1. case class学习
样例类模式匹配
1.1 样例类(case class)适合用于不可变的数据。它是一种特殊的类,能够被优化以用于模式匹配。
case class MetaData(userId: String) case class Book(name: String) { def printBookName(): Unit = { println(name) } } object BookTest { def main(args: Array[String]): Unit = { val book = Book("Java入门到放弃") book.printBookName() } }
在实例化case class类时,不需要使用关键字New,case class类编译成class文件之后会自动生成apply方法,这个方法负责对象的创建。
1.2 模式匹配
一个模式匹配语句包括一个待匹配的值,match关键字,以及至少一个case语句。示例如下:
def matchTest(x: Int): String = x match { case 1 => "one" case 2 => "two" case _ => "many" }
1.3 case class的匹配
abstract class Notification # 抽象类,虚基类,父类 case class Email(sender: String, title: String, body: String) extends Notification case class SMS(caller: String, message: String) extends Notification case class VoiceRecording(contactName: String, link: String) extends Notification
Notification 是一个虚基类,它有三个具体的子类Email, SMS和VoiceRecording,我们可以在这些Case Class类上使用模式匹配:
def showNotification(notification: Notification): String = { notification match { case Email(email, title, _) => s"You got an email from $email with title: $title" case SMS(number, message) => s"You got an SMS from $number! Message: $message" case VoiceRecording(name, link) => s"you received a Voice Recording from $name! Link: $link" } } val someSms = SMS("12345", "Are you there?") val someVoiceRecording = VoiceRecording("Tom", "voicerecording.org/id/123") println(showNotification(someSms)) // prints You got an SMS from 12345! Message: Are you there? println(showNotification(someVoiceRecording)) // you received a Voice Recording from Tom! Click the link to hear it: voicerecording.org/id/123
2. 类转json
scala自带的Json解析工具,简单使用,参考Scala json字符串和json对象互相转换
import org.json4s.jackson.{JsonMethods, Serialization} case class User(name: String, age: Int) object Json4STest { def main(args: Array[String]): Unit = { //数据格式:user:{"name": "zs","age": 10} val json = "{\"name\": \"zs\",\"age\": 10}" //导隐式函数 implicit val f = org.json4s.DefaultFormats /** ************************* json字符串->对象 ***************************************/ val user: User = JsonMethods.parse(json).extract[User] println(user) /** ************************* 对象->json字符串 ***************************************/ val userJStr: String = Serialization.write(user) println(userJStr) } }
3. Array 和 List
val listTest = List(1,2,3,4) val arrayTest = Array(1, 2, 3, 4) //正确 for (i <- arrayTest.indices){ println(arrayTest(i)) } scala> 1 until 10 by 3 res17: scala.collection.immutable.Range = Range(1, 4, 7) scala> 1 to 10 by 3 res18: scala.collection.immutable.Range = Range(1, 4, 7, 10) scala> arrayTest.indices res19: scala.collection.immutable.Range = Range(0, 1, 2, 3)
4. Scala常用函数式编程
4.1 map
- map方法可以将某个函数应用到集合中的每个元素并产出其结果的集合,比如
scala> val names = List("a", "b", "c")
names: List[String] = List(a, b, c)
scala> names.map(_.toUpperCase)
res1: List[String] = List(A, B, C)
4.2 foreach
- foreach和map相似,只不过它没有返回值,foreach只要是为了对参数进行作用。
scala> names.foreach{name => println(name)}
a
b
c
4.3 flatten
- flatten可以把嵌套的结构展开.
scala> List(List(1,2), List(3,4)).flatten
res3: List[Int] = List(1, 2, 3, 4)
4.4 flatmap
- flatMap结合了map和flatten的功能。接收一个可以处理嵌套列表的函数,然后把返回结果连接起来。
scala> List(List(1,2), List(3,4)).flatMap(x => x.map(x => x *2))
res4: List[Int] = List(2, 4, 6, 8)
4.5 filter
- 滤除掉使函数返回false的元素
scala> def isEven(i:Int):Boolean = i %2 == 0
isEven: (i: Int)Boolean
scala> List(1,2,3,4,5,6).filter(isEven _)
res5: List[Int] = List(2, 4, 6)
4.6 zip
- zip方法将两个集合结合在一起
scala> List("a","b", "c").zip(List(1,2,3))
res6: List[(String, Int)] = List((a,1), (b,2), (c,3))
4.7 zipWithIndex
- 将元素和下标结合在一起
scala> List(2,3,4,5).zipWithIndex
res8: List[(Int, Int)] = List((2,0), (3,1), (4,2), (5,3))
4.8 sort
函数学习
- 在scala集合中,可以使用以下几种方式来进行排序
- sorted默认排序
- sortBy指定字段排序
- sortWith自定义排序
//定义一个List集合
scala> val list=List(5,1,2,4,3)
list: List[Int] = List(5, 1, 2, 4, 3)
//默认就是升序
scala> list.sorted
res25: List[Int] = List(1, 2, 3, 4, 5)
//定义一个List集合
scala> val list=List("1 hadoop","2 spark","3 flink")
list: List[String] = List(1 hadoop, 2 spark, 3 flink)
//按照单词的首字母进行排序
scala> list.sortBy(x=>x.split(" ")(1))
res33: List[String] = List(3 flink, 1 hadoop, 2 spark)
scala> val list = List(2,3,1,6,4,5)
a: List[Int] = List(2, 3, 1, 6, 4, 5)
//降序
scala> list.sortWith((x,y)=>x>y)
res35: List[Int] = List(6, 5, 4, 3, 2, 1)
//升序
scala> list.sortWith((x,y)=>x<y)
res36: List[Int] = List(1, 2, 3, 4, 5, 6)
4.9 分组 - groupBy
scala> val a = List("张三"->"男", "李四"->"女", "王五"->"男")
a: List[(String, String)] = List((张三,男), (李四,女), (王五,男))
// 按照性别分组
scala> a.groupBy(_._2)
res0: scala.collection.immutable.Map[String,List[(String, String)]] = Map(男 -> List((张三,男), (王五,男)),
女 -> List((李四,女)))
// 将分组后的映射转换为性别/人数元组列表
scala> res0.map(x => x._1 -> x._2.size)
res3: scala.collection.immutable.Map[String,Int] = Map(男 -> 2, 女 -> 1)
4.10 聚合 - reduce
- reduce表示将列表,传入一个函数进行聚合计算
scala> val a = List(1,2,3,4,5,6,7,8,9,10)
a: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> a.reduce((x,y) => x + y)
res5: Int = 55
// 第一个下划线表示第一个参数,就是历史的聚合数据结果
// 第二个下划线表示第二个参数,就是当前要聚合的数据元素
scala> a.reduce(_ + _)
res53: Int = 55
// 与reduce一样,从左往右计算
scala> a.reduceLeft(_ + _)
res0: Int = 55
// 从右往左聚合计算
scala> a.reduceRight(_ + _)
res1: Int = 55
4.11 折叠 - fold
- fold与reduce很像,但是多了一个指定初始值参数
//定义一个List集合
scala> val a = List(1,2,3,4,5,6,7,8,9,10)
a: List[Int] = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
//求和
scala> a.sum
res41: Int = 55
//给定一个初始值,,折叠求和
scala> a.fold(0)(_+_)
res42: Int = 55
scala> a.fold(10)(_+_)
res43: Int = 65
//从左往右
scala> a.foldLeft(10)(_+_)
res44: Int = 65
//从右往左
scala> a.foldRight(10)(_+_)
res45: Int = 65
//fold和foldLet效果一致,表示从左往右计算
//foldRight表示从右往左计算
4.12 高阶函数
- 使用函数值作为参数,或者返回值为函数值的“函数”和“方法”,均称之为“高阶函数”
4.12.1 函数值作为参数
//定义一个数组
scala> val array=Array(1,2,3,4,5)
array: Array[Int] = Array(1, 2, 3, 4, 5)
//定义一个函数
scala> val func=(x:Int)=>x*10
func: Int => Int = <function1>
//函数作为参数传递到方法中
scala> array.map(func)
res0: Array[Int] = Array(10, 20, 30, 40, 50)
4.12.2 匿名函数
//定义一个数组
scala> val array=Array(1,2,3,4,5)
array: Array[Int] = Array(1, 2, 3, 4, 5)
//定义一个没有名称的函数----匿名函数
scala> array.map(x=>x*10)
res1: Array[Int] = Array(10, 20, 30, 40, 50)
5. spark程序
5.1 创建sparkSession
val spark = SparkSession
.builder()
.master("local")
.appName("test")
.config("spark.sql.execution.arrow.enabled", "true")
.getOrCreate()
spark.sql("select 1 as num").show()
- master: 设置运行方式:local代表本机单核运行,**local[4]代表在本机用4核跑,spark://master:7077**是以standalone方式运行;
- appName: 设置spark程序的名字,可以在web UI界面看到;
- config: 附加配置项;
- getOrCreate: 创建一个SparkSession。
5.2 读取和保存本地excel文件
<!--excel依赖--> <dependency> <groupId>com.crealytics</groupId> <artifactId>spark-excel_2.11</artifactId> <version>0.13.1</version> </dependency>
fake_data.xlsx
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iJMKgw32-1689610033377)(C:\Users\86183\AppData\Roaming\Typora\typora-user-images\image-20230109233201179.png)]
读excel,字段取值都是string类型
val dataPath = "C:\\Users\\86183\\Desktop\\教程\\fake_data.xlsx"
//读excel
val df = spark.read.format("com.crealytics.spark.excel")
.option("header", "true").load(dataPath)
df.show(false)
println(df.dtypes.mkString("Array(", ", ", ")"))
val saveDataPath = "C:\\Users\\86183\\Desktop\\教程\\fake_data_1.xlsx"
//写excel
df.coalesce(1).write
.format("com.crealytics.spark.excel")
.option("dataAddress", "A1")
.option("header", "true")
.mode("overwrite")
.save(saveDataPath)
5.3 dataFrame注册hive表
df.createTempView("temp_table")
val sqlString =
"""
|select
|*
|from temp_table
|""".stripMargin
spark.sql(sqlString).show(false)
5.4 聚合函数groupBy用法
5.4.1 基础用法
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions._
object GroupbyExample extends App {
val spark: SparkSession = SparkSession.builder()
.master("local[1]")
.appName("SparkByExamples.com")
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
import spark.implicits._
val simpleData = Seq(("James","Sales","NY",90000,34,10000),
("Michael","Sales","NY",86000,56,20000),
("Robert","Sales","CA",81000,30,23000),
("Maria","Finance","CA",90000,24,23000),
("Raman","Finance","CA",99000,40,24000),
("Scott","Finance","NY",83000,36,19000),
("Jen","Finance","NY",79000,53,15000),
("Jeff","Marketing","CA",80000,25,18000),
("Kumar","Marketing","NY",91000,50,21000)
)
val df = simpleData.toDF("employee_name","department","state","salary","age","bonus")
df.show()
//Group By on single column
df.groupBy("department").count().show(false)
df.groupBy("department").avg("salary").show(false)
df.groupBy("department").sum("salary").show(false)
df.groupBy("department").min("salary").show(false)
df.groupBy("department").max("salary").show(false)
df.groupBy("department").mean("salary").show(false)
//GroupBy on multiple columns
df.groupBy("department","state")
.sum("salary","bonus")
.show(false)
df.groupBy("department","state")
.avg("salary","bonus")
.show(false)
df.groupBy("department","state")
.max("salary","bonus")
.show(false)
df.groupBy("department","state")
.min("salary","bonus")
.show(false)
df.groupBy("department","state")
.mean("salary","bonus")
.show(false)
//Running Filter
df.groupBy("department","state")
.sum("salary","bonus")
.show(false)
//using agg function
df.groupBy("department")
.agg(
sum("salary").as("sum_salary"),
avg("salary").as("avg_salary"),
sum("bonus").as("sum_bonus"),
max("bonus").as("max_bonus"))
.show(false)
df.groupBy("department")
.agg(
sum("salary").as("sum_salary"),
avg("salary").as("avg_salary"),
sum("bonus").as("sum_bonus"),
stddev("bonus").as("stddev_bonus"))
.where(col("sum_bonus") > 50000)
.show(false)
}
# 使用多个聚合函数前,先导入相关的包 "import org.apache.spark.sql.functions._"
import org.apache.spark.sql.functions._
df
.groupBy("first_class_id")
.agg(count("first_class_id").as("count_first_class_id"),sum("exposure_cnt").as("sum_exposure_cnt")).show()
选择多列
val groupByList = Array("item_id", "first_class_id")
# : _* 表示讲列名传入select
df.select(groupByList.map(col): _*).show
df.groupBy(groupByList.map(col): _*).agg(sum("exposure_cnt").as("sum_exposure_cnt")).show()
# agg方法
var map = scala.collection.immutable.Map.empty[String, String]
for (func <- aggFunc) {
for (colName <- calculateCol) {
map += (colName -> func)
}
}
df.groupBy(groupByList.map(col): _*).agg(map).show(false)
Spark 指南:Spark SQL(二)—— 结构化操作
Spark中选取DataFrame多列的三种方式
SparkSQL 高级篇(一) 聚合操作
Spark:group by和聚合函数使用
【Saprk】Spark DataFrame 列的类型转换
Spark 指南:Spark SQL(三)—— 结构化类型
Explain different ways of groupBy() in spark SQL
Spark读取本地文件和HDFS文件
spark读取excel成dataframe的几种方式
package com.huawei.rcm.study
abstract class Notification
case class Email(sender: String, title: String, body: String) extends Notification
case class SMS(caller: String, message: String) extends Notification
case class VoiceRecording(contactName: String, link: String) extends Notification
object demo {
def matchTest(x: Int): String = x match {
case 1 => "one"
case 2 => "two"
case _ => "many"
}
def showNotification(notification: Notification): String = {
notification match {
case Email(email, title, _) =>
s"You got an email from $email with title: $title"
case SMS(number, message) =>
s"You got an SMS from $number! Message: $message"
case VoiceRecording(name, link) =>
s"you received a Voice Recording from $name! Link: $link"
}
}
def main(args: Array[String]): Unit = {
val someSms = SMS("12345", "Are you there?")
val someVoiceRecording = VoiceRecording("Tom", "voicerecording.org/id/123")
println(showNotification(someSms)) // prints You got an SMS from 12345! Message: Are you there?
println(showNotification(someVoiceRecording)) // you received a Voice Recording from Tom! Click the link to hear it: voicerecording.org/id/123
println(matchTest(1))
}
}
import org.apache.spark.sql.SparkSession
import org.json4s.jackson.{JsonMethods, Serialization}
case class User(name: String, age: Int)
object Json4STest {
def main(args: Array[String]): Unit = {
//数据格式:user:{"name": "zs","age": 10}
val json = "{\"name\": \"zs\",\"age\": 10}"
//导隐式函数
implicit val f = org.json4s.DefaultFormats
/** ************************* json字符串->对象 ************************************** */
val user: User = JsonMethods.parse(json).extract[User]
println(user)
/** ************************* 对象->json字符串 ************************************** */
val userJStr: String = Serialization.write(user)
println(userJStr)
val strings = new Array[String](3)
val arrayTest = Array(1, 2, 3, 4) //正确
val listTest = List(1, 2, 3, 4)
for (i <- listTest.indices) {
println(listTest(i))
}
// sort
// val list=List(5,1,2,4,3)
// list.sorted
val list = List("1 hadoop", "2 spark", "3 flink")
list.sortBy(x => x.split(" ")(1))
// groupBy
// arrayTest.map()
// val a = List("张三"->"男", "李四"->"女", "王五"->"男")
// a.groupBy(x=>x._2)
// arrayTest.groupBy()
// arrayTest.sorted
// val a = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
// a.reduce((x, y) => x + y)
// a.reduceLeft(_+_)
val a = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
a.fold(0)(_ + _)
val spark = SparkSession
.builder()
.master("local")
.appName("test")
.config("spark.sql.execution.arrow.enabled", "true")
.getOrCreate()
spark.sql("select 1 as num").show()
val dataPath = "C:\\Users\\86183\\Desktop\\教程\\fake_data.xlsx"
//读excel
val df = spark.read.format("com.crealytics.spark.excel")
.option("header", "true").load(dataPath)
df.show(false)
println(df.dtypes.mkString("Array(", ", ", ")"))
val saveDataPath = "C:\\Users\\86183\\Desktop\\教程\\fake_data_1.xlsx"
//写excel
df.coalesce(1).write
.format("com.crealytics.spark.excel")
.option("dataAddress", "A1")
.option("header", "true")
.mode("overwrite")
.save(saveDataPath)
df.createTempView("temp_table")
val sqlString =
"""
|select
|*
|from temp_table
|""".stripMargin
spark.sql(sqlString).show(false)
import org.apache.spark.sql.functions._
df.groupBy("first_class_id")
.agg(count("first_class_id").as("count_first_class_id"), sum("exposure_cnt").as("sum_exposure_cnt")).show()
val groupByList = Array("item_id", "first_class_id")
val aggFunc = Array("avg", "max")
val calculateCol = Array("ctr", "exposure_cnt")
// val columns = df.columns
import org.apache.spark.sql.{Column, DataFrame}
import org.apache.spark.sql.functions.col
val columns: Array[String] = df.columns
val arrayColumn: Array[Column] = columns.map(column => col(column))
val df2: DataFrame = df.select(arrayColumn: _*)
df.select(groupByList.map(col): _*).show
df.groupBy(groupByList.map(col): _*).agg(sum("exposure_cnt").as("sum_exposure_cnt")).show()
df.groupBy(groupByList.map(col): _*).count().show()
var map = scala.collection.immutable.Map.empty[String, String]
for (func <- aggFunc) {
for (colName <- calculateCol) {
map += (colName -> func)
}
}
df.groupBy(groupByList.map(col): _*).agg(map).show(false)
}
}
6. spark ML之特征处理
spark ML之特征处理
1、VectorIndexer
根据源码注释,VectorIndexer是用于在“向量”的数据集中索引分类特征列的类(Class for indexing categorical feature columns in a dataset of Vector),这看起来不太好理解,直接看用法,举例说明就好了。
1.1 数据
我们用普通的数据格式即可:
data1.txt
1,-1.0 1.0
0,0.0 3.0
1,-1.0 5.0
0,0.0 1.0
其中第一列为label,后面的为features
spark读取数据程序(供参考):
import spark.implicits._
val data_path = "files/ml/featureprocessing/data1.txt"
val data = spark.read.text(data_path).map {
case Row(line: String) =>
var arr = line.split(',')
(arr(0), Vectors.dense(arr(1).split(' ').map(_.toDouble)))
}.toDF("label", "features")
data.show(false)
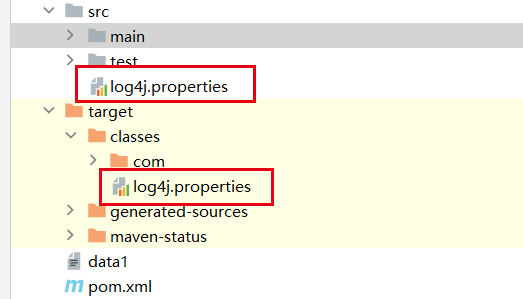
7. Spark运行日志去除——log4j.properties
log4j.rootLogger=ERROR,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%-20c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h5tlIh8Q-1689610033378)(C:\Users\86183\AppData\Roaming\Typora\typora-user-images\image-20230115211719071.png)]
spark.read.text(data_path).map {
case Row(line: String) =>
var arr = line.split(‘,’)
(arr(0), Vectors.dense(arr(1).split(’ ').map(_.toDouble)))
}.toDF(“label”, “features”)
data.show(false)
# 7. Spark运行日志去除——log4j.properties
```properties
log4j.rootLogger=ERROR,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%-20c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n