使用Word Embedding实现中文自动摘要
- 主要步骤
- 中文语料库
- 数据预处理
- 生成词向量
- 把文档的词转换为词向量
- 生成各主题的关键词
- 检查运行结果
- 参考资料
本文通过一个实例介绍如何使用Word Embedding实现中文自动摘要,使用
Gensim中的word2vec模型来生成Word Embedding。
主要步骤
1)导入一个中文语料库
2)基于这个中文语料库,搭建word2vec模型,训练得到各单词的词向量;
3)导入一个文档,包括各主题及其概要描述信息,预处理该文档,并转换为词向量;
4)用聚类的方法,生成各主题的若干个关键词。
中文语料库
本文采用的是搜狗实验室的搜狗新闻语料库,数据链接https://github.com/garfieldkai/word2vec/blob/master/data/corpus.txt
下载下来的文件名为: news_sohusite_xml.smarty.tar.gz
数据预处理
1)解压并查看原始数据
cd 到原始文件目录下,执行解压命令:
tar -zvxf news_sohusite_xml.smarty.tar.gz
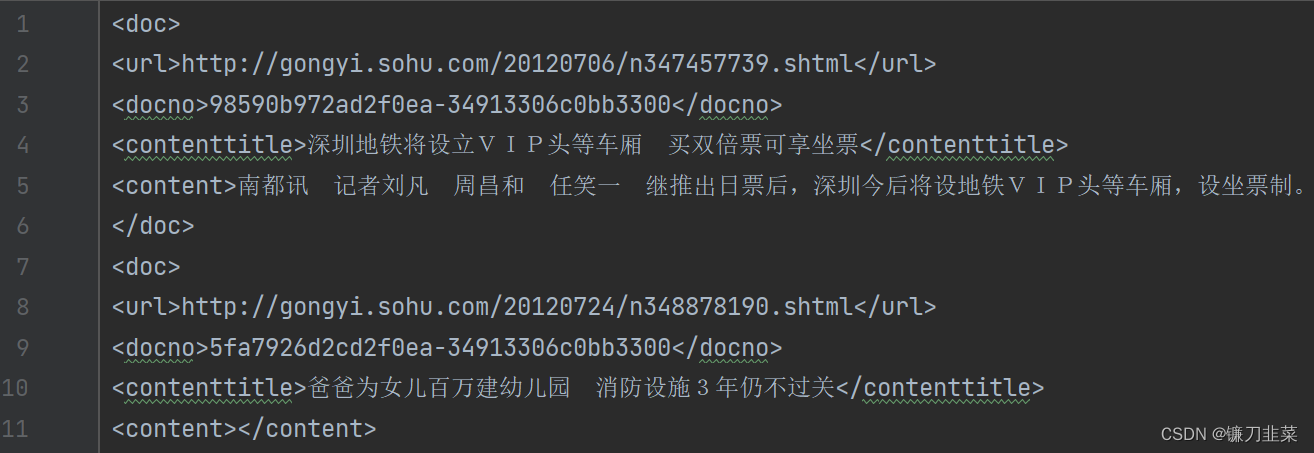
得到文件news_sohusite_xml.dat, 用vim打开该文件,
vim news_sohusite_xml.smarty.dat
得到如下结果:
2)取出内容
取出<content> </content> 中的内容,执行如下命令:
cat news_sohusite_xml.smarty.dat | iconv -f gbk -t utf-8 -c | grep "<content>" > corpus.txt
windows下可以使用
type news_sohusite_xml.smarty.dat | iconv -f gbk -t utf-8 -c | findstr "<content>" > corpus.txt
得到文件名为corpus.txt的文件,可以通过vim 打开
vim corpus.txt
得到如下效果:

3)分词
利用jieba分词,过滤停用词等,代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/8 11:39
# @Author : Alvaro Pang
# @File : cutWord.py
# @Software: PyCharm
import jieba
import numpy as np
filePath = 'corpus.txt'
fileSeqWordDonePath = 'corpusSeqDone_1.txt'
# 打印中文列表
def PrintListChinese(list):
for i in range(len(list)):
print(list[i])
# 打印文件内容到列表
fileTrainRead = []
with open(filePath, 'r', encoding='utf-8') as fileTrainRaw:
for line in fileTrainRaw: # 按行读取文件
fileTrainRead.append(line)
# jieba分词后保存在列表中
fileTrainSeq = []
for i in range(len(fileTrainRead)):
fileTrainSeq.append([' '.join(list(jieba.cut(fileTrainRead[i][9:-11], cut_all=False)))])
if i % 10000 == 0:
print(i)
# 保存分词结果到文件中
with open(fileSeqWordDonePath, 'w', encoding='utf-8') as fW:
for i in range(len(fileTrainSeq)):
fW.write(fileTrainSeq[i][0])
fW.write('\n')
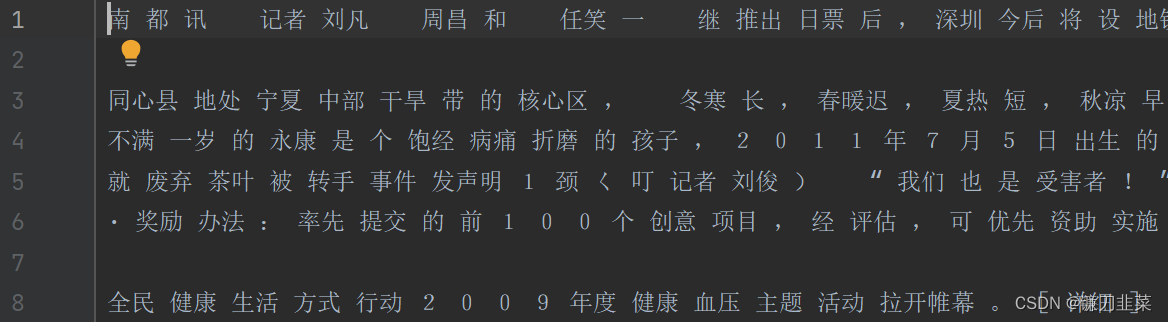
可以得到文件名为 corpusSegDone_1.txt 的文件,需要注意的是,对于读入文件的每一行,使用结巴分词的时候并不是从0到结尾的全部都进行分词,而是对[9:-11]分词 (如行22中所示: fileTrainRead[i][9:-11] ),这样可以去掉每行(一篇新闻稿)起始的 和结尾的。得到如下图所示的结果:
生成词向量
使用Gensim word2vec库生成词向量,代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/10 1:07
# @Author : Alvaro Pang
# @File : wordvectors.py
# @Software: PyCharm
import warnings
import logging
import os.path
import sys
import multiprocessing
import gensim
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
# 忽略警告
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')
if __name__ == '__main__':
program = os.path.basename(sys.argv[0]) # 读取当前文件的文件名
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s', level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# inp为输入语料,outp1为输出模型,outp2为vector格式的模型
inp = './corpusSeqDone_1.txt'
out_model = './corpusSeqDone_1.model'
out_vector = './corpusSeqDone_1.vector'
# 训练skip-gram模型
model = Word2Vec(LineSentence(inp), vector_size=50, window=5, min_count=5, workers=multiprocessing.cpu_count())
# 保存模型
model.save(out_model)
# 保存词向量
model.wv.save_word2vec_format(out_vector, binary=False)
把文档的词转换为词向量
对数据进行预处理,并用Skip-gram模型将其转换为词向量:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/13 21:10
# @Author : Alvaro Pang
# @File : textvectors.py
# @Software: PyCharm
# 采用word2vec词聚类方法抽取关键词1——获取文本词向量表示
import sys, codecs
import pandas as pd
import numpy as np
import jieba
import jieba.posseg
import gensim
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim') # 忽略警告
# 返回特征词向量
def getWordVec(wordList, model):
name, vecs = [], []
for word in wordList:
word = word.replace('\n', '')
try:
if word in model: # 模型中存在该词的向量表示
name.append(word)
vecs.append(model[word])
except KeyError:
continue
a = pd.DataFrame(name, columns=['word'])
b = pd.DataFrame(np.array(vecs, dtype='float'))
return pd.concat([a, b], axis=1)
# 数据预处理操作:分词、去停用词、词性筛选
def dataPrepos(text, stopkey):
l = []
pos = ['n', 'nz', 'v', 'vd', 'vn', 'l', 'a', 'd'] # 定义选取的词性
seq = jieba.posseg.cut(text) # 分词
for i in seq:
if i.word not in l and i.word not in stopkey and i.flag in pos: # 去重+去停用词+词性筛选
l.append(i.word)
return l
# 根据数据获取候选关键词词向量
def buildAllWordsVecs(data, stopkey, model):
idList, titleList, abstractList = data['id'], data['title'], data['abstract']
for index in range(len(idList)):
id = idList[index]
title = titleList[index]
abstract = abstractList[index]
l_ti = dataPrepos(title, stopkey) # 处理标题
l_ab = dataPrepos(abstract, stopkey) # 处理摘要
# 获取候选关键词的词向量
words = np.append(l_ti, l_ab) # 拼接数组元素
words = list(set(words)) # 数组元素去重,得到候选关键词列表
wordvecs = getWordVec(words, model) # 获取候选关键词的词向量表示
# 词向量写入csv文件,每个词400维
data_vecs = pd.DataFrame(wordvecs)
data_vecs.to_csv('./vecs/wordvecs_' + str(id) + '.csv', index=False)
print("document ", id, " well done.")
def main():
# 读取数据
dataFile = './sample_data.csv'
data = pd.read_csv(dataFile)
# 停用词表
stopkey = [w.strip() for w in codecs.open('stopWord.txt', 'r', encoding='utf-8').readlines()]
# 词向量模型
inp = 'corpusSeqDone_1.vector'
model = gensim.models.KeyedVectors.load_word2vec_format(inp, binary=False)
buildAllWordsVecs(data, stopkey, model)
if __name__ == '__main__':
main()
生成各主题的关键词
采用聚类方法对候选关键词的词向量进行聚类分析。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/7/14 23:08
# @Author : Alvaro Pang
# @File : clustertopics.py
# @Software: PyCharm
# 采用word2vec词聚类方法抽取关键词2——根据候选关键词的词向量进行聚类分析
import sys, os
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
# 对词向量采用K-mean聚类抽取topK关键词
topK = 6
os.environ["OMP_NUM_THREADS"] = '1'
def getkeywords_kmeans(data, topK):
words = data['word'] # 词汇
vecs = data.iloc[:, 1:] # 向量表示
kmeans = KMeans(n_clusters=1, random_state=10).fit(vecs)
labels = kmeans.labels_ # 类别结果标签
labels = pd.DataFrame(labels, columns=['label'])
new_df = pd.concat([labels, vecs], axis=1)
df_count_type = new_df.groupby('label').size() # 各类别统计个数
print(df_count_type)
vec_center = kmeans.cluster_centers_ # 聚类中心
# 计算距离(相似性)采用欧式距离
distances = []
vec_words = np.array(vecs) # 候选关键词向量,dataFrame转array
vec_center = vec_center[0] # 第一个类别聚类中心,本例只有一个类别
length = len(vec_center) # 向量维度
for index in range(len(vec_words)): # 候选关键词个数
cur_wordvec = vec_words[index] # 当前词语的词向量
dis = 0 # 向量距离
for index2 in range(length):
dis += (vec_center[index2] - cur_wordvec[index2]) * (vec_center[index2] - cur_wordvec[index2])
dis = math.sqrt(dis)
distances.append(dis)
distances = pd.DataFrame(distances, columns=['dis'])
result = pd.concat([words, labels, distances], axis=1) # 拼接词语与其对应中心的距离
result = result.sort_values(by="dis", ascending=True) # 按照距离大小进行升序排列
# 将用于聚类的数据的特征维度将到2维
pca = PCA(n_components=2)
new_pca = pd.DataFrame(pca.fit_transform(new_df))
# 可视化
d = new_pca[new_df['label'] == 0]
plt.plot(d[0], d[1], 'r.')
d = new_pca[new_df['label'] == 1]
plt.plot(d[0], d[1], 'go')
d = new_pca[new_df['label'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.gcf().savefig('kmeans.png')
plt.show()
# 抽取排名前topk个词语作为文本关键词
wordlist = np.array(result['word']) # 选择词汇列并转换成数组格式
word_split = [wordlist[x] for x in range(0, topK)] # 抽取前topK个词汇
word_split = " ".join(word_split)
return word_split
def main():
# 读取数据集
dataFile = 'sample_data.csv'
articleData = pd.read_csv(dataFile)
ids, titles, keys = [], [], []
rootdir = "vecs" # 词向量文件根目录
fileList = os.listdir(rootdir) # 列出文件夹下所有的目录与文件
# 遍历文件
for i in range(len(fileList)):
filename = fileList[i]
path = os.path.join(rootdir, filename)
if os.path.isfile(path):
data = pd.read_csv(path) # 读取词向量文件数据
article_keys = getkeywords_kmeans(data, topK) # 聚类算法得到当前文件的关键词
print(article_keys)
article_keys = article_keys
# 根据文件名获得文章id以及标题
(shortname, extension) = os.path.splitext(filename) # 得到文件名和文件扩展名
t = shortname.split('_')
article_id = int(t[len(t) - 1]) # 获得文章id
article_tit = articleData[articleData.id == article_id]['title'] # 获得文章标题
article_tit = list(article_tit)[0] # series转成字符串
ids.append(article_id)
titles.append(article_tit)
keys.append(article_keys)
# 将所有结果写入文件
result = pd.DataFrame({"id": ids, "title": titles, "key": keys}, columns=["id", "title", "key"])
result = result.sort_values(by='id', ascending=True)
result.to_csv('keys_word2vec.csv', index=False)
if __name__ == '__main__':
main()
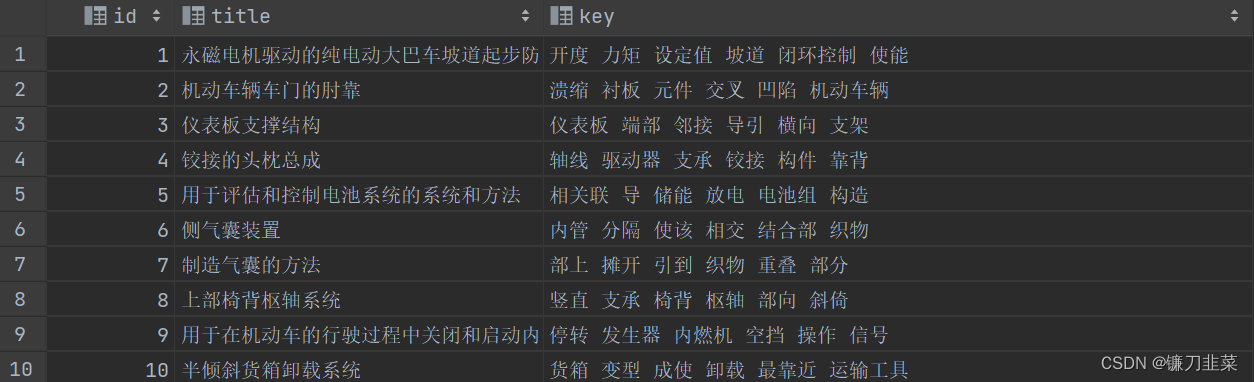
检查运行结果
查看生成的各个主题的关键词,如下:
参考资料
- 《深入浅出Embedding——原理解析与应用实践》 吴茂贵 王红星 著
- 搜狗语料库word2vec获取词向量
- 用Word2Vec训练中文词向量(一)