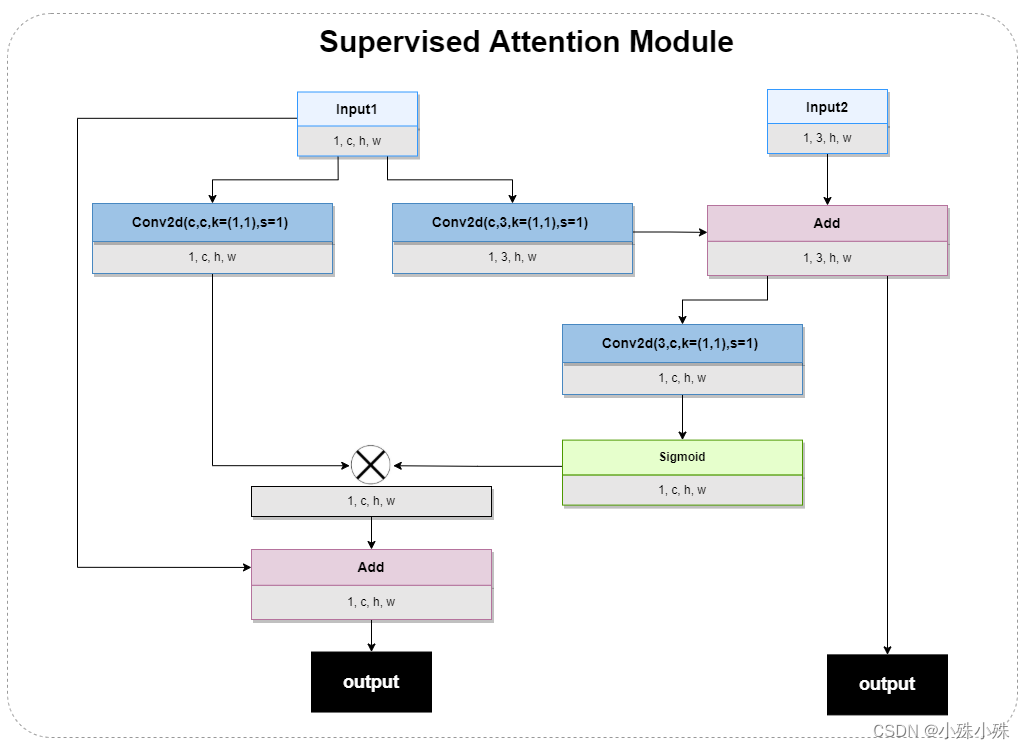
图7
7.ORSNet(Original Resolution Subnetwork)
为了保留输入图像的细节,模型在最后一阶段引入了原始分辨率的子网(ORSNet:Original Resolution Subnetwork)。ORSNet不使用任何降采样操作,并生成空间丰富的高分辨率特征。它由多个原始分辨率块(BRB)组成,是模型的最后阶段,结构如下:

图8
可以看到,输入为三个,分别为上一层的输出和Stage2中的Decoder前后的特征。后两个输入,每个输入又分为三个尺度,三个尺度的通道数都先变成96,然后在变成128;小尺度的size都变成和大尺度一样,最后做特征融合融合前会经过ORB(Original Resolution Block)模块。
ORB由一连串的CAB组成,还有一个大的残差边,结构如下:

图9
四、损失函数
MPRNet主要使用了两个损失函数CharbonnierLoss和EdgeLoss,公式如下:
其中累加是因为训练的时候三个阶段都有输出,都需要个GT计算损失(如图2的三个output);该模型不是直接预测恢复的图像,而是预测残差图像
,添加退化的输入图像
得到:
Deblurring和Deraining两个任务CharbonnierLoss和EdgeLoss做了加权求和,比例1:0.05;只使用了CharbonnierLoss,我感觉是因为这里使用的噪声是某种分布(入高斯分布、泊松分布)的噪声,不会引起剧烈的边缘差异,所以Denoising没有使用EdgeLoss。
下面简单介绍一下两种损失。
1.CharbonnierLoss
公式如下:
CharbonnierLoss在零点附近由于常数的存在,梯度不会变成零,避免梯度消失。函数曲线近似L1损失,相比L2损失而言,对异常值不敏感,避免过分放大误差。
2.EdgeLoss
L1或者L2损失注重的是全局,没有很好地考虑一些显著特征的影响, 而显著的结构和纹理信息与人的主观感知效果高度相关,是不能忽视的。
边缘损失主要考虑纹理部分的差异,可以很好地考虑高频的纹理结构信息, 提高生成图像的细节表现,公示如下:
其中表示Laplacian边缘检测中的核函数,
表示对
做边缘检测,公式中其他部分和CharbonnierLoss类似。
MPRNet的主要的内容就介绍到这,主要是backbone的创新,其他部分中规中矩,关注不迷路。
![[LINUX]之grep文本过滤](https://img-blog.csdnimg.cn/2d2aa1c719d24763ad74f4840e66c15c.png)