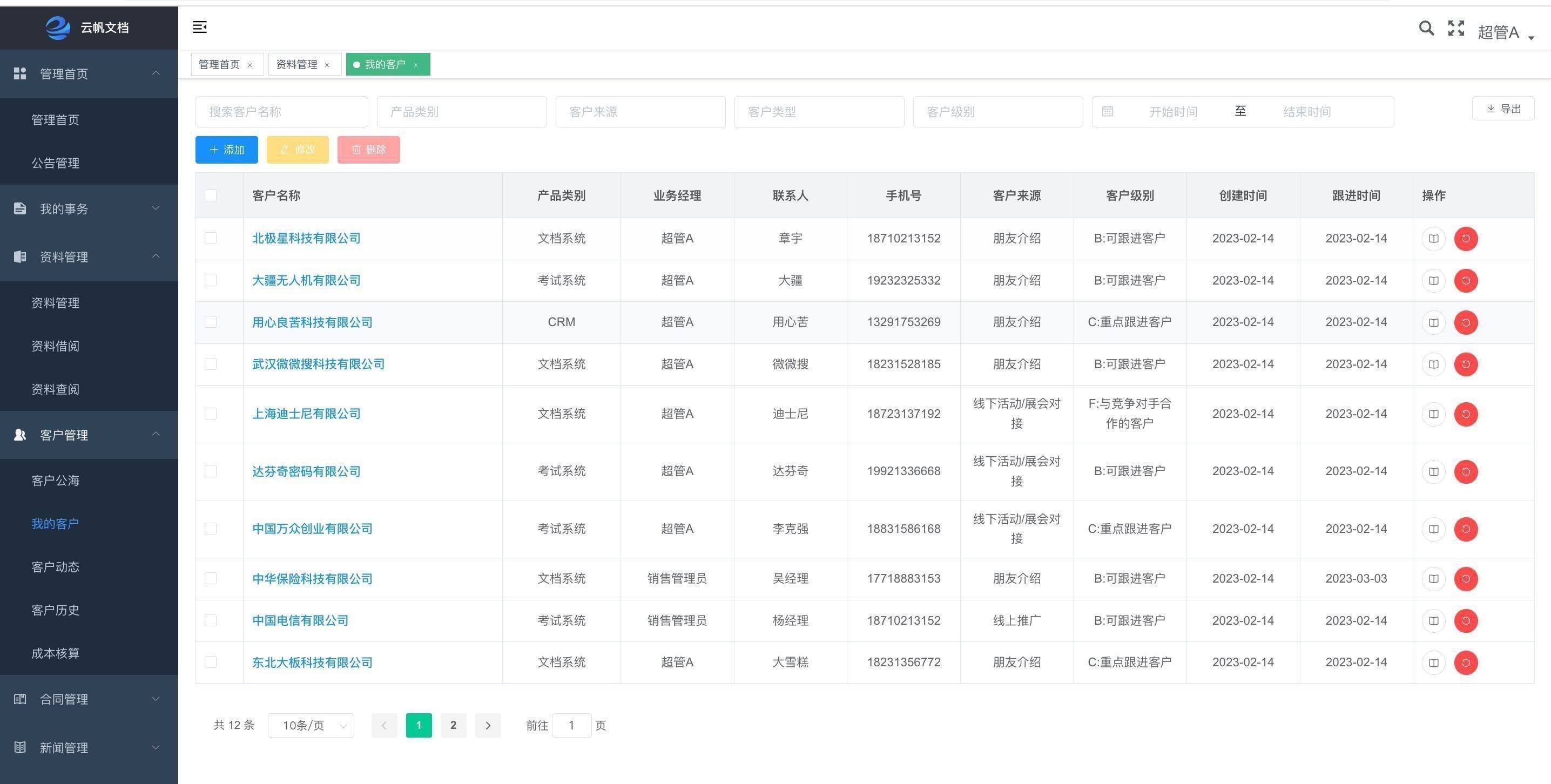
- 1、通过 f12 查看网页相关信息
- ① 搜索“python”相关岗位,想爬取下来作为分析,但是看到html源码为特殊字符,而不是页面上直观能看到的文字信息
- ②点击对应的css样式查看css源码,通过源码解析字体加密过程
- 2、通过 Domain+URI 获取到该字体文件
- ① 这里没有后缀,我们只能去试是那一种格式的
- ② 直至试出来文件格式为woff
- 3、检验字体文件对应关系是否正确
- 4、使用 python 进行字体映射
- ① 将woff转换为xml查看逻辑
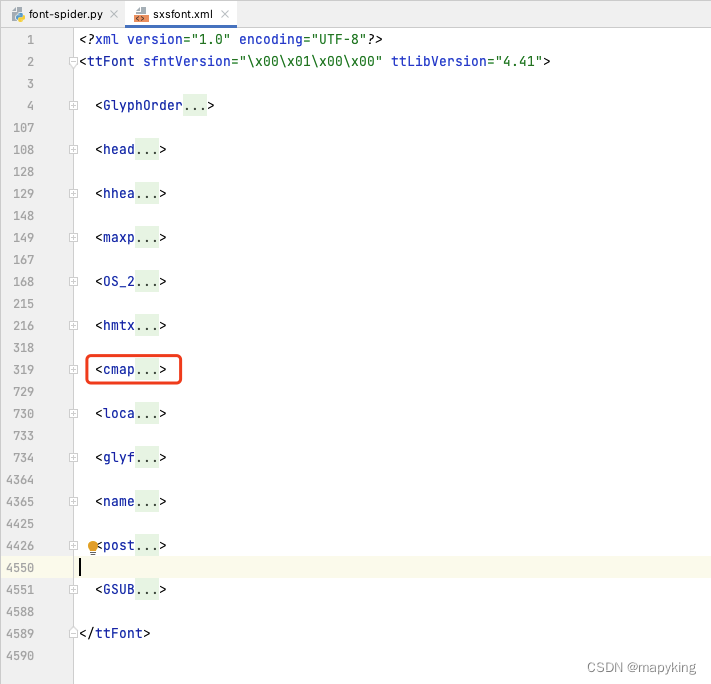
- ② 主要观察\<cmap>里的对应关系
- ③ 使用字典完成映射关系
- 5、根据映射对网页源码进行对应替换
这里以实习僧为具体案例
1、通过 f12 查看网页相关信息
① 搜索“python”相关岗位,想爬取下来作为分析,但是看到html源码为特殊字符,而不是页面上直观能看到的文字信息

关闭对应的css样式可以看到,确实是做了字体反爬

②点击对应的css样式查看css源码,通过源码解析字体加密过程


查看 font-family 是由 myFont 传值生成,继续找 myFont 变量

2、通过 Domain+URI 获取到该字体文件
https://www.shixiseng.com/interns/iconfonts/file?rand=0.5135261623696619
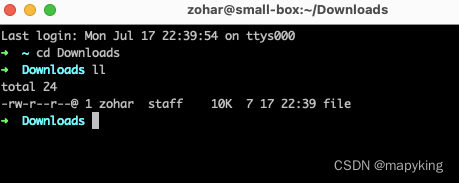
① 这里没有后缀,我们只能去试是那一种格式的
一般常见的为:ttf、eot、otf、woff、svg,可以使用在线工具去检验
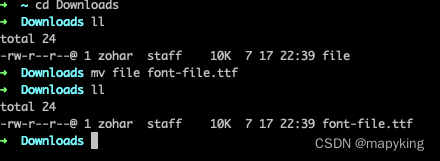
② 直至试出来文件格式为woff
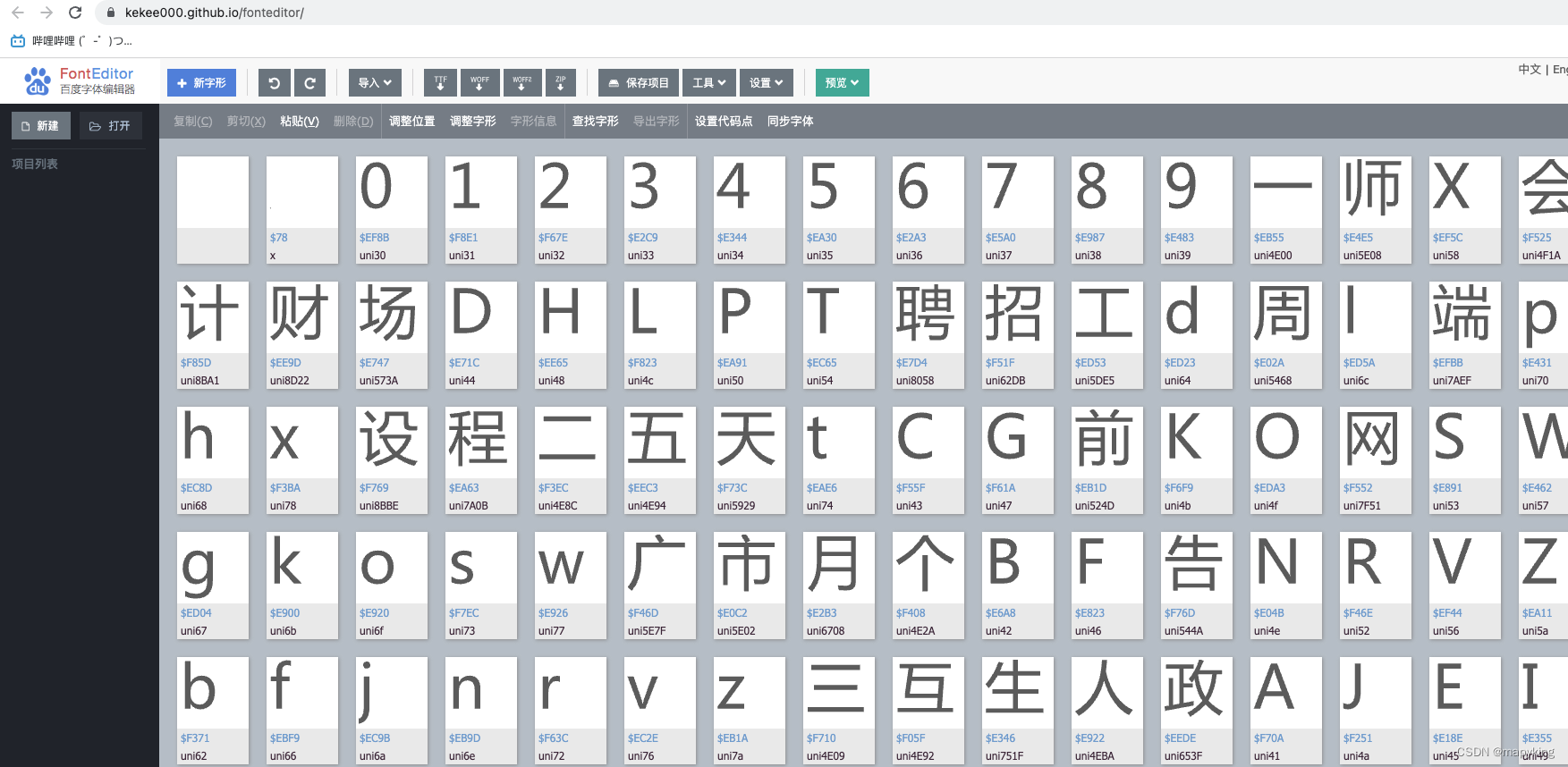
3、检验字体文件对应关系是否正确
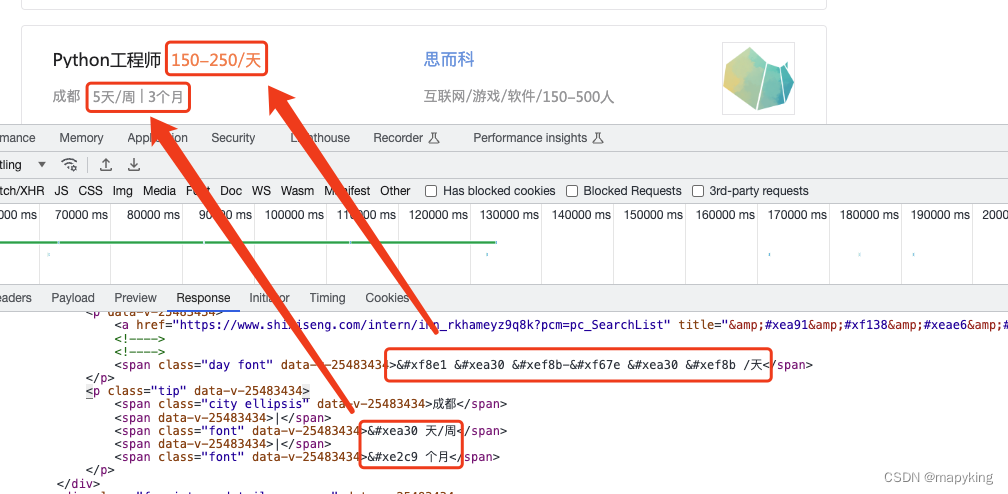
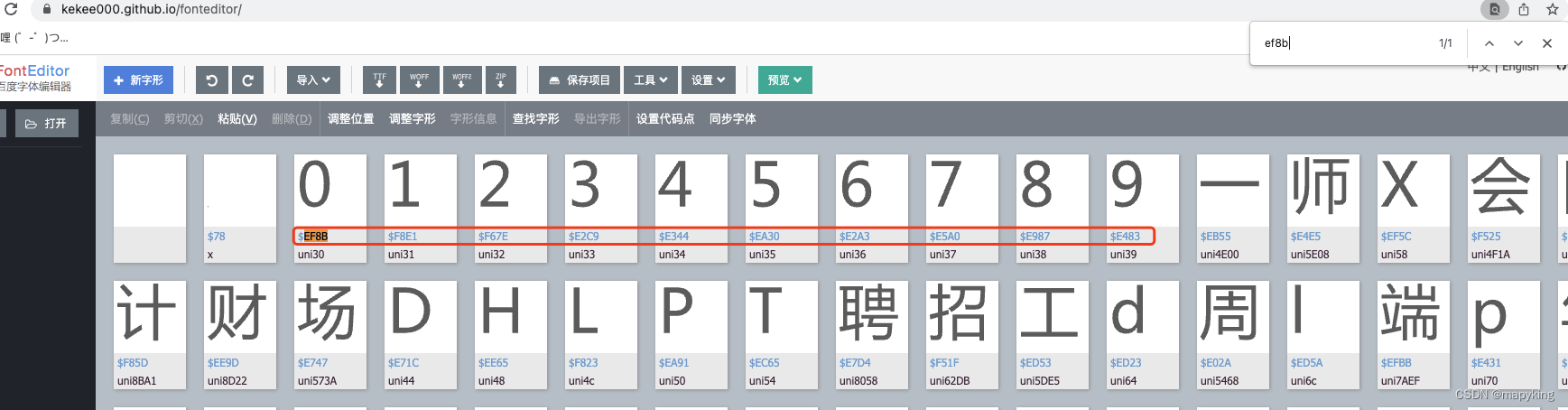
这里判断正确无误,底层通过css转换就是这个文件的文字
4、使用 python 进行字体映射
pip3 install fontTools
① 将woff转换为xml查看逻辑
from fontTools.ttLib import TTFont
font = TTFont('./font-file.woff')
font.saveXML('sxsfont.xml')
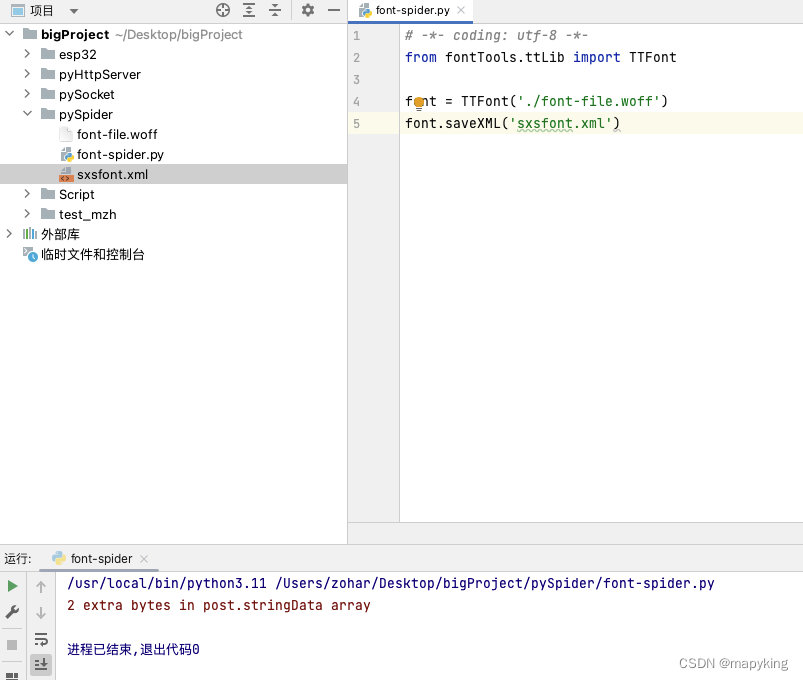
② 主要观察<cmap>里的对应关系
例如 这里python工程师

网页显示:  
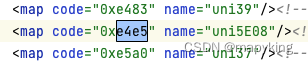
xml中的code值:0xed53 0xea63 0xe4e5
xml中的name值:uni5DE5 uni7A0B uni5E08
通过观察可以得出:网页显示后四位与xml中的code值后四位一样,对应的name值看起来也是unicode编码,也是拿后四位去验证

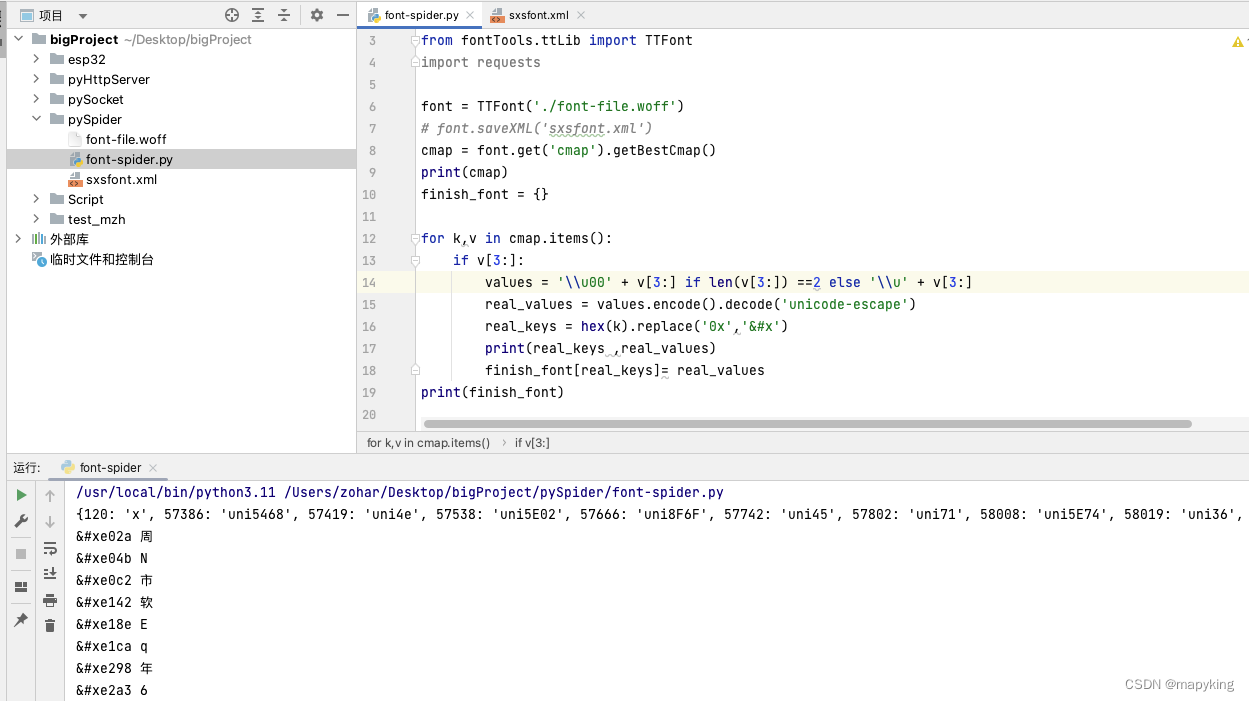
③ 使用字典完成映射关系
from fontTools.ttLib import TTFont
font = TTFont('./font-file.woff')
cmap = font.get('cmap').getBestCmap()
print(cmap)
finish_font = {}
for k,v in cmap.items():
if v[3:]:
values = '\\u00' + v[3:] if len(v[3:]) ==2 else '\\u' + v[3:]
real_values = values.encode().decode('unicode-escape')
real_keys = hex(k).replace('0x','&#x')
print(real_keys ,real_values)
finish_font[real_keys]= real_values
print(finish_font)
5、根据映射对网页源码进行对应替换
for k, v in finish_font.items():
html_text = html_text.replace(k, v)