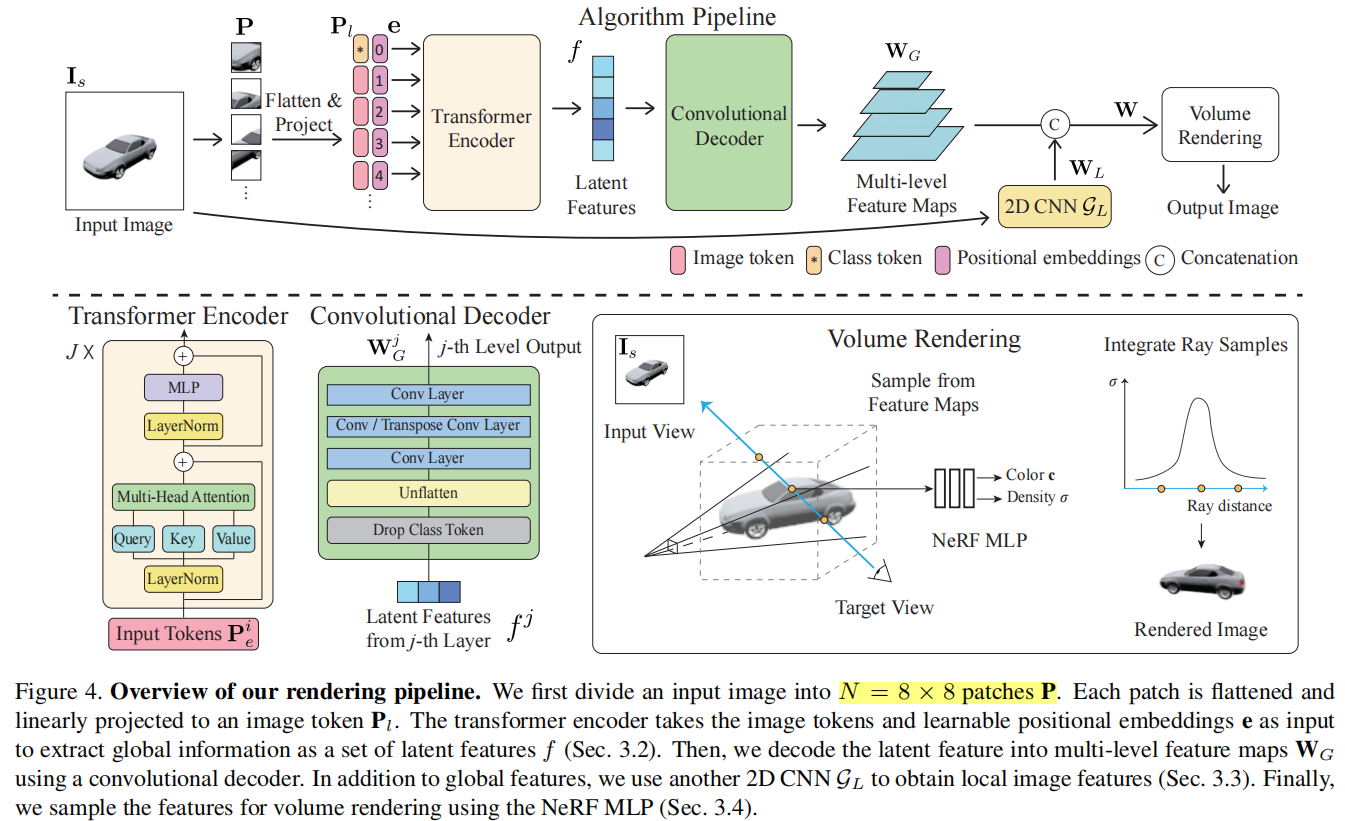
文章目录
- 1.《Vision transformer for nerf-based view synthesis from a single input image》【WACV'2023】
- 摘要
- 动机
- 方法
- 实验
- 2.《SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction》【CVPR'23】
- 动机
- Related work
- Approach
- 总结
- 3.《NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion》【ICML'23】
- 摘要
- 引言
- 背景
- 方法
- 实验
1.《Vision transformer for nerf-based view synthesis from a single input image》【WACV’2023】
摘要
虽然神经辐射场(NeRF)在新视图合成方面显示出令人印象深刻的进展,但大多数方法需要同一场景的多个输入图像和精确的相机姿态。在这篇文章中,作者寻求将NeRF的输入大幅减少到 a single unposed image。现有的使用local image feature来重建3D object的方法通常会在远离input view-point时呈现模糊的预测。这篇文章为了解决这个问题,提出利用global、local特征来构造一个有表现力的3D表征,然后用一个conditional NeRF基于这个3D表征来进行NVS任务。global特征通过一个ViT来学习,local特征通过一个2D CNN来学习。这种新的三维表示允许网络重建unseen regions,而不需要施加像对称性或规范坐标系这样的约束。代码见:https://github.com/ken2576/vision-nerf
动机
最近的工作(Common Objects in 3D; PixelNeRF; PIFu)通过将输入的图像特征投影到查询的三维点上以预测颜色和密度。这些 image-conditioned models在离inpu view很近的target view上可以很好地渲染,但是,当target view离inpu view较远时,如下图所示,对于target view中那些在input view中是invisible的pixels,这些模型的渲染质量会急剧下降。

这篇文章给予的解释是(这种问题已经被这篇文章解释),这样的自遮挡导致 incorrectly-conditioned features。如在下图的例子中,对于target view中的蓝色点(invisible in input view)处的这个轮胎,以往的 image-conditioned models(e.g., PixelNeRF)会将其投影到input view中来extract feature并以此作为condition,但是这样的方式在下图的情况中提取到的特征是“车窗”,这明显是不对应的特征,因此是incorrectly-conditioned feature。使用这样的错误特征作为condition,肯定会导致不正确的预测。

为了解决这个问题,这个文章提出一种新方法,首先将input image 制作为 feature tokens,然后应用ViT学习到 global information,然后,这些 feature tokens被 unflatten 和 resample 到 multi-level feature maps,允许网络以 coarse-to-fine 的方式捕捉全局信息。此外,这篇文章采用一个 2D-CNN 来从input image中捕获细节和外貌这些local features。最后以获取的更好的3Drepresentation来作为NeRF的condition渲染图像。
方法
在single-view NVS任务(single-views NVS也存在)中,对于target view
I
t
I_t
It中的某一个像素点x,如果这个点在source image
I
s
I_s
Is中是可见的,则我们可以直接使用投影到
I
s
I_s
Is上得到的颜色
I
s
(
π
(
x
)
)
I_s(\pi(x))
Is(π(x)) 来作为 target view
I
t
I_t
It上这一点的表征,其中
π
\pi
π是投影操作。但如果这个点在source image
I
s
I_s
Is中是不可见(遮挡)的,我们只能诉诸于
π
(
x
)
\pi(x)
π(x)处颜色之外的信息。 下面是三种收集这种信息的可行性方案:

1)1D latent code方法: 一些方法(CodeNeRF, Occupancy networks, Deepsdf, sharf等)将3D和外貌先验编码金一个 1D global latent vector z,见上图(a),然后使用CNN将它解码为 color c 和 density σ,如下公式。这类方法中,所有的3D points 共享相同的latent code,所以归纳偏置是比较小的。
2)2D spatially-variant image feature 方法: 如上图(b)所示,这类方法计算效率更高,因为他们在2D image上操作而不是在3D voxels上。PixelNeRF是一个典型的例子,定义输出如下:

其中,
x
c
x_c
xc是3D 位置,
d
c
d_c
dc是 ray direction,W是feature map。在这样的方式下,沿着一条ray的所有3D points都共享相同的特征
W
(
π
(
x
t
)
)
W(\pi(x_t))
W(π(xt))。所以这样的表征方式对于 visible area 可以提升渲染质量和计算效率,但是对于 unseen regions 经常产生模糊的预测。
3)3D volume-based approaches 方法: 为了利用三维局部性,另一种方法是将物体视为三维空间中的一组体素,然后应用3D卷积来重建 unseen areas,如上图(c)。比如在《 Fast and explicit neural view synthesis》【WACV】中,voxel grid 可以通过将 2D images 或 feature maps 反投影到一个3D volume中来构造(这有点像NerfDiff中的triplane操作)。对于每一个3D point,我们可以得到它的3D 位置 x 和它的投影特征
W
(
π
(
x
t
)
)
W(\pi(x_t))
W(π(xt))。然后,3D CNN可以利用它邻居体素
x
n
x_n
xn 的的信息来推断 x 处的几何和外貌:

一方面,这样的方法在渲染时速度更快,并且在渲染 unseen regions 时可以利用 3D priors。但另一方面,由于体素大小和接受域有限,这种方法渲染的分辨率也有限。
最后,介绍下本篇文章的方法。这篇文章观察到,1D 方法享有对象的整体视图,并能够以一种紧凑的格式编码整体形状。2D 方法提供了更好的视觉质量,虽然3D方法对其进行了改进,但是volume-based 方法计算效率慢,并且当增大网格尺寸以提高分辨率时需要更多的内存。所以,作者选取2D、1D方法进行结合(但感觉这有点牵强,3D的方法貌似是更合理的)。如下图所示,网络架构很直观,对于一个input image,一边用Transformer提取global information,一边用CNN提取local information,融合后作为condition送入NeRF中。
实验
每个object选取512 rays,batch 为8,在16 A100上训练500K次iteration。
实验在 ShapeNet上的13个类别上进行评估,结果如下:


总结: 问题有趣,对 unseen region的问题描述的很充分,但方法一般。缺点是,对于unseen areas,通过以上1D、2D、3D的哪一种方法获取的feature都不是unseen areas真正对应的特征,只能看作是unseen areas的一种近似或插值(而且3D的方式可能还更合理一些),当是极端的unseen areas时(真正的color与上下文都没关系),即使像本文这样结合了全局和局部的上下文信息,但由于网络本身没有生成能力,也是无法真正做到对unseen area做出合理预测的。作者在最后的limitations上也指出了这个问题,使用生成模型可能对occluded parts的预测很有帮助。
2.《SparseFusion: Distilling View-conditioned Diffusion for 3D Reconstruction》【CVPR’23】
动机
目前稀疏视角3D重建的方法,有两类:
- 一类是比较经典的,基于重投影特征的神经渲染方法。这类方法考虑了几何一致性,但是不能生成unseen region,且在处理大视角变化是效果也差。
- 另一类是替代的,基于(概率)生成的方法。这类方法生成图片的质量更好,但是缺乏3D一致性(对于姿态准确)和重建真实性(看起来更真实)。
这篇文章发现,“几何一致性”和“概率图像生成”不需要进行权衡,它们可以在mode-seeking behavior进行互补。
稀疏视角重建时,NeRF可以通过利用data-driven priors快速地利用multi-view cues,从而实现稀疏重建,但是在 “large viewpoint changes”的情况下,他们会产生模糊的预测,无法在“sparse input views中观测不到的区域”处产生可信的内容。比如说,在下图的两张泰迪熊中,我们观测不到鼻子的内容,所以鼻子部分的内容就属于“sparse input views中观测不到的区域”,当NeRF要预测pose的view包含鼻子部分时,就会产生模糊的结果。“sparse input views中观测不到的区域”放在GeoNeRF中,就是将Geo view中的某一处映射到sparse input views中得到的是pseudo feature的情况(也正因为input views中是pseudo feature,所以NeRF无从参考,可能性就很多)。
- 以下图中泰迪熊为例进行分析,产生这种情况的原因是NeRF没有考虑到输出中的不确定性。比如,泰迪熊的鼻子可能是红色的或黑色的,但NeRF通过减少推断为独立的像素级或点级预测,无法模拟这种变化。

针对上面的问题,这篇文章转而将稀疏重建问题变为建模所有可能图像的分布,即利用一个扩散模型对possible image的分布进行推断。但是,尽管概率图像合成方法允许生成更高质量的图像,它并不直接产生底层对象的3D表示。事实上,多个query views(独立)采样出的输出通常不能对应到一个一致的底层3D模型,例如,如果泰迪熊的鼻子在 context views 中是观察不到的,那么,一个采样的查询视图可能将它涂成红色,而另一个则会涂成黑色。 这种现象是因为概率图像生成方法缺乏3D一致性。
所以为了获取3D一致性的表征,作者提出了一个Diffusion Distillation技巧,将扩散模型预测的分布“distill”到到一个NeRF表征上,即用扩散模型预测分布来解决“NeRF不考虑输出中不确定性”的问题(减少模糊),用NeRF表征提供3D一致性(多视角对应目标一致)。其实,读到这里可以发现,在方法上,这篇文章与DreamFusion非常相似,都是蒸馏扩散模型的知识来监督NeRF的训练。
作者还注意到,条件扩散模型不仅能够采样novel view images,而且还能够(近似地)计算生成的图像的似然。为什么这么说?因为生成图像的似然是指在给定生成模型和参数的情况下,计算生成的图像与真实观测图像之间的概率或可能性,而条件扩散模型的训练是基于对数似然的最大化,这意味着模型在训练过程中会尝试最大化生成真实图像的概率。在这样的insight下,作者通过最大化NeRF渲染图像的基于扩散的似然,来优化NeRF。
这样的方式就导致了 mode-seeking optimization,即能像diffusion model那样生成高质量的图像,又可以保持NeRF的3D一致性。mode seeking的意思是指:比如,用两张消防栓图片合成的是消防栓场景,两张狗狗的图片合成的是狗狗的场景,而不会合成消防栓,所以使用的图片就对场景做出了选择,以后遇到训练集中没见过的类别,也能够做出正确的视角生成。
Related work
Instance-specific Reconstruction from Multiple Views. 尽管有些工作寻求减少input views,但是它们也不能够预测 unseen regions。
Single-view 3D Reconstruction. 预测 beyond the visible 的 3D geometry (and appearance) 的能力是单视图三维预测方法的一个关键目标。之前的方法追求在不同的3D表征上预测,比如体素、网格、神经表征等,但是由于输入是单一的图像,这从根本上限制了可以预测的细节。注意,novel view synthesis和reconstruction还是有区别的,前者要求是合成图像,后者要求重建出场景的3D结构或外貌。
Generalizable View Synthesis from Fewer Views. 泛化性的工作,一条线是基于feature re-projection,比如IBRNet、GPNR、FWD、PixelNeRF、NeRFormer等,这类方法保持了3D一致性,但是它们回归到均值,并不能产生感知上尖锐的输出;另一条线是将NVS看作是一个2D生成任务,比如ViewFormer、SRT、LFN等,这类工作生成的质量更好,但代价是更大的失真和3D一致性。在下表中,是目前方法的对比。需要注意的是,Generalization 和 Generate unseen是两种情况,Generalization指的是生成新的场景,Generate unseen指的是还生成当前场景,但是生成input views中unseen的regions。

Concurrent work. 3DiM【ICLR’23】 提出了一种用于 image-conditioned 的新视图合成的二维扩散方法,与这篇文章的不同之处是没有推断出三维表示。Nerdi【CVPR’23】 更接近这篇工作,使用二维扩散模型作为single-view三维的指导,但在这种挑战性的环境下重建的结果更粗糙。Renderdiffusion【CVPR’23】 直接在3D space中学习扩散模型,与我们利用二维扩散模型来优化三维不同。
Approach
由于物体的某些方面可能没有被观察到,而且其几何形状难以精确推断,直接预测3D或 novel view 会导致不确定性区域的输出是难以置信的模糊。因此为了确保 plausible 和 3D-consistent 的预测,这篇文章采取了如下图所示的 two-step 方法。π是target view pose,C是reference view的(img, pose)。
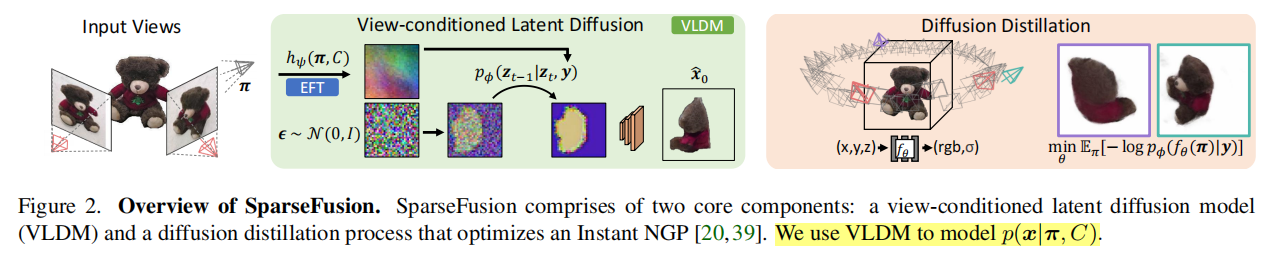
首先,使用一个epipolar feature transformer (EFT,受启发于GPNR)作为特征提取器,在上下文为C的情况下获取π视角下的低分辨率特征y。紧接着,训练一个view-conditioned latent diffusion model (VLDM) 来建模
p
(
x
∣
π
,
C
)
p(x|π, C)
p(x∣π,C)。
Epipolar Feature Transformer:该篇文章提出的这个EFT是基于GPNR的前馈网络g(r,C),它预测r视角下的图像每个像素点的color,通过沿着每个像素点在input views上的极线提取特征来实现。这里对GPNR中的网络进行了一些修改:将patch projection layer换成一个ResNet-18,并修改最后一层以同时预测颜色(g(·))和特征向量(h(·))。作者训练g(·)作为一个强的baseline,并将h(·)作为几何特征输入至VLDM中,也就是将EFT看作一个几何特征提取器。
虽然EFT可以直接预测novel views,但像素级预测机制不允许它建模潜在的概率分布,从而导致不确定性区域下的模糊均值搜索预测。

上图是VLDM的细节图,首先将target view image用一个encoder编码为latent
z
0
z_0
z0作为ground truth,依次作为diffusion model的输出,然后将EFT输出的 geometry feature y作为反向过程的condition,以此来训练扩散模型,见下面公式。其实就是在latent space上训练一个diffusion model,之所以叫view condition diffusion model,就是从input view中抽取出一个 feature vector作为condition。

VLDM的预测结果可视化如下,对于不确定性的不可见区域,VLDM可以生成多种结果。

虽然能够通过VLDM在不确定性的unseen regions生成真实的高质量预测,但是这种方式不能输出一个3D表示。事实上,由于VLDM模拟了图像上的分布,从它采样的视图不能(也不应该!)对应于一个单一的底层3D解释,因为每个采样点的目标都是不一样的。
最终的训练过程如下:不是将VLDM预测的
z
^
0
\hat{z}_0
z^0直接拿来与NeRF的输出相减作为损失,而是将NeRF的输出作为
z
0
z_0
z0,预测
z
^
0
\hat{z}_0
z^0,这就是文章中所说的最小化负对数似然。

总结
这篇文章从“生成模型缺乏3D一致性,NeRF缺乏生成质量” 的角度来概述现在泛化性NeRF工作的角度很有道理,此外,本篇文章提出的EFT从reference views提取geometry vector 作为diffusion model 的condition也很有用。
3.《NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion》【ICML’23】
摘要
从单个图像合成新的视图需要推断对象和场景的遮挡区域,同时保持与input的语义和物理一致性。现在的方法将 NeRF condition在local 图像特征上,然后聚合这些特征进行体素渲染。但是,在严重遮挡情况下,这种投影不能解决不确定性,因此导致缺乏细节的模糊渲染。
引言
稀疏NVS的目的是,在给定一个object或一个scene的几个输入视图的情况下,从其他视角下合成新的视图。这个问题是具有挑战性的,因为新的视角必须解释 遮挡 和 看不见的区域 。 这个问题有很长时间的历史,可以追溯到imagebased rendering (IBR)。但是,IBR只能产生次优结果,并且通常是特定于场景的。最近,神经辐射场(NeRF)展现出了高质量的NVS结果,但是它需要数十或数百张图像来过拟合一个场景,并且没有泛化推断新场景的能力。新视图中unseen regions的uncertainty不能被映射到input views上的投影所解决,因为这是伪特征。
解决单视角合成中这种不确定性问题的一个独特工作路线是:利用condition on input views的2D生成模型来预测novel views(《Geometry-free view synthesis: Transformers and no 3d priors.》,《Novel view synthesis with diffusion models》)。这些方法就是向生成模型输入input views作为condition,直接生成novel views,但是,这些方法只能合成部分3D-一致的图像,因为扩散模型的输出常常是multi-view inconsistent。
这篇工作关注于从单张图片进行NVS。为了实现这样,一些泛化性的工作已经被做(GRF、PixelNeRF等),其中NeRF是condition在聚集3D点映射到的特征上。这些方法可以产生好的结果,尤其是在离input-view相近的view-point下。然而,当target view-point远离input时,这些方法会产生模糊的结果。(可以概括这类特征为伪特征,然后总览下SparseFusion,NeRF-Diff关于uncertainty of unseen regions的动机。)
在这篇文章中,作者提出了NerfDiff,一个训练-微调框架用于在给定单视角图像情况下合成多视角一致、高质量的新视角图像。其实就是利用了生成模型可以生成高质量图像的优势,但并不直接生成,而是将其生成的信息蒸馏到NeRF中,从而获取3D一致性,与此同时生成模型还可以预测unseen regions,这也解决了泛化性NeRF在unseen region处预测模糊的问题。这种思路和解释其实与SparseFusion是一样的,都是将两种范式结合起来,互相弥补缺点。
贡献点:
- 提出了一种名为NerfDiff的框架,联合学习一个image-conditioned NeRF和一个 conditional diffusion model (CDM),然后在测试阶段使用多视图一致的扩散模型来微调学到的NeRF(在new scene上需要retrain)。
- 提出了一个基于 camera-aligned triplanes 的 image-conditioned NeRF,这是从CDM实现高效渲染和微调的核心组件。
- 提出了一种三维感知的CDM,它将体积渲染集成到二维扩散模型中,便于泛化到新的视图(not generalization to new scene)。
背景
image-conditioned NeRF
原始NeRF的训练,需要数十或数百张 posed images来提供充足的 multi-view constraint。但在现实中,这样的多视角数据不是简单可以获取的。因此,这篇工作把焦点放在从single unposed image中恢复神经辐射场。因为这样的一个问题是 under-constrained(欠约束的),所以它需要从类似于目标场景的大量场景中学习到三维归纳偏置。也正是遵循这种philosophy,pixel-aligned NeRFs(PixelNeRF、VisionNeRF)用局部2D图像特征编码3D信息,以便学习到的表示在经过大量场景训练后,可以推广到不可见的场景。
PixelNeRF
给定一个图像
I
s
I^s
Is,PixelNeRF首先通过一个encoder
e
ϕ
e_\phi
eϕ提取feature volume(就是一个多通道特征图)。然后,对于target view相机空间下的每一个3D point x,它对应的image features都可以通过内参矩阵将 x 映射到 image plane上,然后在feature volume上进行双线性插值来获取。然后获取到的特征与(x,d)联合起来预测color和density。如下图所示,PixelNeRF可以实现single-view NVS,并且由于projected feature的加入模型也具有了泛化 unseen scenes的能力。

Challenges(主要是 uncertainty challenge)
但是,现有的 single-image NeRF无法产生 high-fidelity(高保真) 的渲染结果,尤其是当严重的遮挡存在时。这是因为 single-image view synthesis 是一个under-constrained问题,因为合成的遮挡区域可以表现为多种可能性。因此,使用MSE loss训练这种情况时,它会强迫模型在所有可能的解决方案之间回归到平均像素值,从而产生不准确和模糊的预测。为什么这么说呢,因为假如使用 MSE 当作损失的话,对于一个target view rendered image,MSE只会让它的每一个像素值回归到GT image上。对于occluded region而言,GT image上对应的这个区域只是其所有可能性分布中的一个采样点,如果只以其作为GT的话,会变为均匀分布。以这样的GT来监督模型训练的话,会导致不正确或模糊。

Geometry-free View Synthesis
在NVS任务中,之前的方法要用到 geometric information ,就是需要通过各种方法来估计场景的一个显式三维几何结构,比如深度图、点云、3D模型等,然后利用摄像机的姿态生成准确和3D一致的结果。
近年来,Geometry-free 提供了另一种途径来合成新视角图像,它们不明确依赖于显式的 3D 几何信息,如深度图、点云、三维模型等三维几何结构,而主要利用可用的视觉信息,如输入图像或视频帧,然后通过渲染等技术来生成所需的视图。
为了解决uncertainty challenge,一种独特的路线是使用2D生成模型来预测novel views。以3DiM为例,它学习了一个条件噪声预测器
ϵ
ϕ
\epsilon_\phi
ϵϕ,它在input view和相应target pose的condition下,对高斯噪声的target image降噪 (。下面是这个模型的优化方程,其中
I
I
I是target image,
I
s
I^s
Is是input image。
Z
t
Z_t
Zt是对
I
I
I进行加噪过程的第t步的噪声。根据《Generative modeling by estimating gradients of the data distribution》【Nips’2019】,降噪器是对分布的分数函数(对数似然关于参数的偏导)的一种近似:

也就是说,训练时学习到的这个降噪器
ϵ
ϕ
\epsilon_\phi
ϵϕ,其实就是一个分数函数。所以在测试时,学到的这个分数
ϵ
ϕ
\epsilon_\phi
ϵϕ被重复的运用来去噪noised image,合成novel views。3DiM这类方式,是使用生成模型直接预测target view image。
但是,Geometry-free methods 通常会出现“对齐问题”,这指的是generated views应该在目标的shape和appearance层面与conditioning view能够alignment。在Geometry-free methods中,没有对object的几何进行显式建模,而是依赖学习一种从 conditioning view 到target view中的映射,因此当conditioning view是input view时,就会与generated views不匹配,从而导致生成的结果出现 artifacts 和 inconsistencies 。对于这个问题,3DiM试图使用交叉注意力来聚集input view中的信息来解决,但是,这样的方式需要模型具有很大的容量,并且即使这样,它对复杂场景和分布外的cameras的泛化能力也不够强。此外,由于每个视图都是在二维视图中独立进行的,而不是在三维数据中进行的,因此在采样阶段,CDM的合成新视图往往是多视图不一致的(因为在3D中进行的话,就会有一个统一的3D参照物)。
方法
为了实现两全其美,这篇文章提出NerfDiff来合并diffusion model和image-conditioned NeRF的力量,框架如下所示。这是一个两阶段的 training-finetuning 框架,先trainning,然后finetuning。

在训练阶段,用target view训练 single-image conditioned NeRF 和 2D CDM(与DreamFusion不同,不是预训练模型,需训练)。然后在测试阶段,将CDM冻结,用此时CDM的采样来监督NeRF的渲染,finetuning NeRF。也就是说,训练阶段同时训练NeRF和扩散模型,测试阶段冻结扩散模型,只训练NeRF。
架构的细节如下。在PixelNeRF和VisionNeRF中,对于target ray上的某个3D point,它们将其映射到image plane上然后提取特征作为该3D点的特征,这样就会导致一个问题: 该3D点的深度信息没有体现在所提取的特征上,也就是这条target ray上的所有points投影到image plane上的相同位置,然后提取相同的特征。所以为了区别这些点,PixelNeRF和VisionNeRF会为这些extracted features拼接上一个在当前camera space中所处空间位置的位置编码,这需要用MLP网络来融合image features、spatial information,因此减缓了渲染过程。因此,作者这里启发于《Efficient geometry-aware 3D generative adversarial networks》【CVPR’22】,提出将提取出的image feature W reshape到一个camera-aligned triplane上{
W
x
y
,
W
x
z
,
W
y
z
W_{xy}, W_{xz}, W_{yz}
Wxy,Wxz,Wyz},然后在三个平面上分别进行投影和双线性插值提取特征并拼接起来。以这样的方式就无需位置编码,进而提升效率。xy平面被aligned到input image上,然后xz,yz平面都与这个平面正交。这样的方式有以下优点:1)triplane可以保存local features;2)不需要假设一个全局坐标系和全局相机姿态,这不同于现有的triplane-based方法。此外,作者这里将预训练的RestNet换为U-Net,理由是U型连接和自注意力模块可以使输出的image feature W同时包含local 和global的信息,这对预测occluded regions是重要的,这一操作与VisionNeRF相似。

截至目前,尽管 single-image NeRF能够产生 multi-view consistent images,但结果常常是模糊的,由于 uncertainty 问题。所以为了解决这个问题,作者在 single-image NeRF 之后引入了一个 CDM。具体来说,这个CDM的作用是:细化 single-image NeRF渲染出来的结果,以至于与 target view相同。
与现今的geometry-free methods相比(在3DiM中指出),这里将NeRF渲染出的结果作为CDM的condition(与SparseFusion、DreamFusion相同),而不是将input view作为CDM的condition,从而避免了“alignment”问题。
合成的图像更sharper,意思是合成的图像更清晰。
为了解决CDM采样引起的inconsistency问题,这篇文章提出在第二个阶段(微调)中使用的 NeRF-Guided Distillation算法来提升微调性能。在微调时,一个naive的想法就是从CMD的预测中采样一个virtual view,然后以此来监督 NeRF Rendered。但是作者发现这样的方式效果不好,因为 CDM predictions的inconsistency会导致再优化NeRF时的混淆。因此作者启发于《Diffusion models beat gans on image synthesis》【Nipes’21】,通过考虑每个virtual view的联合分布,将三维一致性纳入到multi-view扩散中:

这样,目标就变为找到一个使上式最大化的NeRF参数(θ, W),同时从CDM预测virtual view的联合分布中采样出最有可能的virtual view(
Z
t
Z_t
Zt)。其实就是挑选一个最合适的virtual view来进行NeRF训练,从而避免了混淆的问题。遵循上式后,更改后的 diffusion score (就是 denoiser)可以写作:

其中,
I
θ
,
W
I_{θ, W}
Iθ,W是渲染出的图像,
I
t
I^t
It是input image,
I
t
I_{t}
It是第t步预测的target image。
在微调阶段,蒸馏NeRF时,直接最大化关于NeRF参数联合分布的对数似然,这相等于最小化所有virtual views的denoised images I_t和NeRF rederings I_{θ,W}的MSE损失。这个优化操作与SparseFusion是一样的,目的都是为了去除“CDM predictions的inconsistency导致在采样virtual view优化NeRF rendering时引起的conflict problem”,从而将MSE的优化目标,改为最小化关于NeRF参数的负对数似然,其实就是希望从CDM predictions挑选一个最合适的virtual view 来进行NeRF的监督。
与SDS的关系。
实验
训练时长:8-A100上训练4天。








![【Azure】Azure成本管理:规划、监控、计算和优化成本 [文末送书]](https://img-blog.csdnimg.cn/80bd63a6318e4b308149d39d16a53c0e.jpeg)