摘要:本文整理自中南电力设计院工程师、注册测绘师姚远,在 Flink Forward Asia 2022 行业案例专场的分享。本篇内容主要分为四个部分:
1. 建设背景
2. 技术架构
3. 应用落地
4. 后续及其他
Tips:点击「阅读原文」免费领取 5000CU*小时 Flink 云资源
01
建设背景
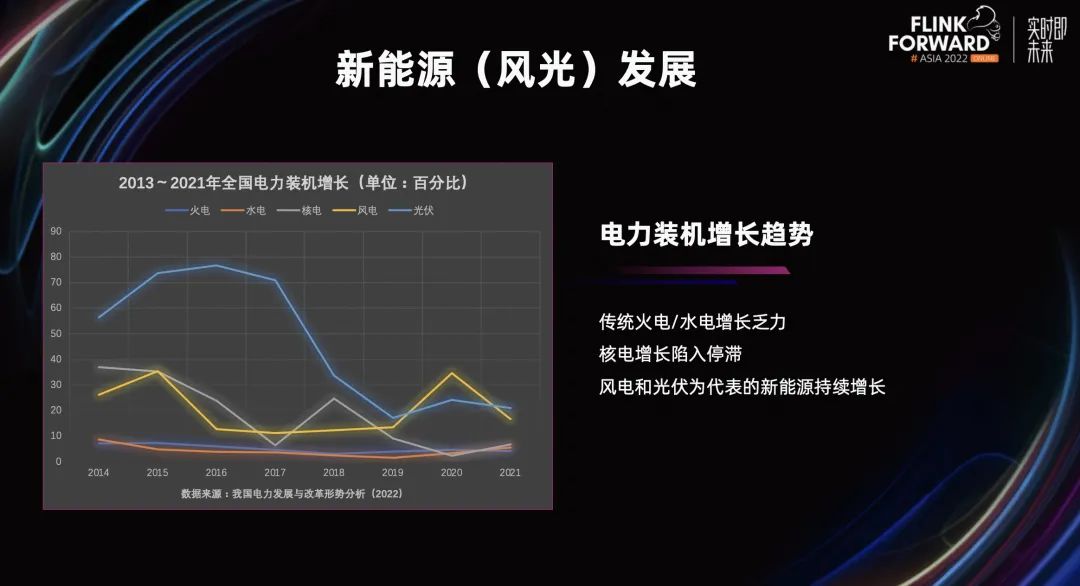
建设背景主要分为宏观背景和场站侧的需求。
上图引用的是 2022 年我国电力发展和改革形势分析报告的统计数据,展示了 2013-2021 年,九年间装机容量的增长百分比。可以看出传统火电和水电的增长已经乏力;核电由于基数较少基本处于平稳发展;而新能源电站,特别是风电站和光伏电站经过多年的建设,在维持较高增长率的同时,很多电站已经进入存量运维的阶段。随着时间推移,设备老化等运维问题逐渐增加。
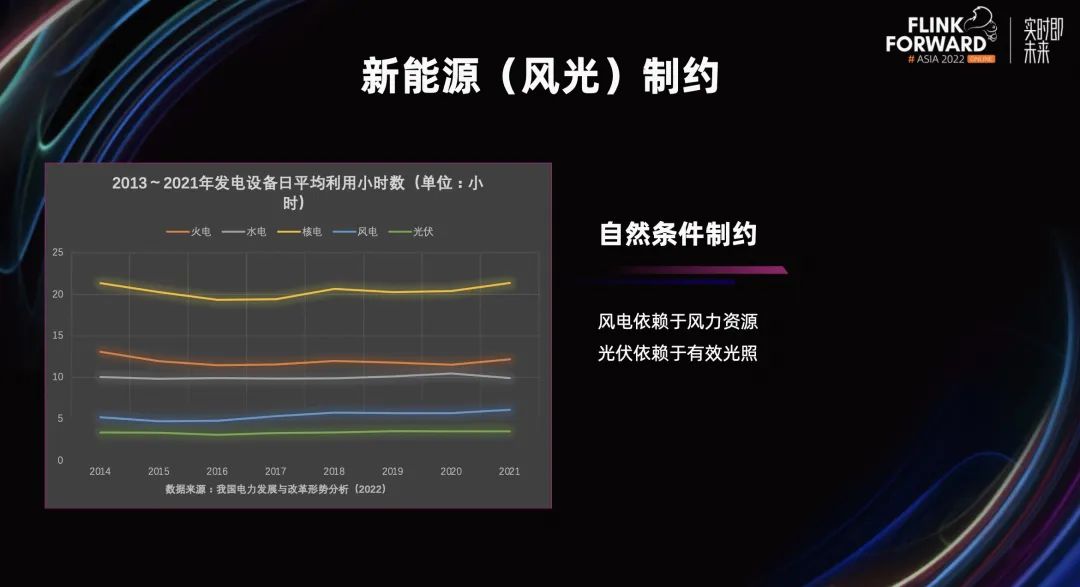
从发电设备的日平均利用小时数来看,风电和光伏的日平均可利用小时数都维持在一天五个小时左右,这还是综合了全年的数据进行的平均计算。如果单看某一段时期,利用小时数会更低,对整个电网的稳定运行是特别不利的,主要是因为风电和光伏严重依赖自然条件进行发电。所以,针对场站,在自然条件允许的情况下,确保风电和光伏的满负荷运转,是运维考虑的首要问题。

从场站侧来看,我们在系统建设上的主要出发点有以下三点:
刚才所描述的设备,在风光可利用窗口期内,尽可能多发电是首要的目的。
希望合理减少人工的运维投入,更多进行自动化的运转。
能预测风光的强度,也就能大概预测发电量,对并网运行和电力市场的现货交易情况都有很大用处。
02
技术架构
2.1 整体架构
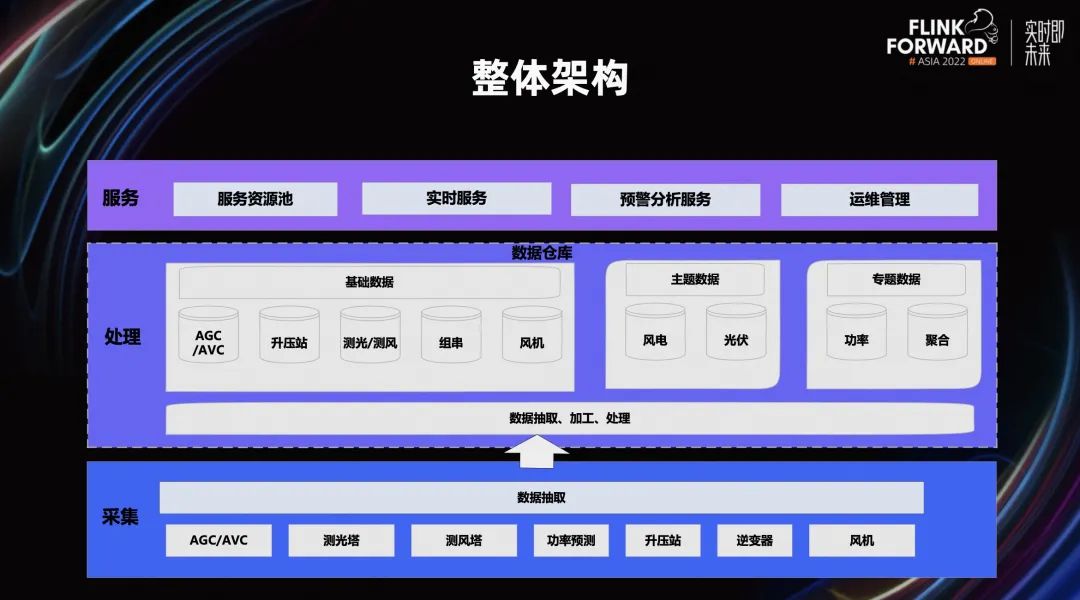
从上图抽象的简单处理架构可以看出,我们把核心系统分为了三个部分,分别是采集、处理、服务。
采集:利用物联网的子系统,适配各种采集协议,进行数据采集。更多的是电力行业相关的专有协议,经过简单的处理后推送到处理系统。
处理:包含了整个 Flink 流处理在内的整套处理分析、存储中心。
服务:利用处理之后的数据,结合业务系统的数据进行对外服务。
2.2 “分布式”系统
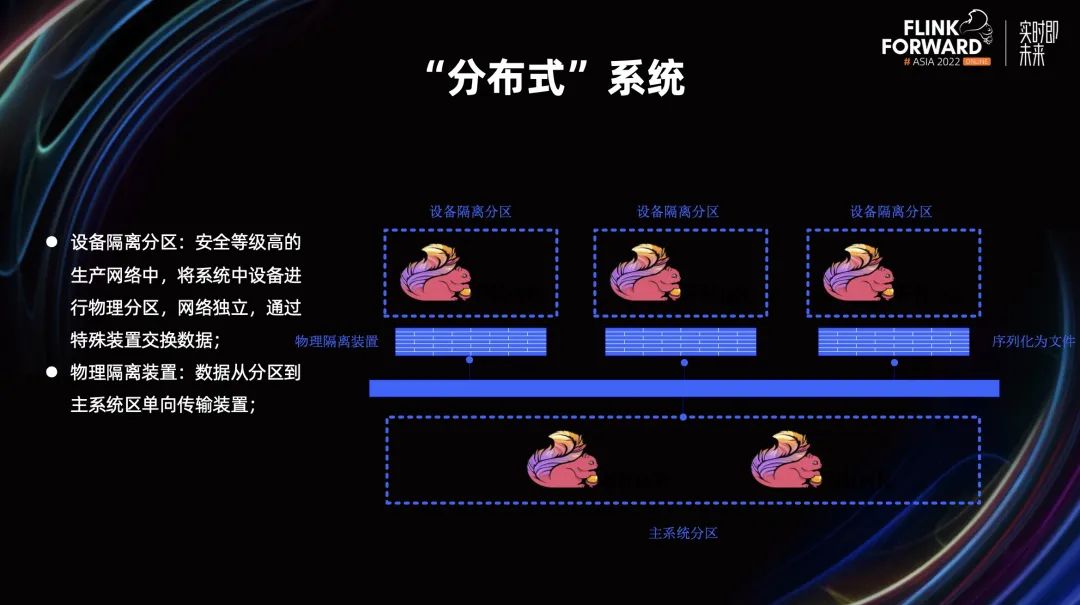
通常意义上的分布式系统,可能就是系统分布在各个节点里进行协同的交互。但由于我们现场场站的限制,我们的分布节点之间不能进行直接通讯。按照标准要求会进行设备隔离的分区,它利用硬件将系统中设备进行了物理分区,网络是独立的,但它又没有完全阻挡数据的交互,它可以通过特殊装置进行数据交换,物理隔离装置就起到了这个作用。我们的系统采用的是单向隔离,数据只从分区到主系统分区进行单向的数据传输。
03
应用落地
3.1 隔离分区处理
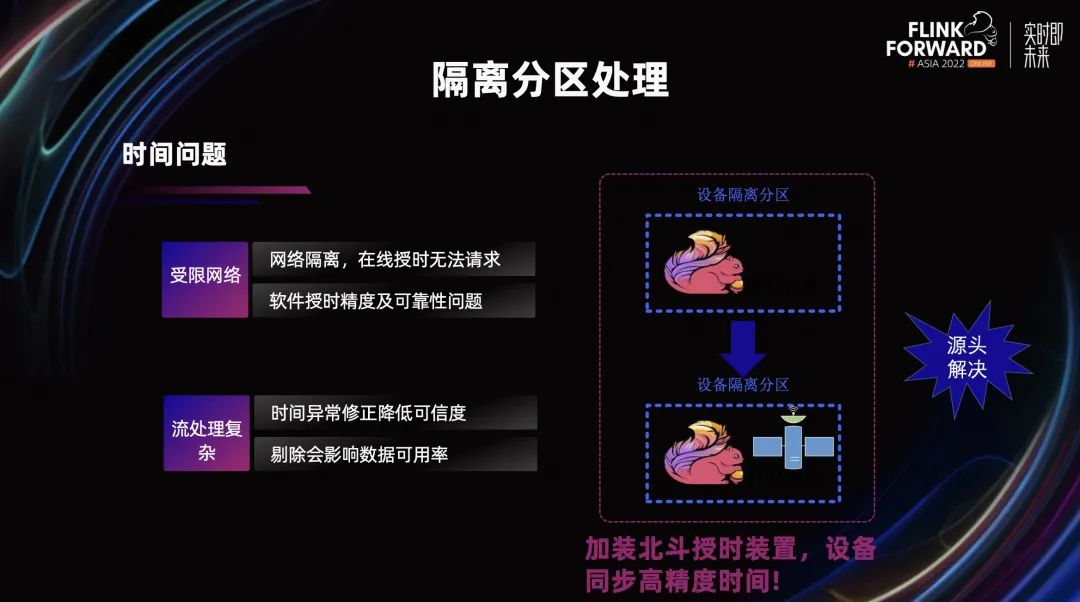
时间问题可能是分布式系统大家都会碰到的常见问题,在我们的系统里这个问题也比较突出。传感器的数量较多,而且传感器的数值对系统的运作还很重要。因为系统处于受限的网络环境中,高精度在线授时无法进行请求,软件授时精度及可靠性也无法得到保证。同时,我们采用流处理模式处理时间的问题,很难进行数据的清洗,剔除又会降低数据的可用率。
最开始我们的思路是采用清洗的办法来处理,但处理难度太大,我们就换了个思路。我们在隔离分区内部加上了北斗授时装置,这样分区内的高精度授时传感器都从授时装置中获取高精度的时间。当传感器的数据到达处理系统时,绝大部分时间都可以确保是正常的,极少量的异常数据也是在可容忍的范围内。

通常空间和时间是相伴的问题,特别是风机,它的运作和摆头式的电风扇很类似,叶片绕电机的轴转动,电机又绕基座转动,但风机的转动频率可能会比电风扇低很多。这个问题如果在游戏里,它就是相对坐标和矩阵运算的问题。
在我们的系统里,我们希望所有组件都可以,以统一的坐标进行展示。简单来说就是,给定一个时刻场站所有运行风机的瞬时状态位置,可以在一张图里反馈出来,不需要再进行一些复杂的矩阵或者空间运算。
处理方式是,传感器的数据在进入系统后,匹配塔基的基础数据,然后基于统一的坐标框架,把瞬时姿态信息求解,之后就会落库到时序数据库里进行存储。

传感器的数据预处理和清洗是数据利用的基础。
在预处理上,不少传感器数据在设计时,为了数据的高效和快速传输,会进行一定的计算或者合并处理。在预处理过程中就需要根据传感器的元数据定义,还原数据的真实含义值,最后进行测试和分析。
在数据清理上,我们主要用来处理时间标注、值的跳变、数据量缺失,进行补充差值。
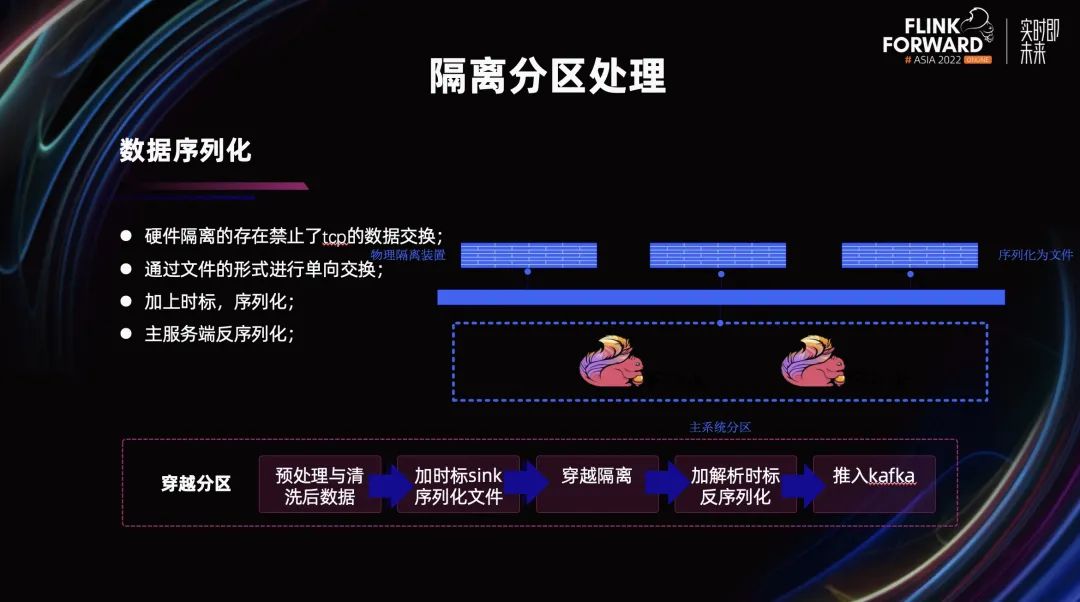
在数据架构部分,我们介绍了网络的隔离状况,它无法利用 tcp 进行数据交互,只能通过文件的方式进行数据传输。基于这个方式,我们利用了增量同步的思路,将数据加上指标后序列化到小文件里,在主服务端循环监测数据文件的变化情况。
有新的文件到达系统之后立即进行反序列化,解析到消息队列中进行后续处理。在整个过程中,数据其实会存在一定延迟,但数据交换的频率足够高,影响不是特别大。
3.2 主系统区处理

在主系统分区里,不仅包含了很多传感器数据,还包含了业务系统数据、与传感器有关联的设备的详细信息、传感器所组成的主设备的详细信息。在这里,可以利用系统之间的数据进行合并分析,掌握设备全体的状态信息。根据我们的划分,我们将按照聚合差值、推导进行数据的拼装合并,然后也会按照比值、差值、时间进行统计。

下面以一个设备的数据整合为例说明一下。
通常一个设备它有上千个传感器,它每个传感器获取的都是单一的测点信息,且每个传感器获取的采样频率不一致。那么设备的瞬时状态和整体的情况是如何的分析的呢?
这个问题就和盲人摸象的故事一样,即使我们上了很多监测手段,但每个监测手段都是独立的。我们真正需要的是,可以整合所有问题,然后告诉我们这个设备的状态是否正常。
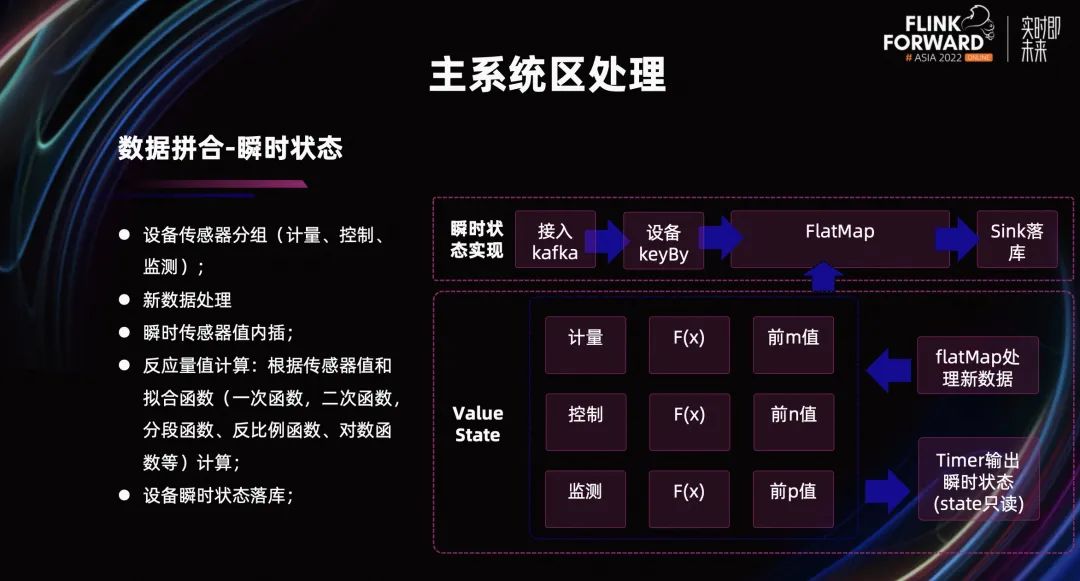
针对设备的瞬时状态,我们处理的思路是,根据设备传感器的分组,确定它是属于计量、控制还是监测。当新的测点数据到达系统后,我们利用属性信息将传感器的分组进行整合运算。在运算状态里,我们会来维持设备本身的传感器信息的分组、运算函数、运算函数所需要的前置信息。
当新的数据进入系统后,我们会进行状态值的更新。而瞬时状态值的计算是定时根据传感器值和拟合函数计算得到。这些拟合函数用的比较多的,包含一次函数、二次函数、分段函数、反比例函数、对数函数等。最终这些设备的瞬时状态会通过异步的形式落库。
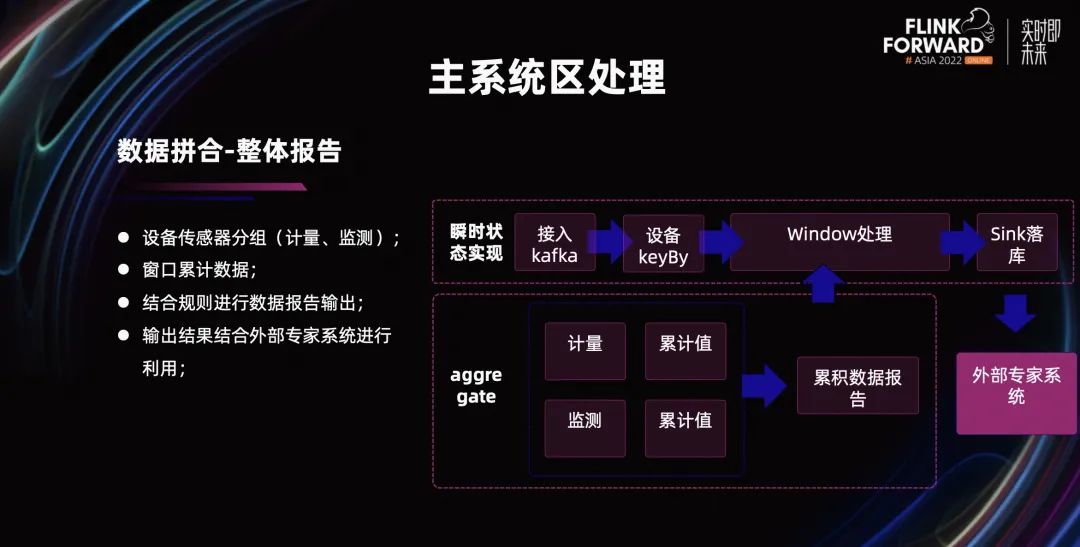
接下来我们来看一下长时间维度的整体情况。
按照五分钟或者一个小时的情况统计,处理过程其实是类似的。不同的是计算过程及函数方法的差异,对应的结果会进入其他的系统进行综合的分析和利用。

单一的设备处理介绍,基本上就是上述思路。更上一层,可能涉及到设备之间和场站之间的信息。主要包括遥测数据、峰谷差数据、电镀统计数据、停运数据。他们的整体统计情况,我们主要通过一些聚合运算来完成。
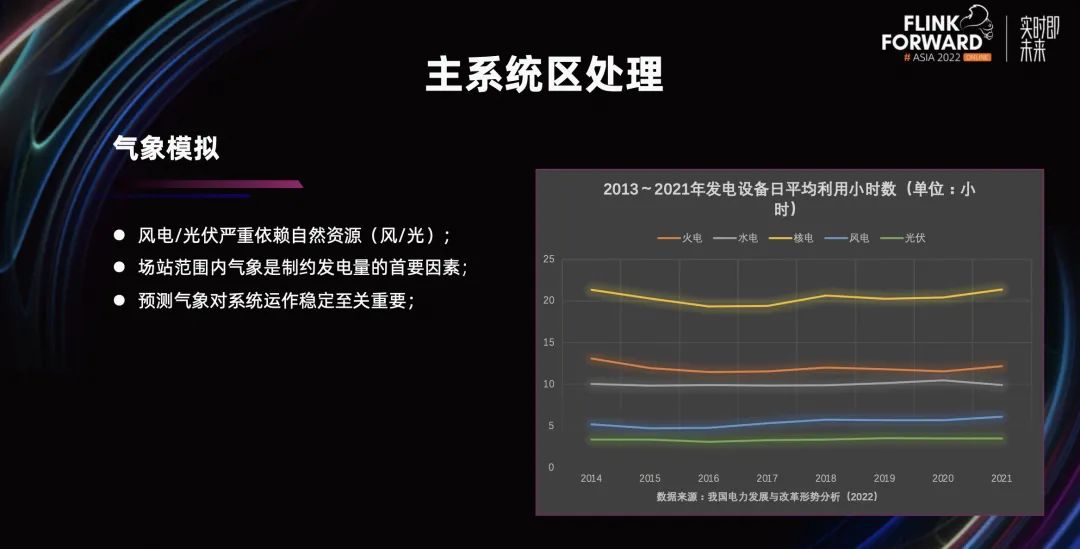
还记得我们在最开始的时候,我们提到了风光严重靠天吃饭的问题。气象就是天的核心,准确的预测气象是非常重要的研究内容。
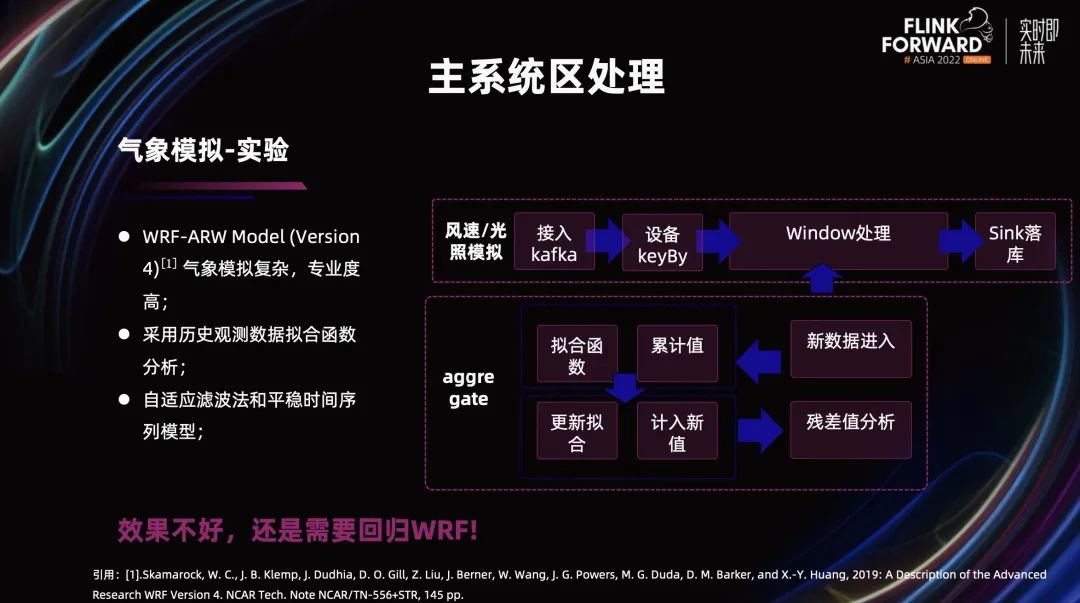
当前主流的方法是进行物理模型的创建,然后进行气象模拟,但它的专业度高,复杂度也高。所以我们想尝试通过将场站几年的历史数据进行拟合,不断迭代分析完善,进行大概的预测。利用文献资料,我们选取了自适应滤波法和平稳时间序列模型,在 Flink 里进行实现。然后根据历史数据和传感器当前的实时数据进行迭代分析。
效果其实不是特别理想,也没有想到更好的解决办法。后续我们可能还会借助建模的方式进行场站范围内微气象的建模,进行分析和预测。
04
后续及其他
4.1 后续

在气象预测方面,如果一条路不太通顺,我们可能会换种思路进一步尝试。
在辅助传感器的应用方面,无论是我们还是业界,基于传感器数据的综合使用分析,还属于浅层利用,离智能化的路还比较长。
在管理融合方面,结合现场的实际需求,真正的让传感器发挥效应,是很值得挖掘的。另外运维现状,新的系统在不断建设,系统之间也没有打通。后续将构想以处理中心的办法来驱动技术和管理应用的结合。
4.2 总结

首先,在专业度上,我们属于跨越不同行业进行融合,在广度而非深度上进行 Flink 利用,很少会动底层实现的能力;其次,对能稳定运行且不干扰其他业务系统的运转,我们将会降低应用程序设计的复杂度,从而达到减少出错率的目的;最后,我们考虑更多的是,通过软硬件结合来协同处理问题。比如时间问题,Flink 处理起来可能会比较困难,我们就会引入硬件来解决这个问题。问题可能在系统之内,但是解决的办法可能在软件系统之外。软硬件结合,其实我们的批处理和流处理也是分开的系统。后续我们可能也会考虑在批流合一方面进行一些尝试。
4.3 今年工作的地点和环境

往期精选





▼ 「活动推荐」扫下方图片参与报名▼

▼ 关注「Apache Flink」,获取更多技术干货 ▼

 点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源
点击「阅读原文」,免费领取 5000CU*小时 Flink 云资源