==介绍==
在我们进一步介绍更多模型分析技巧前,我们先要对基本工具有一些了解。这一篇先介绍ftrace的基本用法。
ftrace在内核的Documentation目录下已经有文档了,我这里不是要对那个文档进行翻译,而是要说明这个工具的设计理念和使用策略。细节的东西读者要自己去看手册。
ftrace通过一个循环队列跟踪内核的执行过程。这个循环队列在内存中,大小是固定的(可以动态设置),所以写入的速度可以很快,在没有ftrace的时候,我经常通过类似的方式人工跟踪系统的执行过程,以便定位调度引起的各种问题。调度的问题对执行时间非常敏感,所以进行跟踪需要尽量避免把IO,等待等各种额外的要素加进来。而直接写内存就成为影响最小的一种模式了,ftrace很好地满足了这个要求。所以基本上现在我已经不需要再写额外的人工跟踪代码来跟踪系统的执行序列了。
ftrace通过debugfs对外提供接口,所以不需要额外的工具进行支持。ftrace在内核中的配置选项是CONFIG_FTRACE,除了这个基本选项外,下面还有很多子特定可以单独选,用户可以自己去看对应的Kconfig文档,一般的发行版都会开启这个特性,所以大部分情况下你也不需要为了使用这个功能重新编译内核。debugfs在大部分发行版中都mount在/sys/kernel/debug目录下,而ftrace就在这个目录下的tracing目录中。如果系统没有mount这个文件系统,你也可以手工mount。作为虚拟文件系统,它和procfs一样,给定类型就可以mount,比如你可以这样:
mount -t debugfs none /home/kenneth-lee/debug
tracing目录中的内容有点乱:
available_events current_tracer function_profile_enabled options saved_cmdlines_size set_ftrace_pid stack_trace trace_options tracing_on
available_filter_functions dyn_ftrace_total_info instances per_cpu set_event set_graph_function stack_trace_filter trace_pipe tracing_thresh
available_tracers enabled_functions kprobe_events printk_formats set_event_pid set_graph_notrace trace trace_stat uprobe_events
buffer_size_kb events kprobe_profile README set_ftrace_filter snapshot trace_clock tracing_cpumask uprobe_profile
buffer_total_size_kb free_buffer max_graph_depth saved_cmdlines set_ftrace_notrace stack_max_size trace_marker tracing_max_latency
里面虽然有一个README文件在解释,但这个文档更新得不快,很多时候和实际的内容对不上。但不要紧,只要我们抓住重点逻辑,就很容易理解了。ftrace的目录设置和sysfs类似,都是把目录当作对象,把里面的文件当作这个对象的属性。所以,虽然这个目录中的文件众多,我们只要先理解以下几个概念就很容易抓住重点了:
1. instance
一个用来跟踪的缓冲区(内存)称为一个instance,缓冲区的大小由文件buffer_size_kb和buffer_total_size_kb文件指定。有了缓冲区,你就可以启动行为跟踪,跟踪的结果会分CPU写到缓冲区中。缓冲区的数据可以通过trace和trace_pipe两个接口读出。前者通常用于事后读,后者是个pipe,可以让你动态读。为了不影响执行过程,我更推荐前一个接口。
trace等文件的输出是综合所有CPU的,如果你关心单个CPU可以进入per_cpu目录,里面有这些文件的分CPU版本。
我们不要看到trace文件中输出那么多文本,就觉得这个跟踪效率不高。那些文本都是事后(就是你读这个文件的时候)format出来的,跟踪的时候仅仅记录了必须的数据信息,所以不需要担心跟踪时的效率问题。
所以读者应该已经明白了/sys/kernel/debug/tracing这个目录本身就代表一个instance。如果你需要更多的instance,你可以进入到这个目录下面的instances目录中,创建一个任意名字的目录,那个目录中就也会有另一套buffer_size_kb啦,trace啦这些文件,那里就是另一个instance了。通过多instance,你可以隔离多个独立的跟踪任务。当然,这也很浪费内存。
和所有面向对象设计一样,instance通过操作对应属性来控制其行为,比如,向trace文件写一个空字符串可以清空对应的缓冲区:
echo > trace
又比如,向tracing_on文件写1启动跟踪,写0停止跟踪等。向set_ftrace_pid写pid可以限制只根据某个pid的事件等。
更复杂的控制在trace_options中,这个文件也是很好理解的,类似vim,你看看它的内容,要启动某个功能就echo某个字符串进去,要关闭它只要echo带“no”前缀的那个字符串进去就可以了。options目录可以提供更精细的控制。
2. 事件(event)
ftrace有两种主要跟踪机制可以往缓冲区中写数据,一种是函数,一种是事件。前者比较酷,很多教程都会先讲前者。但对我来说,后者才比较可靠实用,所以我先讲后者。
事件是固定插入到内核中的跟踪点,我们看Linux代码的时候,经常看到这种trace_开头的函数调用:
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
trace_sched_switch(preempt, prev, next);
rq = context_switch(rq, prev, next, cookie); /* unlocks the rq */
} else {
lockdep_unpin_lock(&rq->lock, cookie);
raw_spin_unlock_irq(&rq->lock);
}
这个地方就是一个事件,也就是打在程序中的一个桩,如果你使能这个桩,程序执行到这个地方就会把这个点(就是一个整数,而不是函数名),加上后面的三个参数(preempt, prev, next)都写到缓冲区中。到后面你要输出的时候,它会用一个匹配的解释函数来把内容解释出来,然后你在trace文件中看到的就是这样的:

启动事件跟踪的方法很简单:
1. 先查available_events中有哪些可以用的事件(查events目录也可以)。
2. 把那个事件的名称写进set_event,可以写多个,可以写sched:*这样的通配符
3. 通过trace_on文件启动跟踪。启动之前可以通过比如tracing_cpumask这样的文件限制跟踪的CPU,通过set_event_pid设置跟踪的pid,或者通过其他属性进行更深入的设定。
剩下的事情就是执行跟踪程序和分析跟踪结果了。
我通常把ftrace的设置和启动等命令和业务程序的启动写到一个脚本中,一次运行足够的时间然后直接取结果。然后就专心手工或者通过python脚本分析输出结果(ftrace的输出用awk很不好拆,还是python比较实际)
事件跟踪的另一个更强大的功能是可以设定跟踪条件,要做这种精细化的设置,你需要直接操作events目录下面的事件参数,比如仍是跟踪前面这个sched_switch,你可以先看看events/sched/sched_switch/format文件:
name: sched_switch
ID: 273
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:char prev_comm[16]; offset:8; size:16; signed:1;
field:pid_t prev_pid; offset:24; size:4; signed:1;
field:int prev_prio; offset:28; size:4; signed:1;
field:long prev_state; offset:32; size:8; signed:1;
field:char next_comm[16]; offset:40; size:16; signed:1;
field:pid_t next_pid; offset:56; size:4; signed:1;
field:int next_prio; offset:60; size:4; signed:1;
你就可以看到这个事件可以支持的域,你只要向同级目录中的filter中写一条类C的表达式就可以对这个事件进行过滤。
比如,我注意到这个跟踪点支持next_comm这个域,我就可以这样写:
echo 'next_comm ~ "cs"' > events/sched/sched_switch/filter
这样我就可以仅跟踪调度器切换到cs这个线程的场景了。
对于性能分析,我用得最多的是这个线程switch事件(还有softirq的一组事件)。因为从考量通量的角度,主业务CPU要不idle,它要不在处理业务,要不在调度。一个“不折腾”的系统,主业务进程应该每次都用完自己的时间片,如果它总用不完,要不是它实时性要求很高(主业务这种情况很少),要不是线程调度设计有问题。我们常常看到的一种模型是,由于业务在线程上安排不合理,导致一个线程刚执行一步,马上要等下一个线程完成,那个线程又执行一步,又要回来等前一个线程完成,这样CPU的时间都在切换上,整个通量就很低了。
这种模型后面专门论述,但通过ftrace看调度过程,我们很容易用python分析这个调度过程,捕获所有“提前切换”的情况,并对高几率的提前切换进行分析,就可以针对性地解决问题了。
事件上还可以安装trigger,用来触发特定的动作,我很少用这个功能,读者可以自己看手册看看有没有什么实际的用途。 其中手册中提到一个特别酷的功能叫“hist”(输出柱状图),它可以通过这样的命令:
echo 'hist:key=call_site:val=bytes_req' > /sys/kernel/debug/tracing/events/kmem/kmalloc/trigger
实现下面这样的效果:

这相当于给你提供一个各个内存分配点的内存分配次数和数量的一个分布图。这很爽,不过老实说,有了trace文件,要产生这样的数据也是分分钟的事,所以我也不是很需要这个功能。
3. 预定义功能
事件跟踪需要根据我们对Kernel业务流有清晰的认识,我们才能合理设置事件。功能跟踪就会简单得多,功能跟踪可以直接使能某种跟踪功能,具体用什么事件,设置什么参数等,都默认设置好,这种预定义功能在available_tracers中列出,只要选择其中一个,把对应的名字写入current_tracer文件中就可以启动这个功能
我的机器上支持如下功能:
blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
比如我要跟踪系统唤醒的时延,我们可以:
echo wakeup > current_tracer
echo 1 > tracing_on
wakeup跟踪的输出是这个样子的:

它可以跟踪在你跟踪的期间里,最高优先级的任务的调度最大时延。比如上面这个统计统计到的最大时延是52us(算不错了),下面给出的跟踪点是这个任务(irq/49-iwlwifi-1625)被唤醒后,执行了哪些动作,才轮到它执行了。通过分析这些动作,你就可以知道你可以优化哪些流程来提升整个系统的实时性了。
我很少使用这种成套跟踪,读者可以自己一个个试用一下,看看是否有趁手的工具,可以帮助你解决你的环境中面的的问题。
4. 函数跟踪
成套跟踪中有两个功能其实是相对独立的,就是function和function_graph。这个功能可以和事件一样单独使用(可惜的是不能同时使用,其实照理说这没有什么难度的)。
函数跟踪和事件跟踪一样,相当于在函数入口那里增加了一个trace_函数, 函数跟踪的效果类似这样:
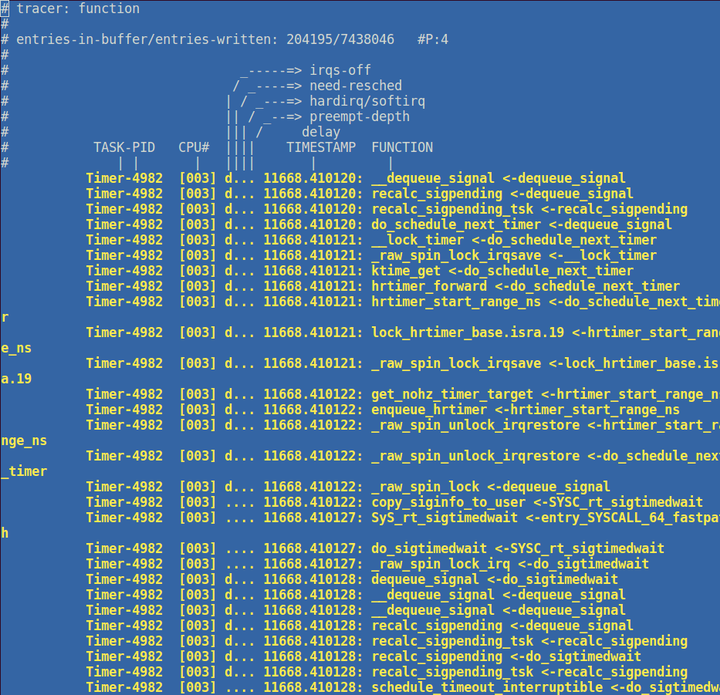
加堆栈跟踪的话,可以变成这样:

函数跟踪也可以做类似事件工作一样的过滤功能,这个用户可以看手册,我用这个功能一般是用来跟踪和性能无关的执行过程,
== 用户态跟踪==
ftrace一个比较明显的缺点是没有用户态的跟踪点支持,作为补救,instance中提供了一个文件,trace_marker,写这个文件可以在跟踪中产生一条记录。类似这样:

你可以注意到,这其中 tracing_mark_write就是一个marker,我在我的程序做pthread_yield()的时候加了一个marker,这样我就可以跟踪当我yield出去的时候,系统是否发生了重新调度。
这个跟踪方法的缺点是需要额外的系统调用,没有内核跟踪那么高效,但聊胜于无,至少这个方法帮助我解决过不少问题。
==会话跟踪==
使用ftrace的另一个缺点是它会话跟踪能力比较差,比如你在网卡上收到一个包,这个包调度到了Socket的队列,然后再送到用户队列。虽然你可以在这些位置人工增加跟踪点,但你不知道这个包属于哪个会话,你也不知道这个包在会话上的时延是什么。这个问题没有非常好的解决方案,关键在于你的跟踪点必须能从这个包上提取出会话有关的信息,比如你能取出这个包的类型和端口号,你就可以从跟踪结果上匹配出整个会话的流程来。
现在网络层的预置事件比较少,我们可以首先考虑是否可以通过函数来跟踪,如果不行,就自己加跟踪点吧。
==其他功能==
ftrace还可以通过uprobe/kprobe设置跟踪点,我对这两个东西不是很信任,所以用得很少,原理也很容易猜出来,所以,读者有兴趣可以自己去看,这里就不深入介绍了。
==总结==
本文介绍了ftrace的基本功能和用法。ftrace主要用于跟踪时延和行为,它让我们可以很深入地了解系统的运行行为。是进行Linux性能调优必须掌握的基本工具