1 可选实验室: Python、 NumPy 和矢量化
简要介绍本课程中使用的一些科学计算。特别是 NumPy 科学计算包及其与 python 的使用。
2 目标
在这个实验室里将回顾课程中使用的 NumPy 和 Python 的特性。
Python 是本课程中使用的编程语言。NumPy 库扩展了 python 的基本功能,添加了更丰富的数据集,包括更多的数值类型、向量、矩阵和许多矩阵函数。NumPy 和 python 相当无缝地协同工作。Python 算术运算符处理 NumPy 数据类型,许多 NumPy 函数将接受 Python 数据类型。
NumPy 的基本数据结构是一个可索引的 n 维数组,其中包含相同类型(dtype)的元素。这里维度指的是数组的索引数。一维数组有一个索引。在课程1中,我们将向量表示为 NumPy 一维数组。一维数组,shape(n,) : 从[0]到[ n-1]索引的 n 个元素。
NumPy 中的数据创建例程通常有一个第一个参数,它是对象的形状。这可以是一维结果的单个值,也可以是指定结果形状的元组(n,m,...)。下面是使用这些例程创建向量的示例。
import numpy as np # it is an unofficial standard to use np for numpy
import time
# NumPy routines which allocate memory and fill arrays with value
a = np.zeros(4); print(f"np.zeros(4) : a = {a}, a shape = {a.shape}, a data type = {a.dtype}")
a = np.zeros((4,)); print(f"np.zeros(4,) : a = {a}, a shape = {a.shape}, a data type = {a.dtype}")
a = np.random.random_sample(4); print(f"np.random.random_sample(4): a = {a}, a shape = {a.shape}, a data type = {a.dtype}")输出为:
np.zeros(4) : a = [0. 0. 0. 0.], a shape = (4,), a data type = float64 np.zeros(4,) : a = [0. 0. 0. 0.], a shape = (4,), a data type = float64 np.random.random_sample(4): a = [0.40589302 0.63171453 0.69259702 0.54159911], a shape = (4,), a data type = float64
有些数据创建例程不采用元组形式:
# NumPy routines which allocate memory and fill arrays with value but do not accept shape as input argument
a = np.arange(4.); print(f"np.arange(4.): a = {a}, a shape = {a.shape}, a data type = {a.dtype}")
a = np.random.rand(4); print(f"np.random.rand(4): a = {a}, a shape = {a.shape}, a data type = {a.dtype}")输出为:
np.arange(4.): a = [0. 1. 2. 3.], a shape = (4,), a data type = float64 np.random.rand(4): a = [0.54170759 0.00065357 0.46959253 0.09870197], a shape = (4,), a data type = float64
值也可以手动指定:
# NumPy routines which allocate memory and fill with user specified values
a = np.array([5,4,3,2]); print(f"np.array([5,4,3,2]): a = {a}, a shape = {a.shape}, a data type = {a.dtype}")
a = np.array([5.,4,3,2]); print(f"np.array([5.,4,3,2]): a = {a}, a shape = {a.shape}, a data type = {a.dtype}")输出为:
np.array([5,4,3,2]): a = [5 4 3 2], a shape = (4,), a data type = int32 np.array([5.,4,3,2]): a = [5. 4. 3. 2.], a shape = (4,), a data type = float64
这些都创建了一个有四个元素的一维向量 a。a.shape返回维度。在这里,我们看到a.shape= (4,)表示一个包含4个元素的一维数组。
3 向量操作
3.1 索引
向量的元素可以通过索引和切片来访问。NumPy 提供了一套非常完整的索引和切片功能。我们将在这里只探索课程所需的基础知识。有关更多详细信息,请参考切片和索引。
索引意味着通过数组中元素的位置来引用数组的元素。
切片意味着根据索引从数组中获取元素的子集。
NumPy 从零开始索引,因此向量 a 的第3个元素是一个[2]。
#vector indexing operations on 1-D vectors
a = np.arange(10)
print(a)
#access an element
print(f"a[2].shape: {a[2].shape} a[2] = {a[2]}, Accessing an element returns a scalar")
# access the last element, negative indexes count from the end
print(f"a[-1] = {a[-1]}")
#indexs must be within the range of the vector or they will produce and error
try:
c = a[10]
except Exception as e:
print("The error message you'll see is:")
print(e)输出:
[0 1 2 3 4 5 6 7 8 9] a[2].shape: () a[2] = 2, Accessing an element returns a scalar a[-1] = 9 The error message you'll see is: index 10 is out of bounds for axis 0 with size 10
3.2 切片
切片使用一组三个值(start: stop: step)创建索引数组。值的子集也是有效的。它的用法可以用一个例子来解释:
#vector slicing operations
a = np.arange(10)
print(f"a = {a}")
#access 5 consecutive elements (start:stop:step)
c = a[2:7:1]; print("a[2:7:1] = ", c)
# access 3 elements separated by two
c = a[2:7:2]; print("a[2:7:2] = ", c)
# access all elements index 3 and above
c = a[3:]; print("a[3:] = ", c)
# access all elements below index 3
c = a[:3]; print("a[:3] = ", c)
# access all elements
c = a[:]; print("a[:] = ", c)输出:
a = [0 1 2 3 4 5 6 7 8 9] a[2:7:1] = [2 3 4 5 6] a[2:7:2] = [2 4 6] a[3:] = [3 4 5 6 7 8 9] a[:3] = [0 1 2] a[:] = [0 1 2 3 4 5 6 7 8 9]
3.3 单向量运算
有许多有用的运算涉及对单个向量的运算。
a = np.array([1,2,3,4])
print(f"a : {a}")
# negate elements of a
b = -a
print(f"b = -a : {b}")
# sum all elements of a, returns a scalar
b = np.sum(a)
print(f"b = np.sum(a) : {b}")
b = np.mean(a)
print(f"b = np.mean(a): {b}")
b = a**2
print(f"b = a**2 : {b}")输出:
a : [1 2 3 4] b = -a : [-1 -2 -3 -4] b = np.sum(a) : 10 b = np.mean(a): 2.5 b = a**2 : [ 1 4 9 16]
3.4 向量与向量元素运算
大多数 NumPy 算法、逻辑和比较操作也适用于向量。这些操作符基于元素逐个元素地工作。
a = np.array([ 1, 2, 3, 4])
b = np.array([-1,-2, 3, 4])
print(f"Binary operators work element wise: {a + b}")输出:
Binary operators work element wise: [0 0 6 8]
当然,为了使其正确工作,向量必须具有相同的大小:
#try a mismatched vector operation
c = np.array([1, 2])
try:
d = a + c
except Exception as e:
print("The error message you'll see is:")
print(e)输出:
The error message you'll see is: operands could not be broadcast together with shapes (4,) (2,)
3.5 标量向量运算
向量可以通过标量值“缩放”。标量值只是一个数字。标量乘以向量的所有元素。
a = np.array([1, 2, 3, 4])
# multiply a by a scalar
b = 5 * a
print(f"b = 5 * a : {b}")输出:
b = 5 * a : [ 5 10 15 20]
3.6 矢量向量点积
点积是线性代数和 NumPy 的支柱。这是一个在本课程中广泛使用的操作。点乘将两个向量中的值按元素方式相乘,然后对结果求和。向量点积要求两个向量的尺寸相同。注意,点乘应该返回一个标量值。
def my_dot(a, b):
"""
Compute the dot product of two vectors
Args:
a (ndarray (n,)): input vector
b (ndarray (n,)): input vector with same dimension as a
Returns:
x (scalar):
"""
x=0
for i in range(a.shape[0]):
x = x + a[i] * b[i]
return x
# test 1-D
a = np.array([1, 2, 3, 4])
b = np.array([-1, 4, 3, 2])
print(f"my_dot(a, b) = {my_dot(a, b)}")输出为:
my_dot(a, b) = 24
# test 1-D
a = np.array([1, 2, 3, 4])
b = np.array([-1, 4, 3, 2])
c = np.dot(a, b)
print(f"NumPy 1-D np.dot(a, b) = {c}, np.dot(a, b).shape = {c.shape} ")
c = np.dot(b, a)
print(f"NumPy 1-D np.dot(b, a) = {c}, np.dot(a, b).shape = {c.shape} ")输出为:
NumPy 1-D np.dot(a, b) = 24, np.dot(a, b).shape = () NumPy 1-D np.dot(b, a) = 24, np.dot(a, b).shape = ()
3.7 速度的需要: 矢量与循环
使用NumPy库是因为它提高了速度和内存效率。
np.random.seed(1)
a = np.random.rand(10000000) # very large arrays
b = np.random.rand(10000000)
tic = time.time() # capture start time
c = np.dot(a, b)
toc = time.time() # capture end time
print(f"np.dot(a, b) = {c:.4f}")
print(f"Vectorized version duration: {1000*(toc-tic):.4f} ms ")
tic = time.time() # capture start time
c = my_dot(a,b)
toc = time.time() # capture end time
print(f"my_dot(a, b) = {c:.4f}")
print(f"loop version duration: {1000*(toc-tic):.4f} ms ")
del(a);del(b) #remove these big arrays from memory输出:
np.dot(a, b) = 2501072.5817 Vectorized version duration: 46.8779 ms my_dot(a, b) = 2501072.5817 loop version duration: 4033.1399 ms
因此,矢量化在本例中提供了很大的速度提升。这是因为NumPy更好地利用了底层硬件中可用的数据并行性。GPU和现代CPU实现单指令多数据(SIMD)管道,允许并行发布多个操作。这在机器学习中至关重要,因为机器学习中的数据集通常非常大。
4 矩阵
矩阵,是二维数组。矩阵的元素都是相同的类型。在记谱法中,矩阵用大写字母表示,黑体字母如 X。在这个实验室和其他实验室中,m 通常是行数和列数。矩阵的元素可以用二维索引引用。在数学设置中,索引中的数字通常从1到 n。在计算机科学和这些实验室中,索引将从0运行到 n-1。通用矩阵表示法,第一个索引是行,第二个是列。
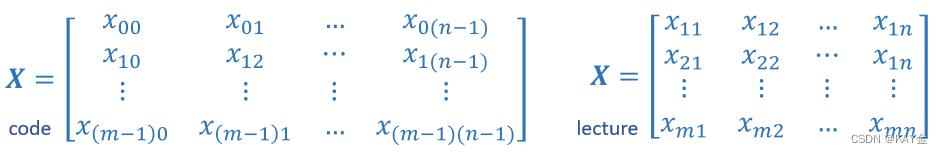
NumPy 的基本数据结构是一个可索引的 n 维数组,其中包含相同类型(dtype)的元素。这些是之前描述过的。矩阵有一个二维(2-D)索引[ m,n ]。下面你将回顾:
- 数据创建
- 切片和索引
4.1 矩阵创建
创建二维向量的函数和创建一维向量的函数一样。注意 NumPy 是如何使用方括号来表示每个维度的。更进一步的是,在打印时,每行将打印一行。
a = np.zeros((1, 5))
print(f"a shape = {a.shape}, a = {a}")
a = np.zeros((2, 1))
print(f"a shape = {a.shape}, a = {a}")
a = np.random.random_sample((1, 1))
print(f"a shape = {a.shape}, a = {a}") 输出:
a shape = (1, 5), a = [[0. 0. 0. 0. 0.]] a shape = (2, 1), a = [[0.] [0.]] a shape = (1, 1), a = [[0.44236513]]
也可以手动指定数据。尺寸是用额外的括号指定的,与上面打印的格式相匹配。
# NumPy routines which allocate memory and fill with user specified values
a = np.array([[5], [4], [3]]); print(f" a shape = {a.shape}, np.array: a = {a}")
a = np.array([[5], # One can also
[4], # separate values
[3]]); #into separate rows
print(f" a shape = {a.shape}, np.array: a = {a}")输出:
a shape = (3, 1), np.array: a = [[5] [4] [3]] a shape = (3, 1), np.array: a = [[5] [4] [3]]
4.2 矩阵操作
4.2.1 索引
矩阵索引描述[ row,column ]。可以返回元素或行/列。见下文:
#vector indexing operations on matrices
a = np.arange(6).reshape(-1, 2) #reshape is a convenient way to create matrices
print(f"a.shape: {a.shape}, \na= {a}")
#access an element
print(f"\na[2,0].shape: {a[2, 0].shape}, a[2,0] = {a[2, 0]}, type(a[2,0]) = {type(a[2, 0])} Accessing an element returns a scalar\n")
#access a row
print(f"a[2].shape: {a[2].shape}, a[2] = {a[2]}, type(a[2]) = {type(a[2])}")输出:
a.shape: (3, 2), a= [[0 1] [2 3] [4 5]] a[2,0].shape: (), a[2,0] = 4, type(a[2,0]) = <class 'numpy.int32'> Accessing an element returns a scalar a[2].shape: (2,), a[2] = [4 5], type(a[2]) = <class 'numpy.ndarray'>
最后一个例子值得注意。通过指定行来访问矩阵将返回一个一维向量。
Reshape:使用重塑形状来设置数组的形状。
A = np.arange (6).reshape(- 1,2)
这行代码首先创建了一个包含6个元素的1-D Vector。然后,它使用重塑命令将该向量重塑为一个二维数组。可以这样写:
A = np.arange (6).reshape(3,2)
到达相同的3行,2列数组。-1参数告诉例程计算给定数组大小和列数的行数。
4.2.2 切片
切片使用一组三个值(start:stop:step)创建一个索引数组。
#vector 2-D slicing operations
a = np.arange(20).reshape(-1, 10)
print(f"a = \n{a}")
#access 5 consecutive elements (start:stop:step)
print("a[0, 2:7:1] = ", a[0, 2:7:1], ", a[0, 2:7:1].shape =", a[0, 2:7:1].shape, "a 1-D array")
#access 5 consecutive elements (start:stop:step) in two rows
print("a[:, 2:7:1] = \n", a[:, 2:7:1], ", a[:, 2:7:1].shape =", a[:, 2:7:1].shape, "a 2-D array")
# access all elements
print("a[:,:] = \n", a[:,:], ", a[:,:].shape =", a[:,:].shape)
# access all elements in one row (very common usage)
print("a[1,:] = ", a[1,:], ", a[1,:].shape =", a[1,:].shape, "a 1-D array")
# same as
print("a[1] = ", a[1], ", a[1].shape =", a[1].shape, "a 1-D array")
输出:
a = [[ 0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19]] a[0, 2:7:1] = [2 3 4 5 6] , a[0, 2:7:1].shape = (5,) a 1-D array a[:, 2:7:1] = [[ 2 3 4 5 6] [12 13 14 15 16]] , a[:, 2:7:1].shape = (2, 5) a 2-D array a[:,:] = [[ 0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19]] , a[:,:].shape = (2, 10) a[1,:] = [10 11 12 13 14 15 16 17 18 19] , a[1,:].shape = (10,) a 1-D array a[1] = [10 11 12 13 14 15 16 17 18 19] , a[1].shape = (10,) a 1-D array
在这个实验室中,我们掌握了 Python 和 NumPy 的特性,这些特性是课程所需要的。