什么是分布式锁
分布式锁是一种在分布式系统中用于协调多个节点访问共享资源的机制。在分布式系统中,由于存在多个节点并行执行任务,可能会出现竞争条件和数据不一致的问题。分布式锁通过约束同一时刻只有一个节点能够获得锁的方式,确保了对共享资源的独占访问,从而解决了这些问题。
分布式锁的实现通常需要满足以下特性:
-
互斥性:同一时刻只有一个节点能够持有锁,并且其他节点无法获取该锁。
-
可重入性:允许同一节点多次获取同一个锁,而不会发生死锁。
-
容错性:在锁持有者节点故障或网络异常情况下,能够及时释放锁。
-
超时处理:支持设置获取锁的最大等待时间,避免由于死锁或长时间阻塞导致系统性能下降。
-
高可用性:具备高可用性能,即使部分节点故障也能正常提供服务。
实现分布式锁的方法有多种,常见的包括:
-
基于数据库的分布式锁:利用数据库的事务和唯一索引等特性,使用数据库表记录锁的状态。通过获取和释放特定的行锁来实现互斥访问。
-
基于缓存的分布式锁:利用分布式缓存(如Redis)的原子性操作和过期时间等特点,通过设置一个全局唯一的键值对表示锁的状态。只有成功获取到锁的节点才能在缓存中设置这个键值对,其他节点则无法设置并获取到锁。
什么是分布式锁
同步锁是一种并发控制机制,用于在多线程环境下保护共享资源的访问。它可以防止多个线程同时访问临界区代码,从而避免并发访问导致的数据不一致或冲突。
同步锁的原理是通过获取锁来获得对临界区代码的独占访问权。在Java中,常用的同步锁机制包括内置锁(也称为监视器锁)和显式锁。
- 内置锁(Intrinsic Lock):也称为对象监视器锁或synchronized锁。当一个方法或代码块被
synchronized修饰时,该对象上就存在一个内置锁。只有获得了该锁的线程才能执行被修饰的方法或代码块,其他线程必须等待锁的释放。
示例代码:
public class Example {
private Object lock = new Object();
public void synchronizedMethod() {
synchronized (lock) {
// 临界区代码
}
}
}
- 显式锁(Explicit Lock):使用
java.util.concurrent.locks包中的Lock接口及其实现类,如ReentrantLock。相比内置锁,显式锁提供了更灵活的锁定机制,如可重入性、公平性和条件变量等特性,使得多线程代码的控制更加精确。
示例代码:
public class Example {
private Lock lock = new ReentrantLock();
public void lockedMethod() {
lock.lock();
try {
// 临界区代码
} finally {
lock.unlock();
}
}
}
同步锁的使用可以有效避免多个线程对共享资源的不安全访问,保证数据一致性和并发执行的正确性。但过度使用同步锁可能导致线程竞争和性能下降,因此在设计多线程应用程序时需要合理地使用同步锁机制。
两种锁的使用场景
分布式锁和同步锁是在不同环境下用于实现并发控制的两种机制。
- 分布式锁的使用场景:
分布式锁通常用于分布式系统中,用于协调多个节点对共享资源的访问。一个常见的场景是在分布式环境下实现对某个唯一资源的排他性访问,例如分布式任务调度、分布式缓存更新等。
示例代码(基于Redis实现分布式锁):
import redis.clients.jedis.Jedis;
public class DistributedLock {
private Jedis jedis;
private String lockKey;
public boolean acquireLock() {
long result = jedis.setnx(lockKey, "locked");
return result == 1;
}
public void releaseLock() {
jedis.del(lockKey);
}
}
在上述代码中,通过调用 setnx() 方法尝试获取锁,如果返回值为1,则表示成功获取到分布式锁。释放锁的操作则是调用 del() 方法删除锁的键。
- 同步锁的使用场景:
同步锁主要用于多线程编程中,控制多个线程对共享资源的并发访问。一个经典的场景是在多线程环境下保护对某个临界区代码的独占访问,避免数据竞争和冲突。
示例代码(基于Java内置锁实现同步锁):
public class SynchronizedCounter {
private int count;
public synchronized void increment() {
count++;
}
public synchronized void decrement() {
count--;
}
}
在上述代码中,通过 synchronized 关键字修饰方法,使得多线程在执行这些方法时会自动获取对象的内置锁。这样可以确保同一时间只能有一个线程执行 increment() 或 decrement() 方法,避免并发访问
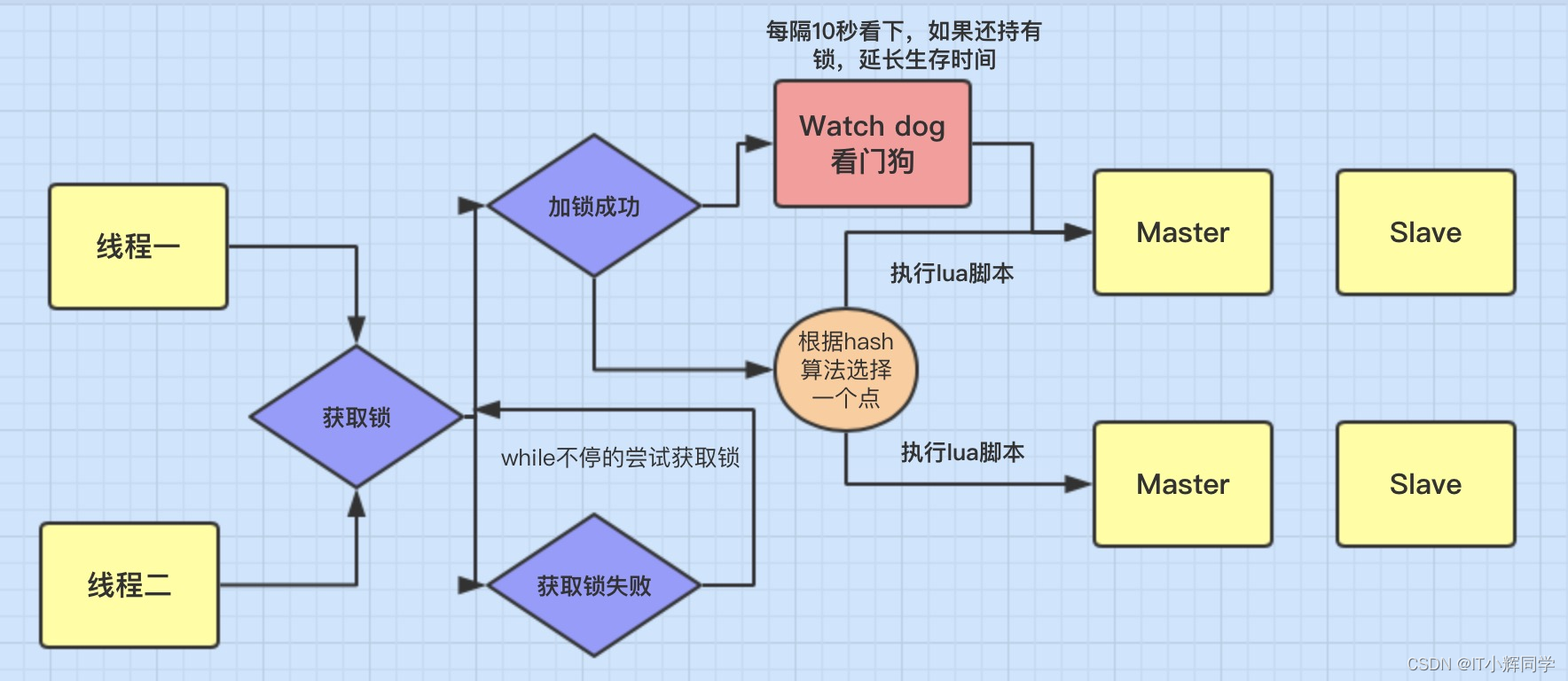
分布式锁实现
分布式锁是在分布式系统中用于实现资源的互斥访问的一种机制。下面介绍两种常见的分布式锁实现方法:
-
基于数据库的分布式锁:
使用数据库作为分布式锁的持久化存储,通过在表中创建唯一索引或使用悲观锁来确保只有一个节点能够成功获取锁。// 获取分布式锁 public boolean acquireLock(String lockName) { try (Connection connection = dataSource.getConnection()) { String sql = "INSERT INTO distributed_lock (lock_name) VALUES (?)"; PreparedStatement statement = connection.prepareStatement(sql); statement.setString(1, lockName); int affectedRows = statement.executeUpdate(); return affectedRows > 0; } catch (SQLException e) { // 处理异常 } return false; } // 释放分布式锁 public void releaseLock(String lockName) { try (Connection connection = dataSource.getConnection()) { String sql = "DELETE FROM distributed_lock WHERE lock_name = ?"; PreparedStatement statement = connection.prepareStatement(sql); statement.setString(1, lockName); statement.executeUpdate(); } catch (SQLException e) { // 处理异常 } }在上述示例中,使用数据库表
distributed_lock存储分布式锁的状态。通过执行相应的SQL语句来获取锁和释放锁,确保只有一个节点能够插入对应的锁名称到表中。其他节点尝试插入同样的锁名称会因为唯一索引或悲观锁失败,从而实现了互斥访问。 -
基于Redis的分布式锁:
使用Redis作为分布式锁的存储中心,利用Redis的原子操作特性和过期时间来实现分布式锁的获取和释放。public boolean acquireLock(String lockKey, String requestId, int expireTime) { try (Jedis jedis = jedisPool.getResource()) { String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime); return "OK".equalsIgnoreCase(result); } catch (Exception e) { // 处理异常 } return false; } public void releaseLock(String lockKey, String requestId) { try (Jedis jedis = jedisPool.getResource()) { String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end"; jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId)); } catch (Exception e) { // 处理异常 } }在上述示例中,使用Redis的
set命令以原子方式将锁信息存储到Redis中,并设置过期时间。通过获取锁时传递一个唯一的请求标识符requestId,并在释放锁时校验该标识符,确保只有持有锁的节点能够释放它。
这两种分布式锁的实现方法各有优劣,选择合适的方式取决于具体业务场景和系统需求。分布式锁的设计和实现需要考虑到分布式环境下的并发性、可靠性和性能等方面的问题,确保在多个节点之间实现正确的资源互斥访问。

![[JAVA]程序逻辑控制,输入输出](https://img-blog.csdnimg.cn/b0cde9c7df4c4abea80f842e2539fa0f.png)