上一篇介绍了PyTorch模型部署流程(Onnx Runtime)的相关部署流程,再来简单的回顾一下~
深度学习模型部署介绍
模型部署指让训练好的深度学习模型在特定环境中运行的过程。模型部署会面临的难题:
- 运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境限制,框架不适合在手机、开发板等生产环境中安装。
- 深度学习模型的结构通常比较庞大,需要大量算力才能满足实时运行的需求。运行效率需要优化。
因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。目前模型部署有一条流行的流水线:
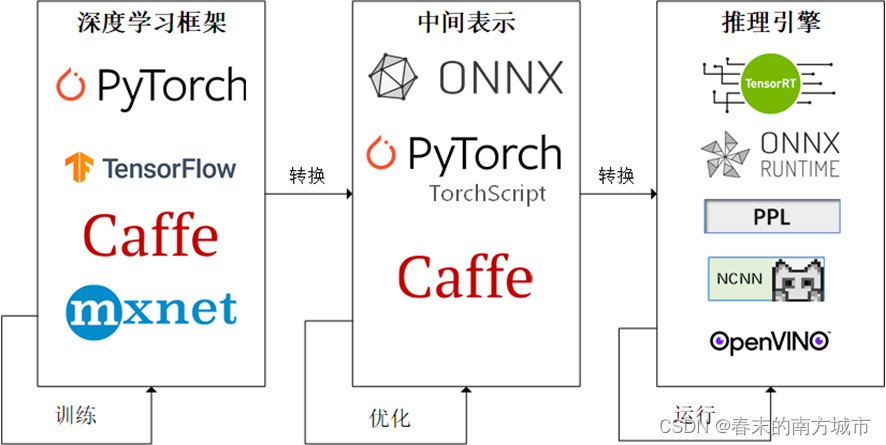
为了让模型最终能够部署到某一环境上,可以使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型。
那么,如果我们想在手机端运行我们的深度学习模型需要怎么做呢?接下来为大家介绍关于端侧深度学习的部署流程,大家了解了基本概念之后可以尝试运行官方demo实例,并根据自己需求进行改进,这样就可以在自己的手机上部署深度学习模型啦~
端侧深度学习模型部署流程
主要技术路线为:训练框架训练模型->模型转化为ONNX格式->ONNX格式转化为其他格式(NCNN,TNN,MNN的模型格式)->在对应的推理框架中部署。
端侧深度学习的应用可以分成如下几个阶段:
- 模型训练阶段,主要解决模型训练,利用标注数据训练出对应的模型文件。面向端侧设计模型时,需要考虑模型大小和计算量;
- 模型压缩阶段,主要优化模型大小,可以通过剪枝、量化等手段降低模型大小,以便在端上使用;
- 模型部署阶段,主要实现模型部署,包括模型管理和部署、运维监控等;
- 端侧推理阶段,主要完成模型推理,即加载模型,完成推理相关的所有计算;
ONNX
ONNX(Open Neural Network Exchange)是 Facebook 和微软在 2017 年共同发布的,用于标准描述计算图的一种格式。目前,在数家机构的共同维护下,ONNX 已经对接了多种深度学习框架和多种推理引擎。因此,ONNX 被当成了深度学习框架到推理引擎的桥梁,就像编译器的中间语言一样。由于各框架兼容性不一,通常只用 ONNX 表示更容易部署的静态图。
其中torch.onnx.export 是 PyTorch 自带的把模型转换成 ONNX 格式的函数。前三个参数分别是要转换的模型、模型的任意一组输入、导出的 ONNX 文件的文件名。
从 PyTorch 的模型到 ONNX 的模型,PyTorch提供了一种叫做追踪(trace)的模型转换方法:给定一组输入,再实际执行一遍模型,即把这组输入对应的计算图记录下来,保存为 ONNX 格式。export 函数用的就是追踪导出方法,需要给任意一组输入,让模型跑起来。测试图片是三通道256x256 大小的,这里也构造一个同样形状的随机张量。
opset_version 表示 ONNX 算子集的版本。input_names, output_names 是输入、输出 tensor 的名称。代码运行成功,目录下会新增一个 srcnn.onnx 的 ONNX 模型文件
NCNN
ncnn是一个为手机端极致优化的高性能神经网络前向计算框架。ncnn从设计之初深刻考虑手机端的部署和使用。 无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。 基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行, 开发出人工智能 APP,将 AI 带到你的指尖。 ncnn目前已在腾讯多款应用中使用,如:QQ,Qzone,微信,天天P图等。
部署实践
a.模型文件转为ONNX文件
Pytorch保存模型有两种方法: 第一种方法只保存模型参数。第二种方法保存完整模型。
只保存模型参数:
| print(model.state_dict().keys()) # 输出模型参数名称 |
直接保存完整模型:
| torch.save(model, './data/model.pkl') # 保存整个模型 |
目前大多数应用都会仅仅保存模型参数,用的时候创建模型结构,然后加载模型。一般我们下载的预训练模型都是只保存模型参数的文件,这种模型文件不能直接拿来推理,需要重新创建并加载模型结构,然后进行保存和转换。以下为模型转换为ONNX的代码:需要先创建模型结构并加载模型然后才能进行保存。
模型以静态输入保存和转换:
| # onnx模型导入 |
模型以动态输入保存和转换:
| # onnx模型导入 |
验证模型转换是否成功:
| # 验证onnx模型 |
b.ONNX格式模型->端侧推理框架模型(NCNN格式)
(1)直接用模型转换工具,输入ONNX文件,生成NCNN文件(.param & .bin)
https://convertmodel.com/#input=onnx&output=onnx
(2)使用代码进行转化
将onnx转换为ncnn模型前,需要简化onnx模型,以免出现不可编译的情况。
首先安装onnx-smiplifier
| pip install onnx-simplifier |
然后简化onnx模型
| python3 -m onnxsim my_mobileface.onnx my_mobileface-sim.onnx |
onnx转换为ncnn,需要使用在ncnn/build/tools/onnx2ncnn,需要在Ubuntu中先安装ncnn,Ubuntu中安装ncnn方法,可以按这个链接安装,我已验证过。如果之前安装过opencv,就直接装ncnn就行。装好之后,找到onnx2ncnn文件的路径,输入下面命令。
| ./onnx2ncnn my_mobileface-sim.onnx my_mobileface.param my_mobileface.bin |
生成的.bin与.param文件就是在Android上需要使用的NCNN模型文件。
c.在Android studio项目中使用模型文件
强烈建议可以先跑通ncnn官方给的几个在Android端部署的例子,然后可以根据自己的需求进行改进,下面是ncnn使用样例:
• https://github.com/nihui/ncnn-android-squeezenet
• https://github.com/nihui/ncnn-android-styletransfer
• https://github.com/nihui/ncnn-android-mobilenetssd
• https://github.com/moli232777144/mtcnn_ncnn
• https://github.com/nihui/ncnn-android-yolov5
• https://github.com/xiang-wuu/ncnn-android-yolov7
• https://github.com/shaoshengsong/qt_android_ncnn_lib_encrypt_example
搭建ncnn环境
从 https://github.com/Tencent/ncnn/releases 下载NCNN压缩包,然后提取压缩包内容到app/src/main/jni, 然后修改app/src/main/jni/CMakeLists.txt中的ncnn_DIR路径。
我的CMakeLists.txt配置如下:
| project(styletransferncnn) |
配置好 ncnn 后,就可以在安卓端运行和推理深度学习模型文件,比如配置好上述要求后就可以运行ncnn官方给出的样例。下图为在安卓端运行图像分类的示例:

下图为我自己根据官方样例改进部署图像超分的示例:
|
|
|


左图为超分前的图像,右图为超分后的图像。