专栏导读
🔥🔥本文已收录于专栏:《风格迁移之从入门到成功魔改》,欢迎免费订阅
此专栏用于带你从零基础学会什么是风格迁移,风格迁移有什么作用,传统做法和Cyclegan的原理,及其优缺点,以及最重要的CycleGAN的成功魔改(附代码)。1)环境部署搭建,资源配置
2)风格迁移传统做法,GAN,CycleGAN的原理及其优缺点。
3)代码详细解析
4)根据缺点进行全方面成功魔改的原理。
本文导读
🔥🔥本文的创新点部分,是来自我即将发表的一篇核心文章!!!。 只有淋过雨的孩子才会懂得给别人打伞,所以我开源的目的很简单,希望可以帮助到有缘相遇的初学者快速了解并掌握该方向内容。 有能力的同学可以进行二次改进创新。我的最终模型在定性和定量的评估中效果均有提升!!!。后续代码将更新到GitHub上,如果对大家有帮助,希望可以得到您的免费star✨。本人万分感谢!!!
本文的结构图均为本人绘制,如有需可以私信或评论区留言❤
既然开源也不求回报,创新部分内附代码。如果对你们的科研创新提供了新思路,劳烦点赞收藏一下,赞满100,我将update所有消融实验数据,谢谢!
🔥🔥注:我的论文中将新模型命名为SWLAGAN。(你要问为什么叫这个,其实是我一时兴起瞎起的。哈哈哈)
🔥生成器网络
自注意力机制
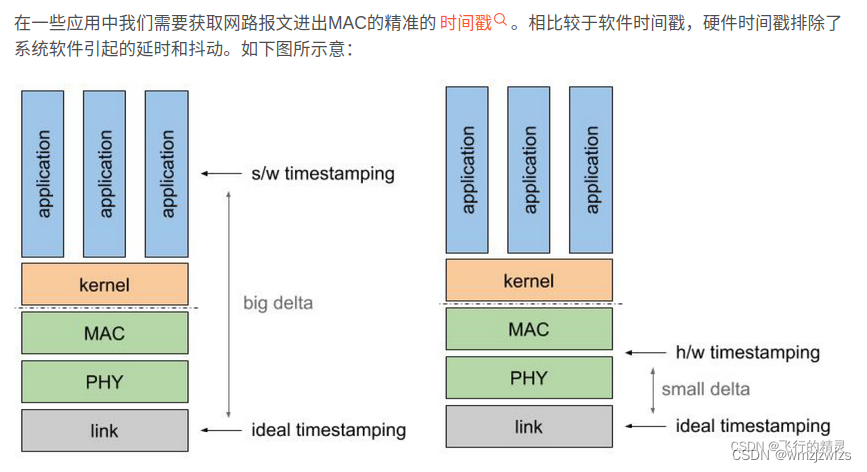
自注意力机制在自然语言处理领域被广泛应用,他可以将输入到全连接神经网络中的多个词语建立语义联系。比如在神经网络中输入多个大小不一的向量,向量之间具有关联,自注意力机制便可以完成多数神经网络都难以实现的向量之间建立关联工作,自注意力机制的算法下图所示。
算法流程如下:图中Q,K,V均是由一组词语表示的输入矩阵X经过线性变化得到,Q和K负责建立词语之间的语义关联,通过自注意力的核心算法计算出表现语义关联的距离矩阵。将距离矩阵和矩阵V进行矩阵相乘得到了具有全局关联的输出矩阵。
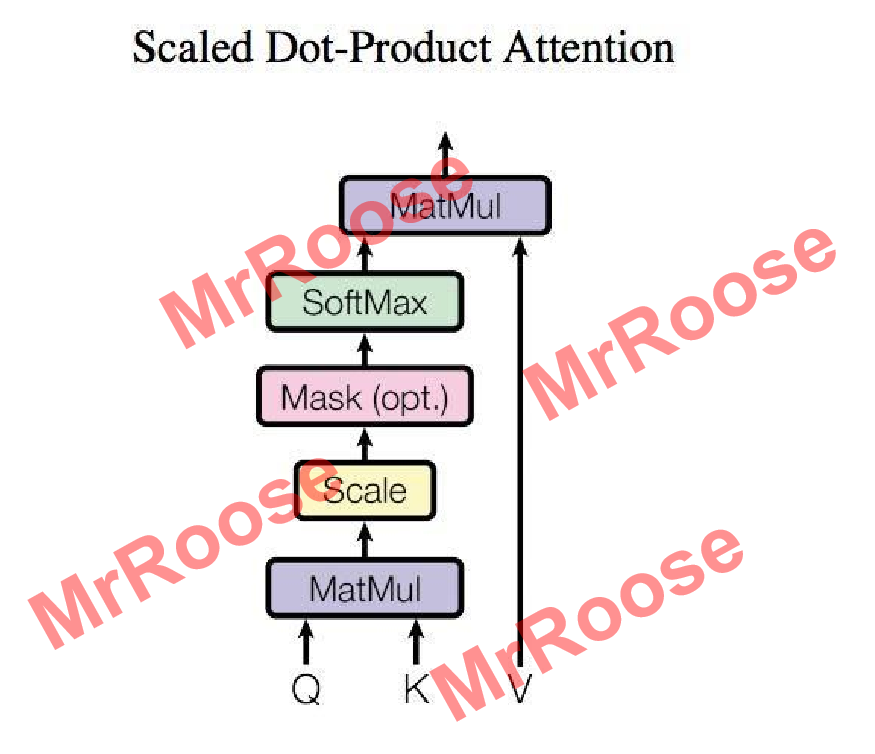
Q,K,V矩阵大小则是由输入矩阵X(X,Q,K,V各行都代表一个词语)经过线性变换而决定的,线性变换矩阵分别为WQ,WK,WV。Q,K,V计算过程图如下图所示。
再计算出矩阵Q,K,V后通过公式得到输出,计算公式如下:
其中是矩阵Q,K的矩阵列数。
通过公式建立词语之间的语义关联,即距离矩阵。其中
的作用是防止Q和K各行内积后,数值过大,而影响语义关联性。Softmax的作用是计算得到每一个词语对应其他词语的关联系数。经过softmax得到的距离矩阵中第i行代表词语i对其他所有词语的关联系数。最后将距离矩阵与V作矩阵相乘得到具有全局关联的输出矩阵。
🔥🔥🔥以下是创新部分的自注意力机制搭建代码:
class Self_Attention(nn.Module):
def __init__(self, in_dim, activation):
super(Self_Attention, self).__init__()
self.chanel_in = in_dim
self.activation = activation
## 下面的query_conv,key_conv,value_conv即对应Wg,Wf,Wh
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1) # 即得到C^ X C
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1) # 即得到C^ X C
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1) # 即得到C X C
self.gamma = nn.Parameter(torch.zeros(1)) # 这里即是计算最终输出的时候的伽马值,初始化为0
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
m_batchsize, C, width, height = x.size()
## 下面的proj_query,proj_key都是C^ X C X C X N= C^ X N
proj_query = self.query_conv(x).view(m_batchsize, -1, width * height).permute(0, 2, 1) # B X CX(N),permute即为转置
proj_key = self.key_conv(x).view(m_batchsize, -1, width * height) # B X C x (*W*H)
energy = torch.bmm(proj_query, proj_key) # transpose check,进行点乘操作
attention = self.softmax(energy) # BX (N) X (N)
proj_value = self.value_conv(x).view(m_batchsize, -1, width * height) # B X C X N
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(m_batchsize, C, width, height)
out = self.gamma * out + x
return out🔥可全局连接的残差网路(SA_Blocks)
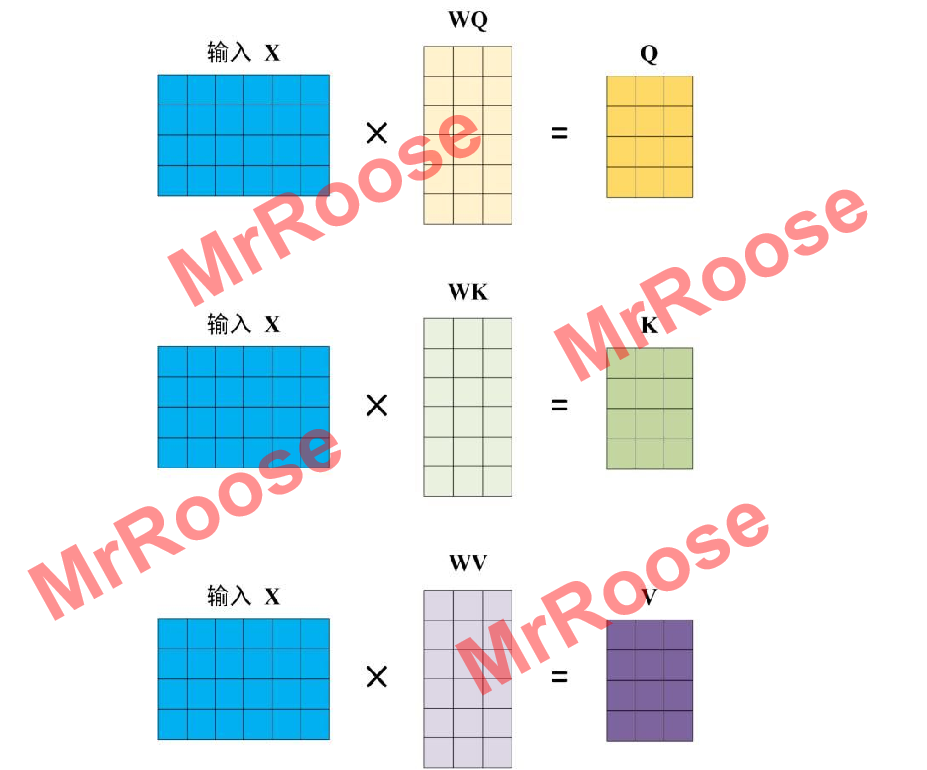
本人提出的残差网络结构将自注意力机制中全局链接的特性与残差网络可以防止网络退化的特性完美结合。改进了原始残差网络被局限在小窗口提取特征的缺陷,增大了特征提取的全局视野的同时,也增加了多尺度不变的特性。SA_Blocks网络结构图如下所示:
SA_Blocks网络结构在继承了原有残差网络的两个3x3卷积层(Conv)外,又增加了一个自注意力层(SEAT),其工作原理是将特征图X(,C为通道数,H为高度,W为宽度)分别通过三个1×1卷积层,得到特征图Q,K,V,其中Q,K的通道数减半,V保持不变(
,
)。由于自注意力机制公式中具有矩阵计算,因此将Q,K,V进行特征转换(
,
,
)。将转换后的Q和K的转置进行特征矩阵相乘,得到了不同通道之间像素点的关联矩阵β(
)。将关联矩阵β归一化后与V进行特征矩阵相乘,得到具有全局连接的特征图X’,为了增加多尺度空间表达能力,又将X’通过一个3×3卷积层得到输出特征图Y,其表达式为:
🔥🔥🔥以下是创新部分的SA_Blocks网络搭建代码:
class SEA_ResnetBlock_1(nn.Module):
def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias):
super(SEA_ResnetBlock_1, self).__init__()
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, use_dropout, use_bias)
self.self_attention=Self_Attention(dim,'relu')
def build_conv_block(self, dim, padding_type, norm_layer, use_dropout, use_bias):
conv_block = []
p = 0
if padding_type == 'reflect':
conv_block += [nn.ReflectionPad2d(1)]
elif padding_type == 'replicate':
conv_block += [nn.ReplicationPad2d(1)]
elif padding_type == 'zero':
p = 1
else:
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim), nn.ReLU(True)]
if use_dropout:
conv_block += [nn.Dropout(0.5)]
p = 0
if padding_type == 'reflect':
conv_block += [nn.ReflectionPad2d(1)]
elif padding_type == 'replicate':
conv_block += [nn.ReplicationPad2d(1)]
elif padding_type == 'zero':
p = 1
else:
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim)]
return nn.Sequential(*conv_block)
def forward(self, x):
out = self.self_attention(x) + self.conv_block(x)+x # add skip connections
return out🔥🔥生成器网络结构
生成器模型采用Auto-Encoder+Skip-connection的网络结构,残差网络模块摒弃了原始残差网络结构,使用本文提出的SA_Blocks结构,其特有的全局连接性弥补了原始残差只能局部提取特征的不足,让模型不仅可以在全局上提取特征还具有了多尺度不变性,使生成的图片质量得到提升,SWLAGAN的生成器网络结构图如下图所示。
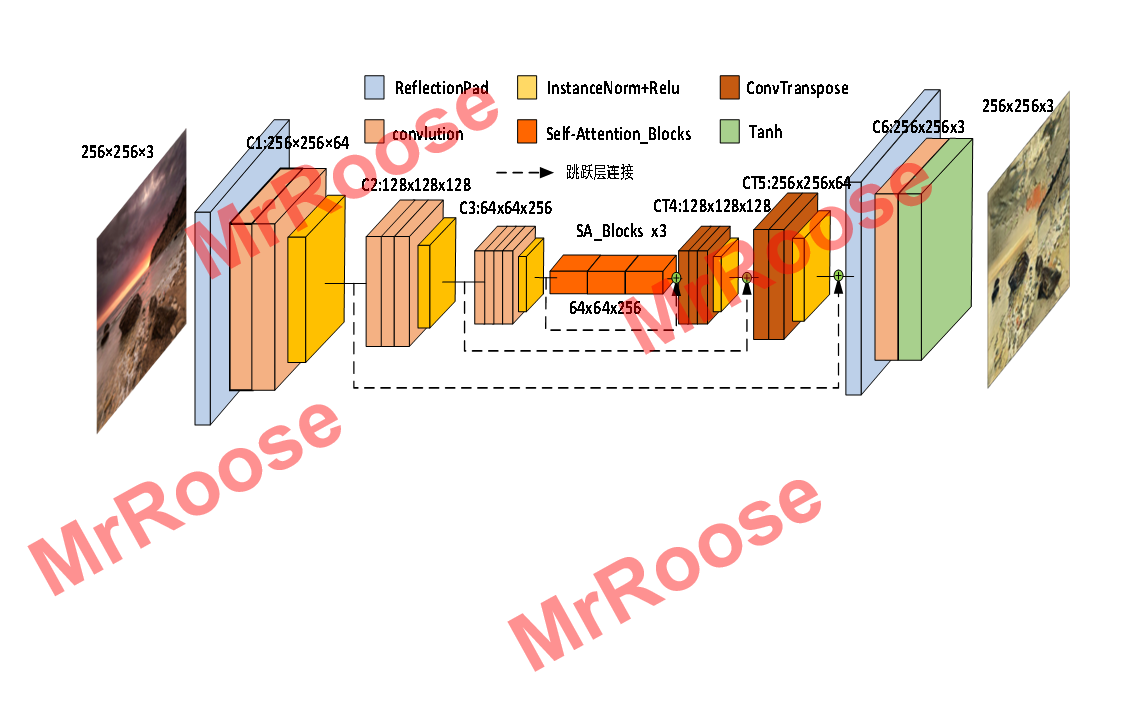
其中蓝色模块是镜像填充层,将对图片四周填充三个像素矩阵的镜像内容;Ci:W×H×C表示目前是第i层卷积,通过该层卷积输出特征图的宽度为W,高度为H,通道数为C;粉色模块是卷积核大小为3,步长为2的卷积操作。褐色模块是卷积核大小为3,步长为1/2的反卷积操作,用来将卷积后的特征图发大。橙色模块是3个连续的SA_Blocks结构,让提取的特征具有全局视野。黄色模块是IN层,将特征图标准化,防止过拟合;虚线部分是将模型中卷积后得到的低级特征与同分辨率下的高级特征进行融合,使模型中各层的特征信息利用率得到提升。
🔥🔥🔥以下是创新部分的生成器构建代码:
class Unet_SEA_ResnetGenerator(nn.Module):
def __init__(self, input_nc, output_nc, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False, n_blocks=6, padding_type='reflect'):
assert(n_blocks >= 0)
super(Unet_SEA_ResnetGenerator, self).__init__()
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
self.pad=nn.ReflectionPad2d(3)
self.Down_conv1=nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=use_bias)#下采样第一层
self.conv_norm=norm_layer(input_nc)
self.relu=nn.ReLU(True)
self.Down_conv2=nn.Conv2d(ngf , ngf * 2, kernel_size=3, stride=2, padding=1, bias=use_bias) #下采样第二层
self.SA=Self_Attention_no_connect(ngf*2,'relu')
self.Down_conv3=nn.Conv2d(ngf*2 , ngf * 4, kernel_size=3, stride=2, padding=1, bias=use_bias) #下采样第三层
self.Sa_block_3=SEA_Block_3(ngf * 4, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout,use_bias=use_bias)
self.Sa_resnetblock_1=SEA_ResnetBlock_1(ngf * 4, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout,use_bias=use_bias)
self.resnet=ResnetBlock(ngf * 4, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout, use_bias=use_bias)
self.Up_conv1=nn.ConvTranspose2d(ngf * 4*2, ngf * 2 , kernel_size=3, stride=2,padding=1, output_padding=1,bias=use_bias)
self.Up_conv2=nn.ConvTranspose2d(ngf * 2*2, ngf, kernel_size=3, stride=2,padding=1, output_padding=1,bias=use_bias)
self.Up_conv3=nn.Conv2d(ngf*2, output_nc, kernel_size=7, padding=0)
self.tan=nn.Tanh()
def forward(self, x):
x1=self.relu(self.conv_norm(self.Down_conv1(self.pad(x))))
x2=self.relu(self.conv_norm(self.Down_conv2(x1)))
x3=self.relu(self.conv_norm(self.Down_conv3(x2)))
x4=self.resnet(x3)
x=torch.cat([x4,x3],1)
x=self.relu(self.conv_norm(self.Up_conv1(x)))
x=torch.cat([x,x2],1)
x=self.relu(self.conv_norm(self.Up_conv2(x)))
x=torch.cat([x,x1],1)
x=self.tan(self.Up_conv3(self.pad(x)))
return x🔥🔥判别器网络
判别器网络,使用Auto-Encoder的网络结构代替原始结构,其核心优势在于判别器的训练不再受到生成器的约束,可以先训练判别器,通过判别器的优化来刺激生成器的训练。进而解决了原始模型会产生的训练不平衡问题,SWLAGAN的判别器网络结构图如下图所示。

判别器在上采样过程中使用扩充加卷积操作来代替反卷积。其中黄色模块表示卷积层,卷积核大小为w,d=(a,b)表示特征图的通道数从a变化为b。Full connected表示全连接层。Subsampling表示平均池化操作。NN Upsampling表示临近点填充层,将图片的四周填充图片对应位置的像素内容。
新判别器可以不受生成器的约束而提前训练,并且还可以带动生成器训练的原理为:假设现在有三张图片,一张是输入x,一张是经过D编码解码后的图片D(x),还有一张是先经过G生成,又经过D编码解码后得到的图片D(G(y))。随着网络的训练,G和D逐渐达到纳什平衡,即,D是通过真实数据分布训练,导致D(x)分布会无限接近x分布,即
。通过极限的思想可得
。此时的x分布将无限接近G(y)分布,此时G便学习到了y源分布到x源分布的映射关系,G和D达到纳什平衡。
🔥🔥🔥以下是创新部分的判别器构建代码:
class Discriminator(nn.Module):
def __init__(self,input_nc,ndf=64,n_layers=3, norm_layer=nn.BatchNorm2d):
super(Discriminator,self).__init__()
# 256 x 256
self.conv1 = nn.Sequential(nn.Conv2d(input_nc,ndf,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
conv_block(ndf,ndf))
# 128 x 128
self.conv2 = conv_block(ndf, ndf*2)
# 64 x 64
self.conv3 = conv_block(ndf*2, ndf*3)
# 32 x 32
self.conv4 = conv_block(ndf*3, ndf*4)
# 16 x 16
self.conv5=conv_block(ndf*4,ndf*5)
# 8 x 8
self.conv6 = nn.Sequential(nn.Conv2d(ndf*5,ndf*5,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(ndf*5,ndf*5,kernel_size=3,stride=1,padding=1),
nn.ELU(True))
self.embed1 = nn.Linear(ndf*5*8*8, 64)
self.embed2 = nn.Linear(64, ndf*8*8)
# 8 x 8
self.deconv1 = deconv_block(ndf, ndf)
# 16 x 16
self.deconv2 = deconv_block(ndf, ndf)
# 32 x 32
self.deconv3 = deconv_block(ndf, ndf)
# 64 x 64
self.deconv4 = deconv_block(ndf, ndf)
# 128 x 128
self.deconv5 = deconv_block(ndf, ndf)
# 256 x 256
self.deconv6 = nn.Sequential(nn.Conv2d(ndf,ndf,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(ndf,ndf,kernel_size=3,stride=1,padding=1),
nn.ELU(True),
nn.Conv2d(ndf, input_nc, kernel_size=3, stride=1, padding=1),
nn.Tanh())
self.ndf = ndf
def forward(self,x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.conv4(out)
out = self.conv5(out)
out=self.conv6(out)
out = out.view(out.size(0), self.ndf*5 * 8 * 8)
out = self.embed1(out)
out = self.embed2(out)
out = out.view(out.size(0), self.ndf, 8, 8)
out = self.deconv1(out)
out = self.deconv2(out)
out = self.deconv3(out)
out = self.deconv4(out)
out = self.deconv5(out)
out = self.deconv6(out)
return out🔥🔥损失函数部分
🔥🔥循环一致性损失LPIPS
对于我们人类来说,评估两张图片的感知相似度是一件极其简单的事情,但其中的原理却极其复杂。以前很多学者喜欢使用L2范数,PSNR,SSIM等感知指标函数来复现人类感知图片这种行为。直到LPIPS的出现打破了这种现状,其在无监督模型上学习到的特征在模型低层次感知相似性上比L2范数等损失函数要强很多,在2018年PIRM感知图像超分辨率挑战赛中众多学者联合比较了各损失函数的性能,通过把多个感知模型的计算结果与真实结果进行拟合画线,得到了8张对比图如下图所示。
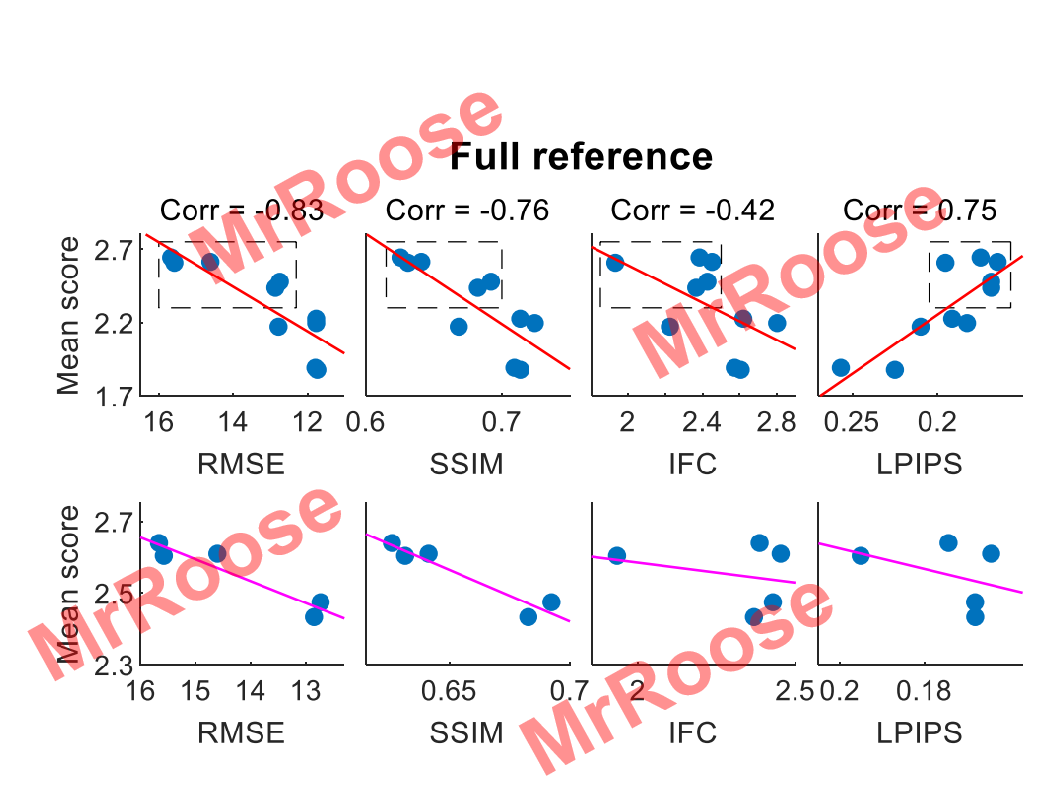
图中Corr代表模型评估的分数和人的主观审美的相似度。其范围在[-1,1],越接近1代表越接近人的主观审美。从图可知,只有LPIPS的评估是正相关,其余都是负相关,所以在感知相似度函数中LPIPS的计算误差是最小的。LPIPS网络结构图如下图所示。
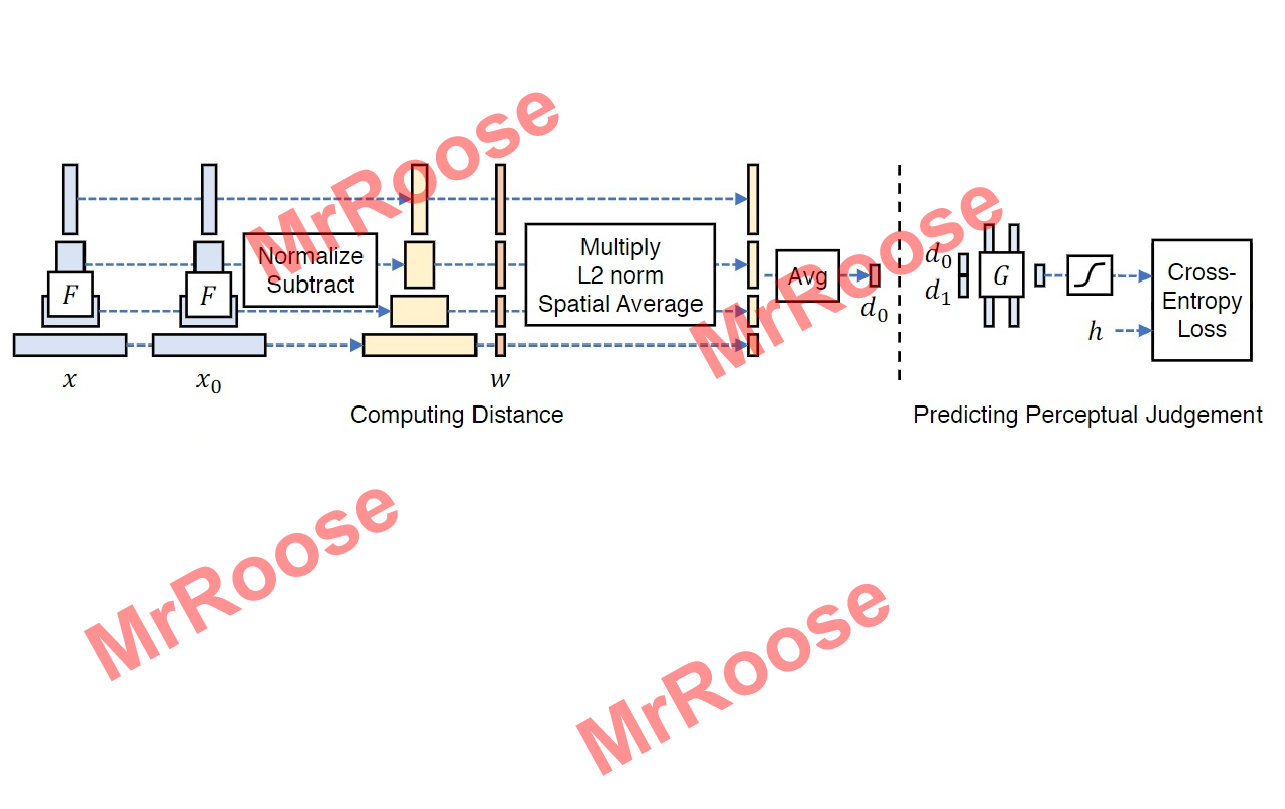
基本原理是将真实图片x与待测图片x0分别带入网络F中进行特征提取,在不同的通道中计算x和x0的特征之间的距离;在不同的卷积层中(这里举例为L层)提取特征堆栈,将不同的通道中特征堆栈进行归一化,此时的结果记为,又通过向量
进行缩放激活通道,使用L2范数计算的距离,并在空间中求平均值,在通道上求和计算出d0。公式如下所示:
其中等同于通过余弦距离公式计算的结果。最后把d0和真实的d1传到含有两个32个通道的RELU全连接层、一个单通道全连接层和一个sigmoid层的模型中训练,其相似性损失函数为:
🔥🔥🔥以下是创新部分的循环一致损失函数LPIPS的构建代码:
self.criterionCycle=lpips.LPIPS(net='alex').to(self.device)
self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * 2
self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * 2🔥🔥对抗损失WGAN-GP
Wasserstein距离也叫做Earth-Mover(推土机)距离,其公式如下:
其中代表两种数据分布,并且都是
中的任何一个边缘分布。当r属于联合分布时,真实数据x和生成数据y将从r中采样,
代表真实数据和生成数据的误差,因此当x和y属于所有联合分布时,求得
的期望下界值便是Wasserstein距离。
Lipschitz连续是指在一个连续函数f中,存在一个常数K,且K≥0。使得定义域内任意的x1和x2都满足不等式。且K称为f的Lipschitz常数。
WGAN的目标函数便是基于Wasserstein距离得来的。由于Wasserstein距离公式中有因此无法直接求导,经证明,可将上式转换为下述公式:
又使用参数w定义函数来重新定义公式,近似的公式如下:
可以通过训练含有参数w的神经网络来表示,随着训练次数不不断增加,网络拟合能力增强,最终网络会拟合出
的情况。又防止K值多大而控制网络的所有参数w在[-c,c]之间,使得输入数据x的偏导数
也可以被控制在固定范围内,使模型梯度变化相对稳定。由于Lipschitz连续的条件得到了满足,此时Wasserstein距离便可以用下面公式近似表示:
同GAN原理一样,WGAN中的生成器也是MIN~G,判别器也是MAX~D。所以WGAN的生成器公式如下:
WGAN的判别器公式如下:
如果只进行权重裁剪(c的赋值)会出现两个问题。第一个问题是,神经网络的参数被控制在某个范围内,从而会使全权重分布严重不均,会出现很多极端的参数值。如下图所示,如果权重都集中徘徊在0.01和-0.01两个点,神经网络拟合的能力将会被削弱。
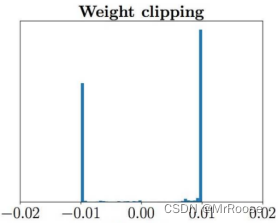
第二个问题在于模型会产生很强的梯度爆炸或者梯度消失,如果权重裁剪过小会出现梯度消失,过大则又会出现梯度爆炸,这两种情况都会导致网络训练极不稳定。
为了解决这些问题,WGAN-GP在原有WGAN的基础上增加梯度惩罚机制,在满足Lipschitz连续条件的同时,通过对梯度变化的约束,使梯度和K之间建立起联系,下面是限制判别器的梯度不能大于K的公式:
随着判别器的判别能力增强,其梯度也会增加,训练结束后,梯度会无限接近K,因此公式可以优化为:
将K=1的梯度惩罚机制与WGAN的损失加权求和得到WGAN-GP的损失函数:
又结合CycleGAN的双生成对抗网络原理,建立两个生成对抗损失,一个是通过G实现X源域转为Y源域的损失公式:
另一个是通过F实现Y源域转为X源域的损失公式:
因此总的对抗损失公式为:
SWLAGAN的总体损失函数为:
🔥🔥🔥以下是创新部分的对抗损失函数的构建代码:
def gradient_penalty(self,netD,real,fake):
BATCH_SIZE,C,H,W=real.shape
epsilon = torch.rand((BATCH_SIZE,1,1,1)).repeat(1,C,H,W).to(self.device)
interpolated_images=real*epsilon*fake*(1-epsilon)
mixed_scores=netD(interpolated_images)
gradient=torch.autograd.grad(
inputs=interpolated_images,
outputs=mixed_scores,
grad_outputs=torch.ones_like(mixed_scores),
create_graph=True,
retain_graph=True,
)[0]
gradient=gradient.view(gradient.shape[0],-1)
gradient_penalty=((gradient.norm(2,dim=1)-1)**2).mean()
return gradient_penalty🔥🔥🔥SWLAGAN模型训练结构图
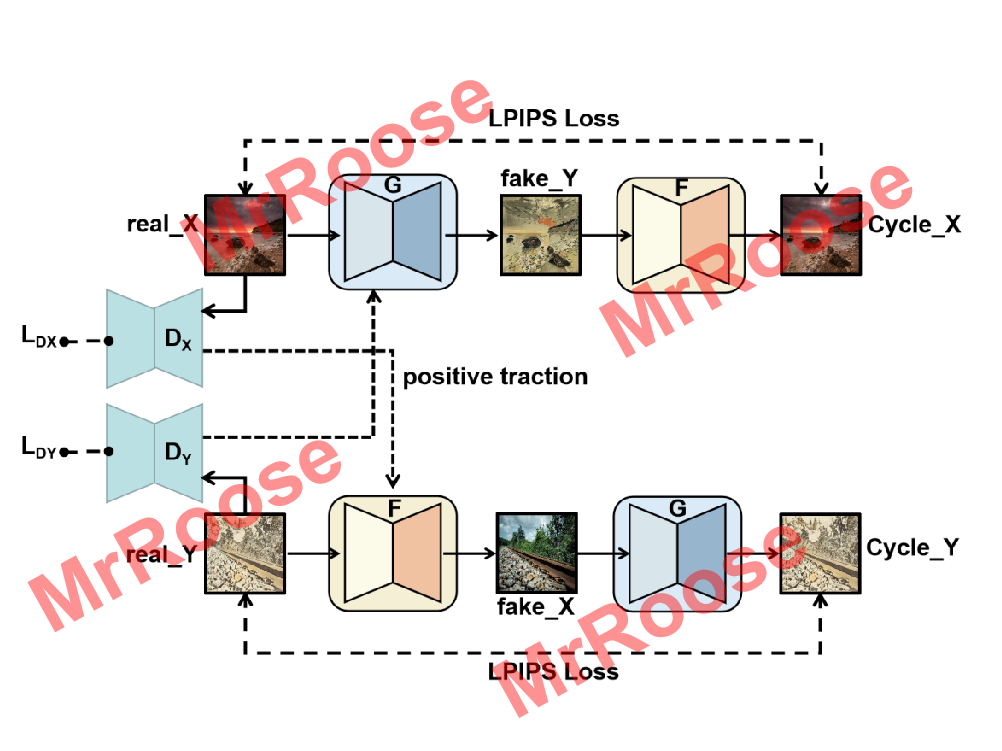
🔥🔥训练模型的Trick
Trick1:Label平滑
如果有两个目标label:Real=1 和 Fake=0,那么对于每个新样本,如果是real,那么把label替换为0.7~1.2之间的随机值;如果样本是fake,那么把label替换为0.0~0.3之间的随机值。
在models/networks.py中的GANLoss类中的__init__函数中进行修改:
原代码:
def __init__(self, gan_mode, target_real_label=1.0, target_fake_label=0.0):
super(GANLoss, self).__init__()
self.register_buffer('real_label', torch.tensor(target_real_label))
self.register_buffer('fake_label', torch.tensor(target_fake_label))
self.gan_mode = gan_mode
if gan_mode == 'lsgan':
self.loss = nn.MSELoss()
elif gan_mode == 'vanilla':
self.loss = nn.BCEWithLogitsLoss()
elif gan_mode in ['wgangp']:
self.loss = None
else:
raise NotImplementedError('gan mode %s not implemented' % gan_mode)修改后的代码:
def __init__(self, gan_mode):
super(GANLoss, self).__init__()
target_real_label = random.randint(7, 12) * 0.1
target_fake_label = random.randint(0, 3) * 0.1
self.register_buffer('real_label', torch.tensor(target_real_label))
self.register_buffer('fake_label', torch.tensor(target_fake_label))
self.gan_mode = gan_mode
if gan_mode == 'lsgan':
self.loss = nn.MSELoss()
elif gan_mode == 'vanilla':
self.loss = nn.BCEWithLogitsLoss()
elif gan_mode in ['wgangp']:
self.loss = None
else:
raise NotImplementedError('gan mode %s not implemented' % gan_mode)Trick2:将图像输入鉴别器之前,将噪声添加到实际图像和生成的图像中
在models/cycle_gan_model.py中的CycleGANModle类中的backward_D_A函数和backward_D_B函数修改
原代码:
def backward_D_A(self):
"""Calculate GAN loss for discriminator D_A"""
fake_B = self.fake_B_pool.query(self.fake_B)
self.loss_D_A = self.backward_D_basic(self.netD_A, self.real_B, fake_B)
def backward_D_B(self):
"""Calculate GAN loss for discriminator D_B"""
fake_A = self.fake_A_pool.query(self.fake_A)
self.loss_D_B = self.backward_D_basic(self.netD_B, self.real_A, fake_A)修改后代码:
def backward_D_A(self):
"""Calculate GAN loss for discriminator D_A"""
real_B=self.real_B #(B C H W)
fake_B = self.fake_B_pool.query(self.fake_B) #(B C H W)
###给fake_B添加噪点
BatchSize_fake,C_fake,H_fake,W_fake=fake_B.size()
img_fake=fake_B.view(H_fake,W_fake,C_fake) #(H W C)
img_fake_np=img_fake.numpy() #将(H W C)的Tensor转为(H W C)的numpy
h_fake,w_fake,c_fake=img_fake_np.shape
Nd = 0.1
Sd = 1 - Nd
mask_fake = np.random.choice((0, 1, 2), size=(h_fake, w_fake, 1), p=[Nd / 2.0, Nd / 2.0, Sd]) # 生成一个通道的mask
mask_fake = np.repeat(mask_fake, c_fake, axis=2) # 在通道的维度复制,生成彩色的mask
img_fake_np[mask_fake==0]=0
img_fake_np[mask_fake==1]=255
img_fake_Tensor=torch.from_numpy(img_fake_np) #(H W C)numpy转为(H W C)的Tensor
H1_fake,W1_fake,C1_fake=img_fake_Tensor.size()
fake_B=img_fake_Tensor.view(BatchSize_fake,C1_fake,H1_fake,W1_fake) #将(H W C)的Tensor转为(B C H W)的Tensor
###给real_B添加噪点
BatchSize_real, C_real, H_real, W_real = real_B.size()
img_real = real_B.view(H_real, W_real, C_real)
img_real_np = img_real.numpy()
h_real, w_real, c_real = img_real_np.shape
mask_real = np.random.choice((0, 1, 2), size=(h_real, w_real, 1), p=[Nd / 2.0, Nd / 2.0, Sd]) # 生成一个通道的mask
mask_real = np.repeat(mask_real, c_real, axis=2) # 在通道的维度复制,生成彩色的mask
img_real_np[mask_real == 0] = 0
img_real_np[mask_real == 1] = 255
img_real_Tensor=torch.from_numpy(img_real_np)
H1_real,W1_real,C1_real=img_real_Tensor.size()
real_B=img_real_Tensor.view(BatchSize_real,C1_real,H1_real,W1_real)
self.loss_D_A = self.backward_D_basic(self.netD_A, real_B, fake_B)
def backward_D_B(self):
"""Calculate GAN loss for discriminator D_B"""
real_A=self.real_A
fake_A = self.fake_A_pool.query(self.fake_A)
###给fake_A添加噪点
BatchSize_fake, C_fake, H_fake, W_fake = fake_A.size()
img_fake = fake_A.view(H_fake, W_fake, C_fake)
img_fake_np = img_fake.numpy()
h_fake, w_fake, c_fake = img_fake_np.shape
Nd = 0.1
Sd = 1 - Nd
mask_fake = np.random.choice((0, 1, 2), size=(h_fake, w_fake, 1), p=[Nd / 2.0, Nd / 2.0, Sd]) # 生成一个通道的mask
mask_fake = np.repeat(mask_fake, c_fake, axis=2) # 在通道的维度复制,生成彩色的mask
img_fake_np[mask_fake == 0] = 0
img_fake_np[mask_fake == 1] = 255
img_fake_Tensor = torch.from_numpy(img_fake_np)
H1_fake, W1_fake, C1_fake = img_fake_Tensor.size()
fake_B = img_fake_Tensor.view(BatchSize_fake, C1_fake, H1_fake, W1_fake)
###给real_A添加噪点
BatchSize_real, C_real, H_real, W_real = real_A.size()
img_real = real_A.view(H_real, W_real, C_real)
img_real_np = img_real.numpy()
h_real, w_real, c_real = img_real_np.shape
mask_real = np.random.choice((0, 1, 2), size=(h_real, w_real, 1), p=[Nd / 2.0, Nd / 2.0, Sd]) # 生成一个通道的mask
mask_real = np.repeat(mask_real, c_real, axis=2) # 在通道的维度复制,生成彩色的mask
img_real_np[mask_real == 0] = 0
img_real_np[mask_real == 1] = 255
img_real_Tensor = torch.from_numpy(img_real_np)
H1_real, W1_real, C1_real = img_real_Tensor.size()
real_B = img_real_Tensor.view(BatchSize_real, C1_real, H1_real, W1_real)
self.loss_D_B = self.backward_D_basic(self.netD_B, real_A, fake_A)加噪点思路:参考了该文章的椒盐噪点
并且由于fake_A等变量是(B,C,H,W)的Tensor,而文章中的算法是基于numpy,因此只需要将fake_A等变量先从Tensor->numpy->算法->Tensor
Trick3: 判别器的优化频率高于生成器。
原代码中判别器的训练次数和生成器的训练次数的比例是1:1,即每一个epoch的时候只训练一次Generator和Discriminator。现在我尝试一个epoch的时候,训练一次Generator,然后用其生成的fake图片训练3次Discriminator。
原理:1)Trick2的噪点会使Discriminator难以训练。
2)多训练Discriminator,能够刺激Generator模型的训练从而生成好的效果图。
在models/cycle_gan_model.py中的CycleGANModel类中的optimize_parameters函数中进行修改
原代码:
def optimize_parameters(self):
# forward
self.forward() # compute fake images and reconstruction images.
# G_A and G_B
self.set_requires_grad([self.netD_A, self.netD_B], False) # Ds require no gradients when optimizing Gs
self.optimizer_G.zero_grad() # set G_A and G_B's gradients to zero
self.backward_G() # calculate gradients for G_A and G_B
self.optimizer_G.step() # update G_A and G_B's weights
# D_A and D_B
self.set_requires_grad([self.netD_A, self.netD_B], True)
self.optimizer_D.zero_grad() # set D_A and D_B's gradients to zero
self.backward_D_A() # calculate gradients for D_A
self.backward_D_B() # calculate graidents for D_B
self.optimizer_D.step() # update D_A and D_B's weights修改后的代码:
def optimize_parameters(self):
# forward
self.forward() # compute fake images and reconstruction images.
# G_A and G_B
self.set_requires_grad([self.netD_A, self.netD_B], False) # Ds require no gradients when optimizing Gs
self.optimizer_G.zero_grad() # set G_A and G_B's gradients to zero
self.backward_G() # calculate gradients for G_A and G_B
self.optimizer_G.step() # update G_A and G_B's weights
# D_A and D_B
self.set_requires_grad([self.netD_A, self.netD_B], True)
for i in range(3):
self.optimizer_D.zero_grad() # set D_A and D_B's gradients to zero
self.backward_D_A() # calculate gradients for D_A
self.backward_D_B() # calculate graidents for D_B
self.optimizer_D.step() # update D_A and D_B's weights🔥🔥🔥🔥成果展示
🔥🔥由于要忙一些其他事情,这篇论文其实还未发表,一拖再拖。但很多小伙伴在后台私信问我细节。我就把绝大多数的创新细节都开源分享给大家了。实验数据这部分因为论文原因暂不公布。给大家看几张效果图。等后续我再update。
🔥🔥这是其中的一个实验春天和秋天的风格转换:



![re学习(18)[ACTF新生赛2020]rome1(Z3库+window远程调试)](https://img-blog.csdnimg.cn/cfa6acd79396412c95aaf4785927750a.png)