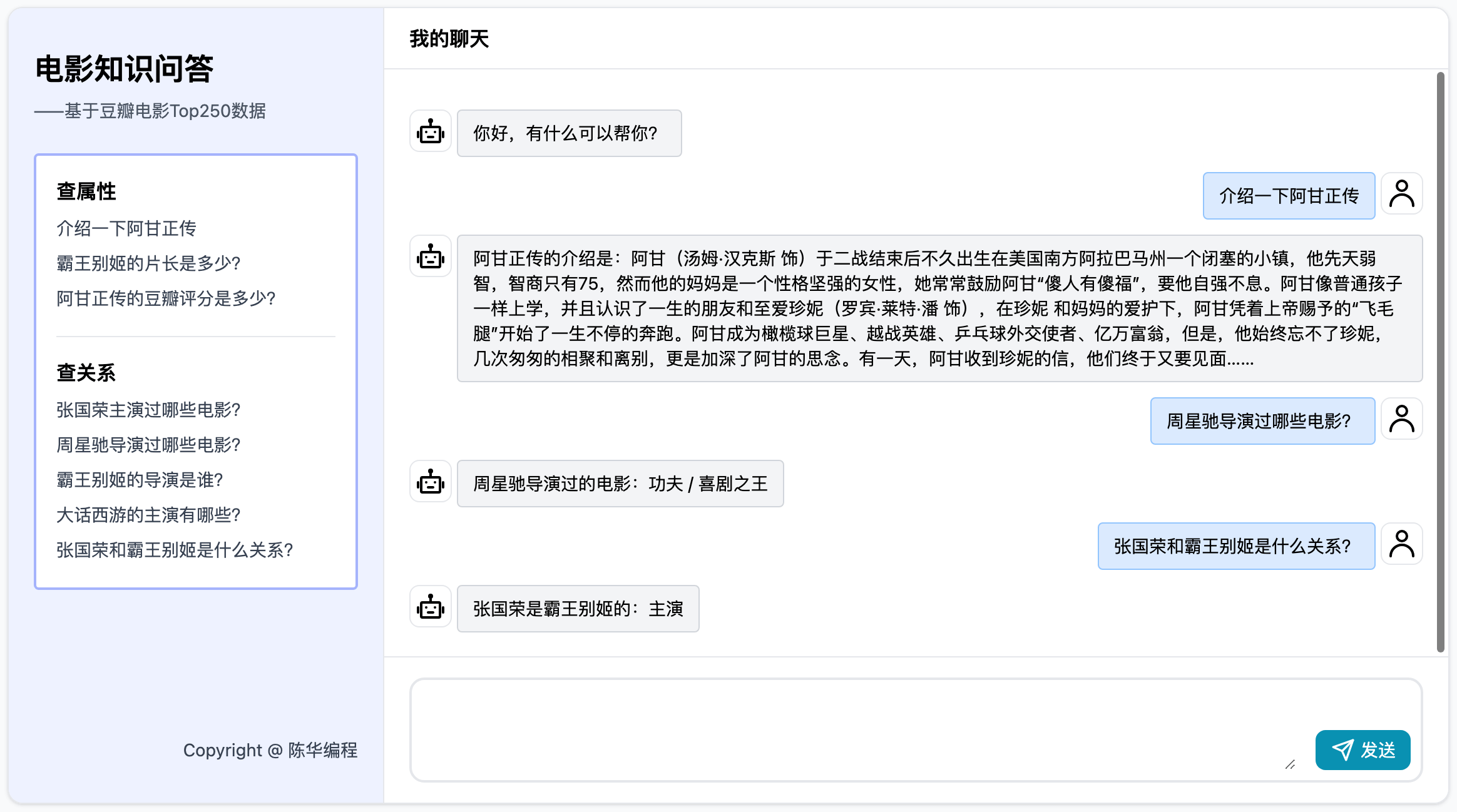
从今天开始,我们要一起来学习一个新的课程,叫做《基于豆瓣电影TOP250数据的知识图谱对话机器人》,同时,这个课程也是「知识图谱」系列的第一个项目。
项目演示
课程内容
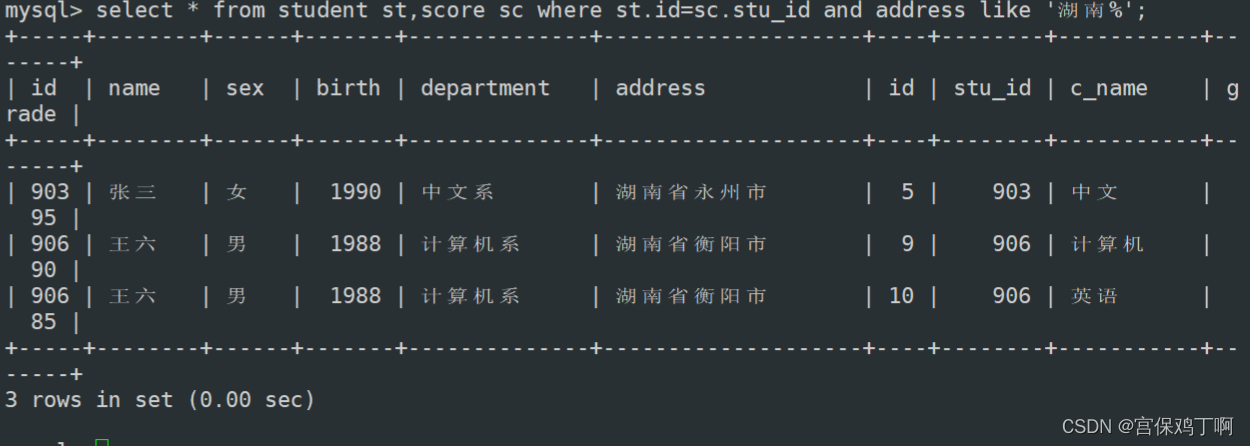
1、爬取数据:使用reqests库,结合bs4和正则表达式,爬取并解析豆瓣电影TOP250的数据。
2、Neo4j图数据库:在Neo4j官方提供的云服务上,学习Neo4j增删改查的Cpyher语法。
3、模板解析:通过正则匹配的方式,提取用户问题中的关键信息,并通过答案模板,查询Neo4j得出查询结果。
4、前端交互:使用TailwindCSS和AlpineJS搭建对话窗口,并使用Flask封装后端服务,完成整体的前后端功能。
补充说明
1、这个课程的目标,是完全从零开始,去搭建一个完整的对话机器人的项目。这个课程是目前市面上,唯一一套从爬虫开始,一直讲到前端显示全流程的知识图谱项目课程,相当于四个课程的合集。
2、在复杂的对话项目中,问题的意图识别和实体抽取,一般是搭建深度学习的模型实现的。但作为第一个知识图谱项目,这个课程重点,是想让大家掌握知识图谱的构建和使用方法。所以,在这个项目中,使用的是一种更好理解的模板匹配的方案,来实现这部分的功能。跟深度学习结合的方法,会在下一个项目中讲到。
适用人群
1、有一定的Python基础即可,暂时不需要深度学习基础,有前后端基础更佳。
2、特别适合要做完整知识图谱项目的同学,比如做毕业设计、全栈工程师之类,一己之力能把带前端效果的完整项目做出来,一定会惊艳所有人。
其他说明
1、这个课程是有一定难度的,碰到复杂逻辑的场景,我会先拆解成小功能,尽量的用简单例子讲解,再嵌入到项目中,方便大家去理解。当然,即便这样讲,学习难度依然不小,大家可以先试看几节,严重卡壳的话,可以先去看看我前面讲过的小项目练练手。
2、这个课程的授课方式,依然是沿用分段复制(不逐字手敲)、逐行解释的方案,以达到在节约时间的同时,也让大家能跟着课程动手实践的目的。
3、这个课程是一个收费课程,可以通过搜索引擎,搜索「陈华编程」官网,或者是点视频下方描述里面的链接,联系客服购买,课程源码和素材,都会邮件发送给大家。
这个课程的细节比较多,录制周期也比较长,前后花了整整一个月时间,才全部制作完成,希望大家多多点赞、关注、三连支持。