人体姿态估计&动作识别
视频演示
Refs: https://www.zhihu.com/zvideo/1227562268420235264
姿态估计与行为识别(行为检测、行为分类)的区别
Refs:姿态估计与行为识别(行为检测、行为分类)的区别
姿态估计
- 定位图片和视频中的人体关节,重建人的关节和肢干。
- 四个方向:
- 单人姿态估计(Single-Person Skeleton Estimation):先定位人体,再根据行人区域,找出关键点。
- 多人姿态估计(Multi-Person Pose Estimation):两种方式:
- Top-down: 先定位到图片中的所有人体,在找出关键点。
- bottom-up:先找出关键点,再组装成行人。
- 人体姿态跟踪(Video Pose Tracking):
- 人体关键点在视频中的temporal motion会比较大,比如一个行走的行人,手跟脚会不停的摆动,所以跟踪难度会比跟踪人体框大。
- 数据集:PoseTrack
- 3D人体姿态估计(3D skeleton Estimation): ^764e2c
- VS 2D:
- 2D姿势估计:从RGB图像估计每个关节的2D姿势(x,y)坐标。
- 3D姿势估计:从RGB图像估计3D姿势(x,y,z)坐标。
- 即使基于轻量主干网络(MobileNetV2)所预测的2D姿态用于动作识别时,效果也好于任何来源的3D人体姿态估计。Ref
- 数据集:Human3.6M
- VS 2D:
行为识别(Action Detection/Regnition)
概述
- 图像或视频中目标的行为类别。
- 两个方向:
- 行为分类(Action Recognition)
- 定义:一般使用的数据集会将动作分割好,一个视频片段包含一段明确的动作。
- 特点:时间短且有唯一确定标签。所以input为视频,输出为label。类似Image Classification。
- 数据集:
- https://zhuanlan.zhihu.com/p/86461157 (都是剪切好的视频,不符合行为检测的要求)
- 行为检测(Temporal Action Localization)
-
当前主流利用I3D来做:
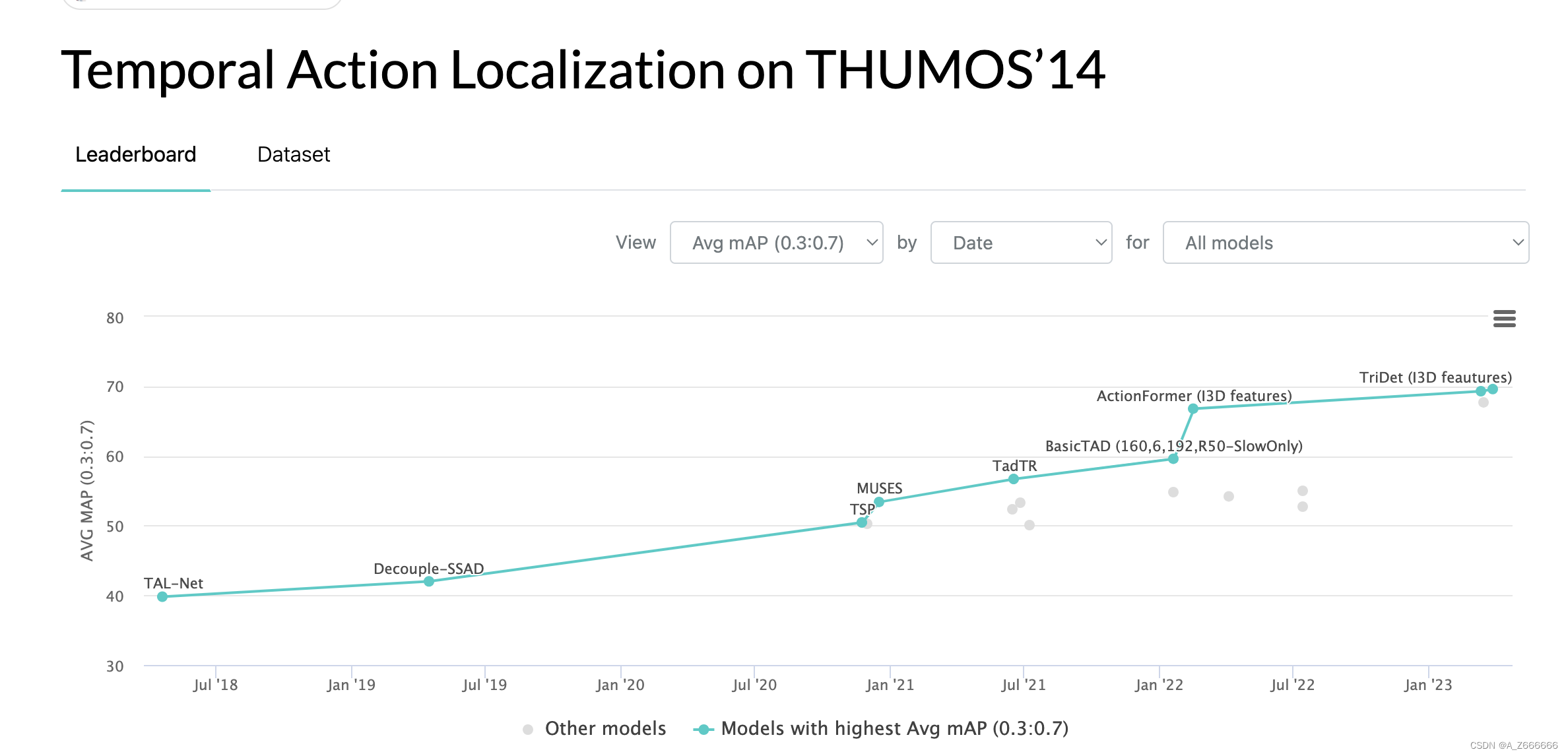
Refs: https://paperswithcode.com/sota/temporal-action-localization-on-thumos14
-
定义:需要输出动作发生的起始和结束时间,以及这个动作的类别。
-
特点:需要处理较长的、未分割的视频,且视频中通常有较多干扰,目标动作一般只占视频的一小部分。类似图像中的Object Detection。
-
相关模型:two-stream、C3D、iDT。
-
难点:
- 时序信息。与行为识别/分类一样,视频理解的通用难点就是时序信息的处理。所以针对这一点目前的主要方法基本上都是使用RNN读入CNN提取的特征,或者直接使用C3D一样的时序卷积。
- 边界不明确。不同于行为识别的是,行为检测要求做精确的动作区间检测,而生活中一个动作的产生往往边界不是十分确定的,所以这也是导致目前行为检测mAP偏低的原因。
- 时间跨度大。在生活中,一个行为动作往往跨度非常大,短的动作几秒左右,比如挥手。长的动作有的持续数十分钟,比如攀岩、骑行等等。这使得我们在提取Proposal的时候变得异常的艰难。
-
数据集:
- 动作检测最大的数据集:HACS.
- 行为检测方向常用的数据集主要是: THUMOS 2014和ActivityNet
- THUMOS 2014来自于THUMOS Challenge 2014,。它的训练集为UCF101数据集,验证集和测试集分别包括1010和1574个未分割的视频片段。在行为检测任务中只有20类动作的未分割视频是有时序行为片段标注的,包括200个验证集(3007个行为片段)和213个测试集视频(包含3358个行为片段)。
- MEXaction2:MEXaction2数据集中包含两类动作:骑马和斗牛。该数据集由三个部分组成:YouTube视频,UCF101中的骑马视频以及INA视频。其中YouTube视频片段和UCF101中的骑马视频是分割好的短视频片段,被用于训练集。而INA视频为多段长的未分割的视频,时长共计77小时,且被分为训练,验证和测试集三部分。训练集中共有1336个行为片段,验证集中有310个行为片段,测试集中有329个行为片断。且MEXaction2数据集的特点是其中的未分割视频长度都非常长,被标注的行为片段仅占视频总长的很低比例。
- ActivityNet: 目前最大的数据库,同样包含分类和检测两个任务。这个数据集仅提供视频的youtube链接,而不能直接下载视频,所以还需要用python中的youtube下载工具来自动下载。该数据集包含200个动作类别,20000(训练+验证+测试集)左右的视频,视频时长共计约700小时。由于这个数据集实在太大了,我的实验条件下很难完成对其的实验,所以我之前主要还是在THUMOS14和MEXaction2上进行实验。
-
技术方案:
19年以前:
1. CDC
2. BMN
-
- 行为分类(Action Recognition)
- 难点:
- 类内和类间差异, 同样一个动作,不同人的表现可能有极大的差异。
- 时间变化, 人在执行动作时的速度变化很大,很难确定动作的起始点,从而在对视频提取特征表示动作时影响最大。
- 缺乏标注良好的大的数据集。
- 以CVPR组织的ACTIVITYNET为例,2017年总共有5个Task被提出。
- Task1:未修剪视频分类(Untrimmed Video Classification)。这个有点类似于图像的分类,未修剪的视频中通常含有多个动作,而且视频很长。有许多动作或许都不是我们所关注的。所以这里提出的Task就是希望通过对输入的长视频进行全局分析,然后软分类到多个类别。
- Task2:修剪视频识别(Trimmed Action Recognition)。这个在计算机视觉领域已经研究多年,给出一段只包含一个动作的修剪视频,要求给视频分类。
- Task3:时序行为提名(Temporal Action Proposal)。这个同样类似于图像目标检测任务中的候选框提取。在一段长视频中通常含有很多动作,这个任务就是从视频中找出可能含有动作的视频段。
- Task4:时序行为定位(Temporal Action Localization)。相比于上面的时序行为提名而言,时序行为定位于我们常说的目标检测一致。要求从视频中找到可能存在行为的视频段,并且给视频段分类。
- Task5:密集行为描述(Dense-Captioning Events)。之所以称为密集行为描述,主要是因为该任务要求在时序行为定位(检测)的基础上进行视频行为描述。也就是说,该任务需要将一段未修剪的视频进行时序行为定位得到许多包含行为的视频段后,对该视频段进行行为描述。比如:man playing a piano
Refs: 姿态估计与行为识别(行为检测、行为分类)的区别
PoseC3D: 基于人体姿态的动作识别新范式
Comments: CVPR 2022 Oral
-
已在[[MMAtion2]]开源。
-
使用3D-CNN, 超越了基于GCN的SOTA.
-
去冗余:
- 对2D姿态先由热图存储为坐标,在行为识别时再由坐标转换为热图。
- 选取每帧的最紧的框以包含图片中的所有人,然后再缩放只特定大小。
- 均匀采样:需要采 N 帧时,我们先将整个视频均分为长度相同的 N 段,并在每段中随机选取一帧。在实验中,我们发现这样的采帧方式对骨骼行为识别尤其适用。
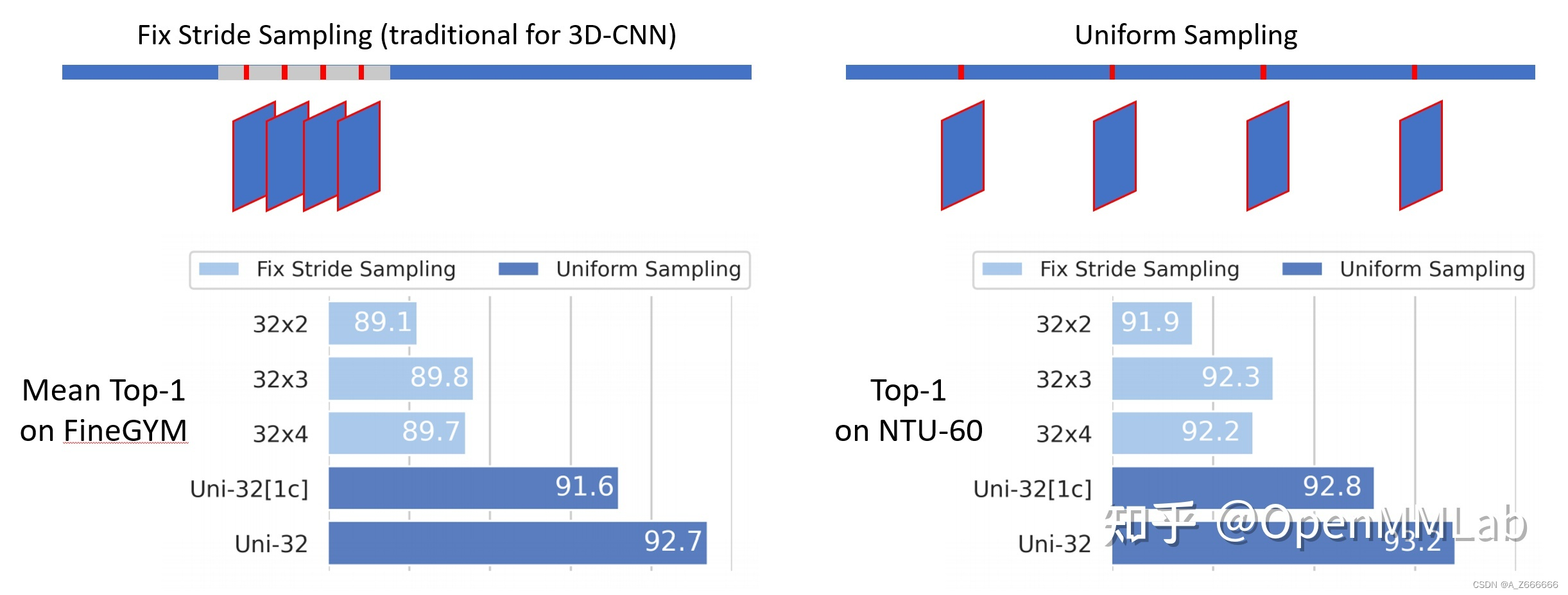
-
使用3D-CNN进行行为识别:
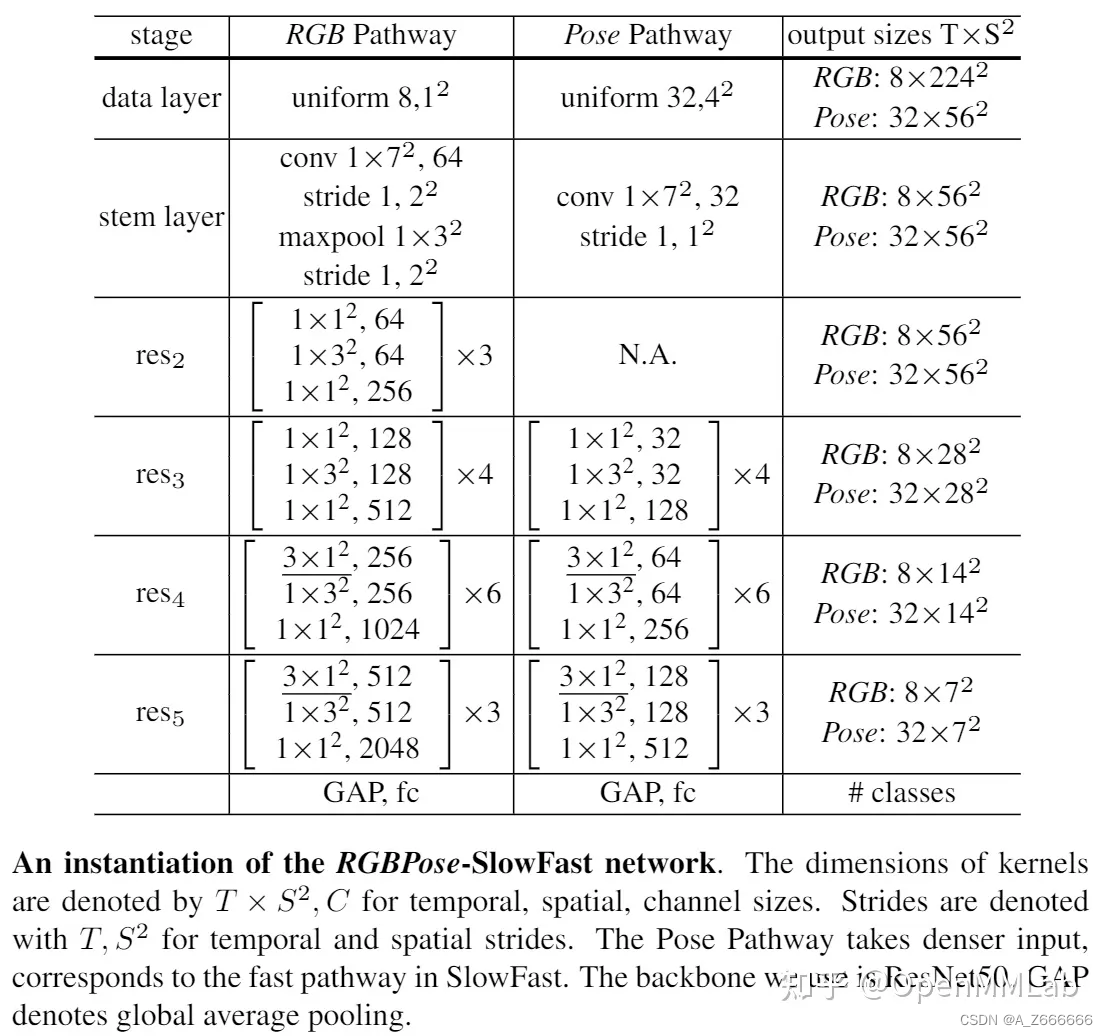
- 骨骼 + RGB 模态:RGBPose-SlowFast。
- 包含两个分支,分别处理 RGB 和骨骼两个模态。
- RGB 分支具有低帧率以及更大的网络宽度,骨骼分支具有高帧率和更小的网络宽度。
- 两分支间存在双向连接,以促进模态间的特征融合。我们将两分支的预测结果融合,作为最终的预测。
- 在训练时,我们用两个单独的损失函数分别训练两个分支,以避免过拟合。
- 网络结构:
-
可扩展性:GCN 所需计算量随人数增加线性增长,在群体识别中并不高效,而3D-CNN不存在这个问题。
Refs: -
知乎: PoseC3D: 基于人体姿态的动作识别新范式
-
Papers: Revisiting Skeleton-based Action Recognition
Refs: https://zhuanlan.zhihu.com/p/34439558
I3D
-
2018年工作。
-
任务:Action Recognition。
-
4种结构:
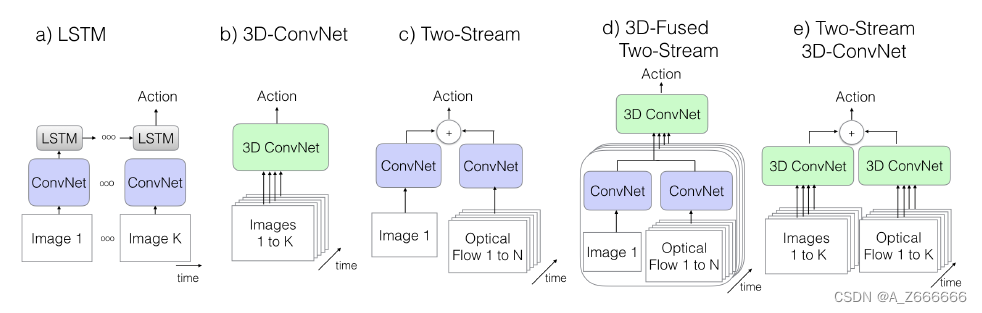
- ConvNet+LSTM:
- 利用最后一帧对视频特征表示。
- 缺点:由于LSTM,所以不能捕捉
low-level motion的特征。
- 3D ConvNets:
- 问题:
- 参数量大,训练困难。
- 无法利用在Imagenet上的预训练模型。
- 问题:
- Two-Stream Networks:
- 用每个clip的预测分数平均的方式获得最终预测(最原始的,或者在最后softmax做融合)。
- 10张
optical flow(其实是5张,x/y两个方向,运动特征) - 论文实现一个类似的two-stream方案,在最后一层用
3d conv将spatial和flow特征进行融合。
- Two-Stream Inflated 3D ConvNets:
- 利用imagenet的预训练模型, 对预训练的
2D conv增加temporal维度,把N×N的filter变为N×N×N。简单的办法就是对N×N的filter重复复制N遍,并归一化,这样多的出发点是短期内时间不变性的假设,姑且把这当成3D filter初始化的一种策略吧。 - 考虑到时间因素,对称感受野不是必须的,这主要还是依赖帧率和图片大小。时间相对于空间变化过快,将合并不同object的边信息,过慢将不能捕捉场景变化。
- 对RGB和光流,分开训练网络。
- 利用imagenet的预训练模型, 对预训练的
- ConvNet+LSTM:
Refs:
- https://zhuanlan.zhihu.com/p/34919655
CDC
- CDC: convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos(2017)
- 主要贡献点:
- 第一次将卷积、反卷积操作应用到行为检测领域,CDC同时在空间下采样,在时间域上上采样。
- 利用CDC网络结构可以做到端到端的学习。
- 通过反卷积操作可以做到帧预测(Per-frame action labeling)。
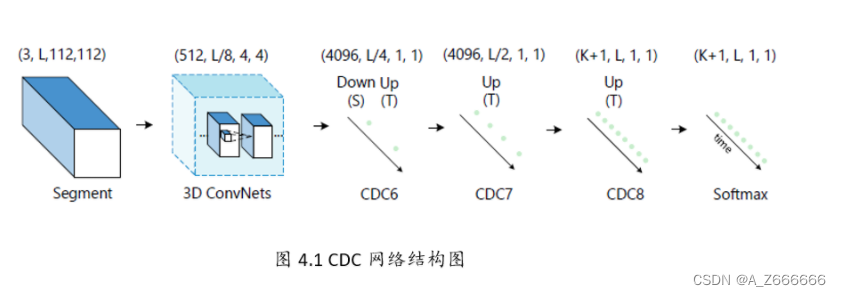
- 网络结构:
-
CDC网络在C3D的基础上用反卷积,将时序升维。做到了帧预测。以下是CDC网络的结构图:
-
网络步骤如下所示:
- 输入的视频段是112x112xL,连续L帧112x112的图像
- 经过C3D网络后,时间域上L下采样到 L/8, 空间上图像的大小由 112x112下采样到了4x4
- CDC6: 时间域上上采样到 L/4, 空间上继续下采样到 1x1
- CDC7: 时间域上上采样到 L/2
- CDC8:时间域上上采样到 L,而且全连接层用的是 4096xK+1, K是类别数
- softmax层
-
CDC FILTER
- 文章的还有一大贡献点是反卷积的设计,因为经过C3D网络输出后,存在时间和空间两个维度,文章中的CDC6完成了时序上采样,空间下采样的同时操作。
- 如下图所示,一般的都是先进行空间的下采样,然后进行时序上采样。但是CDC中设计了两个独立的卷积核(下图中的红色和绿色)。同时作用于4x4xL/8的特征图上。每个卷积核作用都会生成2个1x1的点,如上conv6,那么两个卷积核就生成了4个。相当于在时间域上进行了上采样过程。
-
![![[Pasted image 20230630211843.png]]](https://img-blog.csdnimg.cn/6a0af316ade84e33b63c846c7ecac6b2.png)
Refs: https://zhuanlan.zhihu.com/p/34439558
R-C3D
R-C3D(Region 3-Dimensional Convolution)网络[10]是基于Faster R-CNN和C3D网络思想。对于任意的输入视频L,先进行Proposal,然后用3D-pooling,最后进行分类和回归操作。文章主要贡献点有以下3个:
- 可以针对任意长度视频、任意长度行为进行端到端的检测
- 速度很快(是目前网络的5倍),通过共享Proposal generation 和Classification网络的C3D参数。
- 作者测试了3个不同的数据集,效果都很好,显示了通用性。
Refs: https://zhuanlan.zhihu.com/p/34439558
BMN
- 百度,ActivityNet Challenge 2019 冠军模型。
Refs: https://zhuanlan.zhihu.com/p/337432552