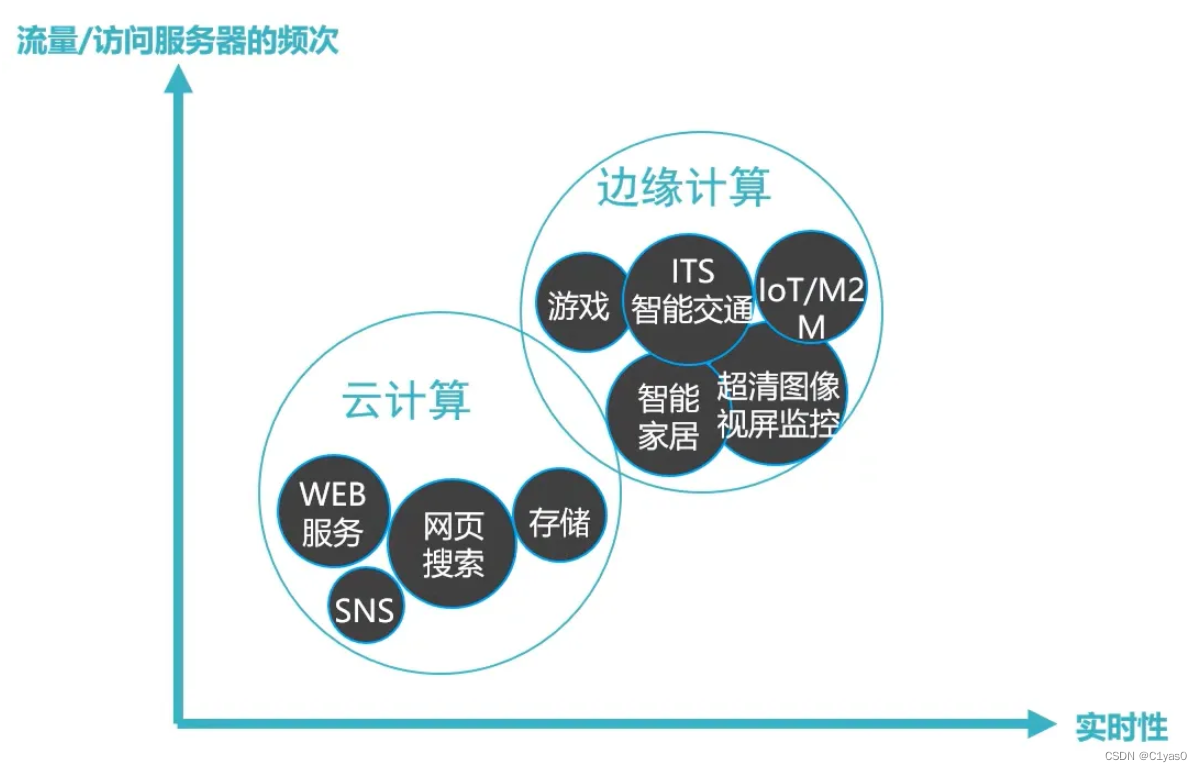
摘要
Many video enhancement algorithms rely on optical flow to register frames in a video sequence. Precise flow estimation is however intractable; and optical flow itself is often a sub-optimal representation for particular video processing tasks. In this paper, we propose task-oriented flow (TOFlow), a motion representation learned in a self-supervised, task-specific manner. We design a neural network with a trainable motion estimation component and a video processing component, and train them jointly to learn the task-oriented flow. For evaluation, we build Vimeo-90K, a large-scale, high-quality video dataset for low-level video processing. TOFlow outperforms traditional optical flow on standard benchmarks as well as our Vimeo-90K dataset in three video processing tasks: frame interpolation, video denoising/deblocking, and video super-resolution.
许多
video enhancement算法通过光流对齐帧,但是精确的光流估计很难,且光流通常是对特定处理视频的一种次级表示,在本文提出一种新的task-oriented flow,这是一种自我监督、特定于具体任务的方式学习的运动表示。本文训练一种神经网络,可以训练运动估计和视频处理两部分组件,通过两者联合训练实现TOFlow,
同时,构造了数据集Vimeo90K,用于低级视频处理的大规模、高质量的视频数据集
TOFlow在其数据集上的性能,在这些传统视频处理任务(帧插值、去噪、去块和超分辨)中要好于光流处理。
介绍
Motion estimation is a key component in video processing tasks,大部分运动估计分为两步:1.估计帧之间运动2.配准,因此 the accuracy of flow estimation很重要。然而,精确的流量估计很难,这是因为许多估计算法依赖于亮度恒定的假设,可能由于存在光照或者姿势的变化、运动模糊和遮挡等而失败。因此making it inefficient for real-time applications
此外,求得的运动场,对于视频处理效果可能不是最好的。

如图,上图显示的是帧插值的例子, EpicFlow是目前最先的方法,但是计算的运动场1b,其中边界与图像中的手指良好,但其插值的帧1C(插入的帧C)由于遮挡,存在明显的伪影。这是因为 EpicFlow对于插值,无法修复被遮挡的区域,然而图d和e是本文的结果,学习效果很好。相比下图是显示去噪的例子, EpicFlow只能估计女孩头发的运动,但是本文的方法却可以去除输入的噪声,因此效果要更好,去噪要更干净。
In this paper, we propose to learn this task-oriented flow (TOFlow) representation with an end-to-end trainable convolutional network that performs motion analysis and video processing simultaneously. Our network consists of three modules: 详见第四节
本文说明了联合学习的好处,联合训练可以学习特定于某个任务的特征,从而实现更好的视频处理。例如,在视频去噪中,我们的 TOFlow 学习减少输入中的噪声,而传统的光流将噪声像素保留在注册帧中。 TOFlow 还减少了遮挡边界附近的伪影。我们在本文中的目标是建立一个标准框架,以便更好地理解面向任务的流程何时以及如何工作。
本文建造了一个数据集Vimeo90K
Vimeo-90K consists of 89,800 high-quality video clips (i.e. 720p or higher) downloaded from Vimeo. We build three benchmarks from these videos for interpola tion, denoising or deblocking, and super-resolution, respectively. We hope these benchmarks will also help improve learning-based video processing techniques with their high-quality videos and diverse examples.
相关工作
We refer readers to survey articles (Nasrollahi and Moeslund 2014; Ghoniem et al 2010) for comprehensive literature reviews on these flourishing research topics.
推荐阅读该文章掌握视频处理的研究方向主题
目前,运动信息可以被整合到网络中并联合训练。此类方法已应用于去噪 (Wen et al 2017)等中
尽管这些算法中的许多算法还与网络的其余部分联合训练了流估计,但没有系统研究联合训练的优势。在本文中,我们通过玩具示例说明了经过训练的面向任务的流程的优势,并展示了其在各种现实世界任务中优于一般流程算法的优势。我们还提出了一个通用框架,可以轻松适应不同的视频处理任务。
任务
本文方法面向的三个视频增强的任务:帧插值frame interpolation,去噪去块video denoising/deblocking and 视频超分辨率video super-resolution、
帧插值:给定低帧率视频,时间帧插值算法通过在两个时间相邻帧之间合成额外帧来生成高帧率视频。具体来说,让 I1 和 I3 是输入视频中的两个连续帧,任务是估计丢失的中间帧 I2。时间帧插值使视频帧速率加倍,并且可以递归应用以生成更高的帧速率
去噪:视频去噪/去块化旨在消除噪声或压缩伪影以恢复原始视频。这通常是通过聚合来自相邻帧的信息来完成的。
超分辨率:类似于视频去噪,给定N个连续的低分辨率帧作为输入,视频超分辨率的任务是恢复高分辨率的中间帧。在这项工作中,我们首先使用双三次插值将所有输入帧上采样到与输出相同的分辨率,我们的算法只需要恢复输出图像中的高频分量。
流程
Task-Oriented Flow for Video Processing
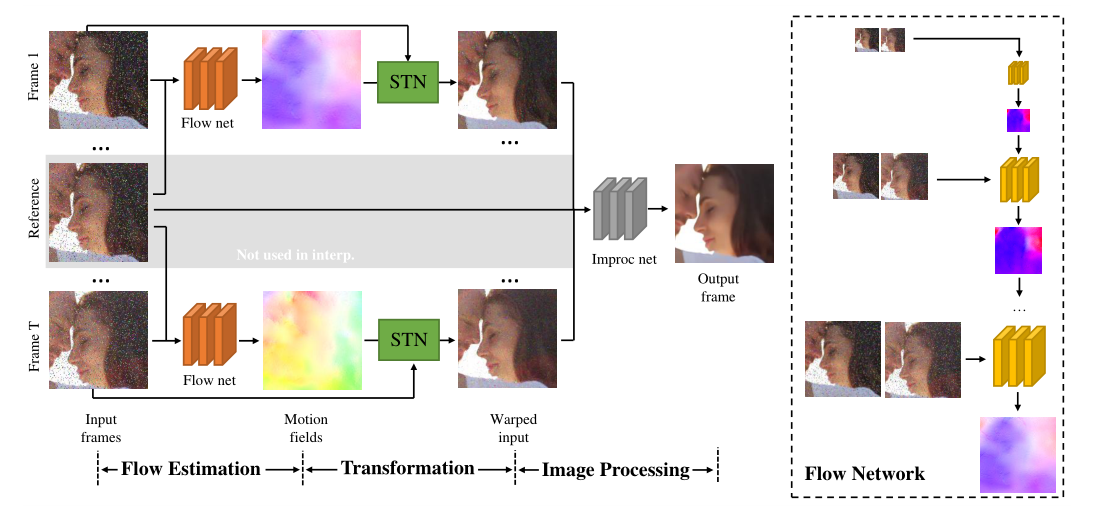
a flow estimation module that estimates the movement of pixels between input frames;
an image transformation module that warps all the frames to a reference frame;
a task-specific image processing module that performs video interpolation, denoising, or super-resolution on registered frames
因为流估计模块与网络的其余部分联合训练,它学习预测适合特定任务的流场。
玩具示例
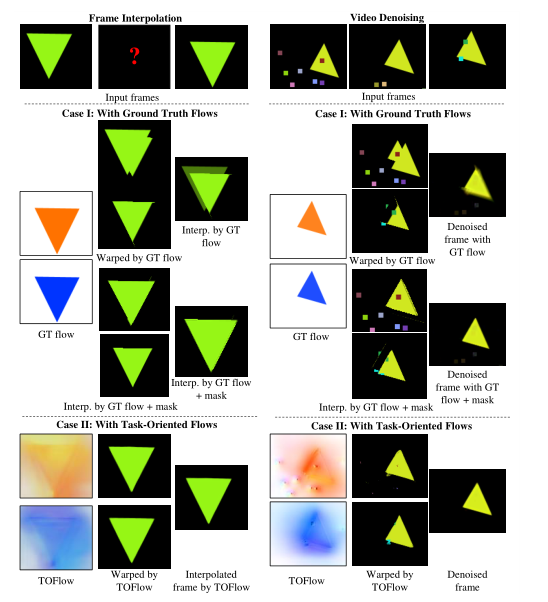
在讨论网络结构的细节之前,我们首先从两个合成序列开始,来演示为什么我们的 TOFlow 可以优于传统的光流。
图 3 的左侧显示了一个帧插值示例,其中一个绿色三角形移动到黑色背景前的底部。如果我们将第一帧和第三帧都扭曲到第二帧,即使使用GT流(案例 I,左列),由于遮挡(案例 I,中间列,前两个行),这是光流文献中的一个众所周知的问题(Baker et al 2011)。基于这两个扭曲帧的最终插值结果仍然包含倍增伪影(案例 I,右列,顶行)。相比之下,TOFlow 不坚持对象运动:背景应该是静态的,但它具有非零运动(案例 II,左列)。然而,使用 TOFlow,扭曲帧中几乎没有任何伪影(案例 II,中间列),并且插值帧看起来很干净(案例 II,右列)
这是因**为 TOFlow 不仅合成了可见对象的运动,还指导如何通过从其邻域复制像素来修复被遮挡的背景区域。**此外,如果地面实况遮挡掩码可用,则使用地面实况流的插值结果也将包含很少的加倍伪影(案例 I,底部行)。然而,计算地面遮挡掩码比估计流量更难,因为它还需要推断正确的深度顺序。另一方面,TOFlow 可以比地面实况流更好地处理遮挡和合成帧,而无需使用地面实况遮挡掩码和深度排序信息。
同样,在图 3 的右侧,我们展示了一个视频去噪的示例。输入帧中的随机小框是合成噪声。如果我们使用地面实况流将第一帧和第三帧扭曲到第二帧,噪声模式(随机正方形)仍然存在,而去噪帧仍然包含一些噪声(案例 I,右列。底部)。但是如果我们使用 TOFlow(案例 II,左列)扭曲这两个帧,那些噪声模式也会被减少或消除(案例 II,中间列),并且基于它们的最终去噪帧几乎不含噪声,甚至比通过使用ground truth flow和occlusion mask对结果进行去噪(案例I,底部行)。这也表明 TOFlow 通过用相邻像素修复输入帧来学习减少输入帧中的噪声,这是传统流无法做到的。
光流估计模块
估计模块的输入N帧(插值时N=3,去噪和超分N=7),中间帧作为参考帧,由N-1光流网络组成,具有相同结果,共享相同的参数(图2右侧橙色网格),从序列和参考帧中各自获取一帧作为输入,预测运行
光流网络模型采用的是提出的多尺度运动估计框架,处理帧之间的大位移情况。输入时参考帧和另一帧的高斯金字塔。每层的将该尺度的帧(该层的帧)和先前预测的上采样运动场作为输入,计算更准确。
对帧插值有一个小的修改,其中参考帧(第 2 帧)不是网络的输入,而是它应该合成的内容。
为了解决这个问题,用于插值的运动估计模块由两个流网络组成,都将第一帧和第三帧作为输入,并分别预测从第二帧到第一帧和第三帧的运动场。有了这些运动场,网络的后面模块可以将第一帧和第三帧转换为第二帧进行合成。
图像转换模块(对齐)
根据运动场,将所有输入帧对其到参考帧。我们使用空间变换网络 (Jaderberg et al 2015) (STN) 进行配准
这是一个可微分双线性插值层,在变换后合成新帧。每个 STN 将一个输入帧转换为参考视点,所有 N-1 个 STN 形成图像转换模块。该模块的一个重要特性是它可以将梯度从图像处理模块反向传播到流估计模块,因此我们可以学习适应不同视频处理任务的流表示。
图像处理模块
我们使用另一个卷积网络作为图像处理模块来生成最终输出。对于每个任务,我们使用稍微不同的架构。详情请参阅附件
Occluded regions in warped frames.变形帧时的遮挡区域【仅适用于帧插值的一种可选组件】
根据玩具示例发现,由于帧变形时总会造成双倍伪影,因此,提出该策略
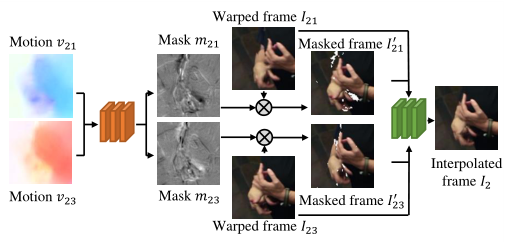
与 Liu et al (2017) 类似,我们也尝试了掩码预测网络。它将两个估计的运动场作为输入,一个从第 2 帧到第 1 帧,另一个从第 2 帧到第 3 帧(图 4 中的 v21 和 v23)。它预测两个遮挡掩码:m21 是来自第 1 帧 (I21) 的扭曲帧 2 的掩码,m23 是来自第 3 帧 (I23) 的扭曲帧 2 的掩码。扭曲帧(I21 和 I23)中的无效区域通过将它们与相应的掩码相乘来掩码。然后通过另一个卷积神经网络计算中间帧,其中扭曲帧(I21 和 I23)和掩码扭曲帧(I021 和 I023)作为输入。

一个有趣的观察是,即使没有掩码预测网络,我们的流量估计对遮挡也很稳健。如图 5 的第三列所示,使用 TOFlow 的扭曲帧几乎没有加倍伪影,因此,其掩码网络可选。
训练
首先对网络的一些模块进行预训练,然后将它们一起微调。
预训练
针对光流估计模块的预训练(1)在on the Sintel dataset预训练(2)针对去噪和超分,使用噪声和模糊输入对其进行微调。对于插值…
由于发现预训练可以提高收敛速度,因此使用L1作为估计光流和GT的损失函数。
针对掩码网络的预训练:在联合训练前,我们也训练该网络,对于帧插值来说,作为一种可选的视频处理组件。
联合训练:在预训练完成后,我们联合训练,使用L1来最小化帧和GT的损失,不对估计的光流进行任何监督,使用ADAM作为权重衰减,
所有任务为15个批次,大小为1的epoch,去噪和超分的学习率为 1 0 − 4 10^ {-4} 10−4,插值为3 ∗ * ∗ 1 0 − 4 10^{-4} 10−4
数据集Viemo90K
从 Vimeo 收集了一个新的视频数据集,其中包含 4,278 个视频和 89,800 个内容彼此不同的独立镜头。为了标准化输入,我们将所有帧的大小调整为固定分辨率 448×256。
我们进一步从数据集中为本文研究的三个视频增强任务生成三个基准
帧插值:我们从 14,777 个视频剪辑中选择了 73,171 个帧三元组,具有以下三个插值任务标准。首先,超过 5% 的像素应该在相邻帧之间具有大于 3 个像素的运动。此标准会删除静态视频。其次,使用光流(使用 SpyNet 计算)的参考帧和扭曲帧之间的 l1 差异应最多为 15 个强度级别(图像的最大强度级别为 255)。这会删除强度变化较大的帧,这对于帧插值来说太难了。第三,相邻帧(v21 和 v23)的运动场之间的平均差异应小于 1 个像素。这消除了非线性运动,因为大多数插值算法,包括我们的,都基于线性运动假设。
去噪:从 38,990 个视频剪辑中选择 91,701 个帧 septuplets 用于去噪任务。对于视频去噪,我们考虑两种类型的噪声:标准偏差为 0.1 的高斯噪声,以及除高斯噪声外还包括 10% 椒盐噪声的混合噪声。对于视频去块,我们使用 FFmpeg 压缩原始序列,编解码器为 JPEG2000,格式为 J2k,量化因子 q = {20,40,60}。
超分:我们还使用相同的 septuplets 集进行去噪,以构建下采样因子为 4 的 Vimeo 超分辨率基准:输入和输出图像的分辨率分别为 112×64 和 448×256。为了从高分辨率输入生成低分辨率视频,我们使用 MA TLAB imresize 函数,它首先使用三次滤波器模糊输入帧,然后使用双三次插值对视频进行下采样。
评价
在本节中,我们评估了所提出网络的两种变体。
(1)分别训练每个模块:我们先预训练运动估计,然后在固定流模块的同时训练视频处理。这类似于两步视频处理算法,我们将其称为固定流。
(2)联合训练所有模块,如 4.5 节所述,我们将其称为 TOFlow。
这两个网络都在我们收集的 Vimeo 基准上进行了训练。我们在三个不同的任务上评估这两种变体,并与其他最先进的图像处理算法进行比较。
本次只针对视频去噪(论文有对帧插值、视频去块、超分辨率的实验进行详细说明)
在 Vimeo 去噪基准上训练和评估我们的框架,使用三种类型的噪声:标准差为 15 强度级别的高斯噪声 (VimeoGauss15)、标准差为 25 的高斯噪声 (Vimeo-Gauss25),以及高斯噪声和10% 椒盐噪声(Vimeo 混合)。
为了将我们的网络与 V-BM4D (Maggioni et al 2012)(一种单目视频去噪算法)进行比较,我们还将 Vimeo Denoising Benchmark 中的所有视频转换为灰度以创建Vimeo -BW


从不同任务中学习光流
Flows Learned from Different Tasks
我们现在比较和对比从不同任务中学习到的流程,以了解是否有必要以这种面向任务的方式学习流程
通过在不同任务中训练得到的光流估计模块进行消融研究。当我们使用训练另一个任务的网络去测试,其性能会明显下降。例如去噪去块的光流网络31在超分中下降了5dB
我们发现,三个任务中,如果在不同任务上进行训练和测试,fixedflow要表现更好,但是在相同任务上训练和测试,toflow表现更好,这说明联合训练效果提高了流网络的性能,但是降低了其他方面的性能。

比较从不同任务中学习的光流场
再次训练光流的准确性
如图 1 所示,针对特定任务定制运动估计网络会降低估计流的准确性。为了验证这一点,我们评估了 Butler 等人 (2012) 在 Sintel Flow Dataset 上的流量估计精度。

如上图所示,TOFlow 的准确度远低于 EpicFlow(Revaud 等人 2015)或 Fixed Flow3,但如表 3、4 和 5 (之前三种任务和EpicFlow对比的数据)所示,TOFlow 在特定任务上的表现优于 Fixed Flow。这与 TOFlow 是一种与实际物体运动不匹配的运动表示,但会导致更好的视频处理结果的直觉一致
不同的光流模块架构
面向任务的视频处理管道不限于一种光流流量估计网络结构,尽管在之前的所有实验中,我们使用 Ranjan 和 Black (2017) 的 SpyNet 作为其内存效率的流量估计模块。
为了证明我们框架的泛化能力,我们还试验了 FlowNetC (Fischer et al 2015) 结构,并在视频去噪、去块和超分辨率方面对其进行了评估。
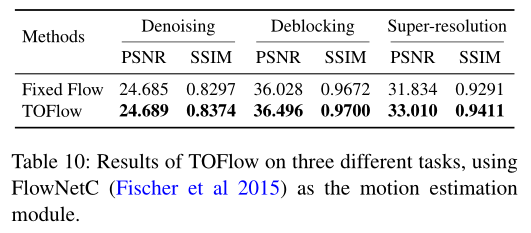
在所有这三个任务中,TOFlow 都优于 Fixed Flow。这证明了 TOFlow 框架对其他流量估计模块的泛化能力
为了证明我们框架的泛化能力,我们还试验了 FlowNetC (Fischer et al 2015) 结构,并在视频去噪、去块和超分辨率方面对其进行了评估。
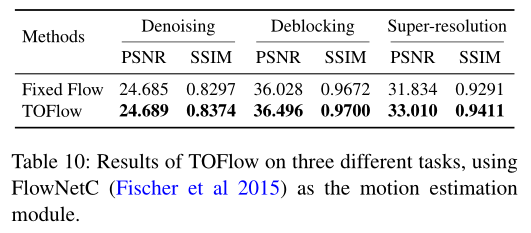
在所有这三个任务中,TOFlow 都优于 Fixed Flow。这证明了 TOFlow 框架对其他流量估计模块的泛化能力