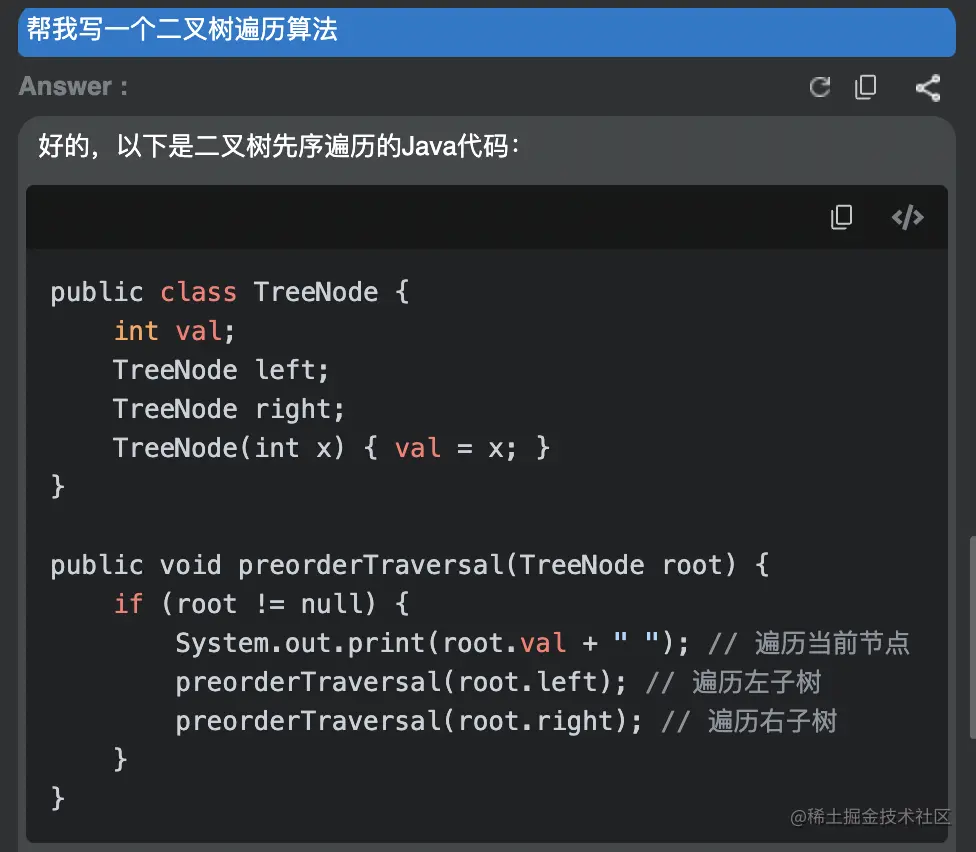
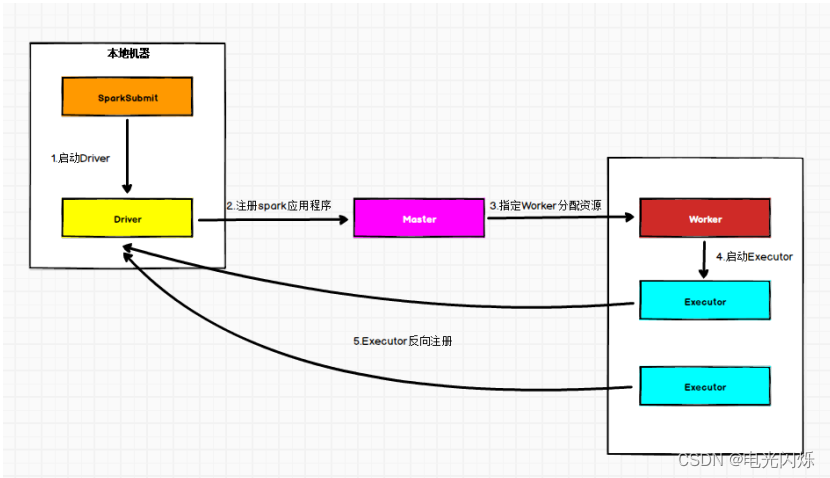
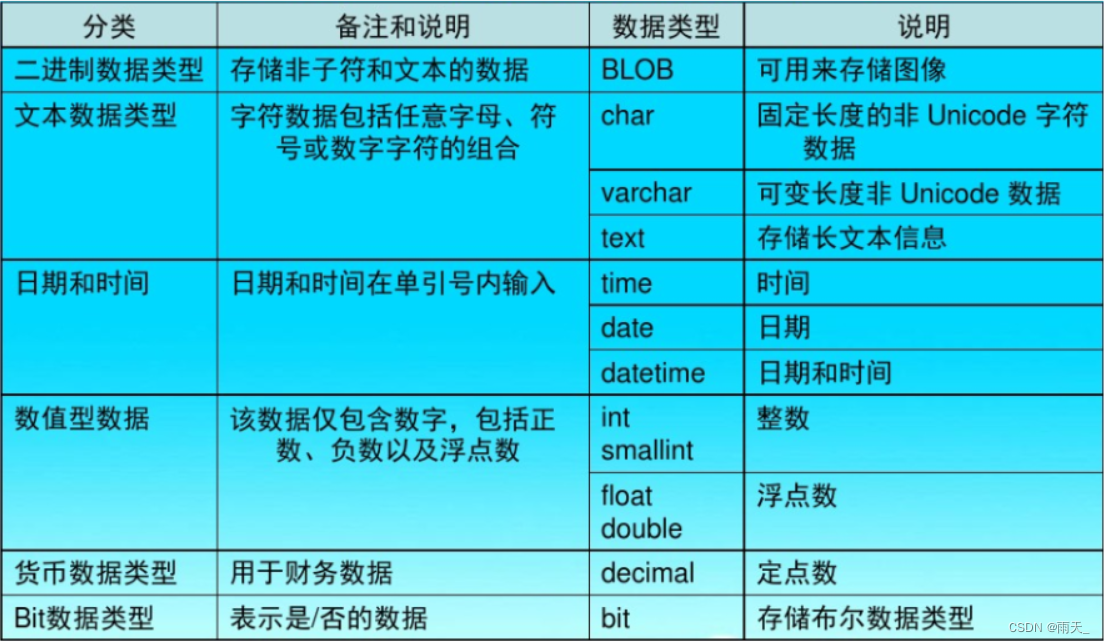
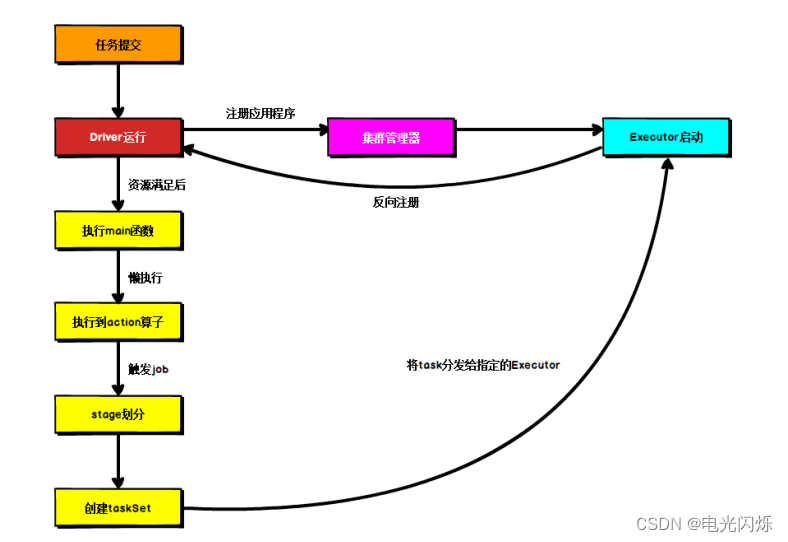
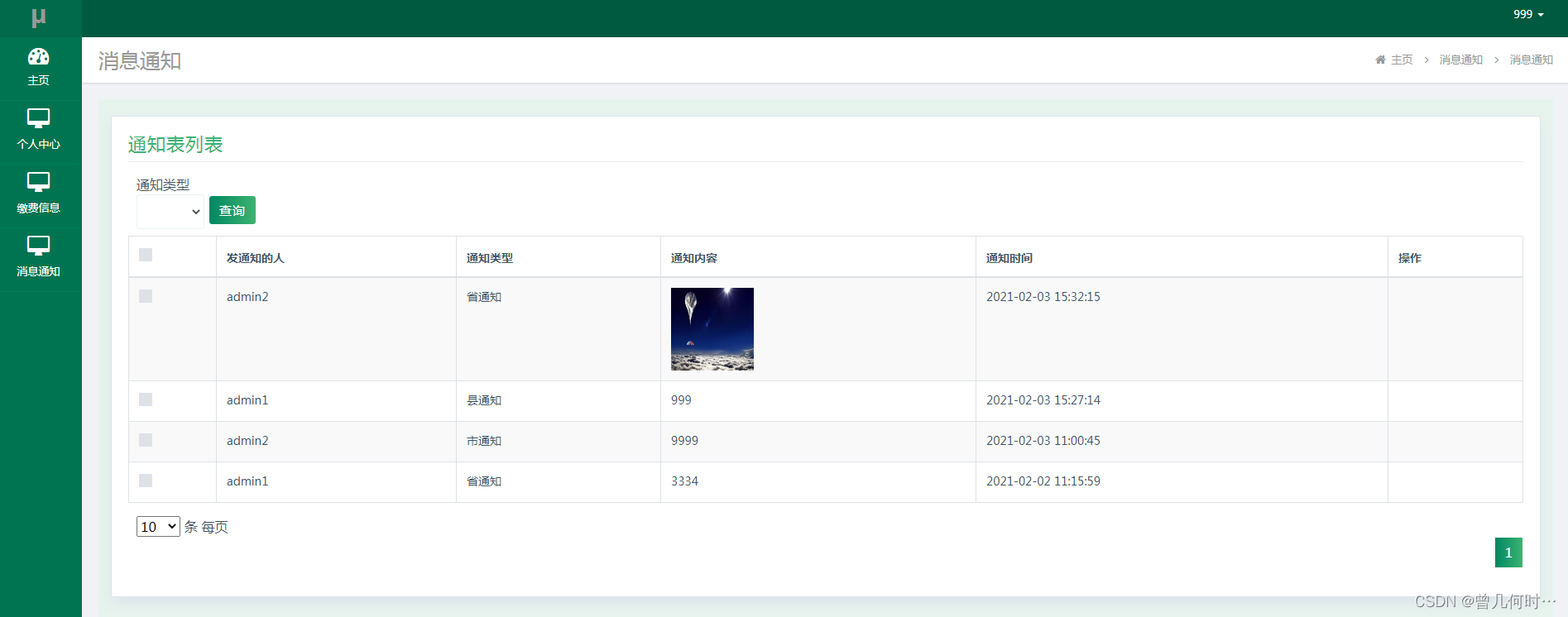
数据管理是收集、收集原始数据并将其转换为另一种格式的过程,以便在更短的时间内更好地理解、决策、访问和分析。

数据管理的重要性
数据管理是数据科学项目中非常重要的一步。下面的例子将解释它的重要性:
图书销售网站希望显示不同领域的畅销书,根据用户的喜好。例如,如果新用户搜索励志书籍,则他们想要示出销售最多或具有高评级的那些励志书籍等。
但在他们的网站上,有大量来自不同用户的原始数据。这里使用数据混合或数据管理的概念。正如我们所知,数据争吵不是由系统本身引起的。这个过程由数据科学家完成。因此,数据科学家将以这样一种方式对数据进行争论,即他们将对销售更多或具有高评级的励志书籍进行排序,或者用户购买这本书与这些书籍包等。在此基础上,新用户将做出选择。这将解释数据管理的重要性。
Python中的数据管理
数据管理是数据科学和数据分析的一个重要课题。Python的Pandas框架用于数据管理。Pandas是一个专门为数据分析和数据科学开发的Python开源库。它用于数据排序或过滤、数据分组等过程。
Python中的数据管理处理以下功能:
- 数据探索:在此过程中,通过可视化数据表示来研究、分析和理解数据。
- 处理缺失值:大多数具有大量数据的数据集包含NaN的缺失值,需要通过用列的平均值、众数、最频繁值替换它们,或者简单地通过删除具有NaN值的行来处理它们。
- 重塑数据:在此过程中,根据需求操作数据,其中可以添加新数据或修改预先存在的数据。
- 过滤数据:有时数据集包含需要删除或过滤的不需要的行或列
- 其他:在使用上述功能处理原始数据集后,我们可以根据我们的要求获得有效的数据集,然后可以将其用于所需的目的,如数据分析,机器学习,数据可视化,模型训练等。
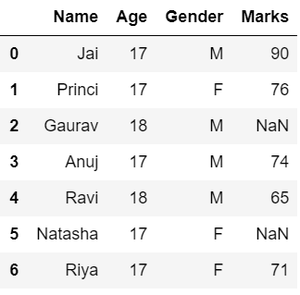
以下是在原始数据集上实现上述功能的数据整理的示例:
Python中的数据探索
# Import pandas package
import pandas as pd
# Assign data
data = {'Name': ['Jai', 'Princi', 'Gaurav',
'Anuj', 'Ravi', 'Natasha', 'Riya'],
'Age': [17, 17, 18, 17, 18, 17, 17],
'Gender': ['M', 'F', 'M', 'M', 'M', 'F', 'F'],
'Marks': [90, 76, 'NaN', 74, 65, 'NaN', 71]}
# Convert into DataFrame
df = pd.DataFrame(data)
# Display data
df
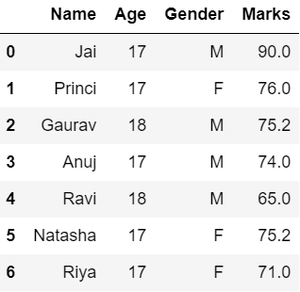
处理Python中的缺失值
正如我们从前面的输出中看到的,MARKS列中存在NaN值,这是数据帧中的缺失值,将在数据处理中通过将它们替换为列均值来处理。
# Compute average
c = avg = 0
for ele in df['Marks']:
if str(ele).isnumeric():
c += 1
avg += ele
avg /= c
# Replace missing values
df = df.replace(to_replace="NaN",
value=avg)
# Display data
df
数据管理中的数据替换
在“Gender”列中,我们可以通过将它们分类为不同的数字来替换“Gender”列数据。
# Categorize gender
df['Gender'] = df['Gender'].map({'M': 0,
'F': 1, }).astype(float)
# Display data
df

在数据管理中过滤数据
假设需要关于得分最高的学生的姓名、性别和分数的细节。这里我们需要使用pandas切片方法从不需要的数据中删除一些数据。
# Filter top scoring students
df = df[df['Marks'] >= 75].copy()
# Remove age column from filtered DataFrame
df.drop('Age', axis=1, inplace=True)
# Display data
df

因此,我们最终获得了一个有效的数据集,可以进一步用于各种目的。
现在我们已经了解了使用Python和pandas进行数据处理的基础知识。下面我们将讨论各种操作,我们可以使用这些操作来执行数据整理:
使用合并操作的数据整理
合并操作用于将两个原始数据合并为所需的格式。
语法: pd.merge( data_frame1,data_frame2, on=”field “)
这里的字段是两个数据框中相似的列的名称。
例如:假设教师有两种类型的数据,第一种类型的数据由学生的详细信息组成,第二种类型的数据由来自会计办公室的待付费用状态组成。因此,教师将在这里使用合并操作,以便合并数据并提供其含义。这样教师就可以很容易地分析它,也减少了教师手工合并的时间和精力。
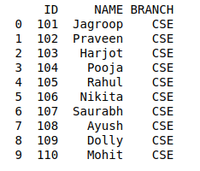
创建第一个数据框架以使用数据管理执行合并操作:
# import module
import pandas as pd
# creating DataFrame for Student Details
details = pd.DataFrame({
'ID': [101, 102, 103, 104, 105, 106,
107, 108, 109, 110],
'NAME': ['Jagroop', 'Praveen', 'Harjot',
'Pooja', 'Rahul', 'Nikita',
'Saurabh', 'Ayush', 'Dolly', "Mohit"],
'BRANCH': ['CSE', 'CSE', 'CSE', 'CSE', 'CSE',
'CSE', 'CSE', 'CSE', 'CSE', 'CSE']})
# printing details
print(details)
创建第二个数据框架以使用数据管理执行合并操作:
# Import module
import pandas as pd
# Creating Dataframe for Fees_Status
fees_status = pd.DataFrame(
{'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'PENDING': ['5000', '250', 'NIL',
'9000', '15000', 'NIL',
'4500', '1800', '250', 'NIL']})
# Printing fees_status
print(fees_status)

使用合并操作的数据整理:
# Import module
import pandas as pd
# Creating Dataframe
details = pd.DataFrame({
'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'NAME': ['Jagroop', 'Praveen', 'Harjot',
'Pooja', 'Rahul', 'Nikita',
'Saurabh', 'Ayush', 'Dolly', "Mohit"],
'BRANCH': ['CSE', 'CSE', 'CSE', 'CSE', 'CSE',
'CSE', 'CSE', 'CSE', 'CSE', 'CSE']})
# Creating Dataframe
fees_status = pd.DataFrame(
{'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'PENDING': ['5000', '250', 'NIL',
'9000', '15000', 'NIL',
'4500', '1800', '250', 'NIL']})
# Merging Dataframe
print(pd.merge(details, fees_status, on='ID'))
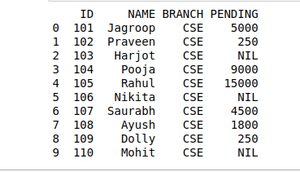
基于分组方法的数据整理
数据整理中的分组方法用于根据从大数据中取出的各种组提供结果。pandas的这种方法用于从大型数据集中对数据的开始进行分组。
例如:有一家汽车销售公司,这家公司拥有不同品牌的汽车制造公司,如Maruti,Toyota,Mahindra,福特等,并有不同年份不同汽车的销售数据。因此,该公司只想争论2010年汽车销售的数据。对于这个问题,我们使用另一种数据管理技术,即pandas groupby()方法。
创建数据框以使用分组方法[汽车销售数据集]:
# Import module
import pandas as pd
# Creating Data
car_selling_data = {'Brand': ['Maruti', 'Maruti', 'Maruti',
'Maruti', 'Hyundai', 'Hyundai',
'Toyota', 'Mahindra', 'Mahindra',
'Ford', 'Toyota', 'Ford'],
'Year': [2010, 2011, 2009, 2013,
2010, 2011, 2011, 2010,
2013, 2010, 2010, 2011],
'Sold': [6, 7, 9, 8, 3, 5,
2, 8, 7, 2, 4, 2]}
# Creating Dataframe of car_selling_data
df = pd.DataFrame(car_selling_data)
# printing Dataframe
print(df)
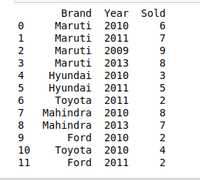
创建数据框架以使用分组方法[2010年数据]:
# Import module
import pandas as pd
# Creating Data
car_selling_data = {'Brand': ['Maruti', 'Maruti', 'Maruti',
'Maruti', 'Hyundai', 'Hyundai',
'Toyota', 'Mahindra', 'Mahindra',
'Ford', 'Toyota', 'Ford'],
'Year': [2010, 2011, 2009, 2013,
2010, 2011, 2011, 2010,
2013, 2010, 2010, 2011],
'Sold': [6, 7, 9, 8, 3, 5,
2, 8, 7, 2, 4, 2]}
# Creating Dataframe for Provided Data
df = pd.DataFrame(car_selling_data)
# Group the data when year = 2010
grouped = df.groupby('Year')
print(grouped.get_group(2010))
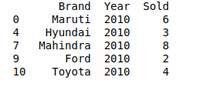
清除重复的数据整理
Pandas duplicates()方法帮助我们从大数据中删除重复的值。数据整理的一个重要部分是从大型数据集中删除重复值。
Syntax: DataFrame.duplicated(subset=None, keep=’first’)
这里的subset是我们要删除Duplicate值的列值。
在保持,我们有3个选项:
- 如果keep =‘first’,则第一个值被标记为原始值,如果发生,则所有值的其余部分将被删除,因为它被认为是重复的。
- 如果keep=‘last’,则最后一个值被标记为原始剩余值,上述相同的值将被删除,因为它被认为是重复值。
- 如果keep =‘false’,所有出现一次以上的值都将被删除,因为所有值都被认为是重复值。
例如,A大学将组织该活动。为了参加学生必须填写他们的详细信息在网上的形式,以便他们将与他们联系。学生可能会多次填写表格。如果一个学生填写多个条目,可能会给活动组织者带来困难。组织者将获得的数据可以通过删除重复值轻松管理。
创建想要参与活动的学生数据集:
import pandas as pd
# Initializing Data
student_data = {'Name': ['Amit', 'Praveen', 'Jagroop',
'Rahul', 'Vishal', 'Suraj',
'Rishab', 'Satyapal', 'Amit',
'Rahul', 'Praveen', 'Amit'],
'Roll_no': [23, 54, 29, 36, 59, 38,
12, 45, 34, 36, 54, 23],
'Email': ['xxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxx@gmail.com', 'xx@gmail.com',
'xxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxxxxxx@gmail.com', 'xxxxxxxxxx@gmail.com']}
# Creating Dataframe of Data
df = pd.DataFrame(student_data)
# Printing Dataframe
print(df)
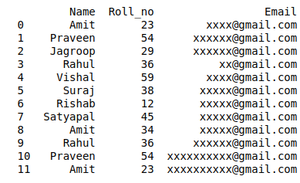
从数据集中删除重复数据:
# import module
import pandas as pd
# initializing Data
student_data = {'Name': ['Amit', 'Praveen', 'Jagroop',
'Rahul', 'Vishal', 'Suraj',
'Rishab', 'Satyapal', 'Amit',
'Rahul', 'Praveen', 'Amit'],
'Roll_no': [23, 54, 29, 36, 59, 38,
12, 45, 34, 36, 54, 23],
'Email': ['xxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxx@gmail.com', 'xx@gmail.com',
'xxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxxxxxx@gmail.com', 'xxxxxxxxxx@gmail.com']}
# creating dataframe
df = pd.DataFrame(student_data)
# Here df.duplicated() list duplicate Entries in ROllno.
# So that ~(NOT) is placed in order to get non duplicate values.
non_duplicate = df[~df.duplicated('Roll_no')]
# printing non-duplicate values
print(non_duplicate)

在数据整理中使用两个数据集的连接创建新数据集。
我们可以通过几种方式连接两个数据帧。对于我们在ConcanatingTwo数据集中的示例,我们使用pd.concat()函数。
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data1 = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd'],
'Mobile No': [97, 91, 58, 76]}
# Define a dictionary containing employee data
data2 = {'Name':['Gaurav', 'Anuj', 'Dhiraj', 'Hitesh'],
'Age':[22, 32, 12, 52],
'Address':['Allahabad', 'Kannuaj', 'Allahabad', 'Kannuaj'],
'Qualification':['MCA', 'Phd', 'Bcom', 'B.hons'],
'Salary':[1000, 2000, 3000, 4000]}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data1,index=[0, 1, 2, 3])
# Convert the dictionary into DataFrame
df1 = pd.DataFrame(data2, index=[2, 3, 6, 7])
我们将沿着轴0连接这两个数据帧。
res = pd.concat([df, df1])

注意:我们可以看到data 1没有salary列,所以所有四行新的dataframe res都是Nan值。