YOLO-V5分类实战系列 —— 调优自己的数据集
- 1、保存训练和测试图片
- 2、数据归一化
- 3、数据增强
- 3.1、数据增强库:albumentations
- 3.2、数据增强库:torchvision
- 4、ONNX CPU 推理
- 4.1、Pt 模型转为 ONNX
- 4.2、ONNX 推理验证
- 4.3、 ONNX CPU推理(C++)
- 5、RK 1808 部署
- 5.1、查看模型输入、输出名字
- 5.2、转换为RKNN模型
- 5.3、C++ 芯片部署
- 6、调优策略
- 6.1、数据标注
- 6.2、数据清洗
- 6.3、网络调优
1、保存训练和测试图片
问题1:训练过程中,如何保证训练集的数据增强和验证集的数据增强是基本一致的?
问题2:训练过程中,如何保证训练集和验证集的标签是正确的?
解决方法:训练测试过程中,保存训练图片和测试图片,并将标签画到图片可视化。
训练过程中,需要保证训练的数据预处理和测试的数据预处理保持一致,这一步还是很重要的,需要优先验证其一致性。常见的【预处理】包括:图片尺寸调整(resize,crop),色彩增强,空间变换(翻转,旋转等),归一化等。
- 下面的代码片段是数据读取的核心类,包括数据读取和数据增强。代码位置: 【
utils/dataloaders.py】,并且需要在def __init__()中需要添加self.augment = augment,保存图像的调用位置def __getitem__()中添加self.save_images(f, sample),下面代码都有添加(红色框内的代码)

-
训练和测试图片保存的代码片段如下,将其添加到类
ClassificationDataset的成员函数即可。通过self.augment判定是训练图片还是测试图片,进而对图片名字进行命名。保存的路径自己可以设置,def save_images(self, f, sample): # 保存数据增强后的图片,用于对比训练和验证的图片预处理是否一致 print(' -------------self.augment: ', self.augment) if self.augment: print(' -------------f: ', f) a = f.split('/train/')[0]+'/train_aug/'+os.path.basename(f)[:-4]+'_train.jpg' print(' -------------a: ', a) torchvision.utils.save_image(sample, a) else: print(' -------------f: ', f) a = f.split('/test/')[0]+'/train_aug/'+os.path.basename(f)[:-4]+'_test.jpg' print(' -------------a: ', a) torchvision.utils.save_image(sample, a)训练过程中,测试和训练预处理保存的图片如下,注意训练集和测试集的图片用同样的图片,这样更方便对比,

2、数据归一化
代码中默认的是【ImageNet】数据集的均值和标准差,具体如下
IMAGENET_MEAN = 0.485, 0.456, 0.406 # RGB mean
IMAGENET_STD = 0.229, 0.224, 0.225 # RGB standard deviation
当使用自己的数据集的时候,通常根据数据集是否与ImageNet差异性大小,决定是否重新计算均值和标准差。针对我自己的数据集,需要重新计算,代码如下
def compute_mean_std():
# 将所有的【路径+图片】读取到列表 all_file
images_path = 'datasets/biaozhu_train/train/' # 针对自己的路径,需要修改
all_file = []
for i,j,k in os.walk(images_path):
if len(k)>0:
print('i: ', i)
print('j: ', j)
all_file.append([os.path.join(i,kk) for kk in k])
print('------------------')
# 统计所有图片的数量
num_images = len(all_file[0]) + len(all_file[1]) + len(all_file[2])
# 逐张图计算均值和方差
mean_r = mean_g = mean_b = 0
std_r = std_g = std_b = 0
for i in range(3):
for j in range(len(all_file[i])):
print(' i: ', i)
print(' j: ', j)
img = cv2.imread(all_file[i][j])
print('img shape: ', img.shape)
img = np.asarray(img)
img = img.astype(np.float32) / 255.
# cv2
im_mean, im_stds = cv2.meanStdDev(img)
mean_r += im_mean[0]
mean_g += im_mean[1]
mean_b += im_mean[2]
std_r += im_stds[0]
std_g += im_stds[1]
std_b += im_stds[2]
# 计算平均值
aa_r = mean_r/num_images
aa_g = mean_g/num_images
aa_b = mean_b/num_images
bb_r = std_r/num_images
bb_g = std_g/num_images
bb_b = std_b/num_images
print(' last mean: ', aa_r,aa_g,aa_b)
print(' last stds: ', bb_r,bb_g,bb_b)
计算结果如下,与【ImageNet】数据集的均值有差别
IMAGENET_MEAN = 0.3539317, 0.36820036, 0.37243055
IMAGENET_STD = 0.22637626, 0.22498632, 0.22197094
值得注意:使用自己计算的均值和标准差,训练过程更加稳定,波动较小
3、数据增强
官方源代码训练过程中,训练流程和验证流程的数据处理库有两个库(如果开发环境中安装了 albumentations 库),分别是 【albumentations】和【torchvision】,否则默认均使用【torchvision】。下面我们将分别介绍它们:
3.1、数据增强库:albumentations
训练过程中(如果安装了albumentations库),则会执行下图中的代码。如图所示,包括三类的数据增强,也是常用的图像数据增强方法

下面我们分别介绍上述的几种数据增强方式:
-
随机裁剪
A.RandomResizedCrop(height=size, width=size, scale=scale, ratio=ratio)函数功能:先对图像进行裁剪,然后resize到固定的尺寸
height:处理完后,最终图像的高度;
width:处理完后,最终图像的宽度;
scale:裁剪图占整张图区域面积(h*w)的比例是多少;
ratio:裁剪区域的宽高比;该函数的部分核心源码如下所示,主要计算待裁剪的【区域大小】和【裁剪的起始位置】,具体如下以及部分注释:
def get_params_dependent_on_targets(self, params): img = params["image"] area = img.shape[0] * img.shape[1] # 当【if】条件不满足时,尝试10次 for _attempt in range(10): # 根据scale和ratio参数,得到随机的参数,进而计算裁剪图的大小(w,h) target_area = random.uniform(*self.scale) * area log_ratio = (math.log(self.ratio[0]), math.log(self.ratio[1])) aspect_ratio = math.exp(random.uniform(*log_ratio)) w = int(round(math.sqrt(target_area * aspect_ratio))) # skipcq: PTC-W0028 h = int(round(math.sqrt(target_area / aspect_ratio))) # skipcq: PTC-W0028 # 计算裁剪区域在原图的起始点 if 0 < w <= img.shape[1] and 0 < h <= img.shape[0]: i = random.randint(0, img.shape[0] - h) j = random.randint(0, img.shape[1] - w) # 进行裁剪+resize操作,底层使用的OpenCV return { "crop_height": h, "crop_width": w, "h_start": i * 1.0 / (img.shape[0] - h + 1e-10), "w_start": j * 1.0 / (img.shape[1] - w + 1e-10), } # 尝试10次后,如果上述的【if】条件依然无法满足,则执行下面的代码进行裁剪 # Fallback to central crop in_ratio = img.shape[1] / img.shape[0] if in_ratio < min(self.ratio): w = img.shape[1] h = int(round(w / min(self.ratio))) elif in_ratio > max(self.ratio): h = img.shape[0] w = int(round(h * max(self.ratio))) else: # whole image w = img.shape[1] h = img.shape[0] i = (img.shape[0] - h) // 2 j = (img.shape[1] - w) // 2 # 进行裁剪+resize操作,底层使用的OpenCV return { "crop_height": h, "crop_width": w, "h_start": i * 1.0 / (img.shape[0] - h + 1e-10), "w_start": j * 1.0 / (img.shape[1] - w + 1e-10), }测试原图

处理后的结果如下图所示:下面三张图,分别使用 0.06,0.5,0.9 的 scale 参数得到的裁剪图,最终 resize 到 256,可以看到被裁剪的范围逐渐增大,由于是随机裁剪,所以裁剪后的区域差别较大


-
空间变换
A.HorizontalFlip(p=hflip) # 左右翻转 A.VerticalFlip(p=vflip) # 上下翻转处理结果如下图所示(左图:左右翻转,右图:上下翻转),


-
色彩变换
A.ColorJitter(*color_jitter, 0) # 随机改变图像的亮度,对比度,饱和度不作介绍
-
归一化
A.Normalize(mean=mean, std=std) # Normalize and convert to Tensor对于分类模型,通常需要减去均值,除以标准差,得到如下图所示:

-
调整输入排列
ToTensorV2()函数功能:(1)HWC 转为 CHW;(2)numpy 转为 tensor
函数的核心源码如下:
def apply(self, img, **params): # skipcq: PYL-W0613 if len(img.shape) not in [2, 3]: raise ValueError("Albumentations only supports images in HW or HWC format") if len(img.shape) == 2: img = np.expand_dims(img, 2) return torch.from_numpy(img.transpose(2, 0, 1))
3.2、数据增强库:torchvision
# 官方的预处理方法
return T.Compose([CenterCrop(size), ToTensor(), T.Normalize(IMAGENET_MEAN, IMAGENET_STD)])
-
中心裁剪:CenterCrop(size)
以最小边的大小裁剪长边的中心区域,核心代码如下class CenterCrop: # YOLOv5 CenterCrop class for image preprocessing, i.e. T.Compose([CenterCrop(size), ToTensor()]) def __init__(self, size=640): super().__init__() self.h, self.w = (size, size) if isinstance(size, int) else size def __call__(self, im): # im = np.array HWC imh, imw = im.shape[:2] m = min(imh, imw) # min dimension top, left = (imh - m) // 2, (imw - m) // 2 return cv2.resize(im[top:top + m, left:left + m], (self.w, self.h), interpolation=cv2.INTER_LINEAR) -
调整输入排列
函数功能:(1)HWC 转为 CHW;(2)BGR 转 RGB;(3)numpy 转为 tensor;
函数的核心源码如下:class ToTensor: # YOLOv5 ToTensor class for image preprocessing, i.e. T.Compose([LetterBox(size), ToTensor()]) def __init__(self, half=False): super().__init__() self.half = half def __call__(self, im): # im = np.array HWC in BGR order im = np.ascontiguousarray(im.transpose((2, 0, 1))[::-1]) # HWC to CHW -> BGR to RGB -> contiguous im = torch.from_numpy(im) # to torch im = im.half() if self.half else im.float() # uint8 to fp16/32T.Normalize(IMAGENET_MEAN, IMAGENET_STD)]:不作介绍
4、ONNX CPU 推理
主要包括三部分内容:
- Pt 转为 ONNX 模型;
- ONNX 推理验证(Python);
- ONNX CPU 推理(C++);
4.1、Pt 模型转为 ONNX
代码位置:yolov5/export.py
# 针对自己的网络输入大小,注意 imgsz 的设置,默认是640
python export.py --weights runs/train-cls/exp24/weights/best.pt --include onnx --imgsz 256
4.2、ONNX 推理验证
代码位置:yolov5/classify/val.py
python classify/val.py --weights best.onnx
4.3、 ONNX CPU推理(C++)
main.cpp
#include <iostream>
#include <opencv2/opencv.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <onnxruntime_cxx_api.h>
#include "helpers.h"
#include<algorithm>
using namespace cv;
using namespace std;
int main(int argc, char* argv[]) {
if (argc < 4)
{
std::cout << ">>>>>>>>>>>>>>>>>>>>>>>>>: Parameters too less" << std::endl;
return -1;
}
std::string class_path = argv[2];
std::string image_path = argv[3];
Ort::Env env;
Ort::Session session(nullptr);
Ort::SessionOptions sessionOptions{nullptr};
constexpr int64_t numChannles = 3;
constexpr int64_t width = 256;
constexpr int64_t height = 256;
constexpr int64_t numClasses = 2;
constexpr int64_t numInputElements = numChannles * height * width;
const string imgFile = image_path;
const string labelFile = class_path;
auto modelPath = argv[1];
sessionOptions = Ort::SessionOptions();
//load labels
Helpers utils;
vector<string> labels = utils.loadLabels(labelFile);
if (labels.empty()){
cout<< "Failed to load labels: " << labelFile << endl;
return 1;
}
//load image
vector<float> imageVec = utils.loadImage(imgFile, height, width);
if (imageVec.empty()){
cout << "Invalid image format. Must be 224*224 RGB image. " << endl;
return 1;
}
// create session
cout << "create session. " << endl;
session = Ort::Session(env, modelPath, sessionOptions);
// get the number of input
size_t num_input_nodes = session.GetInputCount();
std::vector<const char*> input_node_names(num_input_nodes);
std::vector<int64_t> input_node_dims;
std::cout << "Number of inputs = " << num_input_nodes << std::endl;
// define shape
const array<int64_t, 4> inputShape = {1, numChannles, height, width};
const array<int64_t, 2> outputShape = {1, numClasses};
// define array
array<float, numInputElements> input;
array<float, numClasses> results;
// define Tensor
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
auto inputTensor = Ort::Value::CreateTensor<float>(memory_info, input.data(), input.size(), inputShape.data(), inputShape.size());
auto outputTensor = Ort::Value::CreateTensor<float>(memory_info, results.data(), results.size(), outputShape.data(), outputShape.size());
// copy image data to input array
copy(imageVec.begin(), imageVec.end(), input.begin());
// define names
Ort::AllocatorWithDefaultOptions ort_alloc;
std::vector<const char*> inputNames;
std::vector<const char*> outputNames;
inputNames.push_back(session.GetInputName(0, ort_alloc));
outputNames.push_back(session.GetOutputName(0, ort_alloc));
std::cout << "Input name: " << inputNames[0] << std::endl;
std::cout << "Output name: " << outputNames[0] << std::endl;
// run inference
cout << "run inference. " << endl;
try{
for (size_t i = 0; i < 1; i++)
{
auto start = std::chrono::system_clock::now();
session.Run(Ort::RunOptions{nullptr}, inputNames.data(), &inputTensor, 1, outputNames.data(), &outputTensor, 1);
auto end = std::chrono::system_clock::now();
std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
}
}
catch(Ort::Exception& e) {
cout << e.what() << endl;
return 1;
}
// sort results
vector<pair<size_t, float>> indexValuePairs;
cout << "results.size(): " << results[0] << endl;
for(size_t i = 0; i < results.size(); ++i){
cout << "results[i]: " << results[i] << endl;
indexValuePairs.emplace_back(i, results[i]);
}
sort(indexValuePairs.begin(), indexValuePairs.end(), [](const auto& lhs, const auto& rhs)
{ return lhs.second > rhs.second;});
// show Top5
for (size_t i = 0; i < 1; ++i) {
const auto& result = indexValuePairs[i];
cout << i + 1 << ": " << labels[result.first] << " " << result.second << endl;
}
}
helpers.h
#pragma once
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/core/core.hpp>
using namespace std;
class Helpers{
public:
vector<float> loadImage(const string path, int x, int y);
vector<string> loadLabels(const string path);
};
helpers.cpp
#include <fstream>
#include <iostream>
#include <array>
#include "helpers.h"
using namespace std;
using namespace cv;
const float mean_vals[3] = {0.3539317f, 0.36820036f, 0.37243055f};
const float scale_vals[3] = {1.0 / 0.22637626f, 1.0 / 0.22498632f, 1.0 / 0.22197094f};
void normalize_inplace_kxh(cv::Mat &mat_inplace, const float *mean, const float *scale)
{
if (mat_inplace.type() != CV_32FC3) mat_inplace.convertTo(mat_inplace, CV_32FC3);
for (unsigned int i = 0; i < mat_inplace.rows; ++i)
{
cv::Vec3f *p = mat_inplace.ptr<cv::Vec3f>(i);
for (unsigned int j = 0; j < mat_inplace.cols; ++j)
{
p[j][0] = (p[j][0] - mean[0]) * scale[0];
p[j][1] = (p[j][1] - mean[1]) * scale[1];
p[j][2] = (p[j][2] - mean[2]) * scale[2];
}
}
}
vector<float> Helpers::loadImage(const string filename, int sizeX, int sizeY)
{
Mat image = imread(filename);
if (image.empty()) {
cout << "No image found.";
}
// convert from BGR to RGB
cvtColor(image, image, COLOR_BGR2RGB);
// resize
resize(image, image, Size(sizeX, sizeY));
cv::Mat canvas;
image.convertTo(canvas, CV_32FC3, 1. / 255.f, 0.f);
normalize_inplace_kxh(canvas, mean_vals, scale_vals);
// reshape to 1D
canvas = canvas.reshape(1, 1);
// uint_8, [0, 255] -> float, [0, 1]
// Normailze number to between 0 and 1
// Convert to vector<float> from cv::Mat.
vector<float> vec;
canvas.convertTo(vec, CV_32FC1);
// Transpose (Height, Width, Channel)(224,224,3) to (Chanel, Height, Width)(3,224,224)
vector<float> output;
for (size_t ch = 0; ch < 3; ++ch) {
for (size_t i = ch; i < vec.size(); i += 3) {
output.emplace_back(vec[i]);
}
}
return output;
}
vector<string> Helpers::loadLabels(const string filename)
{
vector<string> output;
ifstream file(filename);
if (file) {
string s;
while (getline(file, s)) {
output.emplace_back(s);
}
file.close();
}
return output;
}
编译脚本: build.sh
mkdir build
cd build
cmake ..
make -j4
运行脚本: run.sh
data_path=/home/robot/Project/onnx_demo/onnxruntime_resnet-main/assets/1664450262_1664708729_02597_003.jpg
model_path=/home/robot/Project/onnx_demo/onnxruntime_resnet-main/assets/best.onnx
class_path=/home/robot/Project/onnx_demo/onnxruntime_resnet-main/assets/imagenet_classes.txt
./build/demo $model_path $class_path $data_path
5、RK 1808 部署
主要流程包括:
(1)查看模型的输入和输出节点名称;
(2)PC模拟器模型转换为RKNN,以及推理;
(3)C++部署;
5.1、查看模型输入、输出名字
使用 Netron 打开 ONNX模型,如下图所示,可以得到【输入,输出】节点的名称,分别为【images,output0】,后面转换模型的时候,需要指定输入和输出节点名称,
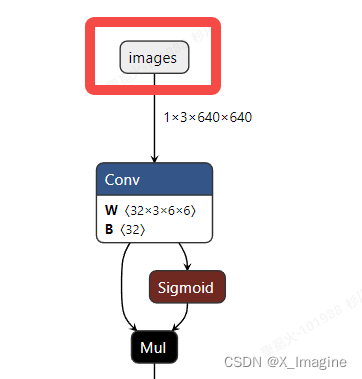
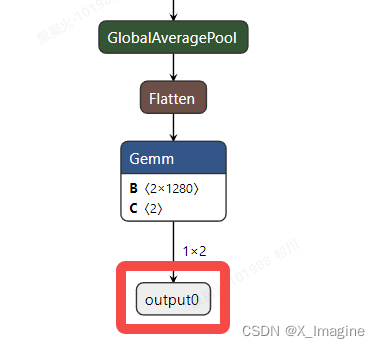
5.2、转换为RKNN模型
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
from rknn.api import RKNN
ONNX_MODEL = 'best.onnx'
RKNN_MODEL = 'best.rknn'
def show_outputs(outputs):
output = outputs[0][0]
output_sorted = sorted(output, reverse=True)
top5_str = 'resnet50v2\n-----TOP 5-----\n'
for i in range(1):
value = output_sorted[i]
index = np.where(output == value)
for j in range(len(index)):
if (i + j) >= 5:
break
if value > 0:
topi = '{}: {}\n'.format(index[j], value)
else:
topi = '-1: 0.0\n'
top5_str += topi
print(top5_str)
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN()
# pre-process config
print('--> Config model')
rknn.config(mean_values=[[90.253, 93.891, 94.97]], std_values=[[57.726, 57.372, 56.603]], reorder_channel='0 1 2')
print('done')
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL,
inputs=['images'],
input_size_list=[[3, 256, 256]],
outputs=['output0'])
if ret != 0:
print('Load resnet50v2 failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
if ret != 0:
print('Build resnet50v2 failed!')
exit(ret)
print('done')
# Export RKNN model
print('--> Export RKNN model')
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export resnet50v2.rknn failed!')
exit(ret)
print('done')
# Set inputs
img = cv2.imread('./2_256x256.jpg')
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
# Inference
print('--> Running model')
t1 = time.time()
outputs = rknn.inference(inputs=[img])
x = outputs[0]
output = np.exp(x)/np.sum(np.exp(x))
outputs = [output]
t2 = time.time()
print('inference time: ', t2-t1)
show_outputs(outputs)
print('done')
rknn.release()
5.3、C++ 芯片部署
对于分类模型的部署,可以参考官方的例子,几乎不需要更改太多代码,编译即可使用,这里不作详细解释
RK工具链Demo :https://github.com/rockchip-linux/rknpu/tree/master/rknn/rknn_api/examples/rknn_mobilenet_demo
个人总结的博客:Rockchip RV1126 模型部署(完整部署流程),该例子与1808共用一套工具链,可以作为参考
6、调优策略
调优策略,也不是很方便介绍太细,下面只从几个大的方面介绍一些注意问题,比如数据标注,数据清洗,模型调优等。
6.1、数据标注
当我们面临一个实际场景时,基本的工作流程应该如下:
- 采集数据:获取该场景下的数据样本,前期可以先采集一部分,验证整个过程。后续随着算法的调优和遇到的问题,数据采集也可能有一定的要求;
- 设计标注规则:比如一张图片应该标注什么标签。有些图片内容对应的标签是模糊不清的,判断可能也不唯一。此时,可能需要看我们关注的点是什么?训练的侧重不同,可能决定一张图片的标签是什么?所以关键是如何定义任务。根据训练的结果,以及项目的侧重点差异,可能会影响标签的标注(比如,我们更关注类别1的分类正确性,那么如果测试集,类别1的预测非常好,但是类别2,3相对较差,并且类别2,3多是相互预测错误,那么根据项目的需要,也是可以接受的);
6.2、数据清洗
通常我们需要先标注一组数据,根据自己数据集的规模,比如取出10%的规模进行训练测试。使用该数据训练网络,并得到初版的效果。此时我们推理测试集,查看测试集的预测情况,错误有哪些,为什么会错?是网络本身的问题,还是该图片本身的标签定义就很模糊呢?
- 脏数据清洗:表示数据质量非常差,完全不可用,比如严重曝光,全黑数据,严重模糊,完全遮挡等;
- 标签模糊定义:有的数据标签比较难以定义,就分类问题而言,通常提取的是图像的全局+局部特征,有时候图片内同时存在目标特征和非目标特征,就存在定义类别的问题;
- 样本划分:当我们训练了一版基本的模型,准确度达到一定的高度。但是,当我们去推理测试集时,总有一些样本预测错误。此时,我们不妨预测一遍训练集,将预测错误的样本提取出来,逐个核对样本,确认是标签本身错误?特征不明显?困难样本?此时,再针对性的解决问题;
6.3、网络调优
实际项目中,重点可能是数据的清洗,网络的调整比较有限,可以调整的有如下几方面,具体流程如下:
- 网络结构:根据部署设备的性能,选择合适大小,应用较为广泛,易部署的模型;
- 超参数:学习率,batch-size等;
- 网络泛化:正则化,dropout,soft-label;




![[Mysql] 索引失效的情况详解~](https://img-blog.csdnimg.cn/8c2c00bab9fe4fa8bd815518b1e397c1.png)