一、工具介绍
Locust是一个开源的Python性能测试工具,用于模拟大量并发用户访问网站、API等,以测试系统的性能和稳定性。它的主要特点包括:
1.简单易用:Locust基于Python编写,使用方便,学习曲线较低。
2.分布式支持:Locust支持分布式部署,可以在多台机器上运行,以模拟更大的并发用户。
3.实时监控:Locust提供实时监控和报告,可以查看测试性能指标、请求响应时间、错误率等数据。
4.脚本编写:Locust使用Python编写测试脚本,支持自定义请求和用户行为。
5.可扩展性:Locust支持自定义插件和扩展,可以满足不同测试需求。
在使用Locust进行性能测试时,需要编写Python脚本来定义用户行为和请求,然后使用Locust运行测试脚本,并设置并发用户数、请求频率等参数。Locust会模拟用户行为和请求,并记录性能数据,最后生成测试报告。
二、在项目中的应用
2.1 说明
本次测试的目的在于探查公司自研系统测试环境的系统业务处理性能,以及在高负载情况下的系统表现,通过对于项目架构和业务场景分析,设计从小程序 登录->首页刷新->设备数据监测/控制记录->设备采集数据查询->设备阈值保存(含web端接口)业务链路模型进行模拟和测试,实现多接口顺时并发压测,设计操作接口、并发比例等详情如下:

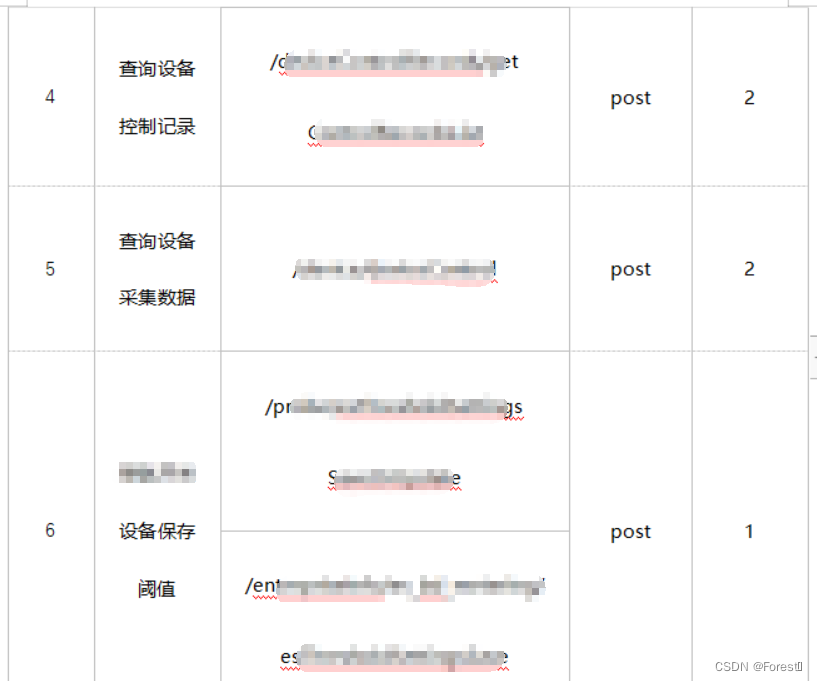
2.2示例代码脚本
import os, random
from locust import HttpUser, events, task, between
class UserBehavior(HttpUser): # 定义一个TaskSet类,用于定义用户行为 TaskSet,HttpUser
# @task # 若添加@task装饰器,则该方法会在每个用户执行任务时执行,此处注销
def on_start(self): # 在测试开始执行的方法,用于进行登录操作获取token,用于后续接口的带入调用
# 定义Content-Type请求头类型和请求体
self.client.headers = {'Content-Type': 'application/json'}
payload = {'username': 'xxx',
'password': 'xxxxx'}
rs_login = self.client.post('url',
headers=self.client.headers,
json=payload)
# 从登录接口返回值中获取token,添加至Content-Type请求头中
self.client.headers['Authorization'] = 'Bearer ' + rs_login.json()['data']['access_token']
print(self.client.headers)
pass
# @task
def on_stop(self):
pass
# 在@task后添加(weight=权重值),若不填写(weight=权重值),只有task则默认的任务权重为1。注:(weight=权重值)要带上weight=,否则只有数值时,则这个数字将被解释为一个位置参数,而不是权重。
@task
def test_login(self): # 登录接口
self.client.headers = {'Content-Type': 'application/json'}
payload = {'username': 'xxx',
'password': 'xxx'}
rs_login = self.client.post('url',
headers=self.client.headers,
json=payload)
self.client.headers['Authorization'] = 'Bearer ' + rs_login.json()['data']['access_token']
@task(weight=3)
def test_refresh(self):
rs_rf0 = self.client.post('url',
headers=self.client.headers)
print(rs_rf0.json()['code'], '刷新操作')
rs_rf1 = self.client.post('url',
headers=self.client.headers,
json={'测试数据': ["xxx"]})
print(rs_rf1.json()['code'], '刷新操作2')
@task(weight=2)
def test_query(self):
data1 = {'28C5363480B514FFA': '测试数据1',
'6440FBF646F0010FA': '测试数据2',
'642B972C2350035FA': '测试数据3',
'6444A4A83250001FA': '测试数据4',
'28C46609643A3EDFA': '测试数据5'}
try:
for id, msg in data1.items():
rs_refresh1 = self.client.post('url',
headers=self.client.headers,
json={"测试数据"})
print(rs_refresh1.json()['code'], msg, rs_refresh1.json()['msg'])
except Exception as e:
print(e)
class WebsiteUser(UserBehavior): # 定义一个HttpUser类,继承以上的UserBehavior任务类。
wait_time = between(0.1, 1.0) # 定义用户执行任务之间的等待时间,使用between函数指定等待时间范围为0.1秒到1秒之间。
host = "url" # 指定要测试的主机地址。
min_wait = 1000 # 指定用户在执行任务之间的最小和最大等待时间,单位为毫秒。
max_wait = 3000
if __name__ == '__main__':
os.system(r'locust -f 脚本路径 --host=测试地址 --web-host=web监控地址,一般为自己的主机ip,若不设置则默认为localhost --web-port=8089')
先做个基准测试,在小并发条件下,探测系统各性能指标表现,作为后续比对基础。
场景一:设置50并发,每秒增长用户数量为5

点击启动按钮后开始压测,在本页面即可查看监控各项性能数据和图标信息
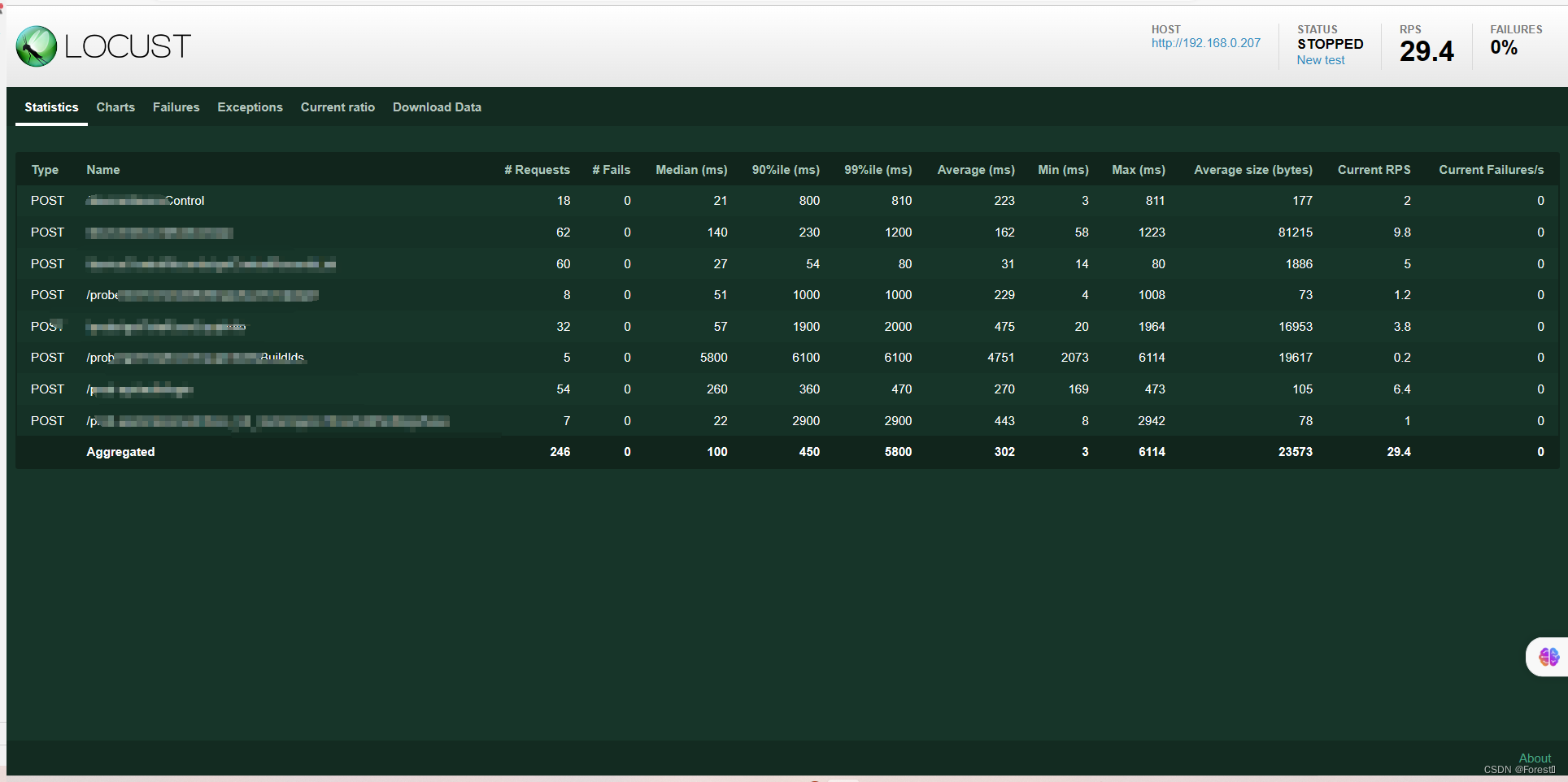
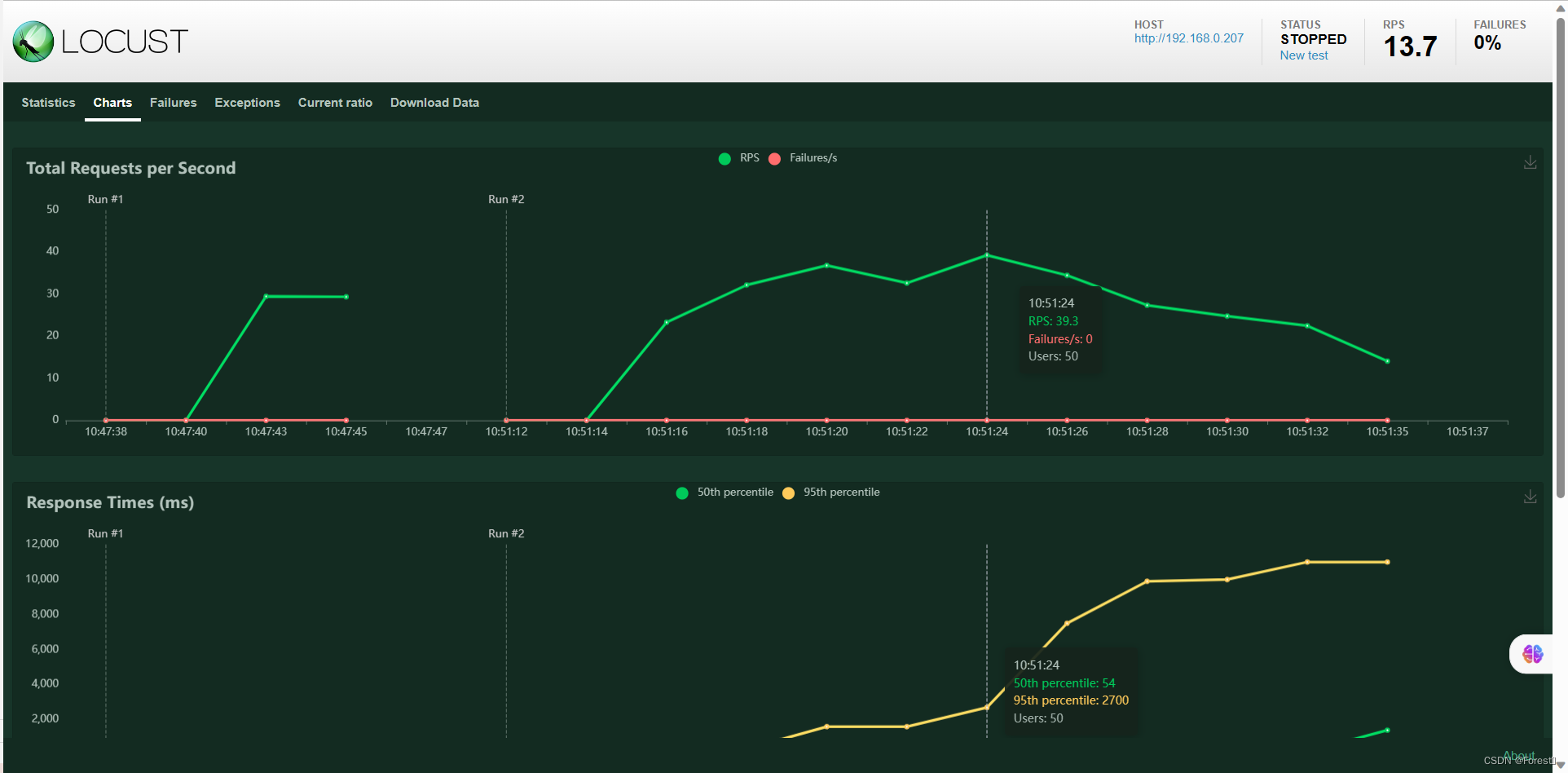
download data - download report中可下载HTML格式的测试报告
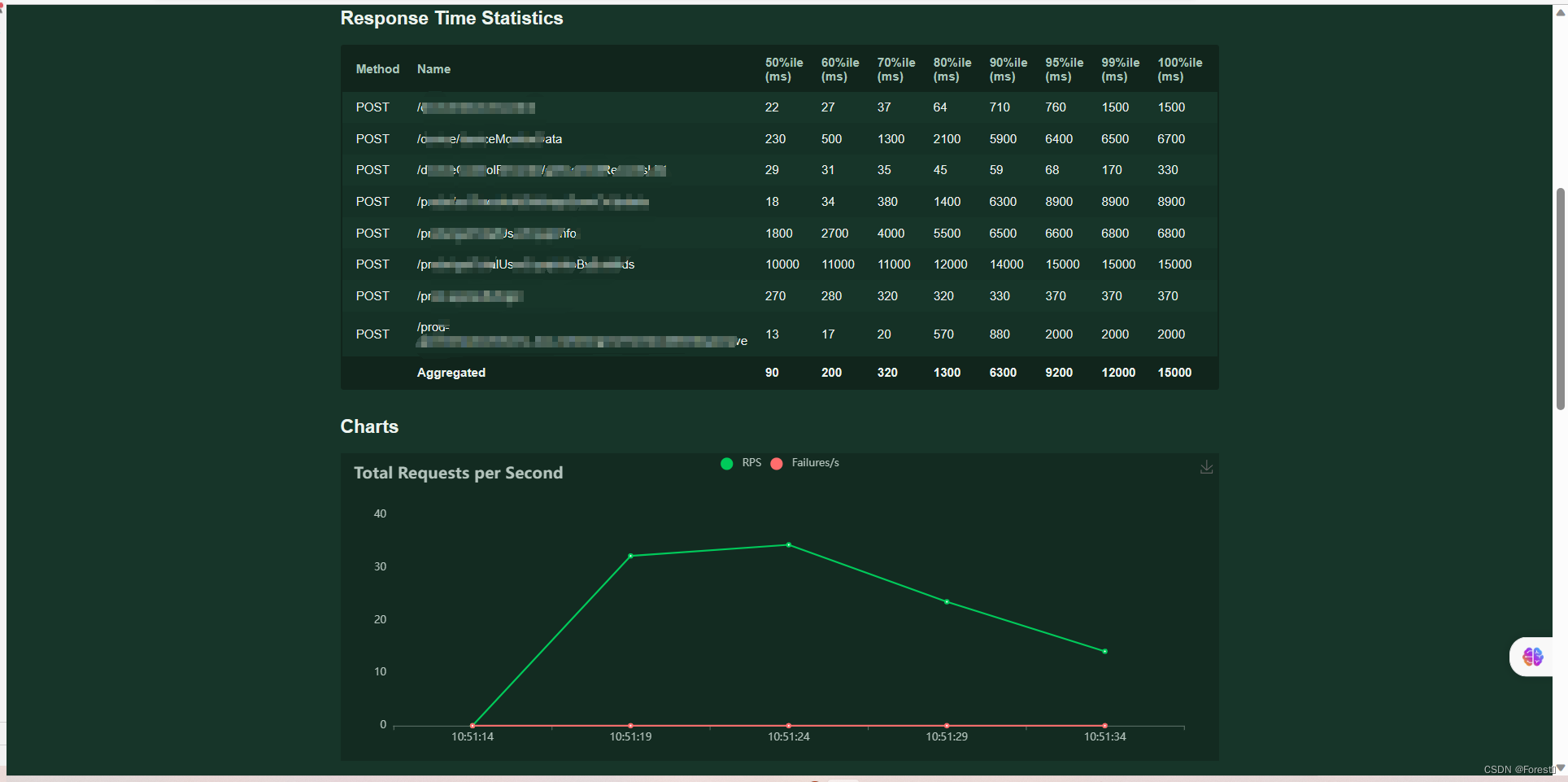
三、分布式压测
3.1 说明
分布式压测是指使用多个节点或机器同时模拟大量并发用户进行性能测试的方法。每个节点负责模拟一部分用户,发送请求并记录性能数据,然后将数据汇总到一个中心节点进行分析和报告生成。
使用分布式压测的场景包括:
1、高并发负载测试:当系统需要处理大量并发用户时,使用分布式压测可以模拟真实的用户行为和流量模式,评估系统的性能和响应能力。这对于在线购物、社交媒体、电子支付等高流量应用特别重要。
2、弹性和扩展性测试:分布式压测可以模拟系统在不同负载下的性能表现,帮助确定系统的弹性和扩展性。通过增加节点,可以模拟更大规模的用户并发,测试系统在高负载下的稳定性和可扩展性。
3、负载均衡测试:在分布式系统中,负载均衡是重要的组成部分。使用分布式压测可以模拟多个节点同时向负载均衡器发送请求,评估负载均衡的性能和效果,确保系统能够平衡负载并提供高可用性。
4、容量规划和优化:通过分布式压测,可以确定系统的容量和性能瓶颈,帮助进行容量规划和优化。通过模拟大规模的并发用户,可以找到系统的瓶颈点,并采取相应的优化措施,提高系统的性能和稳定性。
3.2 实现方式
创建主节点(1个)和从节点脚本(可多个),主节点脚本主要要来监控,从节点脚本代码可主节点脚本代码一致,可根据实际需求修改压测接口,若要测试多个不同接口可在从节点脚本代码中修改或增加任务。
3.3示例代码
3.3.1主节点
import os
from locust import HttpUser, TaskSet, task
# 定义任务类
class UserTask001(HttpUser):
@task # 申明需要执行的任务
def get_index(self):
self.client.get('/22') # client是requests的对象
@task
def get_image(self):
self.client.get('/s?ie=utf-8&wd=locust视频')
# 执行任务类
class WebSiteUser(UserTask001):
# tasks = [UserTask001] # 定义需要执行的任务集
min_wait = 1000 # 最小等待时间(思考时间)
max_wait = 2000 # 最大等待时间(思考时间)
host = 'http://www.baidu.com' # 设定请求的域名
if __name__=="__main__":
#开启master模式
os.system('locust -f D:\py_code\stress\master_node.py --master')
注:主节点的执行方式命令必须要加上参数–master
3.3.2从节点
import os
from locust import HttpUser, task
# 定义任务类
class UserTask001(HttpUser):
@task # 申明需要执行的任务
def get_index(self):
self.client.get('/22') # client是requests的对象
@task
def get_image(self):
self.client.get('/s?ie=utf-8&wd=locust视频')
# 执行任务类
class WebSiteUser(UserTask001):
# tasks = [UserTask001] # 定义需要执行的任务集
min_wait = 1000 # 最小等待时间(思考时间)
max_wait = 2000 # 最大等待时间(思考时间)
host = 'http://www.baidu.com' # 设定请求的域名
if __name__=="__main__":
#开启master模式
os.system('locust -f D:\py_code\stress\secondary.py --worker')
注:主节点的执行方式命令必须要加上参数–worker,运行后可在主节点控制台查看详情,执行多个从节点脚本则会显示多个worker

web-ui监控页面详情
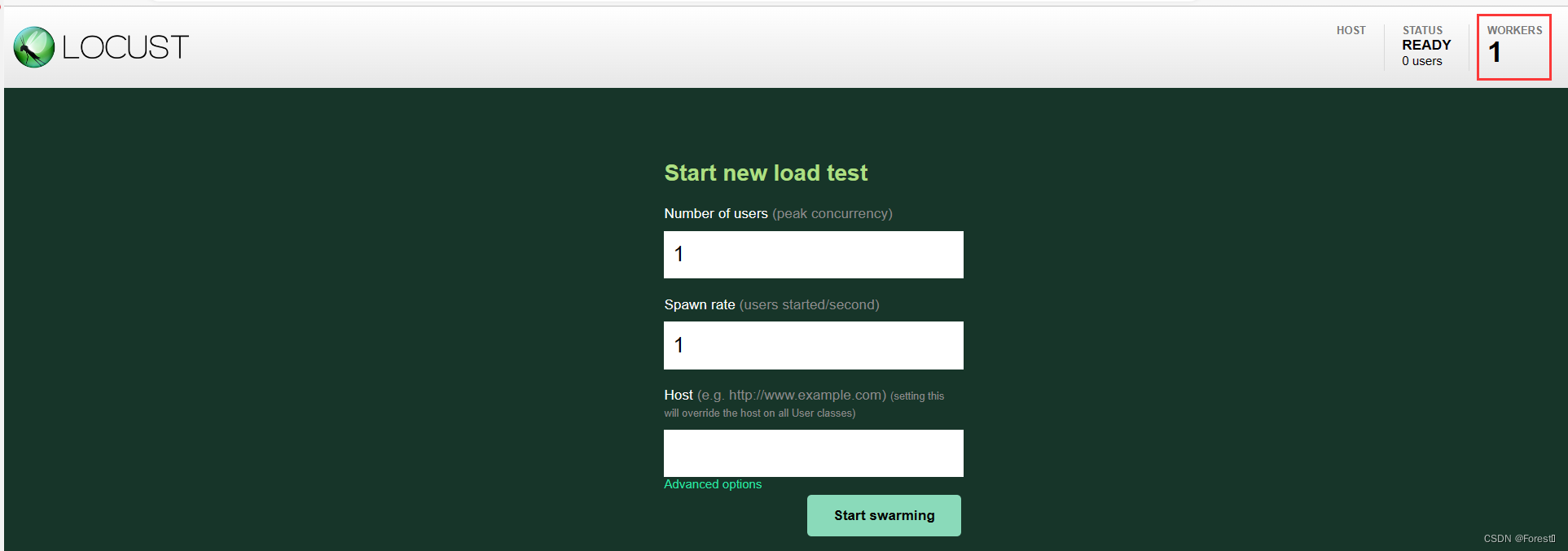
主节点主要用于监控从节点的执行情况,若主节点和从节点脚本分别在不同的测试机上,在执行脚本时需要加上定义的–web-host=IP,ip需对应才可连接。