目录
雪花算法原理介绍
雪花算法源码分析
低频场景下都是偶数的原因
解决雪花算法的偶数问题
1、切换毫秒时使用随机数
2、抖动上限值加抖动序列号
雪花算法原理介绍
雪花算法(snowflake)最早是twitter内部使用的分布式下的唯一id生成算法,在2014年开源,开源的版本由scala编写,地址为https://github.com/twitter-archive/snowflake,该算法具有以下特性
- 唯一性:高并发分布式系统中生成id唯一
- 高性能:每秒可生成百万个id
- 有序性:生成的id是有序递增的
-
不依赖第三方的库或者中间件
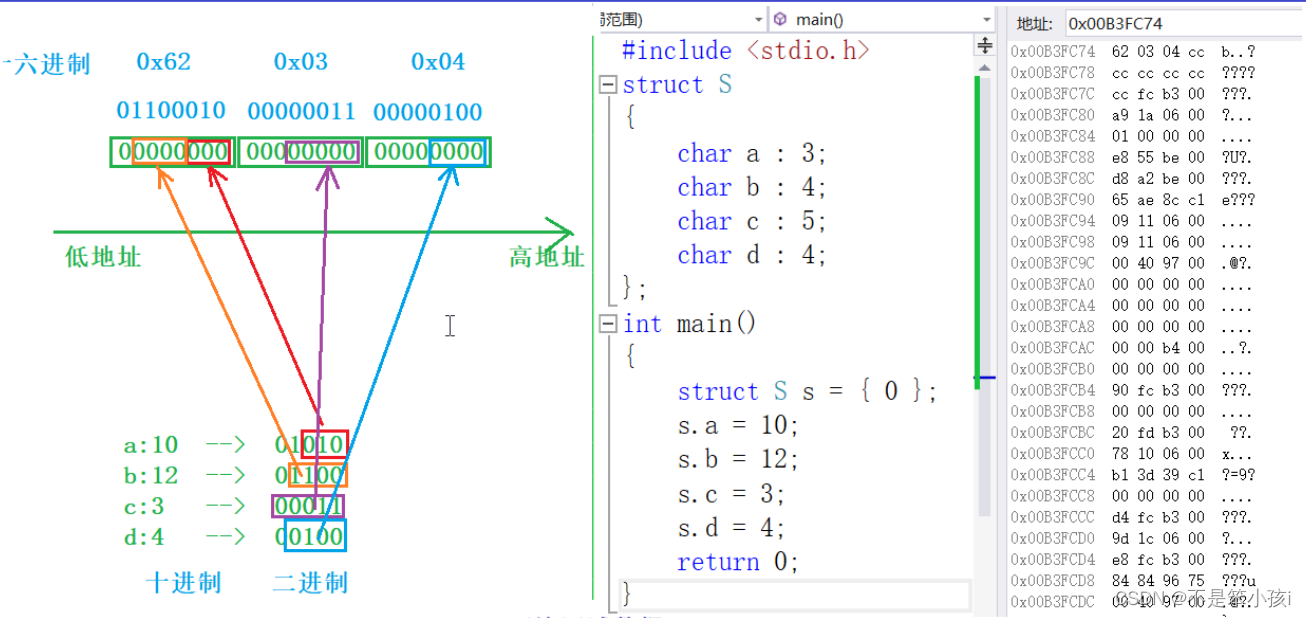
算法产生的是一个Long型 64 bit位的值,转换成字符串长度最长19位。
SnowFlake的结构(每部分用-分开):
0-00000000000000000000000000000000000000000-00000-00000-000000000000
- 第一部分:1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,ID要是正数,最高位是0
- 第二部分:41位毫秒数,不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 自定义起始时间截),自定义起始时间戳即人为指定的算法起始时间,当前时间即生成ID时的时间戳41位的时间截,可以使用约69年, (1L << 41) / (365 * 24 * 3600 * 1000)≈ 69
- 第三、四部分:10位的数据机器位,可以部署在1024(1L<<10)个节点,包括5位datacenterId(机房)和5位workerId(机器号)
- 第五部分:12位序列,每毫秒可生成序列号数,共4096(1L<<12)个ID序号
以上5部分总64bit,即需要一个Long整型来记录
SnowFlake的优点:
- 整体按时间自增排序
- Long整型ID,存储高效,检索高效
- 分布式系统内无ID碰撞(各分区由datacenterId和workerId来区分)
- 生成效率高,占用系统资源少,理论每秒可生成1000 * 4096 = 4096000个,也就是单台机器理论上每秒钟可以生成400万个分布式ID序列号
雪花算法源码分析
雪花算法源码如下所示,代码里面都做了详细的说明
public class SnowFlake {
/**
* 数据中心/机房标识所占bit位数
*/
private final static long DATACENTER_BIT = 5;
/**
* 机器标识所占bit位数
*/
private final static long WORKER_ID_BIT = 5;
/**
* 每毫秒下的序列号所占bit位数,2的12次方,0到4095,一秒钟最多生产4096个数字
*/
private final static long SEQUENCE_BIT = 12;
// 起始时间戳 2023-07-14 00:00:00,可以根据自己的需求进行修改
private final static long EPOCH=1689264000000L;
// 机器标志相对序列号的偏移量 12位
private final static long WORKER_ID_LEFT = SEQUENCE_BIT;
// 机房标志相对机器的偏移量 17 = 12 + 5位
private final static long DATACENTER_LEFT = WORKER_ID_LEFT + WORKER_ID_BIT;
// 时间戳标志相对机器的偏移量 22 = 17 + 5位
private final static long TIMESTAMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
// 用位运算计算出最大支持的数据中心编号 31
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
// 用位运算计算出最大支持的机器编号 31
private final static long MAX_WORKER_ID_NUM = -1L ^ (-1L << WORKER_ID_BIT);
// 用位运算计算出12位能存储的最大整数,12位的情况下为4095
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/*
机房 机器 序列号 上一次请求保存的时间戳
*/
private long datacenterId;
private long workerIdId;
private long sequence = 0L;// 自增序列号(相当于计数器)
private long lastStamp = -1L;
public SnowFlake() {}
/**
* 构造函数
*
* @param workerId 机器ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowFlake(long workerId, long datacenterId) {
if (workerId > MAX_WORKER_ID_NUM || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", MAX_WORKER_ID_NUM));
}
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", MAX_DATACENTER_NUM));
}
this.workerIdId = workerId;
this.datacenterId = datacenterId;
}
/**
* 产出下一个Id
* @return
*/
public synchronized long nextId() {
// 获取当前的时间戳
long curStamp = getCurrentStamp();
// 若当前时间戳 < 上次时间戳则抛出异常
if (curStamp < lastStamp) {
throw new RuntimeException("Clock moved backwords. Refusing to generate id");
}
// 1.同一毫秒内
if (curStamp == lastStamp) {
// 1.1 相同毫秒内 id自增
sequence = (sequence + 1) & MAX_SEQUENCE;
// 1.2 同一毫秒内 序列数已经达到最大4095,等待下一个毫秒到来在生成
if (sequence == 0L) {
// 获取下一秒的时间戳并赋值给当前时间戳
curStamp = getNextMill();
}
} else {
// 2.不同毫秒,序列号重置为0
sequence = 0L;
}
// 3.当前时间戳存档, 用于下次生成id对比是否为同一毫秒内
lastStamp = curStamp;
// 4.或运算拼接返回id
return (curStamp - EPOCH) << TIMESTAMP_LEFT // 时间戳部分
| datacenterId << DATACENTER_LEFT // 机房部分
| workerIdId << WORKER_ID_LEFT // 机器部分
| sequence; // 序列号部分
}
private long getNextMill() {
long mill = getCurrentStamp();
// 循环获取当前时间戳, 直到拿到下一秒的时间戳
while (mill <= lastStamp) {
mill = getCurrentStamp();
}
return mill;
}
private long getCurrentStamp() {
return System.currentTimeMillis();
}
public static void main(String[] args) throws InterruptedException {
SnowFlake snowFlake = new SnowFlake();
for (int i = 0; i < 10; i++) {
Thread.sleep(1L);
System.out.println(snowFlake.nextId());
}
}
}我们运行测试一下,注意测试中每次都调用都休眠了一毫秒,来模拟低频次调用生成分布式ID的场景,运行后控制台输出如下所示:可以看到生成的都是偶数
214341257265152
214341261459456
214341269848064
214341278236672
214341286625280
214341290819584
214341295013888
214341303402496
214341307596800
214341315985408
低频场景下都是偶数的原因
低频场景下调用时,每次都是不同毫秒值的时间戳,导致每次都走到了sequence = 0L,即序列号都是0,最终生成序列号时是通过|或运算生成的,最后一位都是0或运算得到的还是0,转成Long整数时就都是偶数了
public synchronized long nextId() {
......
// 1.同一毫秒内
if (curStamp == lastStamp) {
......
} else {
// 2.不同毫秒,序列号重置为0
sequence = 0L;
}
......
}如果生成的序列号都是偶数,并且作为分库分表的分片键时就会出现严重的数据倾斜问题,这个问题是非常严重的(解决办法可以将该序列号计算hashcode再进行分片计算)
解决雪花算法的偶数问题
1、切换毫秒时使用随机数
改动代码主要是sequence = ThreadLocalRandom.current().nextLong(randomSequenceLimit)这一行,就是在跨毫秒时自增计数器不再初始化为0,而是取一个0或者1的随机数,通过这种形式来避免都是偶数的问题。
/**
* 此属性用于限定一个随机上限,在不同毫秒下生成序号时,给定一个随机数,避免偶数问题。
* 注意次数必须小于{@link #MAX_SEQUENCE}
* 不同毫秒,序列号取一个[0,randomSequenceLimit)之间的随机数,避免都是偶数的情况
*/
private final long randomSequenceLimit=2;
public synchronized long nextId() {
......
if (curStamp == lastStamp) {
......
} else {
// 2.不同毫秒,序列号取一个[0,randomSequenceLimit)之间的随机数,避免都是偶数的情况
sequence = ThreadLocalRandom.current().nextLong(randomSequenceLimit);
//sequence = 0L;
}
......
}2、抖动上限值加抖动序列号
- maxVibrationOffset:最大抖动上限值,即在跨毫秒时如果sequenceOffset的值超过了maxVibrationOffset则归0,最好设置为奇数,注意该值必须小于等于MAX_SEQUENCE即4095
- sequenceOffset:跨毫秒时的序列号,不同毫秒,超过了抖动上限则将sequenceOffset计数器归0,否则sequenceOffset累加1,sequence的值设置为sequenceOffset
通过sequenceOffset序列号自增保证了跨毫秒时不会一直出现偶数的情况,通过maxVibrationOffset的限制保证sequenceOffset不会无限递增
//最大抖动上限值,最好设置为奇数,注意该值必须小于等于MAX_SEQUENCE即4095
private int maxVibrationOffset=1;
//跨毫秒时的序列号,跨毫秒获取时该序列号+1
private volatile int sequenceOffset = -1;
public synchronized long nextId() {
......
if (curStamp == lastStamp) {
......
} else {
// 2.不同毫秒,处理抖动上限,超过了抖动上限则将sequenceOffset计数器归0,否则sequenceOffset累加1
//将sequence设置为sequenceOffset
vibrateSequenceOffset();
sequence = sequenceOffset;
//sequence = 0L;
}
......
}
private void vibrateSequenceOffset() {
//不同毫秒时间,处理抖动上限,超过了抖动上限则将sequenceOffset计数器归0,否则sequenceOffset累加1
sequenceOffset = sequenceOffset >= maxVibrationOffset ? 0 : sequenceOffset + 1;
}通过测试程序进行验证:
第一种通过随机数的方式,基本上解决了跨毫秒的偶数问题,但是因为随机数的缘故,跨毫秒的奇偶数不能保证百分百的1:1,不过也可以接受;
第二种将maxVibrationOffset设置为奇数时,可以在跨毫秒时保证生成的奇偶数序列号数量为1:1,比第一种随机数的效果要好一些。