iptables知识
五条链
iptables是linux内核集成的IP信息过滤规则,负责将发往主机的网络包进行分发,转换等。当客户端请求服务器的某个服务时,请求信息会先通过网卡进入服务器内核,这时iptables会对包进行过滤,决定这些包是发往用户态的服务进程或是转发出去到别的主机。而决定这些路径的方式在iptables中称为链,刚进入内核的请求流会经过PREROUTING链,根据路由规则判断是是不是发往本机请求,是则走INPUT链进入本机用户态进程,否则会走FORWARD链并匹配对应的规则最后流出本机;如果是本机发出的请求会走OUTPUT链并进一步到POSTROUTINE链流出本机,或转发到其他机器或回复信息给客户端。
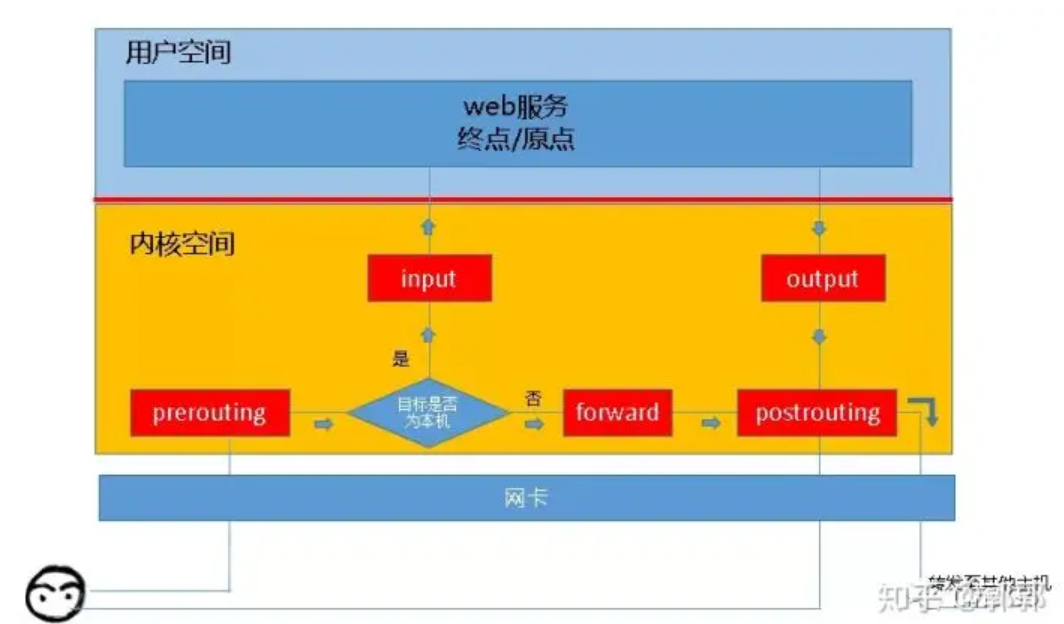
总结上述几条链:
- PREROUTINE:流入本机路由前
- POSTROUTINE:流出本机路由前
- FORWARD:转发路径
- OUTPUT:由本机用户程序发出的
- INPUT:发送至本机用户程序的
两个动作
SNAT
源地址转换,是指将报文发送方的ip地址转换,这样当相应方回复请求时,回复的是发送方的地址。

示例理解
当client发送请求给server时,需要经过gateway,如果gateway不对包进行源地址转换(SNAT),发往server的网络包携带的源地址依然是client,server会对该源地址响应,但client并不识别server的地址,会导致该条请求出现错误。
DNAT
目标地址转换,是将报文的目标地址转换,起到请求转发到别的目的地的作用。
k8s基础知识
下面了解k8s中的几种IP类型。
虚拟IP
虚IP(下文称VIP)有ClusterIP(即serviceIP),是集群自己生成的,ping不通,并和PodIP不处于同一网段,避免请求发生混乱。当创建一个service时,k8s会为该service指派一个IP地址,并会被集群中的所有kube-proxy观察到,kube-proxy从而会安装一系列的iptables规则到宿主机,kube-dns也会相应的插入一条域名解析IP的规则。请求到来的时候,如果符合规则,iptables会将VIP转化为实际的IP并使用。
实际IP
实IP分别有PodIP等,该IP是由CNI插件分配的,在k8s集群启动时候,需要安装CNI插件,通常是一个DaemonSet控制器控制,保证每台节点都有该进程。他的作用是在集群内部产生一套网络,并给每个pod插上”网线”,保证pod与节点,pod与pod是互通的。
Pod之间通信的方式可以通过实际的PodIP,但是该IP会随着pod的变化而变化,不适合用该方式,也可以通过ClusterIP的方式通信,比较稳定,但是不容易被记住,还可以通过svc.ns这种域名的格式,该方法请求kube-dns域名解析得到域名对应的IP。
在kubernetes中,service其实只是一个保存在etcd里的API对象,并不对应任何具体的实例。service即k8s中的“微服务”,而它的服务注册与发现、健康检查、负载均衡等功能其实是底层watch service、endpoint、pod等资源的DNS、kube-proxy,以及iptables等共同配合实现的。
从集群内部访问ClusterIP服务
在kubernetes网络之DNS 一文中,已经详细说明了从域名到ClusterIP的转换过程。
下面以kubernetes集群中某个Pod访问kubernetes服务(kube-apiserver)为例,分析一下kubernetes是怎么将对ClusterIP的访问转变成对某个后端Pod的访问的。
注:kube-proxy以iptables模式工作
1➜ ~ k get svc | grep kubernetes
2kubernetes ClusterIP 192.168.0.1 <none> 443/TCP 348d
3
4➜ ~ k get ep kubernetes
5NAME ENDPOINTS AGE
6kubernetes 10.20.126.169:6443,10.28.116.8:6443,10.28.126.199:6443 348d
- 首先数据包从容器中被路由到cni网桥,出现在宿主机网络栈中。
- Netfilter在
PREROUTING链中处理该数据包,最终会将其转到KUBE-SERVICES链上进行处理:
1-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
KUBE-SERVICES链将目的地址为192.168.0.1的数据包跳转到KUBE-SVC-NPX46M4PTMTKRN6Y链进行处理:
1-A KUBE-SERVICES -d 192.168.0.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
KUBE-SVC-NPX46M4PTMTKRN6Y链以相等概率将数据包跳转到KUBE-SEP-A66XJ5Q22M6AZV5X、KUBE-SEP-TYGT5TFZZ2W5DK4V或KUBE-SEP-KQD4HGXQYU3ORDNS链进行处理:
1-A KUBE-SVC-NPX46M4PTMTKRN6Y -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-A66XJ5Q22M6AZV5X
2-A KUBE-SVC-NPX46M4PTMTKRN6Y -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-TYGT5TFZZ2W5DK4V
3-A KUBE-SVC-NPX46M4PTMTKRN6Y -j KUBE-SEP-KQD4HGXQYU3ORDNS
- 而这三条链,其实代表了三条 DNAT 规则。DNAT 规则的作用,就是将 IP 包的目的地址和端口,改成
--to-destination所指定的新的目的地址和端口。可以看到,这个目的地址和端口,正是后端 Pod 的 IP 地址和端口。而这一切发生在Netfilter的PREROUTING链上,接下来Netfilter就会根据这个目的地址,对数据包进行路由。
1-A KUBE-SEP-A66XJ5Q22M6AZV5X -p tcp -m tcp -j DNAT --to-destination 10.20.126.169:6443
2-A KUBE-SEP-TYGT5TFZZ2W5DK4V -p tcp -m tcp -j DNAT --to-destination 10.28.116.8:6443
3-A KUBE-SEP-KQD4HGXQYU3ORDNS -p tcp -m tcp -j DNAT --to-destination 10.28.126.199:6443
- 如果目的Pod的IP地址就在本节点,则数据包会被路由回cni网桥,由cni网桥进行转发;如果目的Pod的IP地址在其他节点,则要进行一次容器跨节点通信,跨节点通信的过程可以参考kubernetes网络之CNI与跨节点通信原理这篇文章。
从集群外部访问NodePort服务
以下面这个服务(NodePort为31849)为例:
1➜ ~ k get svc webapp
2NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
3webapp NodePort 192.168.15.113 <none> 8081:31849/TCP 319d
- kube-proxy会在主机上打开31849端口,并配置一系列iptables规则:
1$ sudo lsof -i:31849
2COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
3kube-prox 253942 root 12u IPv6 1852002168 0t0 TCP *:31849 (LISTEN)
- 入口链
KUBE-NODEPORTS是KUBE-SERVICES中的最后一条规则:
1-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
- 先跳到
KUBE-MARK-MASQ链打上特殊记号0x4000/0x4000,这个特殊记号后续在POSTROUTING链中进行SNAT时用到。
1-A KUBE-NODEPORTS -p tcp -m comment --comment "default/webapp:" -m tcp --dport 31849 -j KUBE-MARK-MASQ
2
3-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
- 然后跳到
KUBE-SVC-BL7FHTIPVYJBLWZN链:
1-A KUBE-NODEPORTS -p tcp -m comment --comment "default/webapp:" -m tcp --dport 31849 -j KUBE-SVC-BL7FHTIPVYJBLWZN
- 后续的处理流程和上一节描述的相同,直到找到了目的Pod IP。
- 如果目的Pod IP地址就在本节点,则路由给cni网桥转发;如果目的Pod IP在其他节点,则需要进行容器跨节点通信。注意,这种情形下,本节点相当于网关的角色,在将源数据包转发出去之前,需要进行SNAT,将源数据包的源IP地址,转换为网关(本节点)的IP地址,这样,数据包才可能原路返回,即从目的节点经过本节点返回到实际的k8s集群外部的客户端:
1-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
这条规则的意思就是:带有0x4000/0x4000这个特殊标记的数据包在离开节点之前,在POSTROUTING链上进行一次SNAT,即MASQUERADE。而这个特殊标记,如前所述,是在外部客户端数据流入节点时打上去的。
总结
从上面的分析中,可以看出来,kube-proxy iptables模式中,最重要的是下面这五条链:
- KUBE-SERVICES:ClusterIP方式访问的入口链;
- KUBE-NODEPORTS:NodePort方式访问的入口链;
- KUBE-SVC-*:相当于一个负载均衡器,将数据包平均分发给
KUBE-SEP-*链; - KUBE-SEP-*:通过DNAT将Service的目的IP和端口,替换为后端Pod的IP和端口,从而将流量转发到后端Pod。
- KUBE-POSTROUTING:通过对路由到其他节点的数据包进行SNAT,使其能够原路返回。
对于NodePort类型的service,如果本节点上没有目的Pod,则本节点起到的是网关的作用,将数据路由到其他节点。在这种情况下,访问Pod IP的链路会多一跳。我们可以通过将
externalTrafficPolicy字段设置为local,当这样本节点上不存在Pod时,FORWARD链上的filter表规则会直接把包drop掉,而不会从本节点转发出去:
1-A KUBE-NODEPORTS -p tcp -m comment --comment "default/webapp:" -m tcp --dport 31849 -j KUBE-XLB-BL7FHTIPVYJBLWZN
2
3-A KUBE-XLB-BL7FHTIPVYJBLWZN -m comment --comment "default/webapp: has no local endpoints" -j KUBE-MARK-DROP
4
5-A KUBE-MARK-DROP -j MARK --set-xmark 0x8000/0x8000
6
7-A KUBE-FIREWALL -m comment --comment "kubernetes firewall for dropping marked packets" -m mark --mark 0x8000/0x8000 -j DROP
kube-proxy的IPVS模式
上述流程描述的是kube-proxy的iptables模式的工作流程,这个模式最大的问题在于:
- kube-proxy需要为service配置大量的iptables规则,并且刷新这些规则以确保正确性;
- iptables的规则是以链表的形式保存的,对iptables的刷新需要遍历链表
解决办法就是使用IPVS模式的kube-proxy。IPVS是Linux内核实现的四层负载均衡,因此相比于通过配置iptables规则进行“投机取巧”式的负载均衡,IPVS更加专业。IPVS 和iptables一样底层也是基于netfilter,但使用更高效的数据结构(散列表),允许几乎无限的规模扩张。
创建一个service时,IPVS模式kube-proxy会创建一块虚拟网卡,并且把service的ClusterIP绑在网卡上,然后设置这个网卡的后端real server,对应的是EndPoints,并设置负载均衡规则。这样,数据包就会先发送到kube-proxy的虚拟网卡上,然后转发到后端Pod。
IPVS没有SNAT的能力,所以在一些场景下,依然需要依赖iptables。但是使用IPVS模式的kube-proxy,不存在上述两个问题,性能要优于iptables模式。
kube dns
默认DNS策略
Pod默认的dns策略是 ClusterFirst,意思是先通过kubernetes的权威DNS服务器(如CoreDNS)直接解析出A记录或CNAME记录;如果解析失败,再根据配置,将其转发给上游DNS服务器。以CoreDNS为例,它的配置文件Corefile如下所示:
1➜ ~ kubectl get cm -n kube-system coredns -o yaml
2apiVersion: v1
3data:
4 Corefile: |
5 .:53 {
6 errors
7 health {
8 lameduck 5s
9 }
10 ready
11 kubernetes cluster.local in-addr.arpa ip6.arpa {
12 pods insecure
13 fallthrough in-addr.arpa ip6.arpa
14 ttl 30
15 }
16 prometheus :9153
17 forward . /etc/resolv.conf
18 cache 30
19 loop
20 reload
21 loadbalance
22 }
23kind: ConfigMap
24...
第17行使用forward插件配置了上游域名服务器为主机的/etc/resolv.conf中指定的nameserver。
Service和DNS
尽管kubelet在启动容器时,会将同namespace下的Service信息注入到容器的环境变量中:
1➜ ~ kubectl get svc | grep kubernetes
2kubernetes ClusterIP 192.168.0.1 <none> 443/TCP 347d
3
4➜ ~ kubectl exec -it debug-pod -n default -- env | grep KUBERNETES
5KUBERNETES_SERVICE_PORT=443
6KUBERNETES_PORT=tcp://192.168.0.1:443
7KUBERNETES_PORT_443_TCP_ADDR=192.168.0.1
8KUBERNETES_PORT_443_TCP_PORT=443
9KUBERNETES_PORT_443_TCP_PROTO=tcp
10KUBERNETES_PORT_443_TCP=tcp://192.168.0.1:443
11KUBERNETES_SERVICE_PORT_HTTPS=443
12KUBERNETES_SERVICE_HOST=192.168.0.1
但是通常情况下我们使用DNS域名解析的方式进行服务注册和发现。
Kubernetes中的DNS应用部署好以后,会对外暴露一个服务,集群内的容器可以通过访问该服务的Cluster IP进行域名解析。DNS服务的Cluster IP由Kubelet的cluster-dns参数指定。并且在创建Pod时,由Kubelet将DNS Server的信息写入容器的/etc/resolv.conf文件中。
查看resolv.conf文件的配置:
1➜ ~ k exec -it debug-pod -n default -- cat /etc/resolv.conf
2nameserver 192.168.0.2
3search default.svc.cluster.local svc.cluster.local cluster.local
4options ndots:5
-
nameserver 192.168.0.2这一行即表示DNS服务的地址(Cluster IP)为192.168.0.2。 -
search这一行表示,如果无法直接解析域名,则会尝试加上default.svc.cluster.local,svc.cluster.local,cluster.local后缀进行域名解析。其中
default是namespace,cluster.local是默认的集群域名后缀,kubelet也可以通过--cluster-domain参数进行配置。
也就是说:
- 同namespace下,可以通过
nslookup+kubernetes解析域名 - 不同namespace下,可以通过
nslookup+kubernetes.default、kubernetes.default.svc、kubernetes.default.svc.cluster.local解析域名
因为dns服务器会帮你补齐全域名:kubernetes.default.svc.cluster.local
{svc name}.{svc namespace}.svc.{cluster domain}就是kubernetes的FQDN格式。
Headless Service的域名解析
无论是kube-dns还是CoreDNS,基本原理都是通过watch Service和Pod,生成DNS记录。常规的ClusterIP类型的Service的域名解析如上所述,DNS服务会返回一个A记录,即域名和ClusterIP的对应关系:
1➜ ~ k exec -it debug-pod -n default -- nslookup kubernetes.default
2Server: 192.168.0.2
3Address: 192.168.0.2#53
4
5Name: kubernetes.default.svc.cluster.local
6Address: 192.168.0.1
Headless Service的域名解析稍微复杂一点。
ClusterIP可以看作是Service的头,而Headless Service,顾名思义也就是指定他的ClusterIP为None的Service。
直接解析
当你直接解析它的域名时,返回的是EndPoints中的Pod IP列表:
这个EndPoints后端的Pod,不仅可以通过在service中指定selector来选择,也可以自己定义,只要名字和service同名即可。
1➜ ~ k exec -it debug-pod -n default -- nslookup headless
2Defaulting container name to debug.
3Use 'kubectl describe pod/debug-pod -n default' to see all of the containers in this pod.
4Server: 192.168.0.2
5Address: 192.168.0.2#53
6
7Name: headless.default.svc.cluster.local
8Address: 1.1.1.1
9Name: headless.default.svc.cluster.local
10Address: 2.2.2.2
11Name: headless.default.svc.cluster.local
12Address: 3.3.3.3
给Pod生成A记录
如果在Pod.spec中指定了hostname和subdomain,并且subdomain和headleass service的名字相同,那么kubernetes DNS会额外给这个Pod的FQDN生成A记录:
1➜ ~ k exec -it debug-pod -n default -- nslookup mywebsite.headless.default.svc.cluster.local
2Server: 192.168.0.2
3Address: 192.168.0.2#53
4
5Name: mywebsite.headless.default.svc.cluster.local
6Address: 10.189.97.217
Pod的FQDN是:
{hostname}.{subdomain}.{pod namespace}.svc.{cluster domain}
ExternalName Service
ExternalName 类型的Service,kubernetes DNS会根据ExternalName字段,为其生成CNAME记录,在DNS层进行重定向。
1apiVersion: v1 2kind: Service 3metadata: 4 name: external 5 namespace: default 6spec: 7 type: ExternalName 8 externalName: my.example.domain.com
1➜ ~ k exec -it debug-pod -n default -- nslookup external
2Server: 192.168.0.2
3Address: 192.168.0.2#53
4
5external.default.svc.cluster.local canonical name = my.example.domain.com.
6Name: my.example.domain.com
7Address: 66.96.162.92
Kubernetes 服务发现
原文:Demystifying Kubernetes service discovery
作者:Nigel Poulton
Kubernetes 服务发现是一个经常让我产生困惑的主题之一。本文分为两个部分:
- 网络方面的背景知识
- 深入了解 Kubernetes 服务发现
要了解服务发现,首先要了解背后的网络知识。这部分内容相对浅显,如果读者熟知这一部分,完全可以跳过,直接阅读服务发现部分。
开始之前还有一个需要提醒的事情就是,为了详细描述这一过程,本文略长。
Kubernetes 网络基础
要开始服务发现的探索之前,需要理解以下内容:
- Kubernetes 应用运行在容器之中,容器处于 Pod 之内。
- 每个 Pod 都会附着在同一个大的扁平的 IP 网络之中,被称为 Pod 网络(通常是 VXLAN 叠加网络)。
- 每个 Pod 都有自己的唯一的 IP 地址,这个 IP 地址在 Pod 网络中是可路由的。
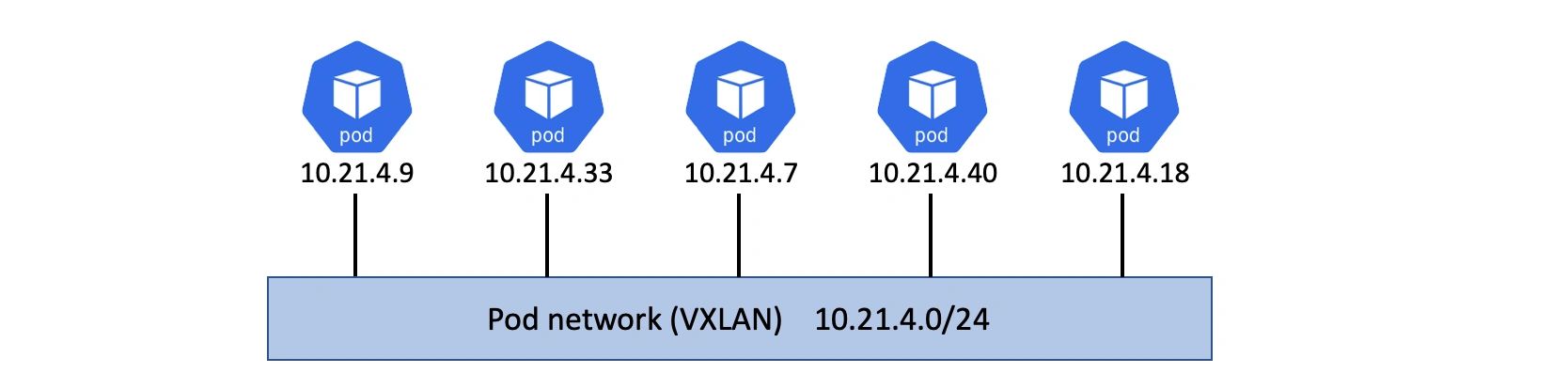
上述三个因素结合起来,让每个应用(应用的组件和服务)无需通过 NAT 之类的网络过程,就能够直接通信。
动态网络
在对应用进行横向扩容时,会在 Pod 网络中加入新的 Pod,新 Pod 自然也伴随着新的 IP 地址;如果对应用进行缩容,旧的 Pod 及其 IP 会被删除。这个过程看起来很是混乱。
应用的滚动更新和撤回也存在同样的情形——加入新版本的新 Pod,或者移除旧版本的旧 Pod。新 Pod 会加入新 IP 到 Pod 网络中,被终结的旧 Pod 会删除其现存 IP。
如果没有其它因素,每个应用服务都需要对网络进行监控,并管理一个健康 Pod 的列表。这个过程会非常痛苦,另外在每个应用中编写这个逻辑也是很低效的。幸运的是,Kubernetes 用一个对象完成了这个过程——Service。
把这个对象叫做 Service 是个坏主意,我们已经用这个单词来形容应用的进程或组件了。
还有一个值得注意的事情:Kubernetes 执行 IP 地址管理(IPAM)职责,对 Pod 网络上已使用和可用的 IP 地址进行跟踪。
Service 带来稳定性
Kubernetes Service 对象在一组提供服务的 Pod 之前创建一个稳定的网络端点,并为这些 Pod 进行负载分配。
一般会在一组完成同样工作的 Pod 之前放置一个 Service 对象。例如可以在你的 Web 前端 Pod 前方提供一个 Service,在认证服务 Pod 之前提供另一个。行使不同职责的 Pod 之前就不应该用单一的 Service 了。
客户端和 Service 通信,Service 负责把流量负载均衡给 Pod。
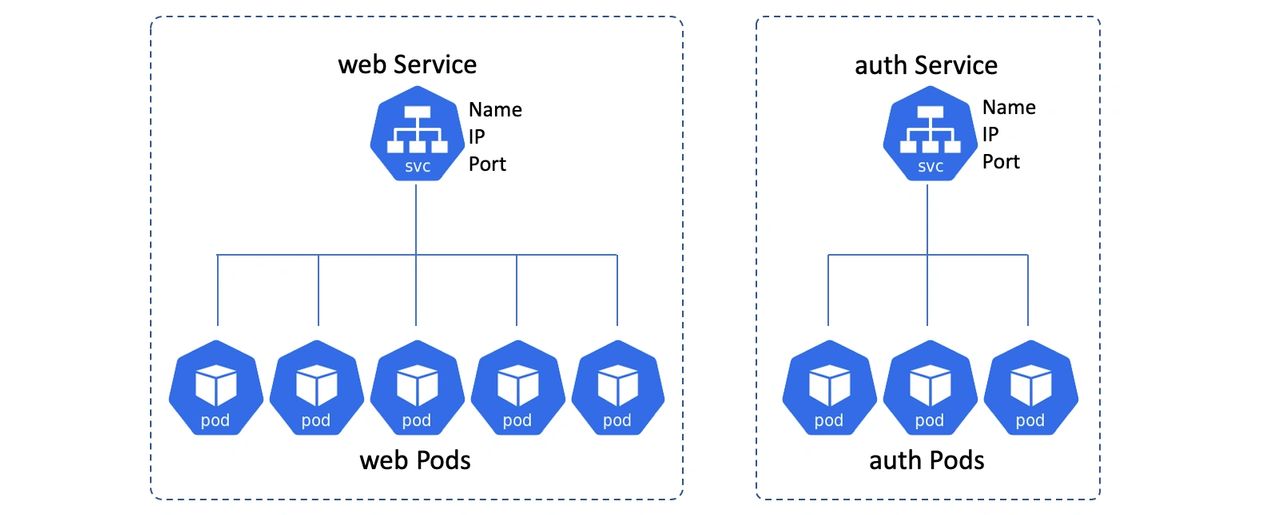
在上图中,底部的 Pod 会因为伸缩、更新、故障等情况发生变化,而 Service 会对这些变化进行跟踪。同时 Service 的名字、IP 和端口都不会发生变化。
Kubernetes Service 解析
可以把 Kubernetes Service 理解为前端和后端两部分:
- 前端:名称、IP 和端口等不变的部分。
- 后端:符合特定标签选择条件的 Pod 集合。
前端是稳定可靠的,它的名称、IP 和端口在 Service 的整个生命周期中都不会改变。前端的稳定性意味着无需担心客户端 DNS 缓存超时等问题。
后端是高度动态的,其中包括一组符合标签选择条件的 Pod,会通过负载均衡的方式进行访问。
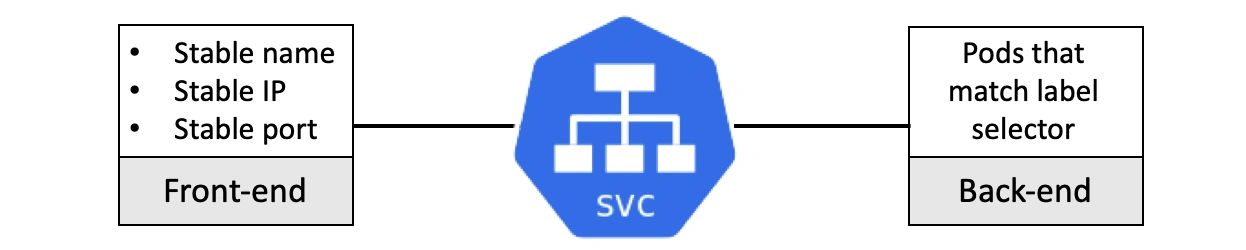
这里的负载均衡是一个简单的 4 层轮询。它工作在连接层面,所以同一个连接里发起的所有请求都会进入同一个 Pod。因为在 4 层工作,所以对于 7 层的 HTTP 头或者 Cookie 之类的东西是无法感知的。
小结
应用在容器中运行,在 Kubernetes 中体现为 Pod 的形式。Kubernetes 集群中的所有 Pod 都处于同一个平面的 Pod 网络,有自己的 IP 地址。这意味着所有的 Pod 之间都能直接连接。然而 Pod 是不稳定的,可能因为各种因素创建和销毁。Kubernetes 提供了稳定的网络端点,称为 Service,这个对象处于一组相似的 Pod 前方,提供了稳定的名称、IP 和端口。客户端连接到 Service,Service 把流量负载均衡给 Pod。
接下来聊聊服务发现。
深入了解 Kubernetes 服务发现
服务发现实际上包含两个功能点:
- 服务注册
- 服务发现
服务注册
服务注册过程指的是在服务注册表中登记一个服务,以便让其它服务发现。
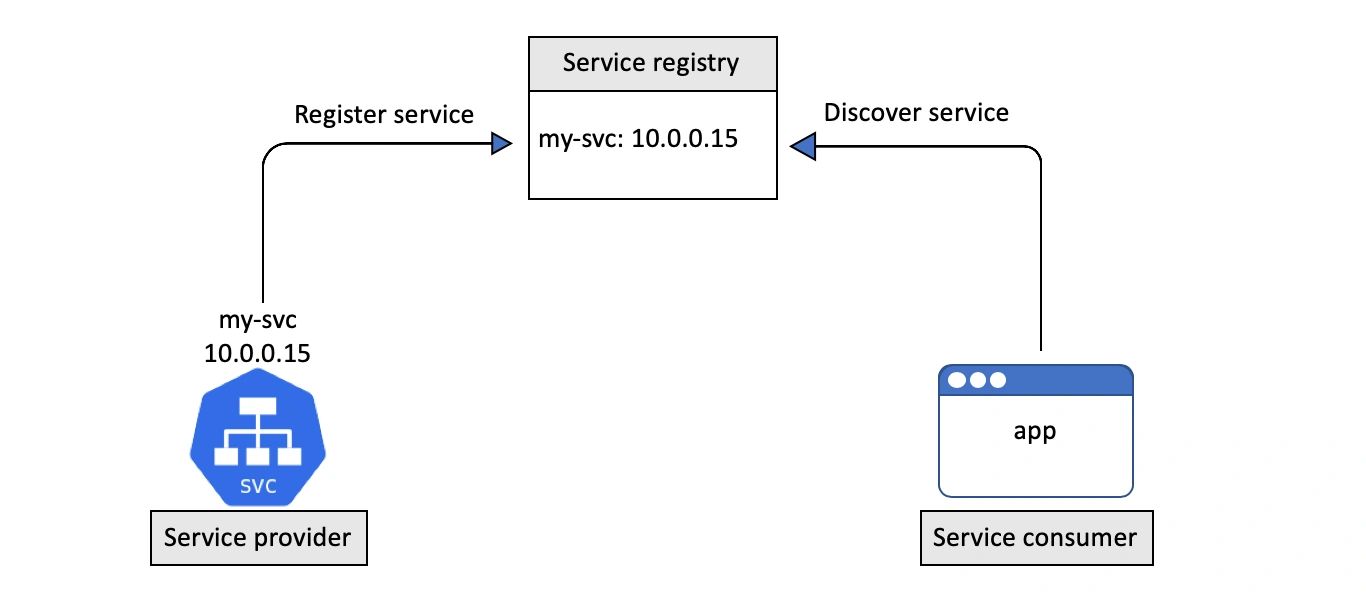
Kubernetes 使用 DNS 作为服务注册表。
为了满足这一需要,每个 Kubernetes 集群都会在 kube-system 命名空间中用 Pod 的形式运行一个 DNS 服务,通常称之为集群 DNS。
每个 Kubernetes 服务都会自动注册到集群 DNS 之中。
注册过程大致如下:
- 向 API Server 用 POST 方式提交一个新的 Service 定义;
- 这个请求需要经过认证、鉴权以及其它的准入策略检查过程之后才会放行;
- Service 得到一个
ClusterIP(虚拟 IP 地址),并保存到集群数据仓库; - 在集群范围内传播 Service 配置;
- 集群 DNS 服务得知该 Service 的创建,据此创建必要的 DNS A 记录。
上面过程中,第 5 个步骤是关键环节。集群 DNS 使用的是 CoreDNS,以 Kubernetes 原生应用的形式运行。CoreDNS 实现了一个控制器,会对 API Server 进行监听,一旦发现有新建的 Service 对象,就创建一个从 Service 名称映射到 ClusterIP 的域名记录。这样 Service 就不必自行向 DNS 进行注册,CoreDNS 控制器会关注新创建的 Service 对象,并实现后续的 DNS 过程。
DNS 中注册的名称就是 metadata.name,而 ClusterIP 则由 Kubernetes 自行分配。

Service 对象注册到集群 DNS 之中后,就能够被运行在集群中的其它 Pod 发现了。
Endpoint 对象
Service 的前端创建成功并注册到服务注册表(DNS)之后,剩下的就是后端的工作了。后端包含一个 Pod 列表,Service 对象会把流量分发给这些 Pod。
毫无疑问,这个 Pod 列表需要是最新的。
Service 对象有一个 Label Selector 字段,这个字段是一个标签列表,符合列表条件的 Pod 就会被服务纳入到服务的负载均衡范围之中。参见下图:
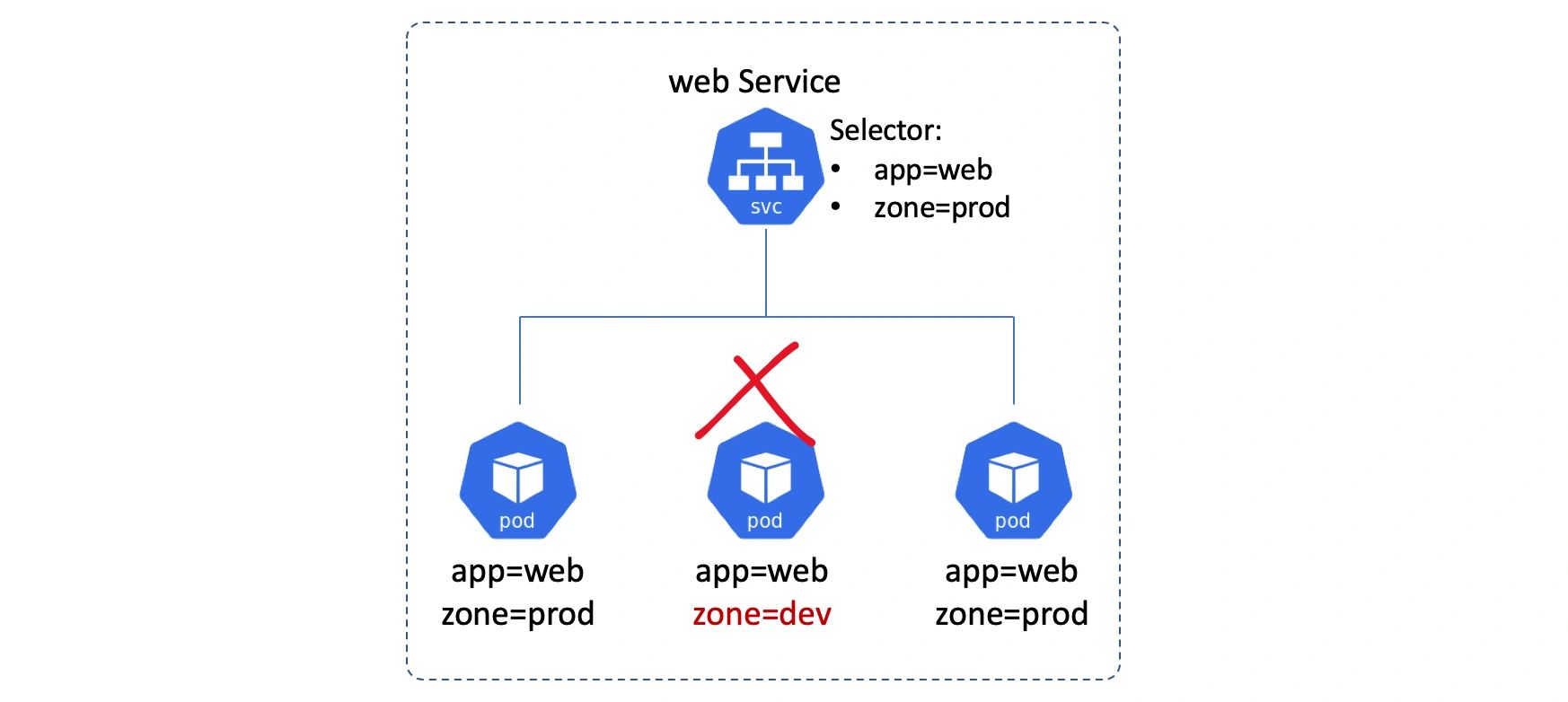
Kubernetes 自动为每个 Service 创建 Endpoints 对象。Endpoints 对象的职责就是保存一个符合 Service 标签选择器标准的 Pod 列表,这些 Pod 将接收来自 Service 的流量。
下面的图中,Service 会选择两个 Pod,并且还展示了 Service 的 Endpoints 对象,这个对象里包含了两个符合 Service 选择标准的 Pod 的 IP。
在后面我们将解释网络如何把 ClusterIP 流量转发给 Pod IP 的过程,还会引用到 Endpoints 对象。
服务发现
假设我们在一个 Kubernetes 集群中有两个应用,my-app 和 your-app,my-app 的 Pod 的前端是一个 名为 my-app-svc 的 Service 对象;your-app Pod 之前的 Service 就是 your-app-svc。
这两个 Service 对象对应的 DNS 记录是:
my-app-svc:10.0.0.10your-app-svc:10.0.0.20
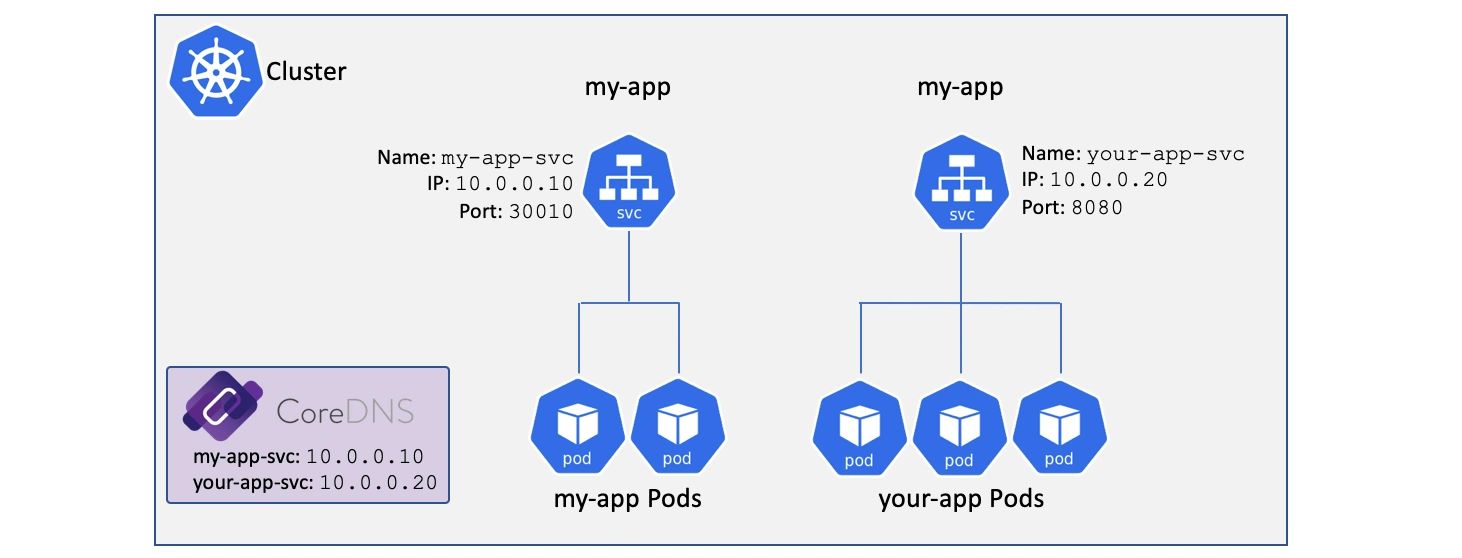
要使用服务发现功能,每个 Pod 都需要知道集群 DNS 的位置才能使用它。因此每个 Pod 中的每个容器的 /etc/resolv.conf 文件都被配置为使用集群 DNS 进行解析。
如果 my-app 中的 Pod 想要连接到 your-app 中的 Pod,就得向 DNS 服务器发起对域名 your-app-svc 的查询。假设它们本地的 DNS 解析缓存中没有这个记录,则需要把查询提交到集群 DNS 服务器。会得到 you-app-svc 的 ClusterIP(VIP)。
这里有个前提就是
my-app需要知道目标服务的名称。
至此,my-app 中的 Pod 得到了一个目标 IP 地址,然而这只是个虚拟 IP,在转入目标 Pod 之前,还有些网络工作要做。
网络
一个 Pod 得到了 Service 的 ClusterIP 之后,就尝试向这个 IP 发送流量。然而 ClusterIP 所在的网络被称为 Service Network,这个网络有点特别——没有路由指向它。
因为没有路由,所有容器把发现这种地址的流量都发送到了缺省网关(名为 CBR0 的网桥)。这些流量会被转发给 Pod 所在节点的网卡上。节点的网络栈也同样没有路由能到达 Service Network,所以只能发送到自己的缺省网关。路由到节点缺省网关的数据包会通过 Node 内核——这里有了变化。
回顾一下前面的内容。首先 Service 对象的配置是全集群范围有效的,另外还会再次说到 Endpoints 对象。我们要在回顾中发现他们各自在这一过程中的职责。
每个 Kubernetes 节点上都会运行一个叫做 kube-proxy 的系统服务。这是一个基于 Pod 运行的 Kubernetes 原生应用,它所实现的控制器会监控 API Server 上 Service 的变化,并据此创建 iptables 或者 IPVS 规则,这些规则告知节点,捕获目标为 Service 网络的报文,并转发给 Pod IP。
有趣的是,kube-proxy 并不是一个普遍意义上的代理。它的工作不过是创建和管理 iptables/IPVS 规则。这个命名的原因是它过去使用 unserspace 模式的代理。
每个新 Service 对象的配置,其中包含它的 ClusterIP 以及 Endpoints 对象(其中包含健康 Pod 的列表),都会被发送给 每个节点上的 kube-proxy 进程。kube-proxy 会创建 iptables 或者 IPVS 规则,告知节点捕获目标为 Service ClusterIP 的流量,并根据 Endpoints 对象的内容转发给对应的 Pod。
也就是说每次节点内核处理到目标为 Service 网络的数据包时,都会对数据包的 Header 进行改写,把目标 IP 改为 Service Endpoints 对象中的健康 Pod 的 IP。
原本使用的 iptables 正在被 IPVS 取代(Kubernetes 1.11 进入稳定期)。长话短说,iptables 是一个包过滤器,并非为负载均衡设计的。IPVS 是一个 4 层的负载均衡器,其性能和实现方式都比 iptables 更适合这种使用场景。
总结
需要消化的内容很多,简单回顾一下。
创建新的 Service 对象时,会得到一个虚拟 IP,被称为 ClusterIP。服务名及其 ClusterIP 被自动注册到集群 DNS 中,并且会创建相关的 Endpoints 对象用于保存符合标签条件的健康 Pod 的列表,Service 对象会向列表中的 Pod 转发流量。
与此同时集群中所有节点都会配置相应的 iptables/IPVS 规则,监听目标为 ClusterIP 的流量并转发给真实的 Pod IP。这个过程如下图所示:
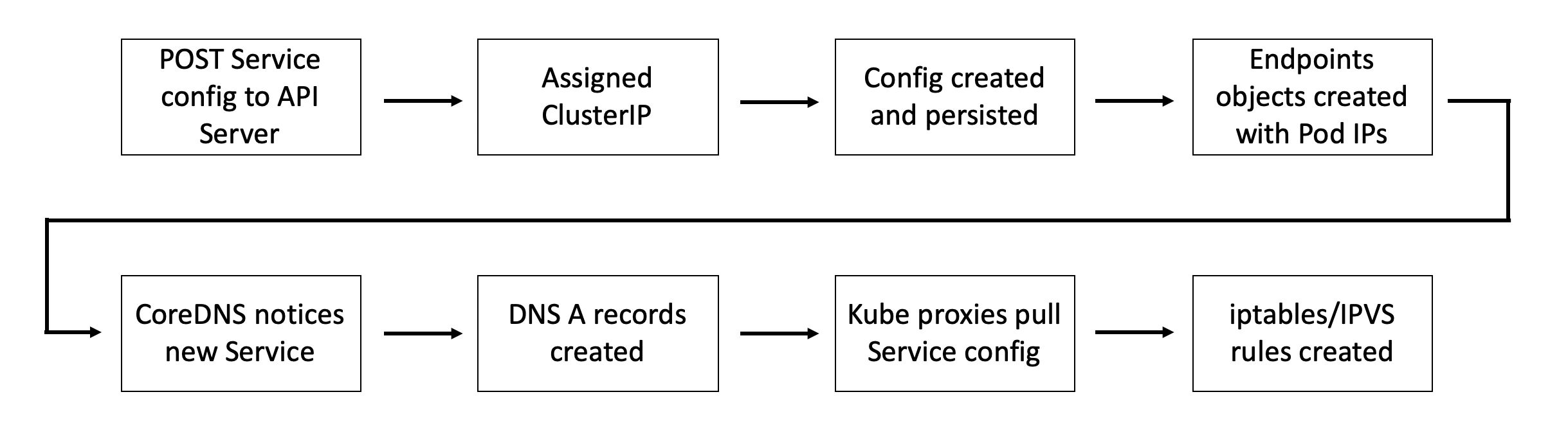
一个 Pod 需要用 Service 连接其它 Pod。首先向集群 DNS 发出查询,把 Service 名称解析为 ClusterIP,然后把流量发送给位于 Service 网络的 ClusterIP 上。然而没有到 Service 网络的路由,所以 Pod 把流量发送给它的缺省网关。这一行为导致流量被转发给 Pod 所在节点的网卡,然后是节点的缺省网关。这个操作中,节点的内核修改了数据包 Header 中的目标 IP,使其转向健康的 Pod。
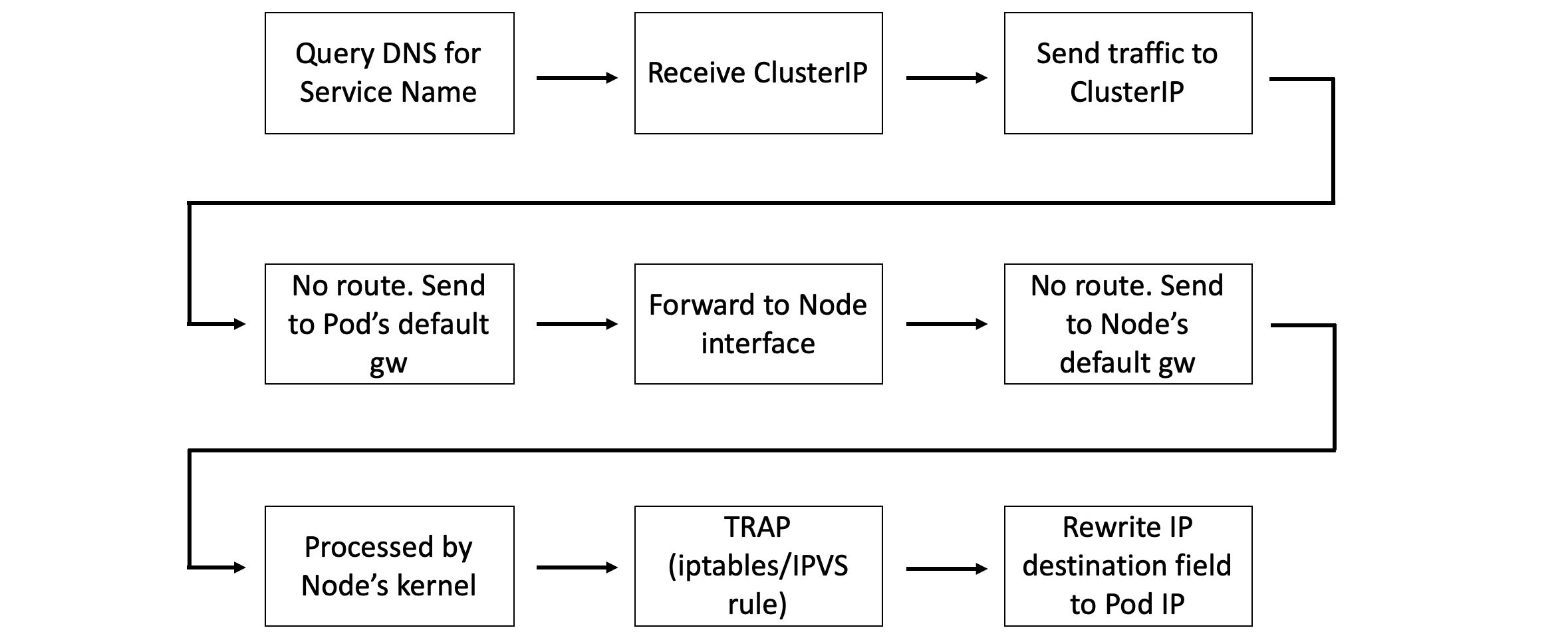
最终所有 Pod 都是在同一个可路由的扁平的叠加网络上,剩下的内容就很简单了。
kubeproxy service nodeport 底层链路详解
最近准备开发一款多集群容器网络通信的工具,需要了解网络相关的知识。由于跨k8s集群的容器网络通了之后,还需要解决跨集群网络的服务发现及`Service`到`PodIP`的负载均衡问题。因此,抱着学习的目的,研究了一下kube-proxy的原理。
我们都知道,kube-proxy是k8s用于处理`Service`到`Pod`的负载均衡的组件。目前k8s常用的负载均衡方式有iptables和ipvs两种(usersapce模式已经被弃用),因此我将使用iptables和ipvs两种模式分别部署两套集群,使用iptables,ipvs,ipset等命令观测看到的现象,并分析kube-proxy的实现原理。
首先部署iptables模式的k8s集群,集群版本为1.23,集群有两个节点,并部署nginx的服务。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- name: http
port: 80
targetPort: 80
type: ClusterIP
此时,三个nginx的副本的服务已经起来。
ClusterIP
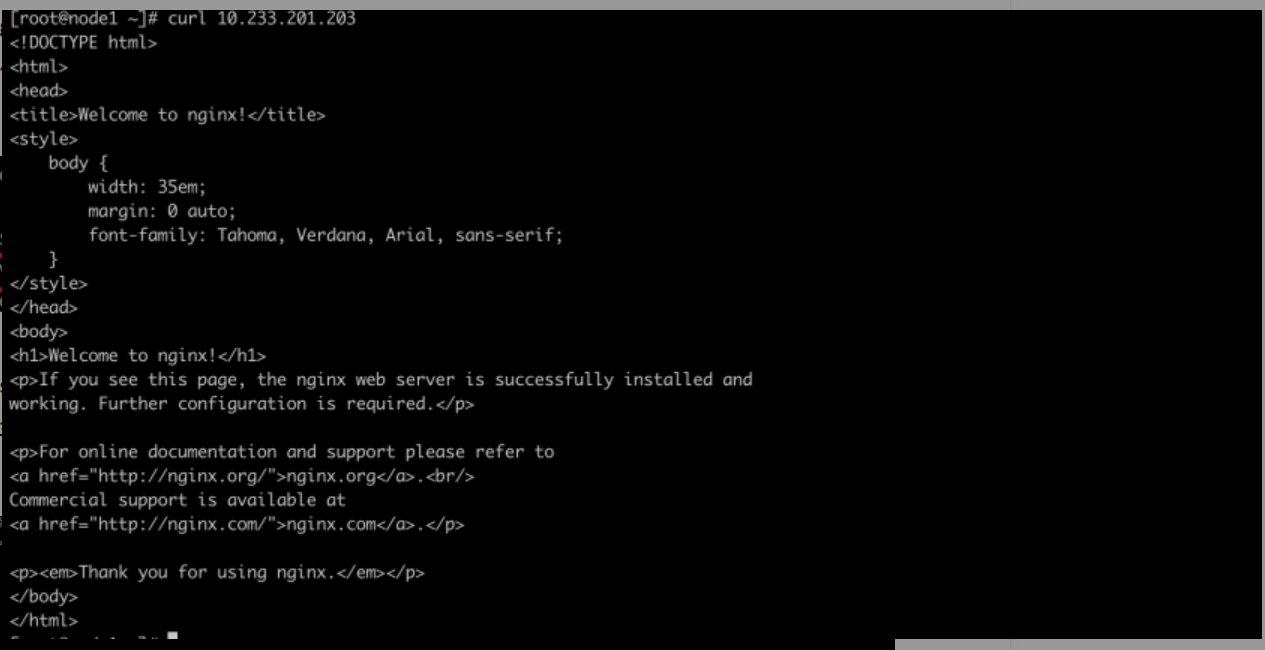
上面我们部署了三个副本的nginx的工作负载,并通过`ClusterIP`类型的`Service`提供服务。下面我们看下`ClusterIP`类型的`Service`的iptables的实现方式。首先我们部署的`Service`的`ClusterIP`是`10.233.201.203`,这个地址是ping不通的,因为`ClusterIP`是个虚拟ip,虚拟ip关联着后端多个`Endpoint`,也就是pod实际提供服务的地址,我们可以看下这个`Service`对应的`Endpoint`。

可以看到Endpoints为三个pod副本实际提供服务的地址,我们在node1节点上尝试curl 一下上面的ClusterIP,执行 curl 10.233.201.203
下面我们分析curl这个`ClusterIP`的网络包的流转过程。首先看iptables的nat表的`PREROUTING`链,这个链作用于路由表之前。执行`iptables -nvL -t nat`可以看到有`KUBE-SERVICES`这条链

执行iptables -nv -t nat -L KUBE-SERVICES 可以看到这条链的规则

继续执行iptables -nv -t nat -L KUBE-SVC-6IM33IEVEEV7U3GP

可以看到nginx的service具有这样几条iptables规则。第一条规则是Masquerade伪装,即将不在10.222.0.0/16网段的源地址ip转换为经过的路由节点或经过的网卡的ip,由于我们在本地发起curl请求,源地址是宿主机地址,因此会走这条路由规则,KUBE-MARK-MASQ 链用于标记需要进行 Masquerade(即需要将源 IP 地址转换为经过路由的节点的 IP 地址)的数据包。KUBE-MARK-MASQ 链中的 MARK all – * * 0.0.0.0/0 0.0.0.0/0 MARK or 0x4000 这一行会在通过该链的所有数据包上设置防火墙标记。具体来说,它将标记设置为值 0x4000,这是一个比特标志,用于表示该数据包应进行 Masquerade。稍后 POSTROUTING 链将使用该防火墙标记,执行数据包的实际网络地址转换(NAT)和 Masquerade。第二条到第四条规则是利用了iptables的statistic模块的random模式,也就是说当访问ClusterIP时,会根据iptables的规则随机匹配到不同的target。第二条规则是说有0.3333的概率匹配到KUBE-SEP-H2GUZ3BVVZUUMDYH,我们看下这条链的规则iptables -vn -t nat -L KUBE-SEP-H2GUZ3BVVZUUMDYH

可以看到这条链有两条规则,其中第二条DNAT规则就是将目的地址转化为10.222.154.5:80 这个地址,也就是我们上面的Endpoint。第一条规则是一条Masquerade规则,是用于回包的时候做源地址转换的,这里可以先不管。KUBE-SEP的第三条规则类似第二条,当第二条规则有66%的概率没有匹配到时,就有50%的概率匹配到第三条规则到另外一个Endpoint。第四条规则在第二条规则有50%的概率没有匹配到时,会进入这条规则。
总结一下:当发起一个到`ClusterIP`的请求时,`PREROUTING`规则先起作用,然后通过iptables的random模式随机的匹配多条到pod的DNAT规则,从上文也可以看到,这是一个O(n)的算法,也就是工作负载有几个副本,就会创建几个到工作副本的dnat规则和回包时的`Masquerade`规则,当pod数量很多的时候,显然会对k8s集群的压力很大。当`PREROUTING`执行了DNAT之后,后面就是正常的到`PodIP`的通信过程,这个过程是由CNI插件控制面的,这里不再详细描述。我们可以通过抓包看到上面的整个分析过程。执行命令 `tcpdump -i any -n host 10.222.154.5`。其中`10.222.154.5` 是其中一个pod的地址,抓包截图如下:
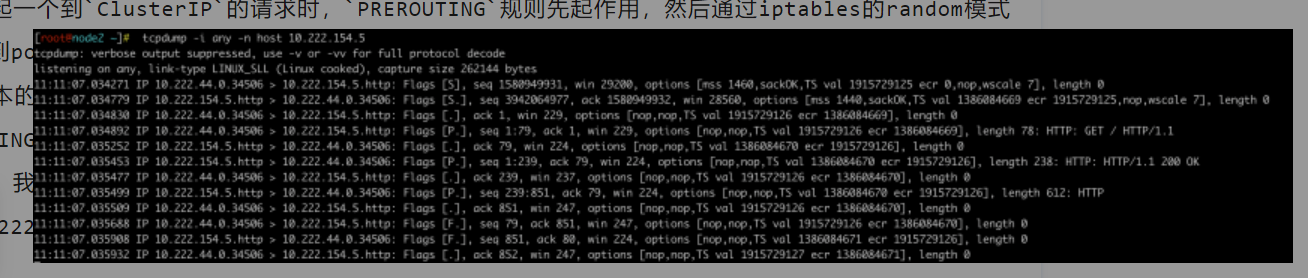
当 curl service的时候,抓包可以看到上面的内容,说明iptables的DNAT生效之后,发往ClusterIP的包实际到了其中某一个podIP。
NodePort
上面我们分析了`ClusterIP`的原理,现在继续看下`NodePort`的,将`Service`改成`NodePort`类型,暴漏的端口为30254,继续看下iptables链

可以看到,相比于ClusterIP的链规则,多了一条KUBE-NODEPORTS的链,当访问 http://node2:30254的时候,前面的链没有匹配到,会进入最后一条KUBE-NODEPORTS链,继续看下这条链的规则。

这条链的规则很简单,当目的端口是30254的时候,iptables规则走向了KUBE-SVC-6IM33IEVEEV7U3GP,这个跟上面的ClusterIP的链是一致的,继续看下这条链有没有什么变化

可以看到除了增加了一条KUBE-MARK-MASQ其他没有什么变化。而这条链的规则也很简单,只不过是给网络包增加了标记而已,如下图所示。

从上面KUBE-SERVICES这条链的规则可以看到,NodePort的规则是在最下面的,而iptables规则的匹配是按顺序的,这是否也意味了NodePort的Service的性能不如ClusterIP?结果不得而知,至少从现象分析上是这个结果。从上面的分析可以发现,NodePort类型的Service流量直接从本地的NodePort通过iptables规则DNAT到PodIP,没有经过ClusterIP。
IPVS模式实践
从上面iptables的分析来看,集群内iptables规则的数量跟集群内pod的数量成正比。不难想象,当集群内pod数量很大的情况,iptables规则数量很大,而Linux系统不断地刷新成百上千条iptables规则会大量消耗系统的CPU资源,甚至引起宿主机的卡死。而IPVS模式则有效解决了这个问题,在分析IPVS模式前,我们需要先了解下ipset和lvs,这两个工具都是linux系统自带的功能。
ipvs模式也是基于netfilter,对比iptables模式在大规模Kubernetes集群有更好的扩展性和性能,支持更加复杂的负载均衡算法(如:最小负载、最少连接、加权等),支持Server的健康检查和连接重试等功能。ipvs依赖于iptables,使用iptables进行包过滤、SNAT、masquared。ipvs将使用ipset需要被DROP或MASQUARED的源地址或目标地址,这样就能保证iptables规则数量的固定,我们不需要关心集群中有多少个Service了。
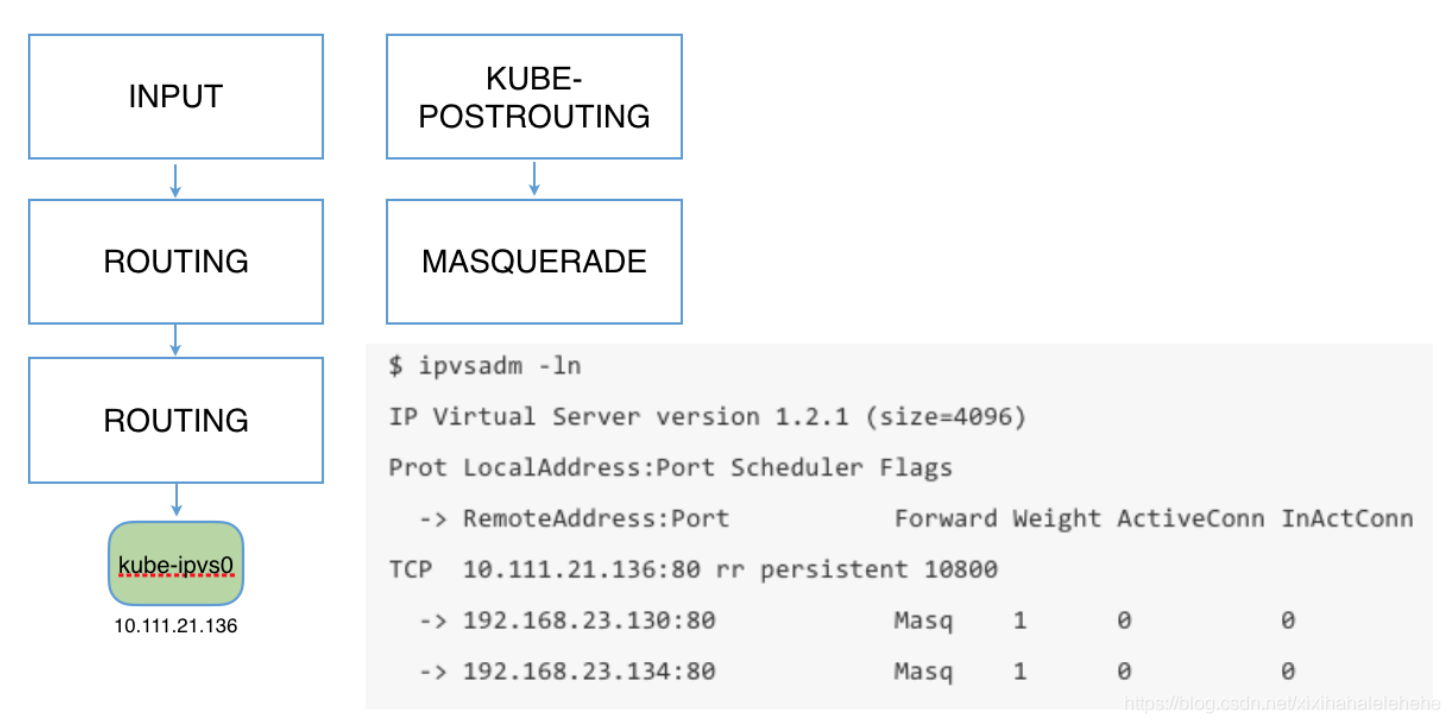
kubernetes中ipvs实现原理图:
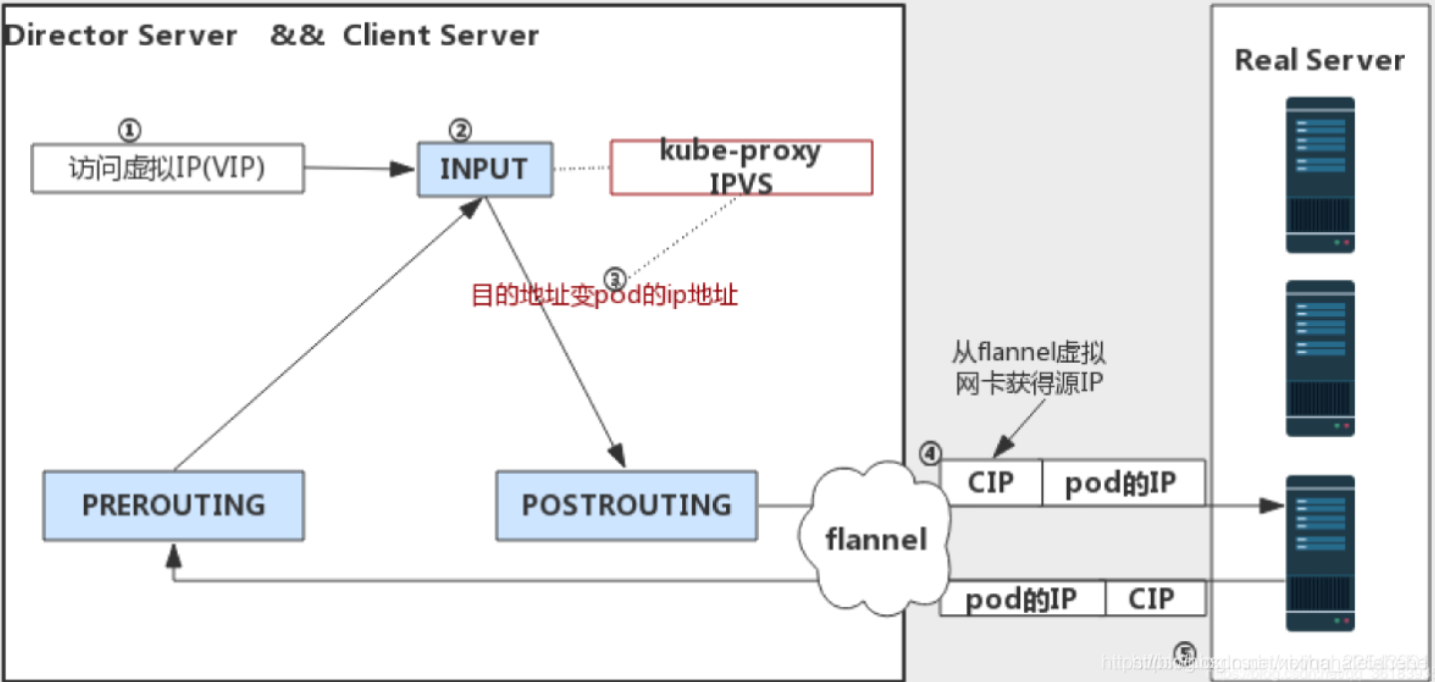
为什么每个svc会在ipvs网卡增加vip地址:
由于 IPVS 的 DNAT 钩子挂在 INPUT 链上,因此必须要让内核识别 VIP 是本机的 IP。这样才会过INPUT 链,要不然就通过OUTPUT链出去了。k8s 通过设置将service cluster ip 绑定到虚拟网卡kube-ipvs0。
①因为service cluster ip 绑定到虚拟网卡kube-ipvs0上,内核可以识别访问的 VIP 是本机的 IP.
②数据包到达INPUT链.
③ipvs监听到达input链的数据包,比对数据包请求的服务是为集群服务,修改数据包的目标IP地址为对应pod的IP,然后将数据包发至POSTROUTING链.
④数据包经过POSTROUTING链选路,将数据包通过flannel网卡发送出去。从flannel虚拟网卡获得源IP.
⑤pod接收到请求之后,构建响应报文,改变源地址和目的地址,返回给客户端。
ipset和LVS
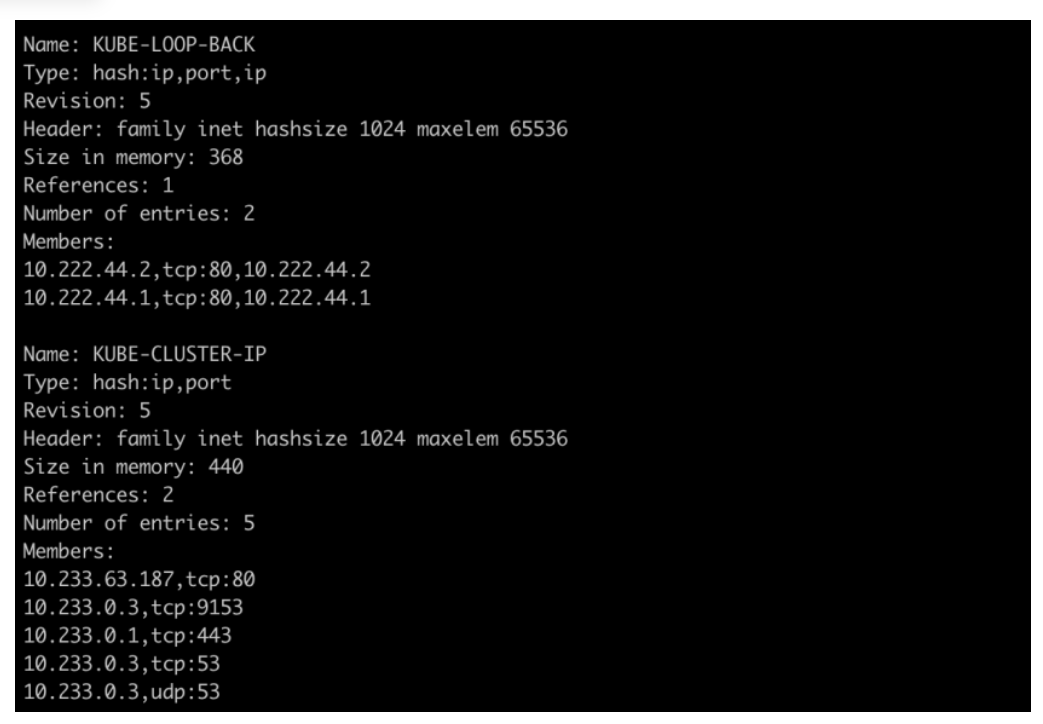
ipset: ipset通过一个KUBE-CLUSTER-IP的实例保存了所有的ClusterIP,当处理源地址伪装,给网络包增加标记这种通用操作时,可以用iptables的match-set 参数统一处理,而不是一个Service配置一条规则,将原有的iptables的链表算法o(n)的复杂度降低到o(1),大大减轻了Linux系统的CPU压力。我们可以通过ipset list 查看本地的ipset集合。
LVS:LVS是linux从内核版本2.4之后内置的功能,是linux自带的负载均衡软件,工作在4层,和iptables类似都是基于netfilter,但是lvs更多的是利用它做负载均衡,他的负载均衡主要是利用了netfilter在INPUT链上做DNAT,更多详细的关于LVS的介绍可以参考:https://www.cnblogs.com/wdliu/p/10279091.html 。我们可以使用ipvsadm工具管理系统的lvs实例。使用ipvsadm查看当前系统所有的lvs负载均衡实例:
ClusterIP实践
简单了解了ipset和lvs之后,我们分析了IPVS模式的kube-proxy的实现方式,首先和上面一样,部署了一个ClusterIP的服务。

查看当前的iptables规则 iptables -nv -t nat -L KUBE-SERVICES

可以看到有三条nat规则,第一条和上面一样,给网络包加了标记,并进行MASQUERADE伪装,,第一条的完整的iptables规则可以通过 iptables-save命令看到:
iptables -A KUBE-SERVICES ! -s 10.222.0.0/16 -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP dst,dst -j KUBE-MARK-MASQ
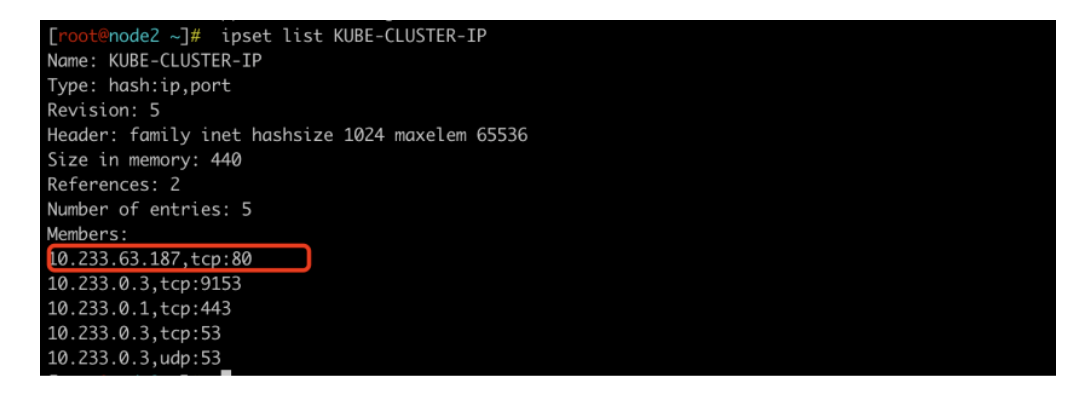
第三条规则是一条ACCEPT规则,意思是对于目的地址为KUBE-CLUSTER-IP集合中的IP地址和端口的流量,直接接受(ACCEPT)并转发这些流量。可以通过ipset命令查看这个集合中的ip地址。执行ipset list KUBE-CLUSTER-IP可以看到包括我们创建的nginx的Service,所有的这个集群的svc的ClusterIP都在里面
我们知道DNAT只能在PREROUTING和INPUT链上进行,通过查看下面的几个链的规则,发现KUBE-SERVICES里面并没有像iptables一样的ClusterIP 到PodIP的DNAT规则,第一条规则是源地址伪装和加标记,第二条规则是关于NodePort的,先不管,第三条是一条ACCEPT规则。

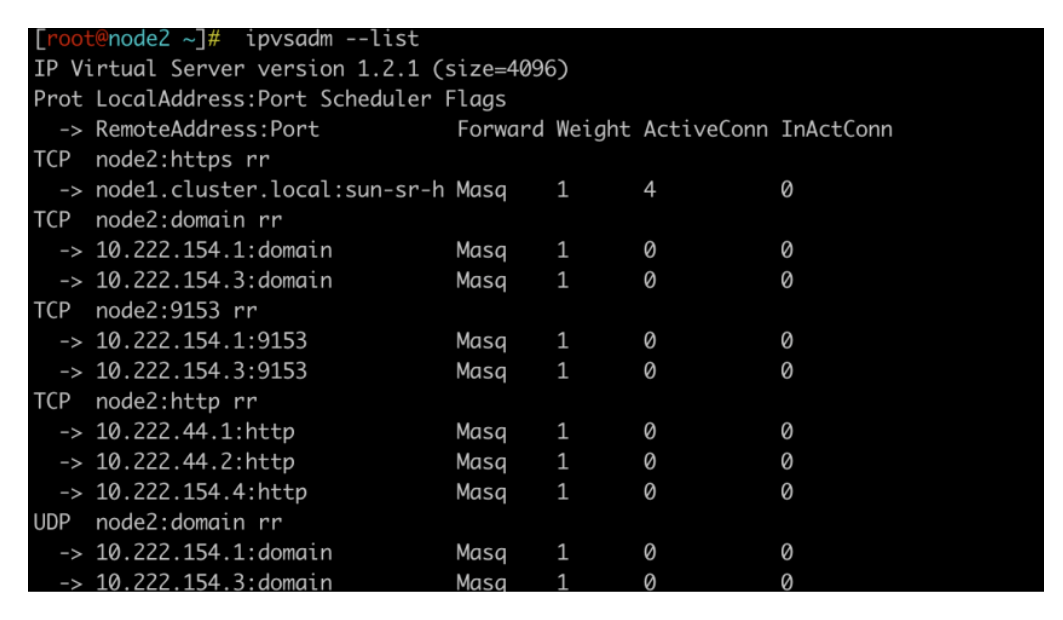
那ClusterIP到PodIP的负载均衡是如何实现的呢,答案是ipvs。上面说过,我们可以使用ipvsadm这个命令查看当前的负载均衡实例数,可以看到这样的一条规则
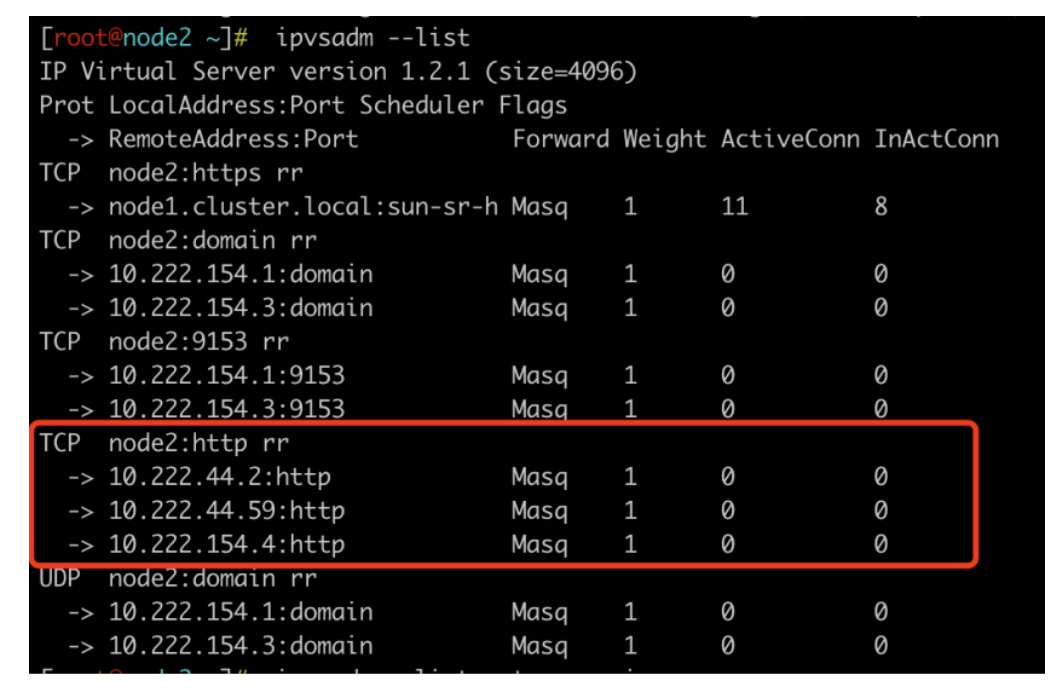
它显示了 TCP 服务节点 node2:http 的转发规则,以及这些规则所指向的后端服务器的 IP 地址和端口号。
具体来说,每行输出表示一个后端服务器,包括以下信息:
•IP 地址和端口号:后端服务器的 IP 地址和端口号,这里分别为 10.222.44.2 和 http(一般是 80 端口)。
•Masq:表示使用了 NAT 转发方式(即使用负载均衡器的 IP 地址作为源地址),而非 DR 或 TUN 转发方式。
•1:表示这个后端服务器的权重为 1,即所有请求都会被平均分配到每个服务器上。
•0:表示这个后端服务器当前的连接数为 0。
•0:表示这个后端服务器的状态为 Active。
执行 ipvsadm -S -n 可以看到类似的结果
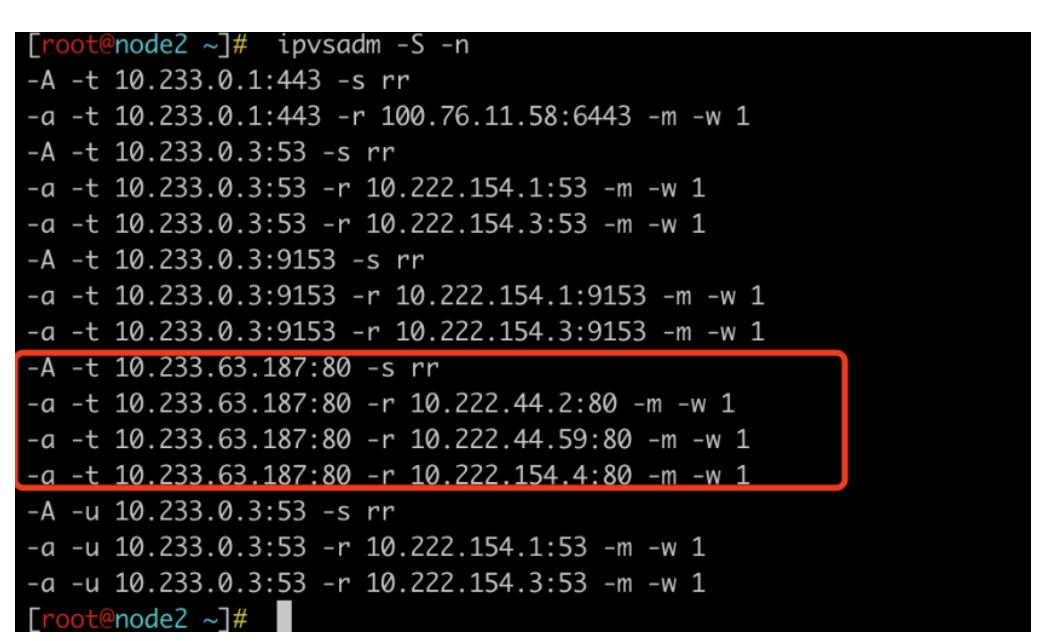
-A 添加了一个Service,-a则添加了这个Service后面的server。
根据之前的先验知识,ipvs模式的k8s会在每个节点存在一个kube-ipvs0的虚拟网卡,查看 ip a发现确实存在
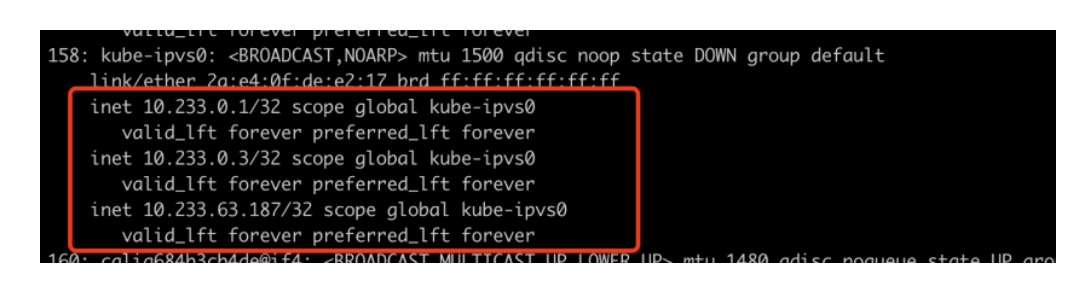
并且,这个网卡有三个ip地址,并且这三个ip地址是集群内所有的Service的ClusterIP,10.233.63.187就是我们部署的nginx的Service。因为Service的ClusterIP都存在kube-ipvs0这个虚拟网卡里,因此理论上,ipvs模式的ClusterIP是能ping通的,事实上确实是这样的。
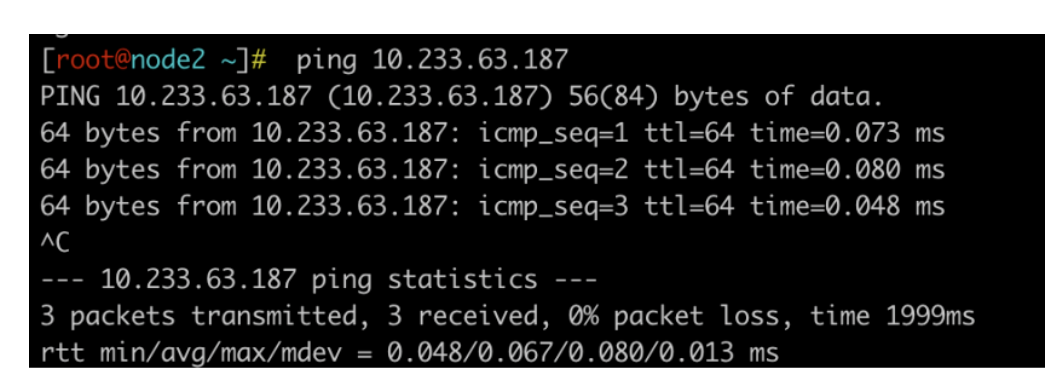
这时,就有这样的问题:这个虚拟网卡的作用是什么,如果去掉这个虚拟网卡会发生什么?
带着这样的问题,我们继续看下iptables的nat表,上面我们已经看过了PREROUTING链和INPUT链

INPUT链里面是空的,而PREROUTING链里面的KUBE-SERVICE里也没有实质的DNAT或SNAT规则。由于在iptables中INPUT和OUTPUT是用于本机内的地址转换(也就是通过本机的网卡转发数据包),所以我们继续看下OUTPUT链。

OUTPUT链里也包含了KUBE-SERVICE这条链,上面已经说过了KUBE-SERVICE里面没有地址转换的规则,这里不再介绍。那kube-ipvs0这个网卡的作用是什么呢,其实很简单,lvs也是基于netfilter的dnat实现的负载均衡,并且挂在INPUT链上,INPUT只能处理转发到本地网卡的网络包,因此本机上必须存在这样的一个虚拟网卡,这样ipvs才能实现DNAT功能,将网络包转发到目的pod,而这个虚拟网卡包含了所有的Service的地址,当访问这个虚拟网卡的时候,由于已经配置了ipvs的规则,所以会被lvs将网络流量转发到负载均衡实例的服务端也就是pod中,跟nginx,haproxy这种能提供负载均衡的组件来相比,lvs的负载均衡处于内核态,不需要指定端口,而处于用户态的nginx,haproxy等都需要提供一个端口去实现负载均衡。
下面我们结合上面看到的各种现象,总结分析下本地curl `ClusterIP`的完整过程:
1.本地发起到ClusterIP请求时,源地址为宿主机ip,目的地址为ClusterIP,因为目的地址为ipset中记录的网络包,所以允许通过(上面说的ACCEPT规则),源地址被伪装成宿主机ip,并且加上了0x4000的标记。
2.网络包到达了kube-ipvs0网卡(网卡里保存着所有的ClusterIP),由于ipvs的底层的netfilter的INPUT规则的作用,根据ipvs的负载均衡策略如轮询,哈希等将目的地址转换成某一个PodIP。
3.经过本地的路由表的作用,网络包经过calico的网卡发往具体的pod,pod开始回包,源地址为PodIP,目的地址为宿主机IP,具体需要经过cni插件涉及的网卡如calixxxx等,不在细说。
4.OUTPUT规则由于源地址不是pod cidr网段,所以不添加标记。
5.POSTROUTING链会判断是否需要进行源地址转换,如果是pod间互访,会将源地址由PodIP转换成网络的出口的网卡的ip,并且POSTROUTING链会判断包是否含有之前的添加的0x4000标记,并做相应的处理,这里不再细说。
上面是宿主机到pod的通信过程,pod到pod的过程更复杂点,但是大同小异,这里不再细说。
NodePort实践
上面我们探讨了`ClusterIP`类型的`Service`在ipvs模式下的实践方式,可以发现,利用ipset让iptables可以处理通用的源地址伪装及添加标记,可以大大减少功能类似的iptables规则。同时,利用一个虚拟网卡,可以使lvs通过`INPUT`链上的规则完成`ClusterIP`到`PodIP`的负载均衡,这种设计大大减轻了iptables规则数量多大导致的k8s的性能瓶颈。下面,基于上一章的内容,我们继续看下`NodePort`的实现方式。
首先将上面部署的Service改成Nodeport模式。查看PREROUTING链上的KUBE-SERVICE链

当通过Nodeport方式访问时,目的地址不在KUBE-CLUSTER-IP这个ipset集合里,因此不会走第一条和第三条规则,会经过第二条规则,看下第二条规则的内容。

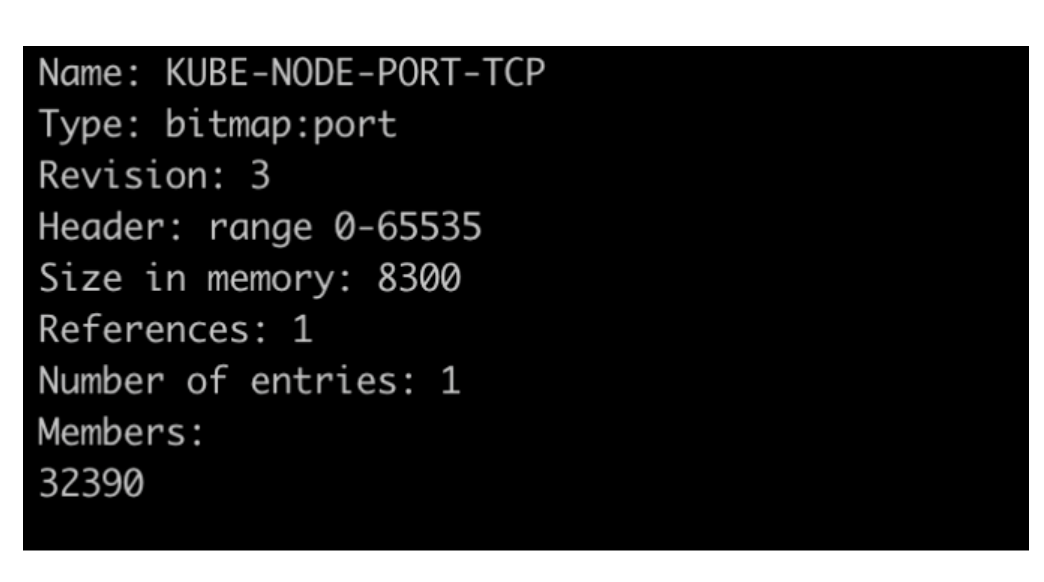
当访问KUBE-NODE-PORT-TCP这个ipset集合中的地址时,会进行源地址伪装。继续看下ipset中这个集合的内容,其中32390就是我们的Service的NodePort端口。
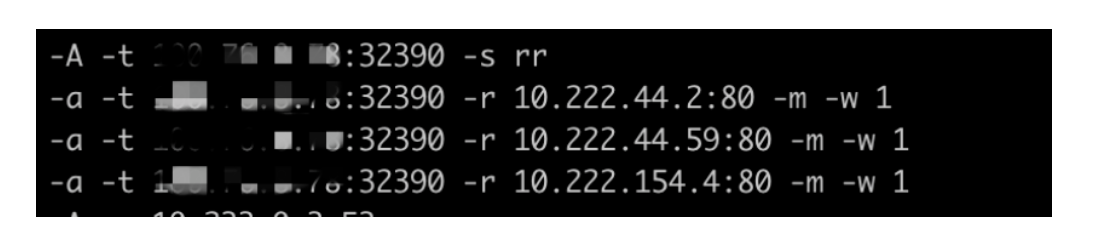
`PREROUTING`链的实现就这么多,后面就是跟`ClusterIP`的`Service`一样的流程,lvs在`INPUT`链上进行负载均衡,只不过是直接从宿主机ip到`PodIP`的DNAT,见截图
DNAT之后,POSTROUTING过程跟ClusterIP一样的。
总结
本文介绍了kube-proxy的两种主要的实现方式:iptables和ipvs,并结合案例,分析了`ClusterIP`和`NodePort`类型的`Service`的实现原理。通过上文的分析,大家可以对iptables和ipvs的两种实现方式进行对比并比较优劣。可以肯定的是,ipvs大大提高了k8s的水平扩展能力,相信随着k8s的部署规模越来越大,应用越来越广泛,ipvs必然会取代iptables成为k8s Service负载均衡的默认实现.
参考文章:
kube-proxy原理剖析
Kubernetes 【网络组件】kube-proxy使用详解
k8s学习:kube-proxy实现原理
kubernetes service 和 kube-proxy详解









![【Azure】Azure成本管理:规划、监控、计算和优化成本 [文末送书]](https://img-blog.csdnimg.cn/80bd63a6318e4b308149d39d16a53c0e.jpeg)