系列文章目录
第一章 初识python
第二章 变量
第三章 基础语句
第四章 字符串str
第五章 列表list []
第六章 元组tuple ( )
第七章 字典dict {}
第八章 集合set {}
第九章 常用操作
第十章 函数
第十一章 文件操作
第十二章 面向对象
第十三章 异常
文章目录
- 系列文章目录
- 14.1 什么是模块?
- 14.2 导入模块
- 方法1:import 模块名
- 方法2:from 模块名 import 功能名
- 方法3:from 模块名 import *
- 方法4:import 模块名 as 别名
- 方法5:from 模块名 import 功能名 as 别名
- 14.3 制作模块
- 定义模块
- 测试和调用模块
- 模块定位顺序
- 名字重复的严重性
- 14.4 all列表
- 14.5 包
- 制作包
- 导入包
- 方法一
- 方法二
14.1 什么是模块?
Python 模块(Module),是一个 Python 文件,以.py 结尾,包含了 Python 对象定义和Python语句。模块能定义函数,类和变量,模块里也能包含可执行的代码。
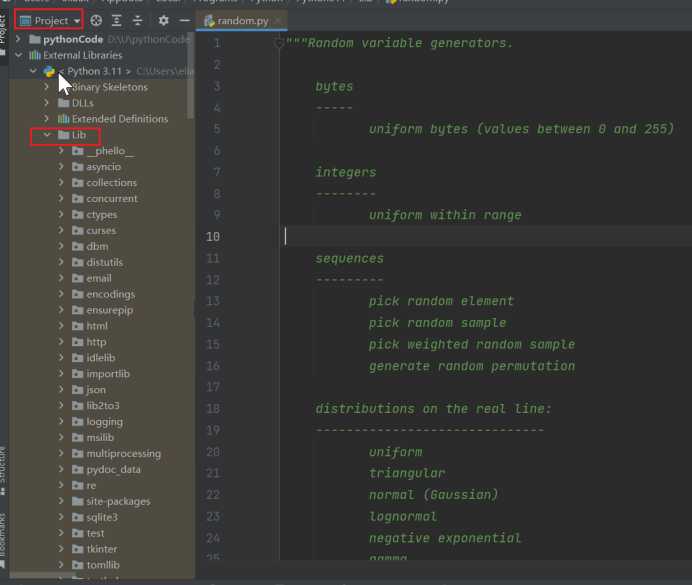
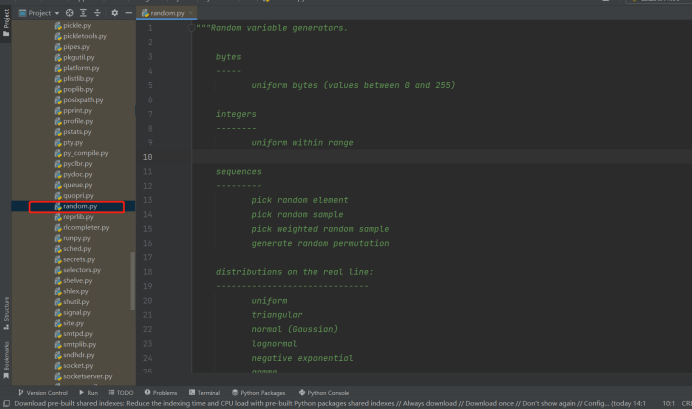
lib文件夹里面,往下滚动,大量充斥着.py的文件,这些文件就是python中的模块,例如我们生成随机数导入的random模块,import random导入的就是random.py这个文件,所谓的random模块其实就是一个文件名为random的py文件,python的模块就是一个python文件而已。
打开random文件看看里面的代码:
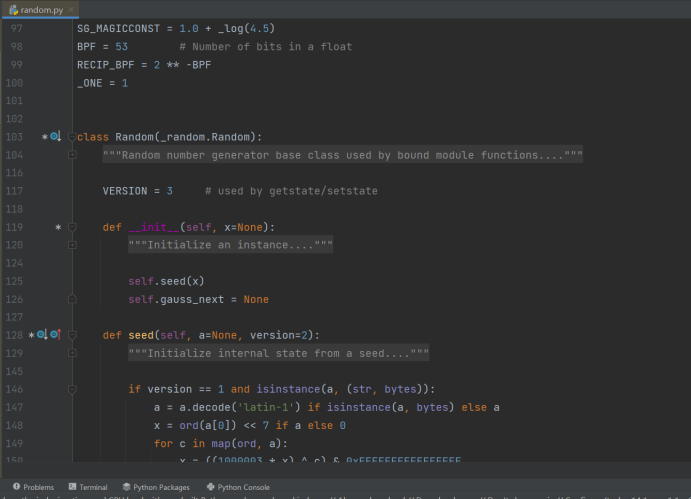
我们导入random模块之后,其实是在使用py文件里面的代码而已。
14.2 导入模块
导入模块的方式
方法1:import 模块名
- 导入模块
import 模块名- import 模块名1,模块名2… 不推荐这种写法
- 调用功能
模块名.功能名()
import math
print(math.sqrt(4)) # sqrt开根号 2.0
方法2:from 模块名 import 功能名
- 导入模块
from 模块名 import 功能1,功能2,功能3...
- 调用功能
功能名()- 注意:不用书写模块名.功能
from math import sqrt
print(sqrt(4))
方法3:from 模块名 import *
from math import *
print(sqrt(4))
as定义别名
方法4:import 模块名 as 别名
模块定义别名,如果进行了别名的定义,将来使用的时候只能使用定义的别名,而不能再次使用模块名。
import time as tt
tt.sleep(3)
print("I wander in your yard, looking forward to meeting you.")
方法5:from 模块名 import 功能名 as 别名
功能定义别名
from time import sleep as sl
sl(3)
print("I wander in your yard, looking forward to meeting you.")
14.3 制作模块
在Python中,每个Python文件都可以作为一个模块,模块的名字就是文件的名字。也就是说自定义模块名必须要符合标识符命名规则。
定义模块
新建一个Python文件,命名为 my_module.py,并定义 testA 函数
def textA(a, b):
return a + b
测试和调用模块
在实际开中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果,这个开发人员会自行在py文件中添加一些测试信息.,例如,在 my_module.py 文件中添加测试代码。
def textA(a, b):
return a + b
print(textA(1, 2))
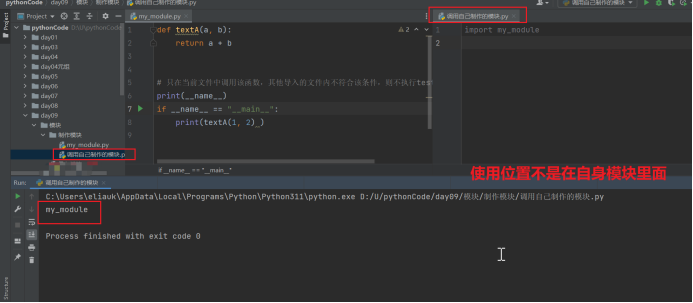
import my_module 导入模块中的所有代码,此时,无论是当前文件,还是其他已经导入了该模块的文件,在运行的时候都会自动执行 testA 函数的调用。

解决办法:
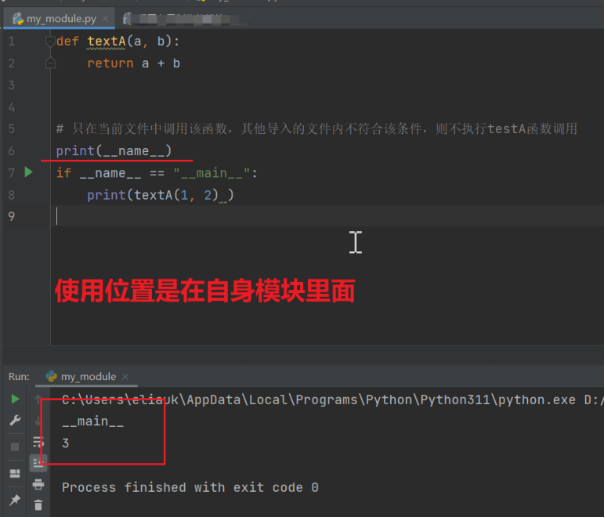
每个模块就是一个python文件,python文件一定会有自己的名字,__name__是一个系统变量,是模块的标识符,也就是说是每个python文件的标识符。如果__name__的使用位置是在自身模块里面,那么它的值就是”__main__”,否则使用位置不是在自身模块里面,那么这个__name__的值就是模块的名字(python文件名)
def textA(a, b):
return a + b
# 只在当前文件中调用该函数,其他导入的文件内不符合该条件,则不执行testA函数调用
print(__name__)
if __name__ == "__main__":
print(textA(1, 2) )
模块定位顺序
当导入一个模块,Python解析器对模块位置的搜索顺序是:由近及远
1.当前目录
2.如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录
3.如果都找不到,Python会查看默认路径。UNIX下,默认路径一般为/usr/local/lib/python/
模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录。
注意:
- 自己的文件名不要和已有模块名重复,否则导致模块功能无法使用。
- 使用
from 模块名 import功能 的时候,如果功能名字重复,调用到的是最后定义或导入的功能。
场景1:模块名重复
# 自己的文件名不要和已有模块名重复,否则导致模块功能无法使用 random
import random
print(random.randint(1, 5)) # 1-5的随机数字
在当前目录新建一个random.py,里面什么都不写,运行会报错

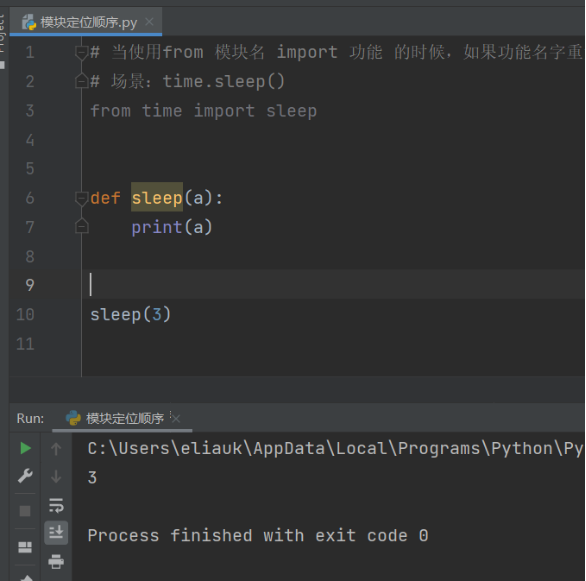
场景2:定义一个同名函数在导入sleep功能的下面,调用的是后面的sleep
# 当使用from 模块名 import 功能 的时候,如果功能名字重复,调用到的是最后定义或导入的功能。
# 场景:time.sleep()
from time import sleep
def sleep(a):
print(a)
sleep(3)
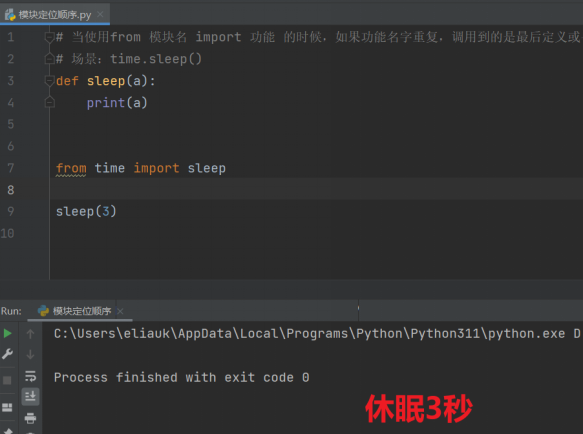
场景二:定义一个同名函数在导入sleep功能的上面,调用的是后面的sleep
名字重复的严重性
问题:import 模块名是否担心 功能名字重复的问题?
答案:不需要,因为调用的时候是 模块名.功能名()
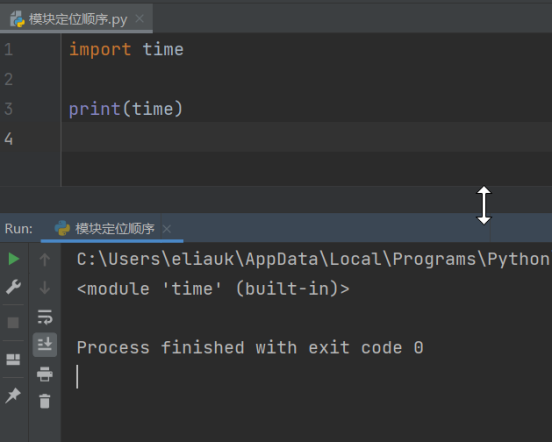
打印出来的是<module ‘time’ (built-in)>,内置模块time
import time
print(time) # <module 'time' (built-in)>
time = 1
print(time) # 1
问:为什么变量也能覆盖模块功能?
答:在python语言中,数据是通过 引用 传递的。
14.4 all列表
如果一个模块文件中有__all__变量,当使用from xxx import *导入时,只能导入这个列表中的元素。
- my_model模块代码
__all__ = ["testA"]
def testA():
print("textA")
def testB():
print("textB")
- 导入模块的文件代码

模块函数很多,只用一小部分的话,用__al__可以减少内存开支
14.5 包
包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为__init__.py 文件,那么这个文件夹就称之为包。
制作包
[New] -> [Python Package] -> 输入包名 ->[OK] -> 新建功能模块(有联系的模块)。
注意: 新建包后,包内部会自动创建 init.py 文件,这个文件控制着包的导入行为。
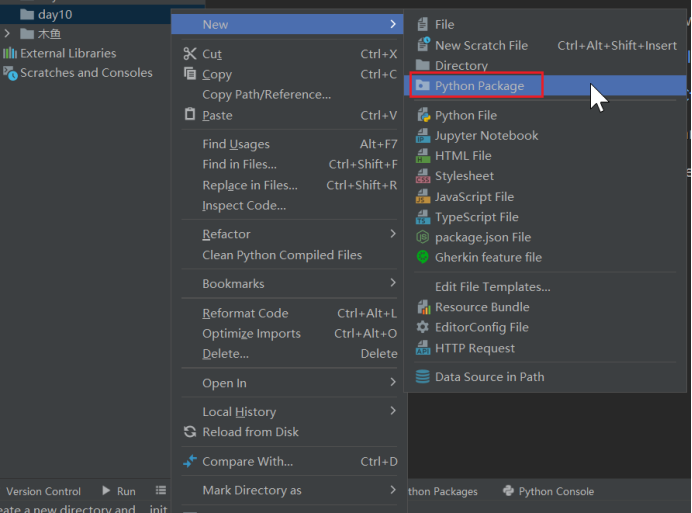
1.新建包myfirstpackage
2.新建包内模块mymodel1和mymodel2
3.mymodel1模块代码
print("mymodel1")
def print_info01():
print("mymodel1---print_info01")
4.mymodel2模块代码
print("mymodel2")
def print_info02():
print("mymodel2---print_info02")
导入包
方法一
import 包名.模块名
包名.模块名.目标功能()
import myfirstpackage.mymodel1
myfirstpackage.mymodel1.print_info01()

方法二
from 包名 import *
模块名.目标功能()
注意: 必须在__init__.py 文件中添加__all__= [],控制允许导入的模块列表