LLM(大语言模型)因其强大的语言理解能力赢得了众多用户的青睐,但LLM庞大规模的参数导致其部署条件苛刻;在网络受限,计算资源有限的场景下无法使用大语言模型的能力;低算力,本地化部署的问题亟待解决。ChatGLM-6B在60亿参数的情况下做到了优秀的中英文对话效果,且能够支持在消费级显卡本地部署;因此在HuggingFace Trends上很快登顶。6B的参数量虽然能够做到本地部署,但是目前的实现依赖库较多,如Pytorch, transfomer;对于端侧部署来说要求仍然较高。因此我们尝试将该模型转换为MNN模型,极大降低了部署时的依赖项,能够更方便的在各类端侧设备上部署与测试;同时我们对MNN模型进行了低bit量化,并实现了反量化与计算融合的计算kernel,大大降低了内存需求。实测PC端小显存显卡能够成流畅运行浮点模型,在Android手机上能够流畅运行量化模型。
代码实现:https://github.com/wangzhaode/ChatGLM-MNN

模型导出
模型导出采用了Pytorch到ONNX到MNN的转换方式,并切对模型进行了拆分导出,将embedding,28 x GLMBlock, lm分别导出;并且在导出时对词表进行了瘦身。模型导出代码。
▐ 导出方式
Pytorch实现的模型导出目前有2种主流方案:1. 导出为ONNX; 2. 导出为TorchScript。分析代码后可知,ChatGLM的模型结构比较简单,Embedding层,28层GLMBlock,线性层;其中GLMBlock结构如为LayerNorm -> SelfAttention -> LayerNorm -> MLP,代码如下:
attention_input = self.input_layernorm(hidden_states)
# Self attention.
attention_outputs = self.attention(
attention_input,
position_ids,
attention_mask=attention_mask,
layer_id=layer_id,
past_key_value=past_key_value,
use_cache=use_cache,
output_attentions=output_attentions
)
attention_output = attention_outputs[0]
outputs = attention_outputs[1:]
# Residual connection.
alpha = (2 * self.num_layers) ** 0.5
hidden_states = attention_input * alpha + attention_output
mlp_input = self.post_attention_layernorm(hidden_states)
# MLP.
mlp_output = self.mlp(mlp_input)
# Second residual connection.
output = mlp_input * alpha + mlp_output因为该模型结构简单,使用的算子 ONNX全部支持;同时MNN对ONNX的支持完备性比较好;因此选择使用ONNX导出模型。
▐ 结构拆分
在确定使用ONNX之后首先直接使用torch.onnx.export尝试对模型进行导出,导出过程非常缓慢,导出后模型的权重大小有28G。在将模型转换到MNN时会执行一些图优化Pass;因为模型太大导致占用内存过高速度非常慢;因此考虑将模型进行拆分优化。拆分之后的优化考虑如下:
Embedding层的参数大小为
150528 * 4096, 单个权重使用内存非常大;考虑到输入文字数量较小(相对于150528),使用Gather实现消耗大量内存/显存,直接将参数存储为二进制文件,通过fseekfread实现Gather的操作能够在稍微牺牲速度的情况下节约2.3G内存;同时为了降低模型的文件大小,将embedding层的数据使用bf16格式存储,能够将文件大小降低一半,对精度和性能形象非常小。GLMBlock层的权重总大小为21G,仍然非常大,每个Block的大小为768M;考虑到要在端侧各类设备部署,可以将28层Block分别导出,对于浮点模型,这样的好处是能够在显存不足的情况下将部分Block放置在GPU,其余部分放置在CPU进行推理,这样能够充分利用设备算力;对与移动端设备,对这些block进行量化,分别获得int8/int4的权值量化模型,使用int4量化模型大小为2.6G,可以在端侧小内存设备部署。
线性层通过一个矩阵乘将hidden_state转换为词语的prob:
[num, 4096] @ [4096, 150528];其实这里并不需要num全部参与运算,比如输入序列长度num = 10时,实际预测下一个词语时进需要使用最后一个[1, 4096]即可。因此可以先对输入变量做一个Gather然后执行矩阵乘:[1, 4096] @ [4096, 150528]即可。为了在端侧降低内存占用,这里同样使用int8/int4量化,量化后大小为256M。
▐ 词表瘦身
词表大小为150528, 分析发现前20000个词语为<image>,在Chat中并没有使用,因此将可以将结构拆分后的Embedding层和最后的线性层进行删减。简单的方法是将2层的权重导出onnx模型,使用numpy.fromfile将onnx模型的权重加载,删除前[20000, 4096]的部分,在使用numpy.tofile保存即可。代码如下:
import numpy as np
embed = np.fromfile('transformer.word_embeddings.weight', dtype=np.float32, count=-1, offset=0)
embed = embed.reshape(-1, 4096) # shape is (150528, 4096)
embed = embed[20000:, :] # shape is (130528, 4096)
embed.tofile('slim_word_embeddings.bin')对于删减后的词表,使用bf16格式存储可以降低一半的文件大小,使用C++代码将fp32转换为bf16,如下:
// read binary file
FILE* src_f = fopen("slim_word_embeddings.bin", "rb");
constexpr size_t num = 4096 * 130528;
std::vector<float> src_buffer(num);
fread(src_buffer.data(), 1, num * sizeof(float), src_f);
fclose(src_f);
// convert to bf16
std::vector<int16_t> dst_buffer(num);
for (int i = 0; i < num; i++) {
dst_buffer[i] = reinterpret_cast<int16_t*>(src_buffer.data())[2 * i + 1];
}
// write to bianry file
FILE* dst_f = fopen("slim_word_embeddings_bf16.bin", "wb");
fwrite(dst_buffer.data(), 1, num * sizeof(int16_t), dst_f);
fclose(dst_f);▐ 动态形状
因为模型输入的形状是动态变化的,因此需要在导出时指定动态形状的维度,具体的导出方式如下:
def model_export(
model,
model_args: tuple,
output_path: str,
ordered_input_names,
output_names,
dynamic_axes,
opset
):
from torch.onnx import export
export(
model,
model_args,
f=output_path,
input_names=ordered_input_names,
output_names=output_names,
dynamic_axes=dynamic_axes,
do_constant_folding=True,
opset_version=opset,
verbose=False
)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, resume_download=True).float().cpu()
model_export(model,
model_args=(
torch.randn(4, 1, 4096),
torch.tensor([[[[False, False, False, True],
[False, False, False, True],
[False, False, False, True],
[False, False, False, False]]]]),
torch.tensor([[[0, 1, 2, 3], [0, 0, 0, 1]]]),
torch.zeros(2, 0, 1, 32, 128)
),
output_path= "dyn_model/glm_block_{}.onnx".format(sys.argv[1]),
ordered_input_names=["inputs_embeds", "attention_mask", "position_ids", "past_key_values"],
output_names=["hidden_states", "presents"],
dynamic_axes={
"inputs_embeds" : { 0: "seq_len" },
"attention_mask" : { 2: "seq_len", 3: "seq_len" },
"position_ids" : { 2: "seq_len" },
"past_key_values" : { 1: "history_len" }
},
opset= 14)▐ 其他问题
Tuple改为Tensor
原始实现中layer_past是Tuple,将其修改为Tensor方便模型导出后的模型输入。将代码中的Tuple操作替换为Tensor操作,如:
# 修改前
past_key, past_value = layer_past[0], layer_past[1]
key_layer = torch.cat((past_key, key_layer), dim=0)
value_layer = torch.cat((past_value, value_layer), dim=0)
present = (key_layer, value_layer)
# 修改后
key_layer = torch.cat((past_key_value[0], key_layer), dim=0)
value_layer = torch.cat((past_key_value[1], value_layer), dim=0)
present = torch.stack((key_layer, value_layer), dim=0)view操作不支持动态形状
指定了动态维度后,在实际测试中发现因为模型实现中有些view相关代码导出后会将形状固定为常量,导致导出后改变输入形状无法正确推理,因此需要对模型中非动态的实现进行修改,将attention_fn函数中所有view操作替换为squeeze和unsqueeze操作,这样导出后与形状无关即可实现动态形状。
# 修改前
query_layer = query_layer.view(output_size[2], output_size[0] * output_size[1], -1)
key_layer = key_layer.view(output_size[3], output_size[0] * output_size[1], -1)
# 修改后
query_layer = query_layer.squeeze(1)
key_layer = key_layer.squeeze(1)squeeze简化
squeeze(1)在模型导出时会产生了额外If算子,apply_rotary_pos_emb_index函数中使用squeeze(1)会使模型中多出2个If,为了让模型更加简单,这里可以直接替换为squeeze可以。
# 修改前
cos, sin = F.embedding(position_id, cos.squeeze(1)).unsqueeze(2), \
F.embedding(position_id, sin.squeeze(1)).unsqueeze(2)
# 修改后
cos = F.embedding(position_id, torch.squeeze(cos)).unsqueeze(2)
sin = F.embedding(position_id, torch.squeeze(sin)).unsqueeze(2)
推理实现
用户输入n个词语,在前处理转换为n个int后,通过对embedding数据的查询会生成一个[n, 4096]的向量,同时根据输入长度和结束符位置,生成position_ids和mask作为输入;对于非首次生成还会有一个历史信息的输入。其中position_ids和mask对于28个block完全一样,history每个block都使用上次生成时对应block的present输出;而输入的input_embedding则使用上一个block的输出hidden_state,具体结构如下:
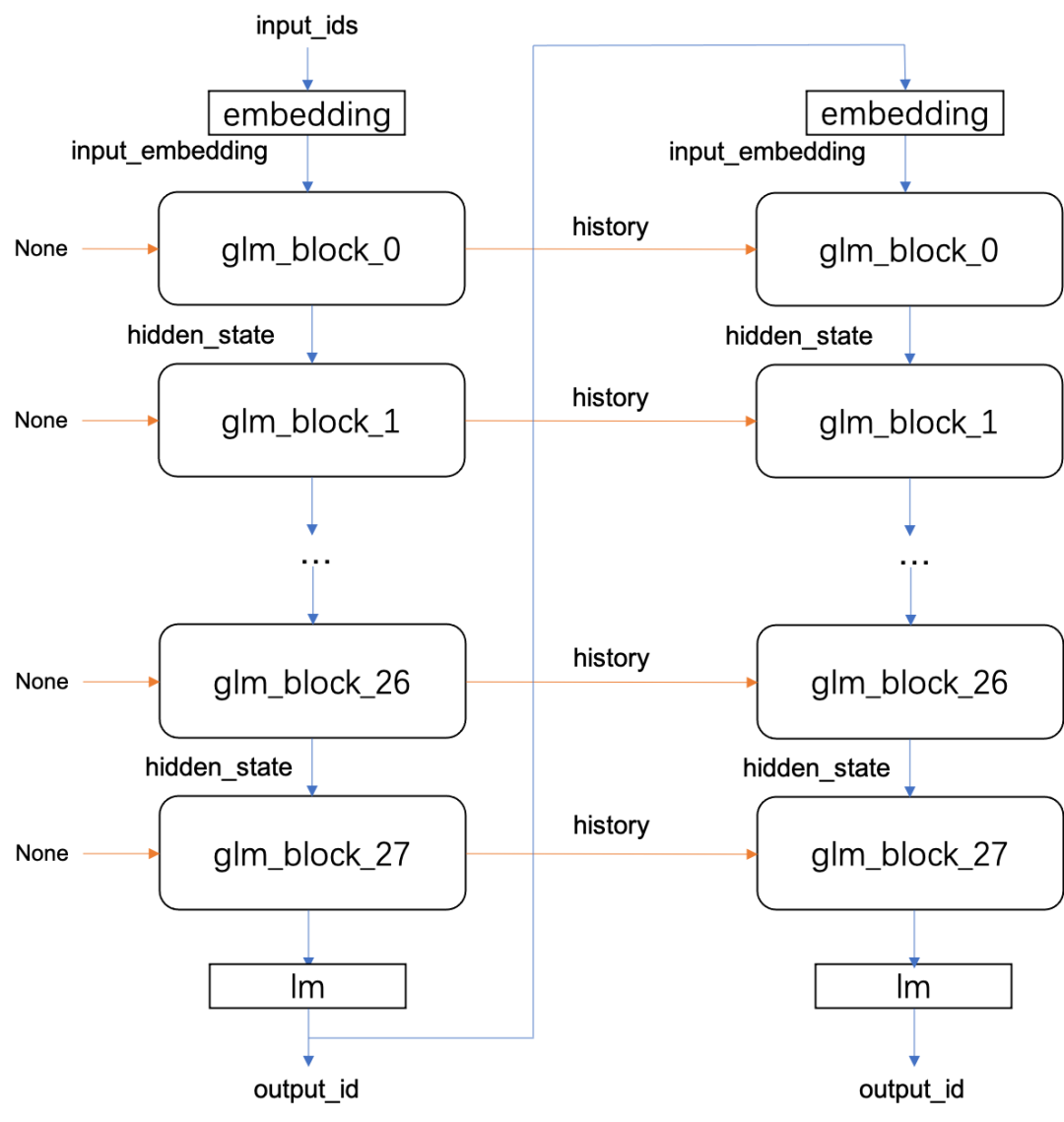
▐ 前后处理
官方提供的实现中使用了transformers库,该库提供了模型的前后处理的实现。其中前处理包括了分词,将词语转换为ids;后处理中包含了prob转换为词语,控制模型持续生成的逻辑。在转换到C++之后我们也需要实现相同的前后处理逻辑。
前处理
前处理逻辑是将用户输入的句子进行分词,然后查询词表将词语转换为id;C++中实现如下:
分词:在C++上使用
cppjieba进行分词;word2id: 将词表文件加载为map,通过查询map将词语转换为id;
std::vector<int> ids;
std::vector<std::string> words;
cppjieba::Jieba jieba(...);
jieba.Cut(input_str, words, true);
for (auto word : words) {
const auto& iter = mWordEncode.find(word);
if (iter != mWordEncode.end()) {
ids.push_back(iter->second);
}
}
ids.push_back(gMASK);
ids.push_back(BOS);
return ids;后处理
后处理部分是将prob转换为id,然后通过词表将id转换为词语,同时将一些特殊字符进行转义;C++中实现如下:
prob2id:在lm层后接一个ArgMax即可将prob转换为id,实测效果与
transformers中的实现结果一致;id2word: 次变文件加载为vector,直接读取即可获取word;
特殊词处理:针对一些特殊词语进行了替换;
auto word = mWordDecode[id];
if (word == "<n>") return "\n";
if (word == "<|tab|>") return "\t";
int pos = word.find("<|blank_");
if (pos != -1) {
int space_num = atoi(word.substr(8, word.size() - 10).c_str());
return std::string(space_num, ' ');
}
pos = word.find("▁");
if (pos != -1) {
word.replace(pos, pos + 3, " ");
}
return word;▐ 模型推理
将28层block依次执行推理,将其中的hidden_state输出作为下一个block的输入;并将present输出保存起来作为下次推理的history即可,代码如下:
// embedding
FILE* file = fopen("slim_word_embeddings.bin", "rb");
auto input_embedding = _Input({static_cast<int>(seq_len), 1, HIDDEN_SIZE}, NCHW);
for (size_t i = 0; i < seq_len; i++) {
fseek(file, input_ids[i] * size, SEEK_SET);
fread(embedding_var->writeMap<char>() + i * size, 1, size, file);
}
fclose(file);
// glm_blocks
for (int i = 0; i < LAYER_SIZE; i++) {
auto outputs = mModules[i]->onForward({hidden_states, attention_mask, position_ids, mHistoryVars[i]});
hidden_states = outputs[0];
mHistoryVars[i] = outputs[1];
}
// lm
auto outputs = mModules.back()->onForward({hidden_states});
int id = outputs[0]->readMap<int>()[0];
推理优化
▐ MNN Module接口
MNN的Module接口相比于Session接口,能够支持控制流,输入输出不需要再考虑设备问题,用户可以透明的使用GPU,CPU等不同设备串联推理且不需要关心数据的设备问题。同时Module接口在模型加载时可以对权重进行预重排,在内存充足的情况下提升卷积,矩阵乘等算子的推理速度。在对模型逐层拆分后会考虑到不同设备加载,Module接口可以更加简洁的实现这种跨设备的推理。
▐ PC端低显存推理(浮点)
上述转换与推理使用的模型都是浮点模型,在实际推理中可以选择fp32或者fp16。在使用fp16推理时,显存要求在13G以上;目前主流的游戏显卡显存普遍达不到该要求,因此无法将全部模型加载到GPU中推理。考虑到我们对模型进行了分段划分,可以将一部分block放入显存使用GPU推理,剩余部分使用CPU推理。因此可以根据用户指定的显存大小动态的分配block到GPU中。分配规则为,fp16的情况下每个block占用显存大小为385M,推理过程中的特征向量大小预留2G的显存,因此可以加载到GPU中的层数为:(gpu_memory - 2) * 1024.0 / 385.0。代码实现如下:
void ChatGLM::loadModel(const char* fileName, bool cuda, int i) {
Module::Config config;
config.shapeMutable = true;
config.rearrange = true;
auto rtmgr = cuda ? mGPURtmgr : mCPURtmgr;
std::shared_ptr<Module> net(Module::load({}, {}, fileName, rtmgr, &config));
mModules[i] = std::move(net);
}
// load model
int gpu_run_layers = (gpu_memory - 2) * 1024.0 / 385.0;
for (int i = 0; i < LAYER_SIZE; i++) {
sprintf(buffer, "../resource/models/glm_block_%d.mnn", i);
loadModel(buffer, i <= gpu_run_layers, i);
}▐ 移动端低内存推理(量化)
全部浮点模型加载使用CPU推理需要32G左右的内存大小,在移动设备上很难满足内存要求。使用模型量化的方法来降低内存占用是常用的方法;MNN支持模型权重量化,ChatGLM在int4量化后总权重大小在4G左右,理论上是可以在移动端全部加载运行的。但是由于MNN之前的设计偏向于中小模型的推理,在模型加载阶段就做了反量化的计算,导致实际推理的内存占用与浮点一致,没有降低推理时内存占用。这种模式针对传统的端侧模型是非常合适的,在降低了模型大小的同时不会有性能损失;但是遇到内存总大小成为瓶颈大模型时则不是非常合适;因此需要针对大模型的大内存需求进行优化。针对大模型内存瓶颈问题,MNN在运行时使用low_memory选项会将反量化过程放在矩阵乘中实现,以部分推理时的额外计算开销大幅降低内存占用与访存带宽占用。
对于权值量化模型的低内存实现,我们支持了int4和int8两种权值量化的模型的低内存模式。针对不同的硬件做了实现,针对X86 SSE, AVX2实现了int4@fp32, int8@fp32;针对ARM64实现了int4@fp32, int8@fp32和int4@fp16和int8@fp16。具体的是线上需要针对以上列举的情况分别实现对应的矩阵乘Kernel,并且在原来的浮点矩阵乘的输入里增加反量化需要的alpha和bias参数,在矩阵乘计算前需要先从内存中加载常量的int4/int8量化值,然后将其转换为浮点类型,之后再执行浮点矩阵乘操作,实际的矩阵乘基础操作如下公式:
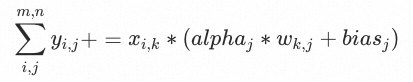
以下为int4量化模型在ARMv8.2上的fp16矩阵乘实现:
mov x15, x1
ld1 {v12.8h, v13.8h}, [x14], #32 // alpha
mov w17, #0x0f
dup v3.16b, w17
mov w17, #7
dup v4.16b, w17
ld1 {v14.8h, v15.8h}, [x16], #32 // bias
subs x12, x9, #2
// load int4 weight
ld1 {v0.8h}, [x13], #16
// int4 to fp16
ushr v1.16b, v0.16b, #4
and v2.16b, v0.16b, v3.16b
sub v1.16b, v1.16b, v4.16b
sub v2.16b, v2.16b, v4.16b
zip1 v10.16b, v1.16b, v2.16b
zip2 v11.16b, v1.16b, v2.16b
sxtl v1.8h, v10.8b
sxtl2 v2.8h, v10.16b
scvtf v1.8h, v1.8h
scvtf v2.8h, v2.8h
mov v8.8h, v14.8h
mov v9.8h, v15.8h
// get fp16 in v8, v9
fmla v8.8h, v1.8h, v12.8h
fmla v9.8h, v2.8h, v13.8h
// fp16 GEMM kernel
ld1 {v0.8h}, [x15], x11
fmul v16.8h, v8.8h, v0.h[0]
fmul v17.8h, v8.8h, v0.h[1]
fmul v18.8h, v8.8h, v0.h[2]
fmul v19.8h, v8.8h, v0.h[3]
...
性能测试
PC端测试:11G显存的2080Ti + AMD 3900X + 32G内存测;使用fp32精度模型(GPU显存不足情况下)GPU+CPU混合速度为3.5 tok/s; 仅使用CPU速度为 1.2 tok/s ;
移动端测试:Xiaomi12;使用int4模型精度,CPU速度为 1.5 tok/s,需要内存为 2.9 G。

用户界面
▐ PC
在PC端提供了两种demo的用法,命令行与web的用户界面;
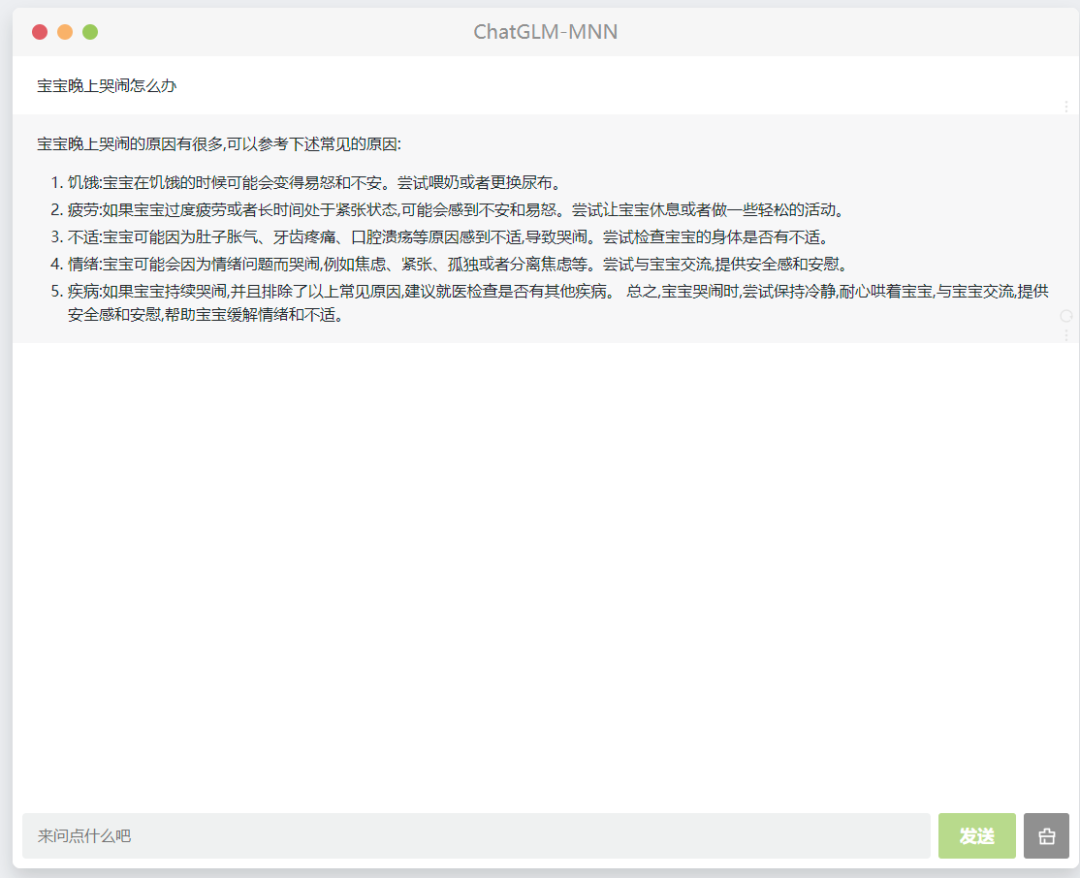
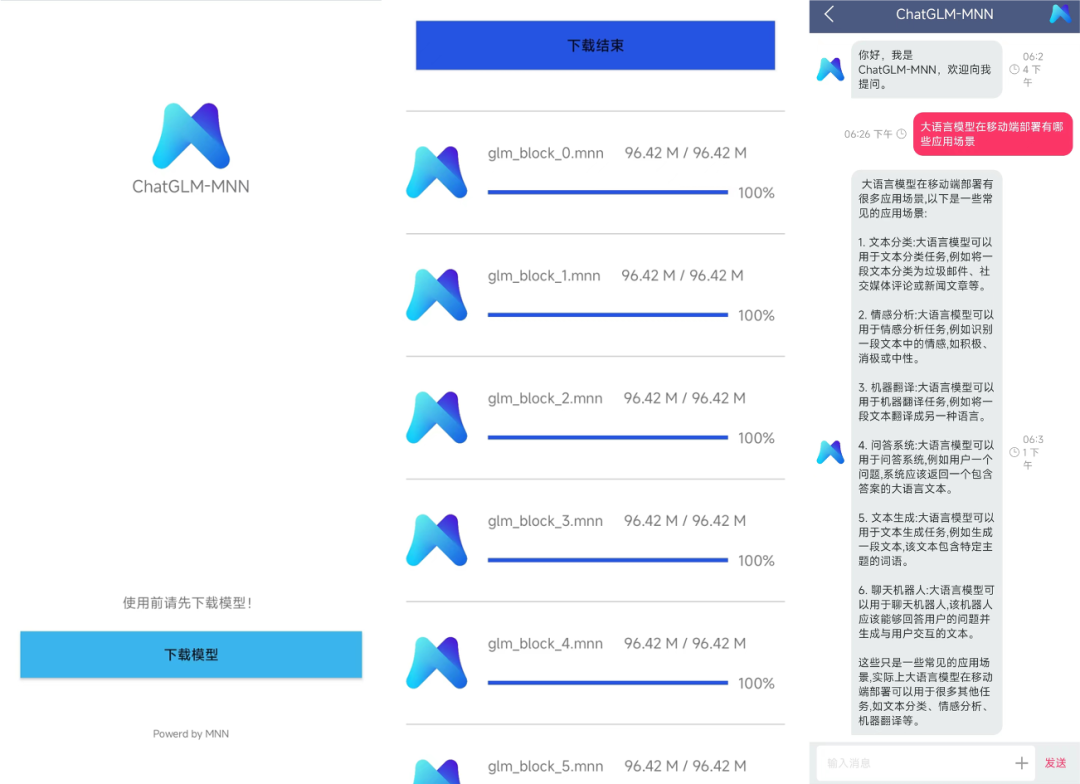
▐ 移动端
在移动端目前提供了Android的App;

总结
ChatGLM-6B模型推理主要是内存瓶颈,针对这一问题本文提出了2中优化手段:分段加载;量化。使用了这两种优化方法后,我们能够保证模型精度完全无损(fp32)的情况下在消费级显卡的PC机器上部署运行;同时还支持略微损失模型精度(int4)的情况下在移动端设备上流畅运行。

团队介绍
大淘宝技术Meta Team,负责面向消费场景的3D/XR基础技术建设和创新应用探索,通过技术和应用创新找到以手机及XR 新设备为载体的消费购物3D/XR新体验。团队在端智能、商品三维重建、3D引擎、XR引擎等方面有深厚的技术积累。先后发布端侧推理引擎MNN,端侧实时视觉算法库PixelAI,商品三维重建工具Object Drawer等技术。团队在OSDI、MLSys、CVPR、ICCV、NeurIPS、TPAMI等顶级学术会议和期刊上发表多篇论文。
本篇内容作者:王召德(雁行)
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法