文章目录
- HTTP
- 是什么
- 报文结构
- 请求头部
- 响应头部
- 工作原理
- 用户点击一个URL链接后,浏览器和web服务器会执行什么
- http的版本
- 持久连接和非持久连接
- 无状态与有状态
- Cookie和Session
- http方法:
- get和post的区别
- 状态码
- HTTPS
- 是什么
- ssl
- 如何搞到证书
- nginx中的部署
- 加密
- CA
- 数字证书
- hash算法
- 对称加密
- 非对称加密
- 数字签名
- webhook
HTTP
是什么
HTTP(Hypertext Transfer Protocol)是一种用于传输超文本的协议。它是互联网上数据传输的基础,用于客户端和服务器之间的通信。HTTP使用TCP/IP协议来传输数据,通常在Web浏览器和Web服务器之间进行通信。
HTTP的主要目标是实现客户端和服务器之间的通信和数据传输。客户端发送HTTP请求到服务器,服务器则返回HTTP响应作为回应。HTTP请求通常由一个URL(Uniform Resource Locator)来标识要访问的资源,例如网页、图片或其他文件。HTTP响应包含了请求的结果,例如HTML文档、图片的二进制数据或其他数据。
HTTP使用了一些常见的方法来定义请求的类型,例如GET、POST、PUT和DELETE等。GET方法用于请求服务器发送指定资源,而POST方法用于向服务器提交数据。HTTP还使用状态码来表示请求的结果,例如200表示请求成功,404表示未找到请求的资源,等等。
HTTP协议是无状态的,这意味着服务器不会保存客户端的状态信息。为了保持状态,HTTP使用了一些机制,如Cookie和Session,以跟踪用户的会话。
总之,HTTP是一种用于在客户端和服务器之间传输超文本数据的协议,它在互联网上扮演着重要的角色,使得我们能够访问和交换网页、图片、文件和其他资源。
报文结构
HTTP报文是在HTTP协议中用于在客户端和服务器之间传输数据的格式。它由请求报文和响应报文两种类型组成,下面详细解释每种报文的结构:
-
请求报文结构:
请求报文由以下几个部分组成:- 请求行(Request Line):包含了请求方法、目标URL和HTTP协议版本。
- 请求头部(Header):包含了关于请求的各种附加信息,如请求的主机、内容类型、缓存控制等。
- 空行(Blank Line):空行用于分隔请求头部和请求体。
- 请求体(Request Body):可选的,用于传输请求的数据,例如在POST请求中的表单数据。
请求行的格式:请求方法 请求目标 HTTP协议版本
示例:GET /index.html HTTP/1.1
请求头部的格式:字段名: 值
示例:Host: www.example.com
Content-Type: application/json -
响应报文结构:
响应报文由以下几个部分组成:- 状态行(Status Line):包含了HTTP协议版本、状态码和状态消息。
- 响应头部(Header):包含了关于响应的各种附加信息,如内容类型、响应的日期、服务器信息等。
- 空行(Blank Line):空行用于分隔响应头部和响应体。
- 响应体(Response Body):可选的,用于传输响应的数据,例如HTML文档、图片或JSON数据。
状态行的格式:HTTP协议版本 状态码 状态消息
示例:HTTP/1.1 200 OK
响应头部的格式:字段名: 值
示例:Content-Type: text/html
Content-Length: 1024
在请求和响应报文中,请求行和状态行指定了HTTP协议版本、请求或响应的状态码和相关信息。请求头部和响应头部用于传递各种元数据,如主机、内容类型、缓存控制等。请求体和响应体则用于传输具体的数据内容。
总结:HTTP报文结构包括请求报文和响应报文。请求报文包含请求行、请求头部、空行和请求体,而响应报文包含状态行、响应头部、空行和响应体。这种结构化的格式使得客户端和服务器能够准确地交换数据,并理解请求和响应的含义和要求。
请求头部
请求头部(Headers)是HTTP请求报文中的一部分,它包含了关于请求的各种附加信息。下面是一些常见的请求头部字段及其详细信息:
-
Host:
- 描述:指定目标服务器的主机名和端口号。
- 示例:Host: www.example.com
-
User-Agent:
- 描述:标识客户端(浏览器或其他工具)的名称和版本信息。
- 示例:User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36
-
Accept:
- 描述:指定客户端可以接受的响应内容类型。
- 示例:Accept: text/html, application/xhtml+xml, application/xml;q=0.9, /;q=0.8
-
Accept-Language:
- 描述:指定客户端接受的自然语言。
- 示例:Accept-Language: en-US,en;q=0.9
-
Accept-Encoding:
- 描述:指定客户端可以接受的内容编码方式,如gzip、deflate等。
- 示例:Accept-Encoding: gzip, deflate
-
Referer:
- 描述:指定当前请求的源URL,用于告诉服务器请求的来源,从那个网站跳转过来的。
- 示例:Referer: https://www.example.com/page1.html
-
Cookie:
- 描述:包含客户端之前接收到的服务器发送的Cookie信息。
- 示例:Cookie: session_id=abc123; user_id=123456
-
Authorization:
- 描述:用于在需要身份验证的请求中发送用户凭证,如用户名和密码。
- 示例:Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l
-
Content-Type:
- 描述:指定请求体中的内容类型。
- 示例:Content-Type: application/json
-
Content-Length:
- 描述:指定请求体的长度(以字节为单位)。
- 示例:Content-Length: 1024
这些是常见的请求头部字段,可以根据具体需求添加或修改头部字段来传递更多的请求信息。请求头部的信息帮助服务器理解客户端的需求,并进行相应的处理和响应。
响应头部
HTTP响应头部(Header)包含了关于响应的各种附加信息,以下是一些常见的响应头部字段及其详细信息:
- Content-Type:
该字段指示了响应体中所传输数据的媒体类型(MIME类型),例如"text/html"表示HTML文档,"application/json"表示JSON数据,"image/jpeg"表示JPEG图片等。 - Content-Length:
该字段指示了响应体的长度(以字节为单位),用于客户端确定响应体的大小。 - Content-Encoding:
该字段指示了响应体所采用的编码方式,例如"gzip"表示使用GZIP压缩,"deflate"表示使用Deflate压缩等。 - Cache-Control:
该字段指示了响应的缓存策略,包括缓存的最大有效时间、是否允许缓存副本以及是否允许缓存服务器等。 - Expires:
该字段指示了响应的过期时间,即响应将在何时过期,过期后客户端必须向服务器重新请求。 - Last-Modified:
该字段指示了响应体的最后修改时间,用于缓存验证,客户端可以在后续请求中发送"If-Modified-Since"字段以检查资源是否已经被修改。 - Server:
该字段指示了响应的服务器软件名称和版本号。 - Set-Cookie:
该字段用于在客户端设置一个或多个HTTP Cookie,以便在后续请求中进行会话跟踪或用户识别。 - Location:
该字段用于重定向响应,指示客户端应该跳转到的新的URL地址。 - Connection: 指示客户端与服务器之间的连接类型。"keep-alive"表示保持持久连接,允许多个请求和响应在同一个连接上进行。
- Date: 指示响应生成的日期和时间。
- ETag: 提供与响应关联的实体标签,用于缓存机制。它可以是一个唯一的标识符,用于标记特定版本的资源,可以判断网页是否发生了变化。
以上是一些常见的HTTP响应头部字段,通过这些字段,服务器可以向客户端提供更多有关响应的相关信息,以便客户端正确处理响应并进行适当的处理。
工作原理
HTTP的工作原理可以分为以下几个步骤:
-
客户端发起请求:客户端(通常是Web浏览器)向服务器发送HTTP请求。请求由以下组成:
- 请求行:包括请求方法(如GET、POST)、请求的URL和使用的HTTP协议版本。
- 请求头:包含附加的请求信息,如浏览器类型、接受的数据类型等。
- 请求体(可选):在某些请求中,如POST请求,可能会包含数据,例如表单字段或上传的文件。
-
服务器响应请求:服务器接收到请求后,会解析请求并准备响应。响应由以下组成:
- 状态行:包括HTTP协议版本、状态码(如200表示成功、404表示未找到资源)和相应的状态信息。
- 响应头:包含附加的响应信息,如数据类型、日期等。
- 响应体:包含服务器返回的实际数据,例如HTML文档、图片的二进制数据或其他数据。
-
数据传输:在响应的过程中,数据通过TCP/IP协议在客户端和服务器之间进行传输。TCP/IP协议提供了可靠的数据传输机制,确保数据的准确性和完整性。
-
完成请求:一旦服务器完成响应,它会关闭与客户端的连接,完成请求-响应过程。客户端收到响应后,根据响应的内容进行相应的处理,例如渲染网页或显示图像。
需要注意的是,HTTP是一种无状态协议,每个请求-响应周期都是相互独立的。为了跟踪用户的状态,HTTP使用了一些机制,如Cookie和Session。Cookie是服务器通过响应头在客户端存储的小型数据文件,它包含了与用户相关的信息。当客户端发送下一次请求时,Cookie会随着请求头一起发送到服务器,服务器可以根据Cookie中的信息来识别和跟踪用户。Session则是在服务器端保存用户状态的一种机制,服务器会为每个会话分配一个唯一的标识符,将用户的状态信息存储在会话中。
通过这样的工作原理,HTTP协议使得客户端和服务器能够进行可靠的数据交换,实现了互联网上的信息传输和资源访问。
用户点击一个URL链接后,浏览器和web服务器会执行什么
当用户点击一个URL链接后,浏览器和Web服务器会执行以下步骤:
-
解析URL:浏览器首先解析URL(Uniform Resource Locator),提取出其中的协议、主机名、端口号(如果有)、路径和查询参数等信息。
-
建立连接:浏览器根据解析得到的主机名和端口号,使用TCP/IP协议与Web服务器建立连接。默认情况下,HTTP使用端口号80进行通信,而HTTPS使用端口号443。
-
发起HTTP请求:一旦与Web服务器建立连接,浏览器会构建HTTP请求。该请求包括请求行、请求头和请求体等部分:
- 请求行:包括请求方法(例如GET、POST)、路径和使用的HTTP协议版本。
- 请求头:包含附加的请求信息,如浏览器类型、接受的数据类型等。
- 请求体(可选):对于某些请求,如POST请求,可能会包含数据,例如表单字段或上传的文件。
-
服务器处理请求:Web服务器接收到浏览器发送的HTTP请求后,会解析请求并根据请求的内容执行相应的处理。这可能涉及查询数据库、读取文件、处理业务逻辑等。
-
生成HTTP响应:服务器根据请求的处理结果生成HTTP响应。响应由以下组成:
- 状态行:包括HTTP协议版本、状态码(如200表示成功、404表示未找到资源)和相应的状态信息。
- 响应头:包含附加的响应信息,如数据类型、日期等。
- 响应体:包含服务器返回的实际数据,例如HTML文档、图片的二进制数据或其他数据。
-
数据传输:在响应的过程中,服务器通过已建立的TCP/IP连接将HTTP响应发送回浏览器。TCP/IP协议确保数据的可靠传输,以确保数据的准确性和完整性。
-
浏览器处理响应:浏览器接收到服务器发送的HTTP响应后,根据响应的内容进行相应的处理。这可能包括渲染网页、显示图像、执行JavaScript代码等。
-
关闭连接:一旦响应完成,服务器关闭与浏览器之间的连接。浏览器根据需要可以继续发送其他请求或保持连接以获取其他资源。
渲染网页:渲染网页指的是将从服务器获取的HTML、CSS和JavaScript等网页资源在浏览器中进行解析和显示的过程。简单来说,渲染网页就是将网页内容呈现给用户,以便用户能够看到和与网页进行交互。
通过这些步骤,用户点击一个URL链接后,浏览器和Web服务器之间完成了请求和响应的交互过程,从而实现了网页的加载和显示。
问题:一个网站打不开了,如何去判断问题所在
- 检查域名解析是否有问题,能否解析出一个ip地址
- ping 服务器ip地址。看服务是否开机启动
- 检查服务器的文本服务是否开启或者检查服务器的web服务的短端口是否打开
- 检查web服务器的日志,看看web服务是否有限制
- 检查web服务器的日志,看看web服务是否有限制
思路:由外到内,一层一层去检查。
[root@localhost ~]# iptables -A INPUT -p tcp --dport 80 -j DROP
[root@localhost ~]# iptables -F
这段代码是针对Linux系统上的iptables防火墙进行配置的命令。
-
iptables -A INPUT -p tcp --dport 80 -j DROP:这是iptables命令的一部分,用于添加一个规则到INPUT链。下面是对每个选项的解析:iptables:该命令用于配置iptables防火墙规则。-A INPUT:指定规则将添加到INPUT链中,该链用于处理进入系统的数据包。-p tcp:指定协议为TCP,表示该规则仅适用于TCP数据包。--dport 80:指定目标端口为80,表示该规则仅适用于目标端口为80的数据包(通常用于HTTP服务)。-j DROP:指定动作为DROP,表示匹配该规则的数据包将被丢弃(即阻止进入系统)。
因此,这行命令的作用是阻止通过TCP协议访问本机的80端口(通常是Web服务器的默认端口)的数据包。
-
iptables -F:这是另一个iptables命令,用于清除防火墙规则,即将所有规则恢复到默认设置。下面是对命令的解析:-F:指定清除(flush)规则,即删除所有的防火墙规则。
所以,这行命令的作用是清除所有已配置的防火墙规则,将iptables恢复到默认设置。
请注意,这段代码需要以root用户身份执行,因为iptables命令通常需要root权限来配置系统级防火墙规则。并且在对防火墙进行配置时,请确保你知道自己在做什么,以免意外地阻止了正常的网络流量或导致其他问题。
http的版本
HTTP(Hypertext Transfer Protocol)是一种用于在Web上传输数据的协议。HTTP的不同版本有不同的特点和优缺点。以下是几个常见的HTTP版本及其区别:
- HTTP/1.0:
- 非持久连接:每次请求/响应完成后,TCP连接会关闭,需要重新建立连接,造成性能上的开销。
- 无状态:服务器不会保存客户端请求的任何信息,每个请求都是独立的。
- 缺点:每个请求都需要建立和关闭连接,效率较低。
- HTTP/1.1:
- 持久连接:多个请求/响应可以共享同一个TCP连接,减少了连接建立和关闭的开销。
- 无状态:与HTTP/1.0相同,服务器不会保存客户端请求的任何信息。
- 新增功能:引入了请求头的Host字段、分块传输编码、缓存控制等。
- 优点:减少了连接建立和关闭的开销,提高了性能。
- HTTP/2:
- 二进制分帧:将请求和响应消息分割为二进制的帧,可以并行发送和解析,提高效率。
- 多路复用:通过单个TCP连接并行处理多个请求和响应,消除了HTTP/1.x中的队头阻塞问题。
- 服务器推送(Server Push):服务器可以主动将多个相关资源推送给客户端,减少了额外的请求。
- 头部压缩:使用专门的算法对头部信息进行压缩,减少了数据传输量。
- 优点:提高了性能和效率,减少了延迟。
- HTTP/3:
- 基于UDP:使用QUIC(Quick UDP Internet Connections)作为传输协议,减少了TCP的握手延迟。
- 多路复用:类似于HTTP/2,通过单个连接并行处理多个请求和响应。
- 错误恢复:在网络切换或连接中断后,能够更快地恢复连接。
- 优点:提高了性能和效率,特别是在高延迟和丢包环境下。
总结:
- HTTP/1.0和HTTP/1.1是基于TCP的协议,HTTP/2和HTTP/3则在传输层选择了更高效的协议(HTTP/2使用TCP,HTTP/3使用UDP)。
- 持久连接和多路复用是HTTP/1.1、HTTP/2和HTTP/3相较于HTTP/1.0的重要改进,减少了连接建立和关闭的开销,提高了性能。
- HTTP/2和HTTP/3的头部压缩、二进制分帧以及服务器推送等功能进一步优化了性能和效率。
可以从速度和安全性方面进行回答。
持久连接和非持久连接
HTTP的持久连接和不持久连接是关于建立和维持连接的不同方式。下面是它们的详细解释:
-
非持久连接(Non-Persistent Connection):
- 在非持久连接的情况下,每次请求都需要建立一个新的连接。
- 当客户端发送一个请求到服务器时,建立TCP连接,发送请求并接收响应后,连接就会被关闭。
- 每个请求/响应周期都需要重新建立连接,导致了较高的延迟。
-
持久连接(Persistent Connection):
- 在持久连接中,客户端和服务器之间的连接在多个请求和响应之间保持打开状态。
- 客户端可以发送多个请求,而无需为每个请求建立新的连接。
- 服务器在接收到请求后,可以在同一个连接上发送多个响应。
- 连接可以在一定的时间后关闭,或者根据头部字段"Connection: close"来指示关闭连接。
持久连接相对于不持久连接有以下优点:
- 减少了连接建立和断开的开销:不需要为每个请求建立新的连接,节省了时间和资源。
- 减少了网络延迟:由于连接保持打开状态,后续请求可以更快地发送和接收响应,减少了整体的延迟时间。
- 提高了性能和吞吐量:通过复用连接,可以同时处理多个请求和响应,提高了服务器的处理能力和系统的吞吐量。
然而,持久连接也存在一些注意事项和限制:
- 连接资源限制:由于每个持久连接需要占用服务器资源,服务器需要管理和控制同时打开的连接数,以防止资源耗尽。
- 阻塞问题:如果一个响应较慢,可能会阻塞其他请求的处理,影响性能。
- 超时和过期问题:由于连接保持打开的时间较长,可能会导致某些资源的过期或变化,需要进行适当的缓存策略和处理。
总而言之,持久连接是一种提高性能和效率的方法,可以减少连接建立和断开的开销,但需要注意资源管理和阻塞等问题。
无状态与有状态
有状态和无状态是两种不同的概念,涉及到系统或协议如何管理和处理信息的持久性。
-
有状态(Stateful):
- 概念:有状态是指系统或协议在处理请求时会记住之前的状态信息。服务器会保留客户端的状态,以便在后续请求中使用。服务器可以识别不同的客户端,跟踪会话,存储和共享状态数据。
- 优点:
- 上下文传递:服务器可以跟踪用户会话和上下文信息,可以根据之前的请求处理逻辑来响应后续请求,提供个性化的服务。
- 简化开发:服务器可以在会话期间存储和管理数据,减少了开发人员需要考虑的状态管理和数据存储的复杂性。
- 缺点:
- 扩展性:由于服务器需要维护客户端的状态信息,扩展服务器规模和处理并发请求可能更加困难。
- 可靠性:服务器的故障或重启可能导致客户端的状态丢失,需要进行额外的处理来确保数据的持久性和可靠性。
- 负载均衡:在多台服务器之间进行负载均衡时,需要确保客户端的状态在不同服务器之间的一致性,增加了管理的复杂性。
-
无状态(Stateless):
- 概念:无状态是指系统或协议在处理请求时不保留之前的状态信息。每个请求都是独立的,服务器不会识别客户端,不会跟踪会话,不会存储客户端的状态信息。
- 优点:
- 可伸缩性:由于服务器不需要维护客户端的状态,可以更容易地扩展服务器规模,处理更多的并发请求。
- 简化部署:无状态协议和应用程序可以更容易地部署和复制,减少了服务器之间状态同步的需求。
- 可缓存性:由于每个请求都是独立的,可以对响应进行缓存,提高性能和效率。
- 缺点:
- 会话管理:服务器无法直接跟踪用户会话,需要使用额外的机制(如会话标识符或Cookie)来管理会话状态。
- 身份验证:每个请求都需要进行身份验证,以确认用户的权限和身份,增加了处理的复杂性。
- 上下文传递:对于需要传递上下文信息的应用,可能需要使用额外的机制来传递上下文,如查询参数、URL重写、隐藏字段等。
选择有状态还是无状态取决于具体的需求和场
景。有状态适用于需要跟踪会话、上下文和个性化服务的应用,但可能面临扩展性和可靠性方面的挑战。无状态适用于高可伸缩性和可缓存性的场景,但需要额外的会话管理和上下文传递机制。
Cookie和Session
Cookie和Session是用于在Web应用程序中管理用户状态和跟踪会话的常见机制。
-
Cookie(Cookie):
- 介绍:Cookie是服务器在客户端(通常是浏览器)存储少量数据的一种方式。当用户访问网站时,服务器可以通过HTTP响应在用户的浏览器中设置一个Cookie。该Cookie会被保存在浏览器中,每次用户发送请求时,浏览器会自动将Cookie发送给服务器。
- 关键点:
- 存储位置:Cookie存储在用户的浏览器中。
- 数据大小:Cookie通常只能存储小量的文本数据。
- 客户端发送:每次请求时,浏览器会自动将相应的Cookie发送给服务器。
- 生命周期:可以设置Cookie的过期时间,也可以创建会话Cookie,仅在用户关闭浏览器时过期。
- 用途:Cookie常用于实现用户身份验证、跟踪用户偏好设置、记录购物车内容等。
-
会话(Session):
- 介绍:会话是一种在服务器端存储和管理用户状态信息的机制。当用户访问网站时,服务器会为每个用户创建一个唯一的会话,并分配一个会话标识符(Session ID)。会话ID通常通过Cookie或URL重写的方式发送给客户端,在后续的请求中,客户端会将会话ID发送回服务器。
- 关键点:
- 存储位置:会话数据存储在服务器端,通常保存在内存或持久化存储(如数据库)中。
- 数据大小:会话可以存储更大的数据量,不受浏览器限制。
- 客户端发送:会话ID通常通过Cookie发送给客户端,浏览器会自动将会话ID附加在每个请求中。
- 生命周期:会话的生命周期由服务器管理,可以根据需要设置过期时间。
- 用途:会话常用于实现用户登录状态管理、保持用户上下文信息、存储用户数据等。
关系:
- Cookie和Session经常结合使用。服务器可以使用Cookie在客户端存储一个唯一的会话ID,而将实际的会话数据存储在服务器端的Session对象中。当客户端发送请求时,会自动附带包含会话ID的Cookie,服务器可以根据会话ID找到对应的会话数据,实现状态的管理和跟踪。
- 典型的流程是:用户通过登录页面进行身份验证,服务器验证成功后创建一个会话,生成一个会话ID,并将会话ID存储在一个名为"session"的Cookie中发送给客户端。客户端在后续的请求中会自动附带该Cookie,服务器根据会话ID来获取对应的会话数据,
实现状态管理和个性化服务。
总结:Cookie是一种在客户端存储少量数据的机制,用于传递会话ID;而Session是一种在服务器端存储和管理用户状态信息的机制。Cookie用于在客户端存储会话ID,而Session用于在服务器端存储实际的会话数据。它们结合使用可以实现状态管理和会话跟踪。
http方法:
-
以下是HTTP中常用的四种方法(也称为HTTP动词)的详细介绍:
-
GET(获取):
GET方法用于从服务器获取指定资源的表示形式。通过发送GET请求,客户端可以请求服务器发送特定资源的数据。GET请求通常是幂等的,这意味着多个相同的GET请求不会对服务器产生副作用,也不会改变资源的状态。它主要用于获取数据,而不是修改或创建数据。 -
POST(提交):
POST方法用于向服务器提交数据,通常用于创建新资源或对现有资源进行修改。通过发送POST请求,客户端将数据作为请求的主体发送给服务器,并期望服务器根据请求执行相应的操作。与GET请求不同,POST请求不是幂等的,即多个相同的POST请求可能会导致不同的结果。POST请求常用于提交表单数据、上传文件等操作。 -
PUT(更新):
PUT方法用于向服务器发送数据,以便在指定位置创建或更新资源。通过发送PUT请求,客户端将数据作为请求的主体发送给服务器,并要求服务器将该数据存储在指定的URL位置。PUT请求通常是幂等的,即多次发送相同的PUT请求将具有相同的结果。PUT请求常用于更新整个资源或在指定位置创建新资源。 -
DELETE(删除):
DELETE方法用于请求服务器删除指定的资源。通过发送DELETE请求,客户端可以请求服务器删除指定URL位置的资源。DELETE请求是幂等的,即多次发送相同的DELETE请求将具有相同的结果。DELETE请求常用于删除资源,但要谨慎使用,因为删除后无法恢复数据。
这些HTTP方法允许客户端与服务器进行不同类型的交互,以便进行数据的获取、创建、更新和删除操作。根据具体的应用场景和需求,选择适当的HTTP方法非常重要。
-
get和post的区别
GET和POST是HTTP协议中最常用的两种方法,它们在以下几个方面有明显的区别:
- 数据传输位置:
- GET:通过URL的查询参数(Query Parameters)传输数据。数据附加在URL的末尾,以键值对的形式出现,例如:
https://example.com/resource?key1=value1&key2=value2。GET请求的数据可以被缓存、保存在浏览器的历史记录中,以及书签中。 - POST:通过请求的主体(Request Body)传输数据。数据不会显示在URL中,而是封装在请求的主体中进行传输。POST请求的数据不会被缓存或保存在浏览器的历史记录中。
- 数据长度限制:
- GET:由于数据通过URL传输,受到URL长度的限制。不同浏览器和服务器对URL长度的限制不尽相同,一般在几千个字符左右。
- POST:由于数据通过请求的主体传输,没有固定的长度限制。但是,服务器和应用程序可能会有对请求主体大小的限制。
- 安全性:
- GET:GET请求的数据会附加在URL中,因此在网络传输过程中容易被拦截和查看。因此,不应将敏感数据通过GET请求传输,例如密码或用户身份验证信息。
- POST:POST请求的数据位于请求主体中,不会明文显示在URL中,相对于GET请求具有更好的安全性。可以将敏感数据通过POST请求进行传输。
- 幂等性:
- GET:GET请求是幂等的,多次发送相同的GET请求不会对服务器产生副作用。即使多次请求,也不会改变资源的状态。
- POST:POST请求不是幂等的,多次发送相同的POST请求可能会导致不同的结果。每次请求都可能对服务器资源进行修改、创建新资源或执行其他非幂等操作。
总的来说,GET适合用于获取数据,对于幂等的操作和数据量较小的情况;而POST适合用于传输大量数据、进行非幂等操作、创建新资源或修改资源的情况。在设计和开发Web应用程序时,根据实际需求选择适当的HTTP方法非常重要。
状态码
以下是常用的HTTP状态码及其详细介绍:
-
200 OK:
表示请求成功。服务器成功处理了客户端的请求,并返回了请求的资源。 -
201 Created:
表示请求已成功,并且服务器创建了新的资源。通常在使用POST方法创建新资源时返回此状态码。 -
204 No Content:
表示服务器成功处理了请求,但没有返回任何内容。通常在使用DELETE方法删除资源或执行某些不需要返回内容的操作时返回此状态码。 -
400 Bad Request:
表示服务器无法理解客户端的请求。常见的原因包括语法错误、无效的请求消息、缺少必需的参数等。 -
401 Unauthorized:
表示请求需要进行身份验证。客户端未提供有效的身份验证凭据或未通过身份验证。 -
403 Forbidden:
表示服务器理解客户端的请求,但拒绝执行该请求。通常是因为客户端没有访问请求资源的权限。 -
404 Not Found:
表示服务器无法找到请求的资源。这可能是由于URL路径错误、资源被移除或不存在等原因造成的。 -
500 Internal Server Error:
表示服务器在执行请求时遇到了意外的错误。这通常是服务器端的问题,而不是客户端请求的问题。 -
503 Service Unavailable:
表示服务器暂时无法处理请求,通常是因为服务器过载或维护。客户端可以稍后重试该请求。
这些状态码是HTTP协议中常见的一部分,用于表示请求和响应之间的状态和结果。客户端根据状态码可以了解请求的处理情况,并根据需要采取适当的操作或显示相关的错误信息。
HTTPS
是什么
HTTPS代表超文本传输安全协议(Hypertext Transfer Protocol Secure)。它是一种通过加密和认证的方式来保护网络通信安全的HTTP协议扩展。
下面是HTTPS的详细说明:
-
安全性:
HTTPS通过使用安全套接层(SSL)或传输层安全性(TLS)协议来保护通信的安全性。这些协议使用加密算法对数据进行加密,以确保传输过程中的机密性和完整性。这样,敏感数据(如密码、个人信息等)在传输过程中不容易被窃听或篡改。 -
数据加密:
HTTPS使用公开密钥加密(Public Key Encryption)来保护数据的机密性。客户端和服务器之间的通信过程中,使用公钥对数据进行加密,只有服务器拥有相应的私钥才能解密数据。这样,即使有人在网络上截获了数据,也无法解密其内容。 -
证书验证:
HTTPS使用数字证书来验证服务器的身份。服务器拥有由可信的证书颁发机构(Certificate Authority,CA)签发的数字证书。客户端在与服务器建立连接时,会验证服务器提供的证书是否有效和可信。这样可以防止中间人攻击和伪装服务器的问题。 -
端口:
HTTP使用默认端口80进行通信,而HTTPS使用默认端口443进行通信。这样,服务器可以通过不同的端口区分HTTP和HTTPS请求,并正确处理相应的协议。 -
SEO影响:
HTTPS对网站的搜索引擎优化(SEO)有一定影响。搜索引擎(如Google)更倾向于显示和排名使用HTTPS的网站,因为HTTPS可以提供更好的安全性和数据保护。 -
速度影响:
由于HTTPS需要进行加密和解密操作,相对于HTTP而言,通信过程可能会稍微慢一些。但是,随着计算机硬件和网络技术的进步,这种差异已经趋于减小,一般用户很难察觉到明显的速度差异。
总的来说,HTTPS通过加密和认证机制提供了更高级别的网络通信安全,使得网站和应用程序能够保护用户的敏感数据,防止信息泄露和篡改。因此,对于需要保护隐私和数据安全的网站、电子商务平台和用户身份验证等应用,使用HTTPS是非常重要的。
ssl
Nginx是一个流行的开源Web服务器软件,它也可以用作反向代理服务器和负载均衡器。Nginx提供了支持SSL/TLS的功能,使得它可以安全地传输数据。下面是关于Nginx中SSL的详细介绍:
-
SSL和TLS:
SSL(Secure Sockets Layer)和TLS(Transport Layer Security)是一组用于加密和身份验证的协议,用于保护在网络上传输的数据。SSL是较早的协议版本,而TLS是SSL的继任者,目前广泛使用的是TLS的不同版本,如TLS 1.2和TLS 1.3。 -
Nginx中的SSL模块:
Nginx使用ngx_http_ssl_module模块来提供SSL/TLS功能。该模块需要在编译Nginx时启用,并且需要加载相应的SSL库。 -
证书和密钥:
SSL/TLS使用证书和私钥来进行加密和身份验证。证书用于验证服务器的身份,私钥用于解密数据。在Nginx中,您需要为您的域名获取有效的SSL证书,并将其与相应的私钥配对。 -
配置SSL:
在Nginx配置文件中,您需要进行以下配置来启用SSL:-
指定证书和私钥的文件路径:
ssl_certificate /path/to/ssl_certificate.crt; ssl_certificate_key /path/to/ssl_certificate.key; -
配置SSL协议和加密算法:
ssl_protocols TLSv1.2 TLSv1.3; ssl_ciphers EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH; ssl_prefer_server_ciphers on; -
配置SSL会话缓存:
ssl_session_cache shared:SSL:10m; ssl_session_timeout 10m; -
配置SSL会话票据:
ssl_session_tickets on; ssl_session_ticket_key /path/to/ssl_ticket.key; -
配置SSL证书验证:
ssl_trusted_certificate /path/to/trusted_certificate.crt; ssl_verify_client on;
-
-
HTTP重定向到HTTPS:
如果您想将所有HTTP请求重定向到HTTPS,可以添加以下配置:server { listen 80; server_name example.com; return 301 https://$server_name$request_uri; } -
HTTP/2支持:
Nginx还支持HTTP/2协议,它是一种更高效的传输协议。要启用HTTP/2,您需要在SSL配置中添加以下指令:listen 443 ssl http2;
这些是关于Nginx中SSL的一些详细介绍。使用SSL可以提供安全的数据传输和身份验证,帮助保护您的应用程序和用户的隐私。请注意,以上只是一个概述,Nginx的
SSL配置选项和功能更加丰富,您可以根据具体需求进行进一步的配置和优化。
如何搞到证书
在阿里云里先要购买域名,然后根据域名区申请免费的证书。
证书是捆绑到域名上的 --》对域名进行担保
nginx中的部署
1.上传下载的证书到ngixn服务器的conf目录下
10488089_*.online_nginx.zip
2.unzip 10488089_*.online_nginx.zip解压
*.online.key 私钥
*.online.pem 公钥
3.修改配置文件启用nginx
server {
listen 443 ssl;
server_name **.online;
ssl_certificate **.pem;
ssl_certificate_key **.key;
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 5m;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
location / {
root html;
index index.html index.htm;
}
}
4.我们还需要配置hosts文件,防止将网站解析到公网上了。
5.我们也需要Linux中的hosts文件。
[root@localhost ~]# curl https://www.*.online
我们会访问到公网上的网站。
需要在/etc/hosts加路径
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.2.24 www.*.online
6.重启服务nginx -s reload
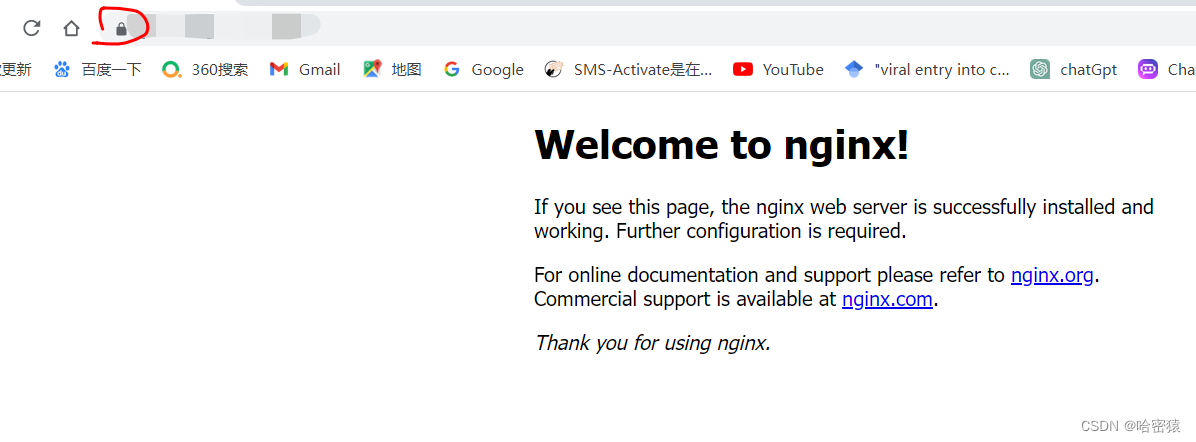
在输入网站的时候,出现小锁就代表成功了。
加密
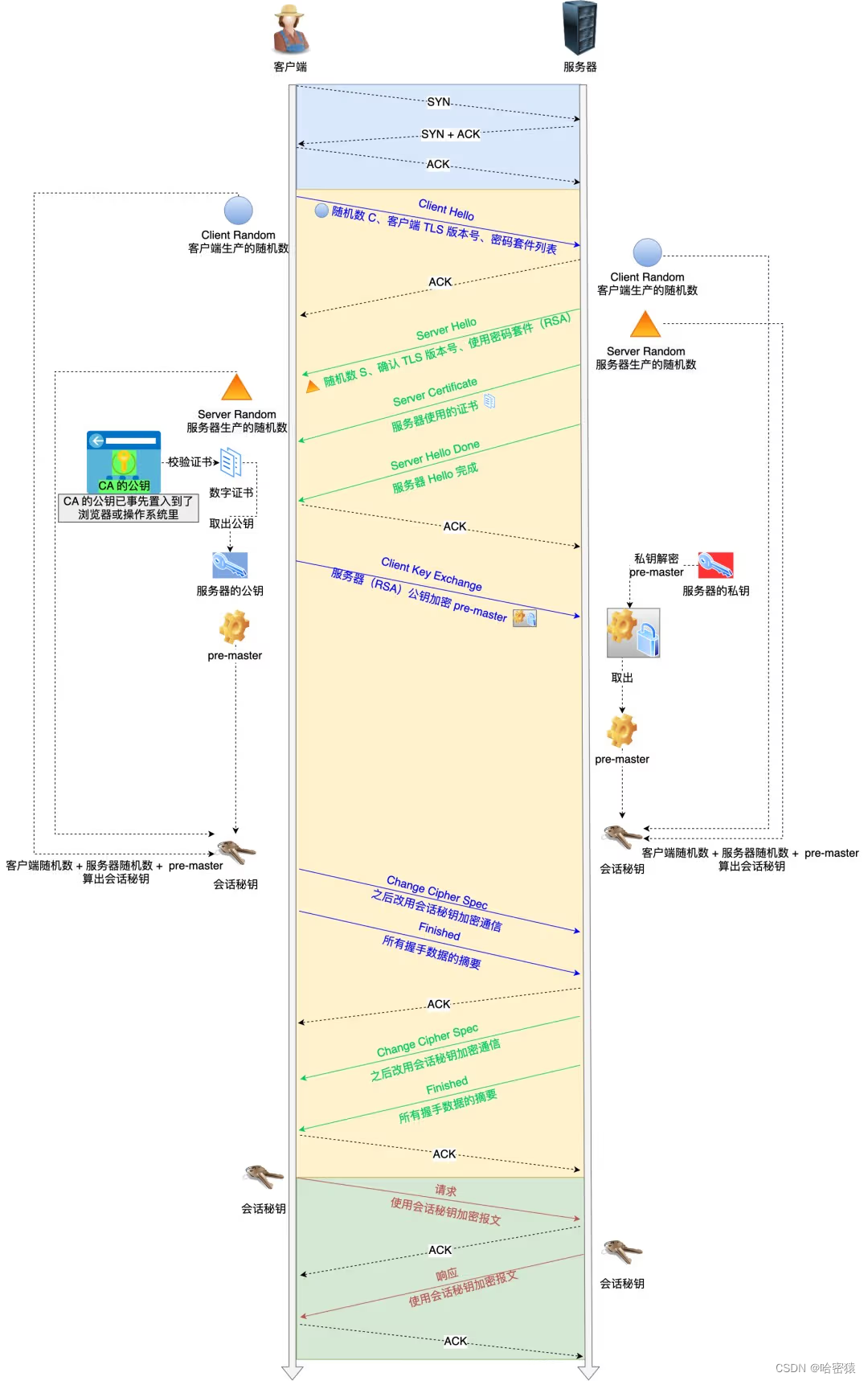
ssl的四次握手
CA
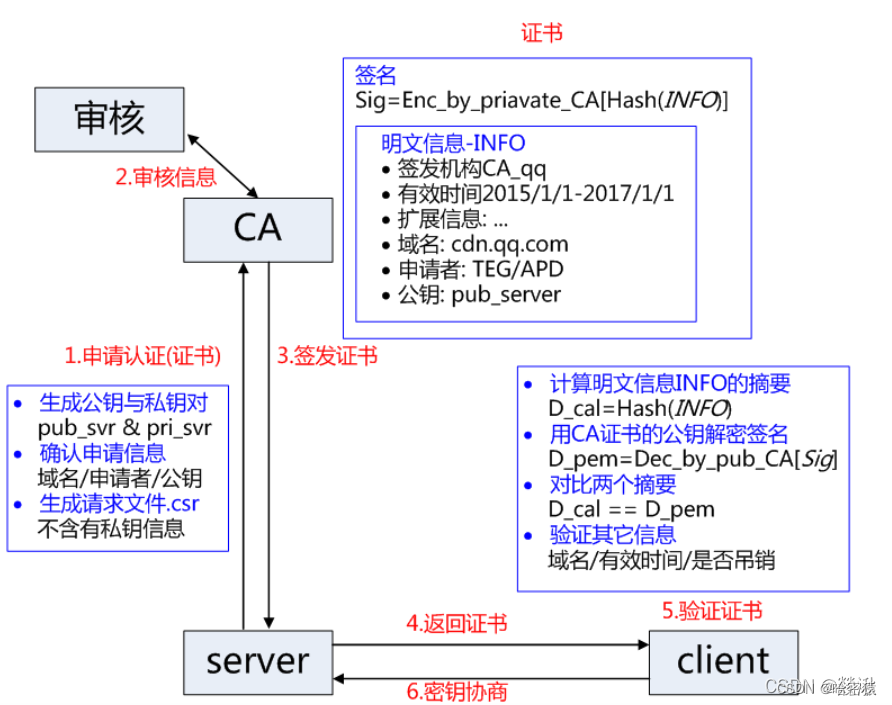
CA是数字证书认证机构(Certificate Authority)的缩写,是一种专门负责颁发和管理数字证书的第三方机构。以下是对CA的全面详细介绍:
-
定义:数字证书认证机构(CA)是一种受信任的第三方实体,负责验证和确认公钥与实体(例如个人、组织或网站)之间的关联关系,并使用数字签名来对这种关联进行认证。CA的主要任务是为各种实体颁发数字证书,并提供公钥基础设施(PKI)的相关服务。
-
功能:
- 验证身份:CA通过严格的身份验证程序,确认实体(如个人或组织)的身份和信息,以确保数字证书中的公钥与正确的实体相关联。
- 颁发数字证书:一旦身份验证成功,CA会生成一个数字证书,其中包含实体的公钥、身份信息和数字签名。证书是对实体身份和公钥的数字化确认。
- 数字签名:CA使用自己的私钥对生成的数字证书进行签名,这个数字签名是对证书的认证,用于验证证书的真实性和完整性。
- 证书撤销:CA负责管理和维护证书的有效性。如果证书的私钥被泄露、实体的信息发生变化或证书出现其他问题,CA可以将证书撤销,以保持数字证书的可信性。
- 证书存储和检索:CA通常维护一个证书数据库,用于存储颁发的数字证书,并提供检索和查询服务,以便用户可以验证证书的有效性和真实性。
-
信任体系:CA的权威性和可信度是基于信任体系建立的。操作系统、浏览器和其他应用程序内置了一组受信任的CA根证书,这些根证书的公钥用于验证由CA颁发的数字证书。这种信任体系确保了数字证书的可靠性和合法性。
-
应用领域:
- 安全通信:CA用于保证网络通信的安全性,例如在HTTPS中使用CA颁发的数字证书对网站进行身份验证和加密通信。
- 数字签名:CA用于验证数字签名的合法性,确保签名的身份和文件的完整性。
- 身份认证:CA用于验证用户身份,例如在电子商务和网上银行等应用中,通过颁发数字证书对用户进行身份认证。
-
CA的责任和安全性:作为数字证书的权威颁发机构,CA承担着重要的责任,包括保
护私钥的安全性、正确执行身份验证程序、及时撤销证书等。CA需要具备高度的安全性和可靠性,以确保数字证书系统的有效性和可信度。
总之,CA是数字证书认证的核心机构,负责验证和认证公钥与实体身份之间的关联,以建立安全的通信和身份认证机制。通过数字证书,用户可以验证实体的身份,确保通信的安全性和完整性。
数字证书
数字签名是一种用于确保数字信息完整性、认证身份和防止篡改的加密技术。它在信息安全领域中起着重要作用,特别是在数据传输和电子文档领域。下面是数字签名的详细介绍:
-
概述:
数字签名使用非对称加密算法,通过对信息进行加密和验证,确保信息的真实性和完整性。它结合了加密技术和公钥基础设施(PKI)来提供身份认证和数据完整性的保证。 -
工作原理:
(1)生成密钥对:首先,签名者生成一对密钥,包括私钥和公钥。私钥只有签名者自己知道,并且必须保密。公钥可以公开分享给其他人。
(2)签名过程:- 签名者使用私钥对要签名的数据进行加密(通常是通过对数据进行哈希运算生成摘要,然后对摘要进行加密)。
- 加密后的数据成为数字签名,附加在原始数据上。
(3)验证过程:- 接收者使用签名者的公钥解密数字签名,得到原始的哈希值。
- 接收者对接收到的原始数据进行相同的哈希运算,生成一个新的哈希值。
- 接收者将新的哈希值与解密得到的哈希值进行比较。如果两者一致,说明数据完整且未被篡改。
- 加密后的数据成为数字签名,附加在原始数据上。
- 签名者使用私钥对要签名的数据进行加密(通常是通过对数据进行哈希运算生成摘要,然后对摘要进行加密)。
-
作用和优势:
- 数据完整性:数字签名提供了一种验证数据是否被篡改的方法。如果数据在传输或存储过程中被修改,其签名验证将失败。
- 身份认证:数字签名使用私钥来生成签名,因此可以确保签名者的身份。接收者可以使用签名者的公钥来验证签名的真实性。
- 不可否认性:数字签名是由签名者生成的,他们不能否认对信息的签名行为,因为私钥只有签名者拥有。
- 保密性:数字签名不需要将私钥传输给其他人,只需要共享公钥。这样可以确保私钥的保密性,降低了密钥泄露的风险。
-
PKI(公钥基础设施):
PKI是数字签名的关键基础设施,用于管理和验证公钥的可信性。PKI由证书颁发机构(CA)负责,CA会颁发数字证书,包含公钥和相关身份信息,并对其进行签名。接收者可以使用CA的公钥验证证书的真实性,从
而信任其中的公钥。
- 应用领域:
- 电子商务:数字签名用于确保在线交易的安全性和完整性。
- 文件认证:数字签名可用于证明文件的来源和完整性,例如软件供应商的数字签名可以验证软件的真实性。
- 邮件安全:数字签名可以防止电子邮件被篡改,并提供发件人身份的认证。
- 身份验证:数字签名可以用于用户身份认证,例如通过数字签名登录系统。
总之,数字签名通过使用加密技术和非对称密钥对来提供数据完整性、身份认证和防止篡改的保证。它在许多领域中起着重要作用,确保信息安全和可靠性。
hash算法
在 Nginx 中,hash 模块是一种用于负载均衡的模块,它基于客户端 IP 地址或其他指定的变量进行哈希运算,并根据哈希值选择后端服务器进行请求转发。下面是对 Nginx hash 模块的详细介绍:
-
负载均衡原理:
负载均衡是将客户端的请求分发给多个后端服务器,以实现请求的平衡分配和增加系统的可靠性和性能。Nginx 提供了多种负载均衡算法,其中之一就是哈希算法。 -
Hash 算法:
Hash 算法是将输入数据通过哈希函数转换为固定长度的哈希值的过程。在 Nginx 中,hash 模块使用指定的变量(如客户端 IP 地址)作为输入,通过哈希运算生成一个哈希值。 -
哈希算法的作用:
哈希算法可以将不同的输入映射到固定范围的哈希值,从而实现请求的分发。对于相同的输入,哈希算法保证始终生成相同的哈希值,因此同一客户端的请求将始终被分发到相同的后端服务器上。 -
Nginx hash 模块的配置:
在 Nginx 的配置文件中,可以使用 hash 模块进行负载均衡的配置。例如:http { upstream backend { hash $remote_addr consistent; server backend1.example.com; server backend2.example.com; } server { listen 80; location / { proxy_pass http://backend; } } }上述配置中,使用
$remote_addr变量作为哈希的输入,consistent参数表示在添加或删除后端服务器时保持哈希的一致性。 -
哈希算法的优势和注意事项:
- 哈希算法能够将特定客户端的请求始终分发到相同的后端服务器,适用于需要维持会话的应用程序。
- 使用哈希算法进行负载均衡时,如果后端服务器的数量发生变化,部分请求可能会被分配到不同的后端服务器上,导致负载不均衡。
- 在使用哈希算法时,要注意选择适当的哈希变量,以确保均匀分配请求并避免哈希碰撞(多个输入映射到相同的哈希值)。
总之,Nginx 的 hash 模块提供了一种基于哈希算法的负载均衡机制,通过选择特定变量进行哈希运算,将客户端请求分发到后端服务器。这
种方式可以确保相同客户端的请求始终被转发到相同的后端服务器,适用于需要维持会话的应用场景。
对称加密
对称加密是一种加密算法,使用相同的密钥(也称为密钥或密码)进行加密和解密数据。它是加密领域中最常用的一种加密方法。下面是对称加密的详细介绍:
-
基本原理:
对称加密使用相同的密钥来加密和解密数据。发送方使用密钥将明文数据转换为加密数据,接收方使用相同的密钥将加密数据解密为原始明文数据。由于加密和解密使用相同的密钥,因此对称加密也被称为共享密钥加密。 -
密钥管理:
在对称加密中,密钥的管理非常重要。发送方和接收方必须在安全的方式下交换密钥,以确保只有授权的人可以访问加密数据。传统上,密钥可以通过安全的通道手动交换,但这种方法不够安全和可扩展。因此,通常使用密钥交换协议(如Diffie-Hellman密钥交换)来安全地生成和交换密钥。 -
加密算法:
对称加密使用不同的加密算法来执行加密和解密操作。一些常见的对称加密算法包括:- AES(Advanced Encryption Standard):目前最常用的对称加密算法之一,支持不同的密钥长度,包括128位、192位和256位。
- DES(Data Encryption Standard):是最早的对称加密算法之一,但因为密钥长度较短而不再推荐使用。
- 3DES(Triple DES):对DES进行了改进,使用多次DES算法执行加密,提高了安全性。
- Blowfish、RC4、RC5等:其他一些对称加密算法。
-
安全性和性能:
对称加密算法通常具有高加密和解密速度,并且在处理大量数据时表现出色。然而,对称加密的一个主要挑战是密钥管理和安全性。由于密钥需要在发送方和接收方之间共享,因此存在被中间人截取密钥的风险。此外,对称加密算法通常面临密钥分发和密钥轮换的挑战。 -
使用场景:
对称加密广泛应用于数据保护和信息安全领域,包括以下场景:- 保护敏感数据的存储和传输:对称加密可用于加密存储在本地计算机、服务器或数据库中的敏感数据,以及在网络上传输的数据。
- 安全通信:对称加密可用于保护网络通信中的数据传输,例如通过安全套接
层(SSL)或传输层安全(TLS)加密协议实现的加密通信。
- 文件和文件夹加密:对称加密可用于加密文件和文件夹,以保护其内容免受未经授权的访问。
总之,对称加密是一种使用相同密钥进行加密和解密的加密方法。它具有高性能和广泛应用的优点,但需要安全地管理密钥以确保数据的机密性和完整性。
非对称加密
非对称加密(Asymmetric Encryption)是一种加密算法,使用了一对密钥,包括公钥(Public Key)和私钥(Private Key)。与对称加密算法不同,非对称加密算法使用不同的密钥来进行加密和解密操作。
下面是非对称加密的详细介绍:
-
公钥和私钥:
非对称加密算法使用一对密钥,公钥和私钥。公钥是公开的,可以被任何人获取,用于加密数据。私钥是保密的,只有私钥的拥有者可以使用它进行解密操作。 -
加密过程:
在非对称加密中,发送者使用接收者的公钥来加密要发送的数据。发送者在使用公钥加密数据后,只有拥有相应私钥的接收者才能解密数据。这种方式确保了数据的机密性。 -
解密过程:
接收者使用其私钥来解密通过非对称加密算法加密的数据。私钥的保密性保证了只有接收者能够解密数据。 -
安全性:
非对称加密算法的安全性基于数学问题的难解性,如大素数的因式分解问题或离散对数问题。这些问题在当前计算能力下被认为是非常困难的。因此,即使公钥被泄露,私钥仍然能够保证数据的安全性。 -
数字签名:
非对称加密算法还可以用于生成和验证数字签名。发送者可以使用私钥对消息进行签名,接收者可以使用发送者的公钥来验证签名的有效性。这种方式可以确保数据的完整性和身份认证。 -
密钥交换:
非对称加密算法也可以用于密钥交换过程。在密钥交换中,双方可以使用对方的公钥来加密要传输的密钥,然后通过安全的通信渠道发送给对方。这样,双方可以通过使用自己的私钥解密对方的加密密钥,从而安全地交换密钥,用于后续的对称加密通信。 -
效率问题:
相比对称加密算法,非对称加密算法的计算复杂性较高,加密和解密操作耗时较长。因此,在实际应用中,通常使用非对称加密算法来解决密钥交换和数字签名等场景,而对实际数据的加密通常使用对称加密算法。
常见的非对称加密算法包括RSA(Rivest-Shamir-Adleman)、DSA(Digital Signature Algorithm)和ECC(Elliptic Curve Cryptography)等。
总结:
非对称加密算法通过使用一对密钥(公钥和私钥)来实现加密和解密操作,确保了数据的机密性、完整性和身份认证。它在密钥交换和数字签名等场景中发挥着重要作用,但由于计算复杂性较高,实际应用中通常与对称加密算法结合使用,以实现高效的加密通信。
数字签名
数字签名是一种用于确保数字信息完整性、认证身份和防止篡改的加密技术。它在信息安全领域中起着重要作用,特别是在数据传输和电子文档领域。下面是数字签名的详细介绍:
-
概述:
数字签名使用非对称加密算法,通过对信息进行加密和验证,确保信息的真实性和完整性。它结合了加密技术和公钥基础设施(PKI)来提供身份认证和数据完整性的保证。 -
工作原理:
(1)生成密钥对:首先,签名者生成一对密钥,包括私钥和公钥。私钥只有签名者自己知道,并且必须保密。公钥可以公开分享给其他人。
(2)签名过程:
- 签名者使用私钥对要签名的数据进行加密(通常是通过对数据进行哈希运算生成摘要,然后对摘要进行加密)。
- 加密后的数据成为数字签名,附加在原始数据上。
(3)验证过程:
- 接收者使用签名者的公钥解密数字签名,得到原始的哈希值。
- 接收者对接收到的原始数据进行相同的哈希运算,生成一个新的哈希值。
- 接收者将新的哈希值与解密得到的哈希值进行比较。如果两者一致,说明数据完整且未被篡改。 -
作用和优势:
- 数据完整性:数字签名提供了一种验证数据是否被篡改的方法。如果数据在传输或存储过程中被修改,其签名验证将失败。
- 身份认证:数字签名使用私钥来生成签名,因此可以确保签名者的身份。接收者可以使用签名者的公钥来验证签名的真实性。
- 不可否认性:数字签名是由签名者生成的,他们不能否认对信息的签名行为,因为私钥只有签名者拥有。
- 保密性:数字签名不需要将私钥传输给其他人,只需要共享公钥。这样可以确保私钥的保密性,降低了密钥泄露的风险。
-
PKI(公钥基础设施):
PKI是数字签名的关键基础设施,用于管理和验证公钥的可信性。PKI由证书颁发机构(CA)负责,CA会颁发数字证书,包含公钥和相关身份信息,并对其进行签名。接收者可以使用CA的公钥验证证书的真实性,从
而信任其中的公钥。
- 应用领域:
- 电子商务:数字签名用于确保在线交易的安全性和完整性。
- 文件认证:数字签名可用于证明文件的来源和完整性,例如软件供应商的数字签名可以验证软件的真实性。
- 邮件安全:数字签名可以防止电子邮件被篡改,并提供发件人身份的认证。
- 身份验证:数字签名可以用于用户身份认证,例如通过数字签名登录系统。
总之,数字签名通过使用加密技术和非对称密钥对来提供数据完整性、身份认证和防止篡改的保证。它在许多领域中起着重要作用,确保信息安全和可靠性。
webhook
Webhook是一种通过HTTP协议实现的回调机制,用于实现应用程序之间的实时数据传递和事件通知。通俗来讲,可以将Webhook看作是一个“电话号码”,当某个事件发生时,系统会拨打这个电话号码,将相关的信息传递给指定的接收方。
具体来说,Webhook的工作原理如下:
-
注册Webhook:首先,你需要在某个应用程序或服务中注册Webhook。这通常涉及提供一个URL,该URL由你提供,作为接收事件通知的终点。
-
事件发生:当注册的事件发生时,触发Webhook。例如,你可能在一个电子商务平台上注册了一个Webhook来接收订单创建事件。
-
发送HTTP请求:事件发生后,触发方会发送一个HTTP请求到你提供的URL,即Webhook的目标地址。这个HTTP请求中包含了事件相关的数据,如订单信息。
-
处理事件:一旦你的应用程序接收到Webhook的HTTP请求,你可以根据接收到的数据进行相应的处理。这可能包括处理订单、更新数据、发送通知等。
Webhook的优点是实时性和灵活性。相比轮询(通过定期发送请求来查询更新),Webhook是一种被动的方式,只有在事件发生时才会触发通知,节省了资源和网络带宽。同时,Webhook可以与各种应用程序和服务集成,使得数据传递和事件通知更加方便和可靠。
举个例子来说,假设你有一个博客网站,并希望在有新评论时收到通知。你可以通过设置一个评论事件的Webhook,将Webhook的目标地址设置为你自己的服务器或第三方服务。当有新评论时,博客平台会发送一个包含评论信息的HTTP请求到你提供的URL,你的服务器或第三方服务接收到请求后可以进行相应的处理,比如发送邮件通知你有新评论。这样你就能够实时了解到评论的情况,而无需手动去查询。
总的来说,Webhook提供了一种简单、高效的机制,用于实现实时数据传递和事件通知,使不同应用程序之间的集成更加方便和实用。
![[每周一更]-(第54期):Go的多版本管理工具](https://img-blog.csdnimg.cn/ccae2bda5b9a485c914dc490e03f9c8c.jpeg#pic_center)