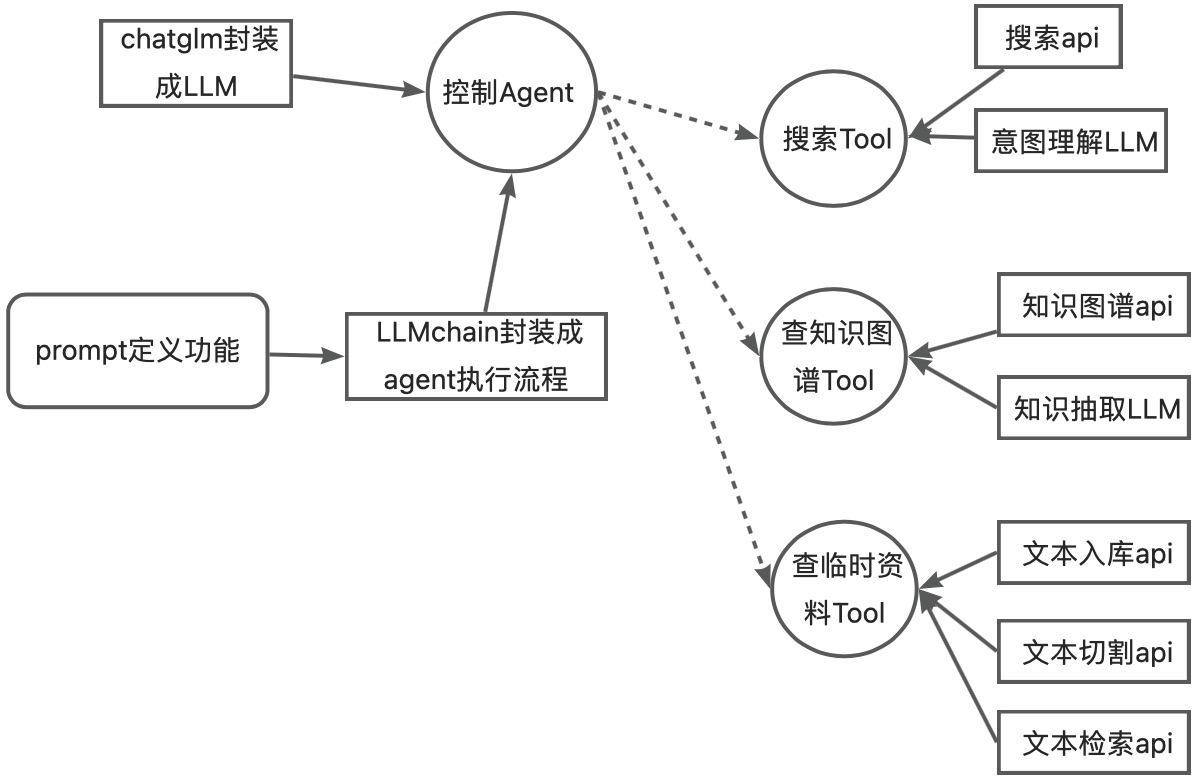
背景:
这个系列文章,会从LLM搭建应用生态角度来写。从0到1训练一个大的通用的模型对于大部分人和团队来讲是不现实的。重资金,重技术含量、重投入这几个门槛可以把很多团队直接劝退。那么在LLM蓬勃发展的时候我们可以做些什么呢,是否可以围绕LLM来搭建生态,搭建应用市场;针对LLM模型的不足做一些小的设计训练呢。这个其实很像发动机引擎,无论是汽车发动机引擎、柴油发动机引擎还是航空发动机引擎,能造的其实全球也不超过20家。但是围绕着这些引擎,延展出了汽车、农用器械、矿产机械、船舶、海洋、火车、飞机.....一系列的产业链、产业生态,编织出了现代工业的网。同理不从0造LLM引擎,深入的理解引擎原理,基于LLM引擎搭建应用生态是否也是可行呢。这一系列的文章尝试来做这件事情,如何打造LLM的生态,如何把LLM引擎能力引出、如何做各种转接头把LLM能力转成适配的动力。
这篇文章主要会介绍下面3部分:
1.Chatglm转成适配langchian的llm模式
2.搭建定制化的工具集
3.基于llm、工具结合构建有一定自主性Agent
代码实现
model
实现思路,继承langchain.llm.base中的LLM类,重写_call方法、_identifying_params属性类,load_model方法用transformer的AutoModel.from_pretrained来加载chatglm模型,把实例化的model传给LLM的model,chatglm基于prompt生成的逻辑封装在generate_resp方法,LLM的_call方法调用generate_resp获取生成逻辑。
### define llm ###
from typing import List, Optional, Mapping, Any
from functools import partial
from langchain.llms.base import LLM
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from transformers import AutoModel, AutoTokenizer
### chatglm-6B llm ###
class ChatGLM(LLM):
model_path: str
max_length: int = 2048
temperature: float = 0.1
top_p: float = 0.7
history: List = []
streaming: bool = True
model: object = None
tokenizer: object = None
@property
def _llm_type(self) -> str:
return "chatglm-6B"
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {
"model_path": self.model_path,
"max_length": self.max_length,
"temperature": self.temperature,
"top_p": self.top_p,
"history": [],
"streaming": self.streaming
}
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
add_history: bool = False
) -> str:
if self.model is None or self.tokenizer is None:
raise RuntimeError("Must call `load_model()` to load model and tokenizer!")
if self.streaming:
text_callback = partial(StreamingStdOutCallbackHandler().on_llm_new_token, verbose=True)
resp = self.generate_resp(prompt, text_callback, add_history=add_history)
else:
resp = self.generate_resp(self, prompt, add_history=add_history)
return resp
def generate_resp(self, prompt, text_callback=None, add_history=True):
resp = ""
index = 0
if text_callback:
for i, (resp, _) in enumerate(self.model.stream_chat(
self.tokenizer,
prompt,
self.history,
max_length=self.max_length,
top_p=self.top_p,
temperature=self.temperature
)):
if add_history:
if i == 0:
self.history += [[prompt, resp]]
else:
self.history[-1] = [prompt, resp]
text_callback(resp[index:])
index = len(resp)
else:
resp, _ = self.model.chat(
self.tokenizer,
prompt,
self.history,
max_length=self.max_length,
top_p=self.top_p,
temperature=self.temperature
)
if add_history:
self.history += [[prompt, resp]]
return resp
def load_model(self):
if self.model is not None or self.tokenizer is not None:
return
self.tokenizer = AutoTokenizer.from_pretrained(self.model_path, trust_remote_code=True)
self.model = AutoModel.from_pretrained(self.model_path, trust_remote_code=True).half().cuda().eval()
def set_params(self, **kwargs):
for k, v in kwargs.items():
if k in self._identifying_params:
self.k = v
llm = ChatGLM(model_path="../ChatGLM2-6B/llm_model/models--THUDM--chatglm2-6b/snapshots/8eb45c842594b8473f291d0f94e7bbe86ffc67d8")
llm.load_model()Tool集合实现
tool集合包括了两层:工具api层,这一层主要是实现工具的逻辑层功能;业务调用工具逻辑层,这一层主要就是对工具能力根据实际业务来适配的策略逻辑层。下面我们会通过一个搜索API根据各种业务需要来封不同工具集来做示意。再强调一遍这部分只是做个示意具体的其他工具集合的实现会在后面文章介绍,比如:向量知识库、只是图谱、可视化工具、摘要抽取、意图理解、文本生成图片、图片内容理解....
搜索工具API层实现代码,Rapid来实现联网搜索即时信息。
import requests
#这个RapidAPIKey,各位自己去注册下就有了
RapidAPIKey = ""
class DeepSearch:
def search(query: str = ""):
query = query.strip()
if query == "":
return ""
if RapidAPIKey == "":
return "请配置你的 RapidAPIKey"
url = "https://bing-web-search1.p.rapidapi.com/search"
querystring = {"q": query,
"mkt":"zh-cn","textDecorations":"false","setLang":"CN","safeSearch":"Off","textFormat":"Raw"}
headers = {
"Accept": "application/json",
"X-BingApis-SDK": "true",
"X-RapidAPI-Key": RapidAPIKey,
"X-RapidAPI-Host": "bing-web-search1.p.rapidapi.com"
}
response = requests.get(url, headers=headers, params=querystring)
data_list = response.json()['value']
if len(data_list) == 0:
return ""
else:
result_arr = []
result_str = ""
count_index = 0
for i in range(6):
item = data_list[i]
title = item["name"]
description = item["description"]
item_str = f"{title}: {description}"
result_arr = result_arr + [item_str]
result_str = "\n".join(result_arr)
return result_str
业务调用工具逻辑层,对搜索API结合业务需要用LLMchain和llm能力来做检索前理解、检索后信息整合。Tool的实现继承langchain.tools的BaseTool来实现,通过回调方式来实现把搜索API能力即成到后续Agent里面。
from langchain.tools import BaseTool
from langchain.callbacks.manager import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
class functional_Tool(BaseTool):
name: str = ""
description: str = ""
url: str = ""
def _call_func(self, query):
raise NotImplementedError("subclass needs to overwrite this method")
def _run(
self,
query: str,
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> str:
return self._call_func(query)
async def _arun(
self,
query: str,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> str:
raise NotImplementedError("APITool does not support async")
class Product_knowledge_Tool(functional_Tool):
llm: BaseLanguageModel
# tool description
name = "生成文案,产品卖点查询"
description = "用户输入的是生成内容问题,并且没有描述产品具体卖点无法给出答案,可以用互联网检索查询来获取相关信息"
# QA params
qa_template = """
请根据下面信息```{text}```,回答问题:{query}
"""
prompt = PromptTemplate.from_template(qa_template)
llm_chain: LLMChain = None
'''
def _run(self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None):
self.get_llm_chain()
context = DeepSearch.search(query = query)
resp = self.llm_chain.predict(text=context, query=query)
return resp
'''
def _call_func(self, query) -> str:
self.get_llm_chain()
context = DeepSearch.search(query = query)
resp = self.llm_chain.predict(text=context, query=query)
return resp
def get_llm_chain(self):
if not self.llm_chain:
self.llm_chain = LLMChain(llm=self.llm, prompt=self.prompt)
class Actor_knowledge_Tool(functional_Tool):
llm: BaseLanguageModel
# tool description
name = "生成文案,人群画像查询"
description = "用户输入的是内容生成问题,并且没有描述人群画像和人群的喜好无法给出答案,可以用互联网检索查询来获取相关信息"
# QA params
qa_template = """
请根据下面信息```{text}```,回答问题:{query}
"""
prompt = PromptTemplate.from_template(qa_template)
llm_chain: LLMChain = None
'''
def _run(self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None):
self.get_llm_chain()
context = DeepSearch.search(query = query)
resp = self.llm_chain.predict(text=context, query=query)
return resp
'''
def _call_func(self, query) -> str:
self.get_llm_chain()
context = DeepSearch.search(query = query)
resp = self.llm_chain.predict(text=context, query=query)
return resp
def get_llm_chain(self):
if not self.llm_chain:
self.llm_chain = LLMChain(llm=self.llm, prompt=self.prompt)
class Search_www_Tool(functional_Tool):
llm: BaseLanguageModel
# tool description
name = "互联网检索查询"
description = "用户输入的问题是一些常识,实事问题,无法直接给出答案,可以用互联网检索查询来获取相关信息"
# QA params
qa_template = """
请根据下面信息```{text}```,回答问题:{query}
"""
prompt = PromptTemplate.from_template(qa_template)
llm_chain: LLMChain = None
'''
def _run(self, query: str, run_manager: Optional[CallbackManagerForToolRun] = None):
self.get_llm_chain()
context = DeepSearch.search(query = query)
resp = self.llm_chain.predict(text=context, query=query)
return resp
'''
def _call_func(self, query) -> str:
self.get_llm_chain()
context = DeepSearch.search(query = query)
resp = self.llm_chain.predict(text=context, query=query)
return resp
def get_llm_chain(self):
if not self.llm_chain:
self.llm_chain = LLMChain(llm=self.llm, prompt=self.prompt)agent
agent这部分的代码逻辑就是:
1.把封装好的chatglm的llm控制引擎即成进来作为控制和管理核心
2.把toolset融合进来,根据llm控制引擎需要扩展能力,plan方法的AgentAction实现
3.根据业务需来设计引擎控制逻辑,这部分在下面代码对应的就是通过intent_template来写策略,通过choose_tools来实现根据用户输入选择调用tool
from typing import List, Tuple, Any, Union
from langchain.schema import AgentAction, AgentFinish
from langchain.agents import BaseSingleActionAgent
from langchain import LLMChain, PromptTemplate
from langchain.base_language import BaseLanguageModel
class IntentAgent(BaseSingleActionAgent):
tools: List
llm: BaseLanguageModel
intent_template: str = """
现在有一些意图,类别为{intents},你的任务是根据用户的query内容找到最匹配的意图类;回复的意图类别必须在提供的类别中,并且必须按格式回复:“意图类别:<>”。
举例:
问题:请给年轻用户生成10条金融产品营销文案?
意图类别:产品卖点查询
问题:世界最高峰?
意图类别:互联网检索查询
问题:“{query}”
"""
prompt = PromptTemplate.from_template(intent_template)
llm_chain: LLMChain = None
def get_llm_chain(self):
if not self.llm_chain:
self.llm_chain = LLMChain(llm=self.llm, prompt=self.prompt)
def choose_tools(self, query) -> List[str]:
self.get_llm_chain()
tool_names = [tool.name for tool in self.tools]
tool_descr = [tool.name + ":" + tool.description for tool in self.tools]
resp = self.llm_chain.predict(intents=tool_names, query=query)
select_tools = [(name, resp.index(name)) for name in tool_names if name in resp]
select_tools.sort(key=lambda x:x[1])
return [x[0] for x in select_tools]
@property
def input_keys(self):
return ["input"]
def plan(
self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any
) -> Union[AgentAction, AgentFinish]:
# only for single tool
tool_name = self.choose_tools(kwargs["input"])[0]
return AgentAction(tool=tool_name, tool_input=kwargs["input"], log="")
async def aplan(
self, intermediate_steps: List[Tuple[AgentAction, str]], **kwargs: Any
) -> Union[List[AgentAction], AgentFinish]:
raise NotImplementedError("IntentAgent does not support async")自定义例子
上面部分的代码,已经把围绕llm引擎打造toolset的基本框架搭建好了。当然世实际的业务应用还需要做亿点点细节开发。下面部分代码就是用一个例子来测试下框架效果。
from langchain.agents import AgentExecutor
from custom_search import DeepSearch
tools = [Search_www_Tool(llm = llm), Actor_knowledge_Tool(llm=llm),Search_www_Tool(llm = llm),Product_knowledge_Tool(llm=llm)]
agent = IntentAgent(tools=tools, llm=llm)
agent_exec = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, max_iterations=1)
agent_exec.run("生成10条描述金融产品卖点的营销文案")
agent_exec.run("四川高考分数线?")
小结:
介绍了围绕LLM引擎打造贴合实际应用生态的重要意义。给出了一个围绕chatglm搭建LLM引擎,围绕chatglm引擎用搜索api打造toolset,通过prompt+LLMchain方式来实现控制策略、实现toolset包括业务逻辑的框架。
1.围绕LLM引擎打造业务生态的意义重大,产业价值和可拓展空间可能会大于LLM引擎本身
2.通过langchain框架,打造chatglm的应用生态框架
3.给出了一个实际测试例子
代码实现在github:https://github.com/liangwq/Chatglm_lora_multi-gpu/tree/main/APP_example/chatglm_agent


![[Mysql] 索引失效的情况详解~](https://img-blog.csdnimg.cn/8c2c00bab9fe4fa8bd815518b1e397c1.png)