目录
- 前言
- 1. onnx
- 1.1 导出onnx
- 1.2 读取onnx
- 1.3 创建onnx
- 1.4 编辑onnx
- 1.5 onnx总结
- 1.6 本节知识点
- 2. 补充知识
- 2.1 Protobuf
- 2.1.1 Protobuf简介
- 2.1.2 基本使用流程
- 总结
前言
杜老师推出的 tensorRT从零起步高性能部署 课程,之前有看过一遍,但是没有做笔记,很多东西也忘了。这次重新撸一遍,顺便记记笔记。
本次课程学习 tensorRT 基础-onnx 文件及其结构的学习,编辑修改 onnx
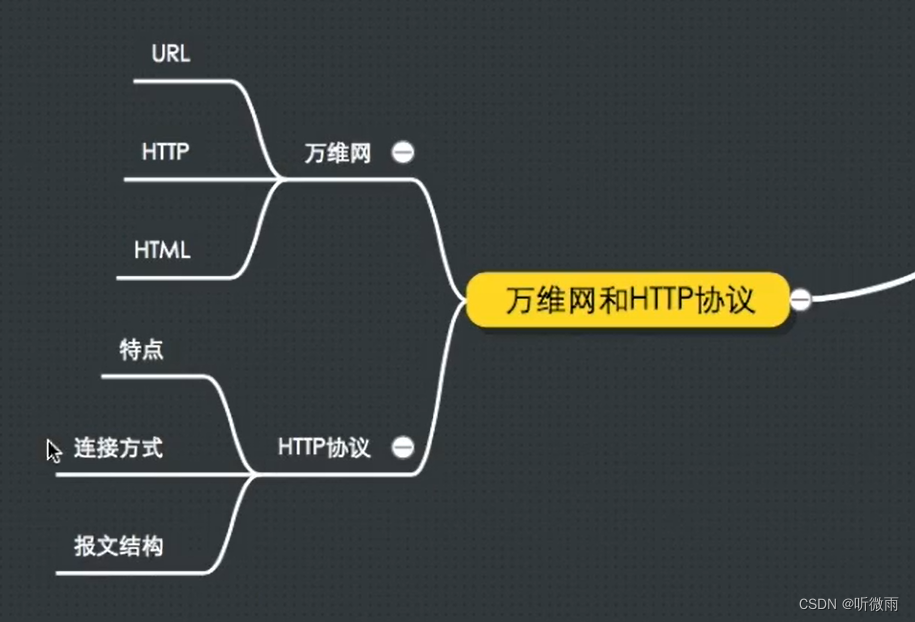
课程大纲可看下面的思维导图

1. onnx
1.1 导出onnx
onnx 是什么?我们先来解决这个问题
onnx 是 Microsoft 开发的一种中间格式的模型
onnx 可以理解为一种通用货币,开发者可以把自己开发训练好的模型保存为 onnx 文件,比如 pytorch 训练的模型导出为 onnx,tensorflow 训练的模型也可以导出为 onnx,caffe 框架训练的模型同样也可以导出 onnx,onnx 类似一把万能钥匙,能打开不同训练框架的门
导出的 onnx 模型可以很方便的被部署工程师借助部署框架(如 tensorRT、openvino、ncnn 等)部署在不同的硬件平台上,而不必关心开发者使用的是哪一种框架,也就是说部署工程师不需要为不同的框架训练的模型做不同的部署,通过 onnx 这个桥梁可以把它们都统一起来,我只需要关注 onnx 部署就行了,而不去关注 pt、uff、caffe 模型的部署,毕竟你们都可以转化为 onnx,大大方便了部署工程师的工作😂
先执行 pytorch-gen-onnx.py 示例代码,内容如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.onnx
import os
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(1, 1, 3, padding=1)
self.relu = nn.ReLU()
self.conv.weight.data.fill_(1)
self.conv.bias.data.fill_(0)
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
# 这个包对应opset11的导出代码,如果想修改导出的细节,可以在这里修改代码
# import torch.onnx.symbolic_opset11
print("对应opset文件夹代码在这里:", os.path.dirname(torch.onnx.__file__))
model = Model()
dummy = torch.zeros(1, 1, 3, 3)
torch.onnx.export(
model,
# 这里的args,是指输入给model的参数,需要传递tuple,因此用括号
(dummy,),
# 储存的文件路径
"demo.onnx",
# 打印详细信息
verbose=True,
# 为输入和输出节点指定名称,方便后面查看或者操作
input_names=["image"],
output_names=["output"],
# 这里的opset,指,各类算子以何种方式导出,对应于symbolic_opset11
opset_version=11,
# 表示他有batch、height、width3个维度是动态的,在onnx中给其赋值为-1
# 通常,我们只设置batch为动态,其他的避免动态
dynamic_axes={
"image": {0: "batch", 2: "height", 3: "width"},
"output": {0: "batch", 2: "height", 3: "width"},
}
)
print("Done.!")
上述代码展示了如何使用 PyTorch 将模型导出为 ONNX 格式。通过使用 torch.onnx.export 函数,可以指定模型、输入参数、输出文件路径等参数来进行导出。
我们的目的是将 pytorch 模型导出为 onnx,导出的 onnx 长什么样子呢?

从图中可以看到它有个 image 作为输入,其大小为 [batch,1,height,width],后面有个 Conv 算子,还有个 ReLU 节点,最后是我们的输出。值得注意的是,在 onnx 里面,如果某个维度是用字母或者 -1 来表示则表明这个维度是动态的。
onnx 里面是储存了模型的整个结构,我们学习本节主要目的是了解 onnx 是如何储存模型的信息的,onnx 的格式实际上是由什么东西组成的。
关于 onnx 你需要了解:
1、 ONNX 的本质,是一种 Protobuf 格式的文件。我们上面看到的模型其实就是 Protobuf 序列化后储存的东西
2、 Protobuf 则通过 onnx-ml.proto 文件得到 onnx-ml.pb.h 和 onnx-ml.pb.cc 用于 C++ 调用或 onnx_ml_pb2.py 用于 python 调用。(如下图所示)
3、 编译工具 protoc 通过编译 onnx-ml.proto 得到 onnx-ml.pb.cc 在加上对应的代码就可以操作 onnx 模型文件,实现对应的增删改
4、 onnx-ml.proto 用于描述 onnx 文件是如何组成的,具有什么结构,它是 onnx 经常参照的东西,下面是 onnx-ml.proto 部分内容,参考自 https://github.com/onnx/onnx/blob/main/onnx/onnx-ml.proto
我们来简单理解下上图中的内容。NodeProto 用于描述 onnx 中的节点 node,它有 input 属性,是 repeated 即重复类型,数组;它有 output 属性,也是 repeated 即重复类型,数组;它有 name 属性是 string 类型。
对于 repeated 是数组,对于 optional 则无视它,对于 input = 1 后面的数字是 id 也无视
我们只用关心是否数组,类型是什么


onnx 文件组成如下图所示:

- model:表示整个 onnx 模型,包括图结构和解析器版本、opset 版本、导出程序类型
- opset 版本即 operator 版本号即 pytorch 的 op 版本(操作算子)
- model.graph:表示图结构,通常是 Netron可视化工具 中看到的结构
- model.graph.node:表示图结构中所有节点如 conv、bn、relu 等,存储如 kernel_size、padding、stride 等信息
- model.graph.initializer:权重数据大都存储在这里
- model.graph.input:模型的输入
- model.graph.input:模型的输出
对于 anchor grid 类的常量数据,通常会储存在 model.graph.node 中,并指定类型为 Constant,该类型节点在 Netron 中可视化时不会显示出来
1.2 读取onnx
接下来我们来读下刚才导出的 onnx 模型,读取的代码如下:
import onnx
import onnx.helper as helper
import numpy as np
model = onnx.load("demo.change.onnx")
#打印信息
print("==============node信息")
# print(helper.printable_graph(model.graph))
print(model)
conv_weight = model.graph.initializer[0]
conv_bias = model.graph.initializer[1]
# 数据是以protobuf的格式存储的,因此当中的数值会以bytes的类型保存,通过np.frombuffer方法还原成类型为float32的ndarray
print(f"===================={conv_weight.name}==========================")
print(conv_weight.name, np.frombuffer(conv_weight.raw_data, dtype=np.float32))
print(f"===================={conv_bias.name}==========================")
print(conv_bias.name, np.frombuffer(conv_bias.raw_data, dtype=np.float32))
运行效果如下:

以上示例代码展示了如何使用 onnx 库来加载和解析 ONNX 模型文件。通过使用 onnx.load 函数,可以加载 ONNX 文件,并通过 model.graph 属性访问模型的图结构和初始化参数。在示例中,打印了模型的节点信息以及卷积层的权重和偏置项。使用 np.frombuffer 方法将原始数据转换为 float32 类型的 ndarray。这样可以获取并查看模型的各个参数值。
1.3 创建onnx
接下来我们来学习如何创建 onnx,创建的代码如下:
import onnx # pip install onnx>=1.10.2
import onnx.helper as helper
import numpy as np
# https://github.com/onnx/onnx/blob/v1.2.1/onnx/onnx-ml.proto
nodes = [
helper.make_node(
name="Conv_0", # 节点名字,不要和op_type搞混了
op_type="Conv", # 节点的算子类型, 比如'Conv'、'Relu'、'Add'这类,详细可以参考onnx给出的算子列表
inputs=["image", "conv.weight", "conv.bias"], # 各个输入的名字,结点的输入包含:输入和算子的权重。必有输入X和权重W,偏置B可以作为可选。
outputs=["3"],
pads=[1, 1, 1, 1], # 其他字符串为节点的属性,attributes在官网被明确的给出了,标注了default的属性具备默认值。
group=1,
dilations=[1, 1],
kernel_shape=[3, 3],
strides=[1, 1]
),
helper.make_node(
name="ReLU_1",
op_type="Relu",
inputs=["3"],
outputs=["output"]
)
]
initializer = [
helper.make_tensor(
name="conv.weight",
data_type=helper.TensorProto.DataType.FLOAT,
dims=[1, 1, 3, 3],
vals=np.array([1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], dtype=np.float32).tobytes(),
raw=True
),
helper.make_tensor(
name="conv.bias",
data_type=helper.TensorProto.DataType.FLOAT,
dims=[1],
vals=np.array([0.0], dtype=np.float32).tobytes(),
raw=True
)
]
inputs = [
helper.make_value_info(
name="image",
type_proto=helper.make_tensor_type_proto(
elem_type=helper.TensorProto.DataType.FLOAT,
shape=["batch", 1, 3, 3]
)
)
]
outputs = [
helper.make_value_info(
name="output",
type_proto=helper.make_tensor_type_proto(
elem_type=helper.TensorProto.DataType.FLOAT,
shape=["batch", 1, 3, 3]
)
)
]
graph = helper.make_graph(
name="mymodel",
inputs=inputs,
outputs=outputs,
nodes=nodes,
initializer=initializer
)
# 如果名字不是ai.onnx,netron解析就不是太一样了
opset = [
helper.make_operatorsetid("ai.onnx", 11)
]
# producer主要是保持和pytorch一致
model = helper.make_model(graph, opset_imports=opset, producer_name="pytorch", producer_version="1.9")
onnx.save_model(model, "my.onnx")
print(model)
print("Done.!")
创建的 onnx 如下图所示,符合我们的预期:

以上示例代码演示了如何从头创建一个简单的 ONNX 模型。首先,定义了一个包含两个节点的图结构。每个节点都由 helper.make_node 函数创建,指定了节点的名称、算子类型、输入、输出和其他属性。在示例中,第一个节点是卷积层(Conv),第二个节点是ReLU激活函数层(Relu)。
接下来,定义了模型的初始化参数,使用 helper.make_tensor 函数创建了权重和偏置项的张量。这些张量包含了参数的名称、数据类型、维度和原始数据。
然后,定义了输入和输出的信息,使用 helper.make_value_info 函数创建了输入和输出的张量类型信息。
最后,使用 helper.make_graph 函数创建了图结构,并通过 helper.make_model 函数创建了完整的模型。模型中指定了使用的算子集合(opset)和制作工具的名称和版本。
最终,使用 onnx.save_model 函数将模型保存为 ONNX 文件。
整个过程是通过使用 onnx 库提供的 helper 函数和数据结构来构建模型的图结构、参数和元数据,从而创建一个完整的 ONNX 模型。
通过打印模型,可以查看模型的结构和元数据信息。
1.4 编辑onnx
接下来我们来学习如何编辑 onnx,编辑的代码如下:
import onnx
import onnx.helper as helper
import numpy as np
model = onnx.load("demo.onnx")
# 可以取出权重
conv_weight = model.graph.initializer[0]
conv_bias = model.graph.initializer[1]
# 修改权
conv_weight.raw_data = np.arange(9, dtype=np.float32).tobytes()
# 修改权重后储存
onnx.save_model(model, "demo.change.onnx")
print("Done.!")
以上示例代码演示了如何编辑已有的 ONNX 模型。首先,使用 onnx.load 函数加载了原始的 ONNX 模型。
然后,通过访问模型的 graph.initializer 属性,可以获取到模型的权重张量。在代码中,使用 model.graph.initializer[0] 获取到了第一个权重张量。
接下来,可以通过修改权重张量的 raw_data 属性来改变权重的数值。在示例中,使用 np.arange 函数生成了一个新的浮点数数组,然后将该数组通过 tobytes 方法转换为 bytes 类型,并赋值给了权重张量的 raw_data 属性。
最后,使用 onnx.save_model 函数将修改后的模型保存为新的 ONNX 文件。
通过这种方式,可以对已有的 ONNX 模型进行权重的修改,从而实现模型的编辑和调整。
1.5 onnx总结
ONNX 重点:
1、 ONNX 的主要结构:graph、graph.node、graph.initializer、graph.input、graph.output
2、 ONNX 的节点创建方式:onnx.helper,各种 make 函数
3、 ONNX 的 proto 文件,https://github.com/onnx/onnx/blob/main/onnx/onnx-ml.proto
4、 理解模型结构的储存、权重的储存、常量的储存、netron 的解读对应到代码中的部分
5、 ONNX 的解析器的理解,包括如何使用 nv 发布的解析器源代码 https://github.com/onnx/onnx-tensorrt
1.6 本节知识点
关于本次课程的知识点有:(from 杜老师)
本节视频辅助讲解
1、为什么要编辑 onnx
2、pytorch 生成 onnx
3、读取 onnx
4、编辑和创建 onnx
本节主要讲解 onnx 的原理,文件较多,我们一个个看
1、
pytorch-gen-onnx.py是之前讲过的从 pytorch 转换 onnx 格式的代码2、 通过
onnx-ml.proto和make-onnx-pb.sh了解 onnx 的结构
2.1 onnx 是基于 protobuf 来做数据存储和传输,*.proto 后缀文件,其定义是 protobuf 语法,类似 json
2.2 对于变量结构、类型等,我们可以参照
onnx-ml.proto里面的定义,这个文件有 800 多行,我们只要搞清楚里面的核心部分就行:
ModelProto:当加载了一个 onnx 后,会获得一个ModelProto。它包含一个GraphProto和一些版本,生产者的信息。
GraphProto:包含了四个 repeated 数组(可以用来存放 N 个相同类型的内容,key 值为数字序列类型)。这四个数组分别是 node(NodeProto类型),input(ValueInfoProto类型),output(ValueInfoProto类型)和 initializer(TensorProto类型)
NodeProto:存 node,放了模型中所有的计算节点,语法结构前面有说过
ValueInfoProto:存 input,放了模型的输入节点;存 output,放了模型中所有的输出节点
TensorProto:存 initializer,放了模型的所有权重参数
AttributeProto:每个计算节点中还包含了一个AttributeProto数组,用来描述该节点的属性,比如 Conv 节点或者说卷积层的属性包含 group,pad,strides 等等2.3 通过 protoc 编译
onnx-ml.proto,产生onnx-ml.pb.cc文件bash make-onnx-pb.sh3、
create-onnx.py
3.1
create-onnx.py从零直接创建 onnx,不经过任何框架的转换。通过 import onnx 和 onnx.helper 提供的 make_node,make_graph,make_tensor 等等接口我们可以轻易的完成一个 ONNX 模型的搭建。3.2 需要完成对 node,initializer,input,output,graph,model 的填充
3.3 读懂
create_onnx.py以 make_node 为例:nodes = [ helper.make_node( name="Conv_0", # 节点名字,不要和op_type搞混了 op_type="Conv", # 节点的算子类型, 比如'Conv'、'Relu'、'Add'这类,详细可以参考onnx给出的算子列表 inputs=["image", "conv.weight", "conv.bias"], # 各个输入的名字,结点的输入包含:输入和算子的权重。必有输入X和权重W,偏置B可以作为可选。 outputs=["3"], pads=[1, 1, 1, 1], # 其他字符串为节点的属性,attributes在官网被明确的给出了,标注了default的属性具备默认值。 group=1, dilations=[1, 1], kernel_shape=[3, 3], strides=[1, 1] ),4、
editor-onnx.py
4.1 由于 protobuf 支持任何的语言,我们可以使用 c/c++/python/java/c# 等等实现对 onnx 文件的读写操作
4.2 掌握 onnx 和 helper 实现对 onnx 文件的各种编辑和修改
增:一般伴随增加 node 和 tensor
graph.initializer.append(xxx_tensor) graph.node.insert(0, xxx_node)删:
graph.node.remove(xxx_node)改:
input_node.name = 'data'5、
read-onnx.py
- 5.1 通过
graph可以访问参数,数据是以 protobuf 的格式存储的,因此当中的数值会以 bytes 的类型保存。需要用np.frombuffer方法还原成类型为float32的ndarray。注意还原出来的ndarray是只读的。
2. 补充知识
2.1 Protobuf
前面有提到说 onnx 本质是一种 protobuf 格式的文件,那 protobuf 又是个啥东东?🤔
关于 protubuf 的相关介绍 Copy 自 赵老师的百度Apollo智能驾驶课程,建议看原视频。
2.1.1 Protobuf简介
概念
Protobuf 全称 Protocol buffers,是 Google 研发的一种一种跨语言、跨平台的序列化结构的数据格式,是一个灵活的、高性的用于序列化数据的协议
特点
在序列化数据时常用的数据格式还有 XML、JSON 等,相比较而言,Protobuf 更小、效率更高且使用更为便捷,Protobuf 内置编译器 protoc,可以将 Protobuf 编译成 C++、Python、Java、C#、Go 等多种语言对应的代码,然后可以直接被对应语言使用,轻松实现对数据流的读或写操作而不需要再做特殊解析。
Protobuf 的优点如下:
- 高效——序列化后字节占用空间少,序列化的时间效率高
- 便捷——可以将结构化数据封装为类,使用方便
- 跨语言——支持多种编程语言
- 高兼容性——当数据交互的双方使用同一数据协议,如果一方修改了数据结构,不影响另一方的使用
Protobuf 也有缺点:
- 二进制格式易读性差
- 缺乏自描述
2.1.2 基本使用流程
需求如下
创建一个 protobuf 文件,在该文件中声明学生的姓名、身高、年龄…等信息,然后分别使用 C++ 和 Python 实现学生数据的读写操作。
实现流程如下
- 1.编写 proto 文件
- 2.编译生成对应的 C++ 或 Python 文件
- 3.在 C++ 或 Python 中调用
1.编写 proto 文件,如下所示
// student.proto
// 使用的 proto 版本
syntax = "proto2"
// 包
package person;
//消息 ---message 是关键字,Student 消息名称
message Student{
//字段
//字段格式:字段规则 数据类型 字段名称 字段编号
required string name = 1;
optional unit64 age = 2;
optional double height = 3;
repeated string books = 4;
}
2.编译,指令如下
$ protoc student.proto --cpp_out=./
执行完成后,在当前目录下 student.proto 文件会生成 student.pb.h 和 student.pb.cc,将 .cc 后缀修改为 .cpp 可供C++调用
3.C++ 调用,调用 demo 如下
// test.cpp
#include <student.pb.h>
using namespace std;
using namespace person;
int main(int argc, char const *argv[])
{
// 1. create object
person::Student stu;
// 2. wirte data
stu.set_name("zhangsan");
stu.set_age(18);
stu.set_height(1.75);
stu.add_books("c++");
stu.add_books("python");
// 3. read data
std::string name = stu.name();
uint64_t age = stu.age();
double height = stu.height();
std::cout << name << " == " << age << " == " << height << std::endl;
for (int i = 0; i < stu.books_size(); i++)
{
std::cout << stu.books(i) << "-";
}
std::cout << std::endl;
return 0;
}
CMakeLists.txt 内容如下:
cmake_minimum_required(VERSION 3.0)
project(test)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -pthread -std=c++11")
set(CMAKE_BUILD_TYPE Debug)
set(EXECUTABLE_OUTPUT_PATH ${PROJECT_SOURCE_DIR}/workspace)
set(PROTOBUF_DIR "/home/zhlab/protobuf")
include_directories(
${PROTOBUF_DIR}/include
${PROJECT_SOURCE_DIR}/src
)
link_directories(
${PROTOBUF_DIR}/lib
)
add_executable(main ${PROJECT_SOURCE_DIR}/src/test.cpp ${PROJECT_SOURCE_DIR}/src/student.pb.cpp)
# add protobuf
target_link_libraries(main protobuf)
target_link_libraries(main pthread)
编译 test.cpp 文件,在 workspace/ 文件夹下运行可执行文件,运行效果如下所示:


总结
本次课程主要学习了 onnx 文件及其结构,onnx 本质是一个 protobuf 文件,它存储了模型的网络结构、权重等信息,onnx 可以理解为一种通用货币,将各种训练框架的模型导出为 onnx 后可交给部署工程师部署在不同的硬件平台上,而不必关心开发者使用的是哪一个框架。
除此之外,我们还学习了 onnx 文件的导出、读取、创建、编辑,通过这些案例使得我们更加了解 onnx,同时也方便我们后续 TRT 的部署工作