本篇博客介绍了正则表达式与在python中的应用(re模块),及一些在开发中常见的模式示例。参考书籍《python核心编程(第三版)》
学不会的python之正则表达式
正则表达式(模式) 简介 正则应用 搜索与匹配
特殊符号与字符 择一匹配 匹配单个字符
起始、结尾、单词边界匹配
字符集
使用闭包操作符实现存在性和频数匹配
表示字符集的特殊字符 使用圆括号指定分组 扩展表示法 Python正则应用 re模块:核心函数和方法
compile()函数编译正则表达式
匹配对象以及 group()和 groups()方法 使用 match()方法匹配字符串 使用 search()在一个字符串中查找模式(搜索与匹配的对比) 使用 findall()和 finditer()查找每一次出现的位置 使用 sub()和 subn()搜索与替换 在限定模式上使用 split()分隔字符串 扩展符号 杂项
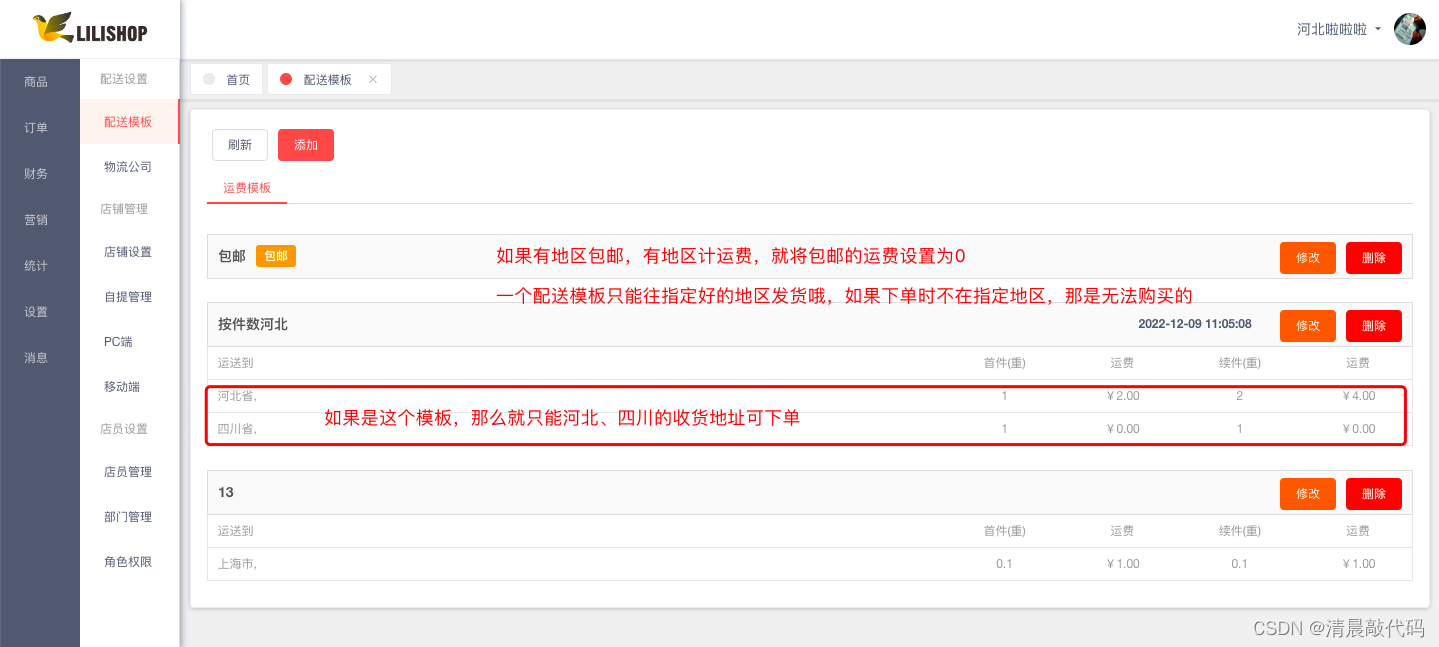
对于当前我们时下最流行的B端与C端的应用来说,做的最多的事就是对文本或者数据进行操作,包含(CURD)但不限于。因为我们不知道需要处理的文本或数据的具体内容,所以需要将那些包含各式各样的数据以某个固定的模式处理成有效数据 简单举例就是:当前你的邮箱有很多不同人发送的邮件,而你只需要一个或者几个客户发送的邮件并转发给你的同事,你需要使用程序来处理。由此我们引申出一个问题就是:如何通过编程使得计算机程序拥有在文本及数据中检索某种模式的能力 正则表达式 就为高级的文本模式匹配、抽取、与/或文本形式的搜索和替换 功能提供了基础。简单地说,正则表达式(简称为 regex)就是一些由字符和特殊符号组成的字串,它们有着固定的语法,描述了模式的重复或者表述多个字符,于是正则表达式能按照某种模式匹配一系列有相似特征的字符串在Python术语中,主要有两种方法完成模式匹配:“搜索”(searching),即在字符串任意部分中搜索匹配的模式 ;而“匹配”(matching)是指判断一个字符串能否从起始处全部或者部分地匹配某个模式 。搜索通过 search()函数或方法来实现,而匹配通过调用 match()函数或方法实现 我们常说的模式(pattern)就是实际的正则表达式;模式匹配就是正则表达式匹配 对于同一需要匹配的文本数据来说:可能会有多种正则模式可以完成匹配 。有的是易于通读理解的,而有的是匹配效率高,只有对、错的情况在正则是很少出现的 在不同的环境,可以对同一匹配文本使用不同的正则表达式进行匹配 我们先简单介绍一些在正则表达式中具有特殊意义的符号与字符,就是所谓的元字符(有特定意义) ,我们在某一模式中遇见此类字符,如果未使用转义字符(\)进行转义,那么它代表的就是下表中的特殊意义 特殊符号 描述 示例 符号 abc 匹配文本字符串的字面值:abc abc re1 re2 匹配模式re1 re2 abc | def ^ (脱字符)匹配字符串起始部分 ^Dear $ (美元符)匹配字符串终止部分 /bin/bash$ . 匹配任意字符(除\n除外) Lo.e * 匹配 0 次或者多次前面出现的正则表达式(贪婪匹配) [A-Za-z0-9]* + 匹配 1 次或者多次前面出现的正则表达式(贪婪匹配) [a-z]+.com ? 匹配 0 次或者 1 次前面出现的正则表达式(懒惰匹配) goo? {N} 匹配 N 次前面出现的正则表达式,N为具体数值 [a-z]{5} {M,N} 匹配 M~N 次前面出现的正则表达式,M、N为具体数值 [0-9]{5,9}(包含5次与9次) […] 匹配来自字符集的任意单一字符 [aeiou] […a −d …] 匹配 a~d 范围中的任意单一字符 [0-9], [A-Za-z] [^…] 不匹配在此字符集中出现的任何一个字符,包括某一范围的字符(如果在此字符集中出现) [^aeiou], [^A-Za-z0-9] (*|+|?|{})? 用于匹配上面频繁出现/重复出现符号的非贪婪版本(*、+、?、{}) .*?[a-z] (…) 匹配封闭的正则表达式,然后另存为子组 ([0-9]{3})?,f(oo|u)bar 特殊字符 \d 匹配任何十进制数字,与[0-9]一致(\D 与\d 相反,不匹配任何非数值型的数字) data\d+.txt \w 匹配任何字母数字字符,与[A-Za-z0-9_]相同(\W 与之相反) [A-Za-z_]\w+ \s 匹配任何空格字符,与[\n\t\r\v\f]相同(\S 与之相反) of\sthe \b 匹配任何单词边界(\B 与之相反) \bThe\b \N 匹配已保存的子组 N(参见上面的(…)) N为数字 price: \16 \c 逐字匹配任何特殊字符 c(即,仅按照字面意义匹配,不匹配特殊含义) \., \\, \* \A(\Z) 匹配字符串的起始(结束)(另见上面介绍的^和$) \ADear 扩展表示法 (?iLmsux) 在正则表达式中嵌入一个或者多个特殊“标记”参数(或者通过函数/方法) (?x),(? im) (?:…) 表示一个匹配不用保存的分组 (?:\w+.)* (P?<name>…) 像一个仅由 name 标识而不是数字 ID 标识的正则分组匹配 (?P) (?P=name) 在同一字符串中匹配由(?P<name)分组的之前文本 (?P=data) (?#…) 表示注释,所有内容都被忽略 (?#comment) (?=…) 匹配条件是如果…出现在之后的位置,而不使用输入字符串;称作正向前视断言 (?=.com) (?!…) 匹配条件是如果…不出现在之后的位置,而不使用输入字符串;称作负向前视断言 (?!.net) (?<=…) 匹配条件是如果…出现在之前的位置,而不使用输入字符串;称作正向后视断言 (?<=800-) (?<!…) 匹配条件是如果…不出现在之前的位置,而不使用输入字符串;称作负向后视断言 (?<!192.168.) (?(id/name)Y|N) 如果分组所提供的 id 或者 name(名称)存在,就返回正则表达式的条件匹配 Y,如果不存在,就返回 N;|N 是可选项 (?(1)y|x)
上述表格这些特殊字符,会在下面内容中有更加详细的介绍 表示择一匹配的管道符号(|),也就是键盘上的竖线(位于键盘Enter键上面),表示一个“从多个模式中选择其一”的操作。它用于分割不同的正则表达式,如下表: 正则表达式模式 匹配字符串 apple | banana apple、banana bin| bash | shell bin、bash、shell
左边是一些运用择一匹配的模式,右边是左边相应的模式所能够匹配的字符 点号或者句点(.)符号匹配除了换行符\n 以外的任何字符(Python 正则表达式有一个编译标记[S 或者 DOTALL] ,该标记能够推翻这个限制,使点号能够匹配换行符,下面介绍在python中的应用) 无论字母、数字、空格(并不包括“\n”换行符)、可打印字符、不可打印字符,还是一个符号 ,使用点号都能够匹配它们,如下表: 正则表达式模式 匹配字符串 a.f 匹配在字母“a”和“f”之间的任意一个字符;例如abf、azf、apf、a#f等 … 匹配任意两个字符;aa、c#、CC
问题:那我们怎样才能匹配到 . 字符呢? 答:显式的匹配点字符,而不是把它当作特殊字符处理,使用反斜线(转义字符)即可,如 \. 要匹配字符串的开始位置,就必须使用脱字符(^)或者特殊字符\A(反斜线和大写字母 A) ,后者主要用于那些没有脱字符的键盘(例如,某些国际键盘)。同样,美元符号($)或者\Z 将用于匹配字符串的末尾位置 使用上述符号的模式指定了匹配的位置或方位 正则表达式模式 匹配字符串 ^un 任何以un开头的字符串 /bin/ba$ 任何以/bin/ba结尾的字符串
再次说明:
如果想要逐字匹配这些字符中的任何一个(或者全部),就必须使用反斜线 进行转义。例如,如果你想要匹配任何以美元符号结尾的字符串 ,一个可行的正则表达式方案*$$ 。 特殊字符\b 和\B 可以用来匹配字符边界 。而两者的区别在于:
\b 将用于匹配一个单词的边界,这意味着如果一个模式必须位于单词的起始部分,就不管该单词前面(单词位于字符串中间)是否有任何字符(单词位于行首) \B 将匹配出现在一个单词中间的模式(即,不是单词边界) 正则表达式模式 匹配字符串 the 任何包含 the 的字符串 \bthe 任何以 the 开始的字符串 \bthe\b 仅仅匹配单词 the \Bthe 任何包含但并不以 the 作为起始的字符串
字符集正则表达式能够匹配一对方括号中包含的任何字符 正则表达式模式 匹配字符串 b[aeiu]t bat、bet、bit、but [cr][23][dp][o2] 一个包含四个字符的字符串,第一个字符是“c”或“r”,然后是“2”或“3”,后面是“d”或“p”,最后要么是“o”要么是“2”。例如,c2do、r3p2、r2d2、c3po 等
关于[cr][23][dp][o2]这个正则表达式有一点需要说明:
如果仅允许“r2d2”或者“c3po”作为有效字符串,就需要更严格限定的正则表达式。因为方括号仅仅表示逻辑或的功能,所以使用方括号并不能实现这一限定要求。唯一的方案就是使用择一匹配,例如,r2d2|c3po 然而,对于单个字符的正则表达式,使用择一匹配和字符集是等效的 。例如,我们以正则表达式“ab”作为开始,该正则表达式只匹配包含字母“a”且后面跟着字母“b”的字符串 如果我们想要匹配一个字母的字符串,例如,要么匹配“a”,要么匹配“b”,就可以使用正则表达式[ab],因为此时字母“a”和字母“b”是相互独立的字符串。我们也可以选择正则表达式 a|b 如果我们想要匹配满足模式“ab”后面且跟着“cd”的字符串,我们就不能使用方括号,因为字符集的方法只适用于单字符的情况。这种情况下,唯一的方法就是使用 ab|cd,这与刚才提到的 r2d2/c3po 问题是相同的 除了单字符以外,字符集还支持匹配指定的字符范围。方括号中两个符号中间用连字符(-)连接,用于指定一个字符的范围;例如,A-Z、a-z 或者 0-9 分别用于表示大写字母、小写字母和数值数字。这是一个按照字母顺序的范围,所以不能将它们仅仅限定用于字母十进制数字上 否定:如果脱字符(^)紧跟在左方括号后面,这个符号就表示不匹配给定字符集中的任何一个字符 正则表达式模式 匹配字符串 z.[0-9] 字母“z”后面跟着任何一个字符,然后跟着一个数字(0到9) [r-u][env-y][us] 字母r、s、t或者u后面跟着e、n、v、w、x或者y,然后跟着u或者s [^aeiou] 不匹配制表符或者\n [^\t\n] 任何包含但并不以 the 作为起始的字符串 [“-a] 在一个 ASCII 系统中,所有字符都位于“”和“a”之间,即 34~97 之间
在上述的特殊字符中*、+就是贪婪匹配,表示尽可能多的去匹配字符。简单来说就是:正则表达式将试图“吸收”匹配该模式的尽可能多的字符,一个字就是多(贪婪) ?就是懒惰匹配:正则表达式中尽可能少地匹配字符,留下尽可能多的字符给 正则表达式模式 匹配字符串 [dn]ot? 字母d或者n,后面跟着一个o,然后是最多一个t,例如:do、no、dot、not 0?[1-9] 任何数值数字,它可能前置一个0,例如,匹配一系列数(表示从 1~9 月的数值),不管是一个还是两个数字,01、1、02、2等都能标识1~9的月份 [0-9]{15,16} 匹配 15 或者 16 个数字(例如银行卡号码) </?[^>]+> 匹配全部有效的(和无效的)HTML 标签
有一些特殊字符也能标识某个特定字符集,如:使用“0-9”这个范围表示十进制数相比,可以简单地使用 d 表示匹配任何十进制数字。另一个特殊字符(\w)能够用于表示全部字母数字的字符集,相当于[A-Za-z0-9_]的缩写形式,\s 可以用来表示空格字符。这些特殊字符大写版本表示不匹配;例如,\D 表示任何非十进制数(与[^0-9]相同) 正则表达式模式 匹配字符串 \w+-\d+ 一个由字母数字组成的字符串和一串由一个连字符分隔的数字 [A-Za-z]\w* 第一个字符是字母;其余字符(如果存在)可以是字母或者数字 \w+@\w+.com 以 XXX@YYY.com 格式表示的简单电子邮件地址
在很多时候,我们想要知道能否提取任何已经成功匹配的特定字符串或者子字符串 。答案是可以,要实现这个目标,只需要用一对圆括号包裹任何正则表达式 当使用正则表达式时,一对圆括号可以实现以下任意一个(或者两个)功能:
使用圆括号进行分组还有一个作用就是,匹配模式的子字符串可以保存起来供后续使用。这些子组能够被同一次的匹配或者搜索重复调用,或者提取出来用于后续处理 为什么一定要用匹配子组呢?主要原因是在很多时候除了进行匹配操作以外,我们还想如果决定匹配模式\w+-\d+,但是想要分别保存第一部分的字母和第二部分的数字,该如何实现?我们可能想要这样做的原因是,对于任何成功的匹配,我们可能想要看到这些匹配正则表达式模式的字符串究竟是什么 如果为两个子模式都加上圆括号,例如(\w+)-(\d+),然后就能够分别访问每一个匹配子组 正则表达式模式 匹配字符串 \d+(.\d*)? 表示简单浮点数的字符串;也就是说,任何十进制数字,后面可以接一个小数点和零个或者多个十进制数字,例如“0.004”、“2”、“75.”等 (Mr?s?.)?[A-Z][a-z]*[A-Za-z-]+ 名字和姓氏,以及对名字的限制(如果有,首字母必须大写,后续字母小写),全名前可以有可选的“Mr.”、“Mrs.”、“Ms.”或者“M.”作为称谓,以及灵活可选的姓氏,可以有多个单词、横线以及大写字母
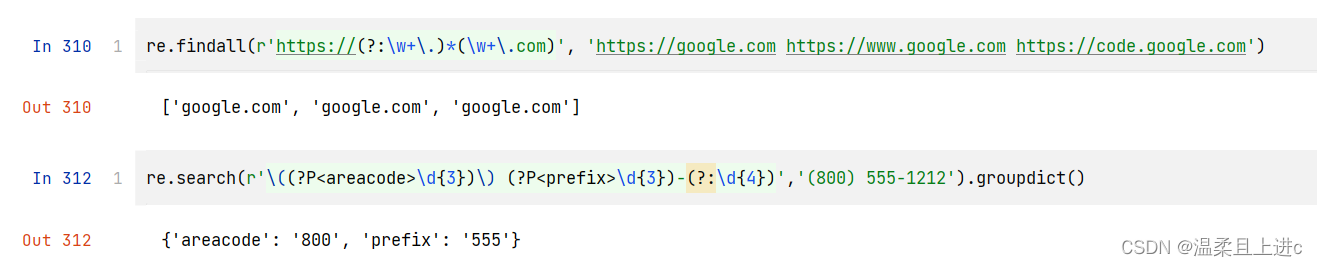
它们是以问号开始(?…),因为它们通常用于在判断匹配前提供标记,实现一个前视(或者后视)匹配,或者条件检查。尽管圆括号使用这些符号,是只有(?P<name>)表述一个分组匹配。所有其他的都没有创建一个分组。但是你仍然需要知道它们是什么,因为它们可能最适合用于你所需要完成的任务 正则表达式模式 匹配字符串 (?:\w+\.)* 以句点作为结尾的字符串,例如“google.”、“baidu.”,但是这些匹配不会保存下来供后续的使用和数据检索 (?#comment) 此处并不做匹配,只是作为注释 (?=.com) 如果一个字符串后面跟着“.com”才做匹配操作,并不使用任何目标字符串 (?!.net) 如果一个字符串后面不是跟着“.net”才做匹配操作 (?<=800-) 如果字符串之前为“800-”才做匹配,假定为电话号码,同样,并不使用任何输入字符串 (?<!192.168.) 如果一个字符串之前不是“192.168.”才做匹配操作,假定用于过滤掉一组 C 类 IP 地址 (?(1)y|x) 如果一个匹配组 1(\1)存在,就与 y 匹配;否则,就与 x 匹配
python中的re 模块支持更强大而且更通用的 Perl 风格(Perl 5 风格)的正则表达式,该模块允许多个线程共享同一个已编译的正则表达式对象,也支持命名子组 函数/方法 描述 仅仅是re模块函数: compile(pattern,flags) 使用任何可选的标记来编译正则表达式的模式,然后返回一个正则表达式对象 re 模块函数和正则表达式对象的方法: match(pattern,string,flags=0) 尝试使用带有可选的标记的正则表达式的模式来匹配字符串。如果匹配成功,就返回匹配对象;如果失败,就返回 None search(pattern,string,flags=0) 使用可选标记搜索字符串中第一次出现的正则表达式模式。如果匹配成功,则返回匹配对象;如果失败,则返回 None findall(pattern,string [, flags] ) 查找字符串中所有(非重复)出现的正则表达式模式,并返回一个匹配列表 finditer(pattern,string [, flags] ) 与 findall()函数相同,但返回的不是一个列表,而是一个迭代器。对于每一次匹配,迭代器都返回一个匹配对象 split(pattern,string,max=0) 根据正则表达式的模式分隔符,split 函数将字符串分割为列表,然后返回成功匹配的列表,分隔最多操作 max 次(默认分割所有匹配成功的位置) re 模块函数和正则表达式对象方法: sub(pattern,repl,string,count=0) 使用 repl 替换所有正则表达式的模式在字符串中出现的位置,除非定义 count,否则就将替换所有出现的位置(另见 subn()函数,该函数返回替换操作的数目) purge() 清除隐式编译的正则表达式模式 常用的匹配对象方法: group(num=0) 返回整个匹配对象,或者编号为 num 的特定子组 groups(default=None) 返回一个包含所有匹配子组的元组(如果没有成功匹配,则返回一个空元组) groupdict(default=None) 返回一个包含所有匹配的命名子组的字典,所有的子组名称作为字典的键(如果没有成功匹配,则返回一个空字典) 常用的模块属性(用于大多数正则表达式函数的标记): re.I、re.IGNORECASE 不区分大小写的匹配 re.L、re.LOCALE 根据所使用的本地语言环境通过\w、\W、\b、\B、\s、\S 实现匹配 re.M、re.MULTILINE ^和$分别匹配目标字符串中行的起始和结尾,而不是严格匹配整个字符串本身的起始和结尾 re.S、rer.DOTALL “.”(点号)通常匹配除了\n(换行符)之外的所有单个字符;该标记表示“.”(点号)能够匹配全部字符 re.X、re.VERBOSE 通过反斜线转义,否则所有空格加上#(以及在该行中所有后续文字)都被忽略,除非在一个字符类中或者允许注释并且提高可读性
在模式匹配发生之前,正则表达式模式必须编译成正则表达式对象。由于正则表达式在执行过程中将进行多次比较操作,因此强烈建议使用预编译 。而且,既然正则表达式的编译是必需的,那么使用预编译来提升执行性能无疑是明智之举。re.compile()能够提供此功能 其实模块函数会对已编译的对象进行缓存 ,所以不是所有使用相同正则表达式模式的 search()和 match()都需要编译 。即使这样,你也节省了缓存查询时间,并且不必对于相同的字符串反复进行函数调用。purge()函数能够用于清除这些缓存 尽管推荐预编译,但它并不是必需的。如果需要编译,就使用编译过的方法;如果不需要编译,就使用函数 有意思的是,不管使用函数还是方法 ,它们的名字都是相同的(也许你也曾对此感到好奇,这就是模块函数和方法的名字相同的原因,例如,search()、match()等)因为这在大多数示例中省去一个小步骤,所以我们将使用字符串替代 对于一些特别的正则表达式编译,可选的标记可能以参数的形式给出 ,这些标记允许不 这些标记也可以作为参数适用于大多数 re 模块函数。如果想要在方法中使用这些标记,它们必须已经集成到已编译的正则表达式对象之中,或者需要使用直接嵌入到正则表达式本身的(?F)标记,其中 F 是一个或者多个i(用于 re.I/IGNORECASE)、m(用于re.M/MULTILINE)、s(用于 re.S/DOTALL)等。如果想要同时使用多个,就把它们放在一起而不是使用按位或操作,例如,(?im)可以用于同时表示 re.IGNORECASE 和 re.MULTILINE 当处理正则表达式时,除了正则表达式对象之外,还有另一个对象类型:匹配对象。这些是成功调用 match()或者 search()返回的对象。匹配对象有两个主要的方法:group()和groups()
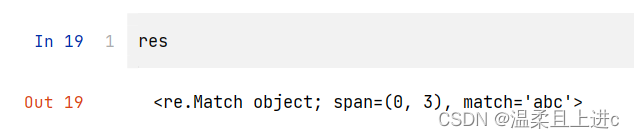
group()要么返回整个匹配对象,要么根据要求返回特定子组。 groups()则仅返回一个包含唯一或者全部子组的元组。如果没有子组的要求,那么当group()仍然返回整个匹配时,groups()返回一个空元组 match()函数试图从字符串的起始部分 对模式进行匹配。如果匹配成功,就返回一个匹配对象;如果匹配失败,就返回 None,匹配对象的 group()方法能够用于显示那个成功的匹配 举例如下:
import re
res = re. match ( 'abc' , 'abc' )
if res :
print ( res. group( ) )
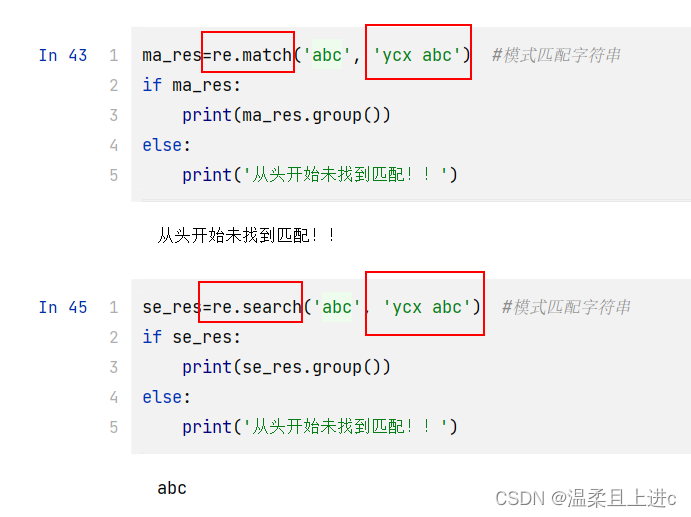
模式“abc”完全匹配字符串“abc”,能够确定 res 是匹配对象的示例 注意 :如果匹配失败,将会抛出 AttributeError 异常search()的工作方式与 match()完全一致,不同之处在于 search()会用它的字符串参数,在任意位置对给定正则表达式模式搜索第一次出现的匹配情况 。如果搜索到成功的匹配,就会返回一个匹配对象;否则,返回 None search()函数不但会搜索模式在字符串中第一次出现的位置,而且严格地对字符串从左到右搜索 match()和 search()都可以使用介绍的可选的标记参数。最后,需要注意的是,等价的正则表达式对象方法使用可选的 pos 和 endpos 参数来指定目标字符串的搜索范围 findall()查询字符串中某个正则表达式模式全部的非重复出现情况。这与 search()在执行字符串搜索时类似,但与 findall()和 search()的不同之处在于,findall()总是返回一个列表。如果 findall()没有找到匹配的部分,就返回一个空列表,但如果匹配成功,列表将包含所有成功的匹配部分(从左向右按出现顺序排列) 子组在一个更复杂的返回列表中搜索结果,而且这样做是有意义的,因为子组是允许从单个正则表达式中抽取特定模式的一种机制 ,例如匹配一个完整电话号码中的一部分(例如区号),或者完整电子邮件地址的一部分(例如登录名称) 对于一个成功的匹配,每个子组匹配是由 findall()返回的结果列表中的单一元素;对于多个成功的匹配,每个子组匹配是返回的一个元组中的单一元素,而且每个元组(每个元组都对应一个成功的匹配)是结果列表中的元素 finditer()在匹配对象中迭代: 注意,使用 finditer()函数完成的所有额外工作都旨在获取它的输出来匹配 findall()的输出 与 match()和 search()类似,findall()和 finditer()方法的版本支持可选的 pos 和 endpos参数,这两个参数用于控制目标字符串的搜索边界 有两个函数/方法用于实现搜索和替换功能:sub()和 subn()
两者几乎一样,都是将某字符串中所有匹配正则表达式的部分进行某种形式的替换。用来替换的部分通常是一个字符串,但它也可能是一个函数,该函数返回一个用来替换的字符串。subn()和 sub()一样,但subn()还返回一个表示替换的总数 ,替换后的字符串和表示替换总数的数字一起作为一个拥有两个元素的元组返回
使用匹配对象的 group()方法除了能够取出匹配分组编号外,还可以使用\N,其中 N 是在替换字符串中使用的分组编号。下面的代码仅仅只是将美式的日期表示法MM/DD/YY{,YY}格式转换为中国常用的格式 YY/MM/DD{,YY} 参考之前文章:python常用操作之使用多个界定符(分隔符)分割字符串
此篇文章也是博主写的,详解了字符串的split()方法与re模块的split()的使用 通过使用 (?iLmsux) 系列选项,用户可以直接在正则表达式里面指定一个或者多个标 (?:…)符号将更流行;通过使用该符号,可以对部分正则表达式进行分组,但是并不会保存该分组用于后续的检索或者应用。当不想保存今后永远不会使用的多余匹配时,这个符号就非常有用 可能会对于正则表达式的特殊字符和特殊 ASCII 符号之间的差异感到迷惑。我们可以使用\n 表示一个换行符,但是我们可以使用\d 在正则表达式中表示匹配单个数字 如果有符号同时用于 ASCII 和正则表达式,就会发生问题,因此在下面的核心提示中,建议使用 Python 的原始字符串来避免产生问题。另一个警告是:\w 和\W 字母数字字符同时受 re.L/LOCALE 和 Unicode(re.U/UNICODE)标记所影响 原始字符串: r’ 正则表达式 ’