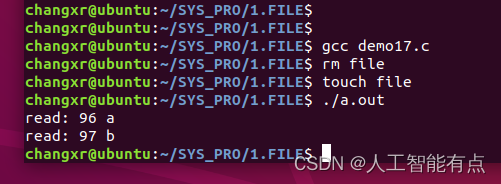
quote方法: 将字符转换为对应Unicode编码
import urllib.request
import urllib.parse
# 获取 https://www.baidu.com/s?wd=周杰伦 网页源码
url = "https://www.baidu.com/s?wd="
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.200.400 QQBrowser/11.8.5310.400',
}
# 将周杰伦三个字变成Unicode编码
# 使用urllib.parse().quote()
name = urllib.parse.quote('周杰伦')
url = url + name
# 请求对象定制
request = urllib.request.Request(url, headers=headers)
# 模拟浏览器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
content = response.read().decode('utf-8')
print(content)
但是还是爬取不到百度网页

这是百度的反爬虫机制所导致的。察觉到你是爬虫而不是人为下载,所以需要在请求头里多加几个参数
'Cookie':'', #cookie你先自己登录百度帐号就有了
'Accept':'',
'Accept-Encoding':'',
然后就好了(我这里只加了Cookie)

urlencode方法: 可以将数据从字典中提取并转换成unicode编码格式,并用&符号自动连接
import urllib.request
import urllib.parse
# urlencode应用场景:多个参数的时候
# 获取https://www.baidu.com/s?wd=周杰伦&sex=男&location=中国台湾 网页源码
base_url = 'https://www.baidu.com/s?'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.200.400 QQBrowser/11.8.5310.400',
'Cookie': ''
}
data = {
'wd': '周杰伦',
'sex': '男',
'location': '中国台湾'
}
new_data = urllib.parse.urlencode(data)
# 拼接url
url = base_url + new_data
# 请求对象定制
request = urllib.request.Request(url, headers=headers)
# 模拟浏览器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码数据
content = response.read().decode('utf-8')
print(content)